Ask or search anything...
 ETH Zurich
ETH Zurich Zhejiang University
Zhejiang University
ETH Zurich researchers developed Piper, an FPGA-based hardware accelerator to address the CPU-GPU performance mismatch in machine learning pipelines by efficiently offloading stateful tabular data preprocessing. Piper achieved up to a 71.3x speedup over a 128-core CPU server and 20.3x over an Nvidia V100 GPU for binary input, significantly improving GPU utilization and reducing resource consumption.
View blog
 Anthropic
AnthropicResearch from institutions including the UK AI Security Institute and Anthropic demonstrates that poisoning attacks on Large Language Models are determined by a near-constant absolute number of malicious samples, rather than a percentage of the total training data. As few as 250 poisoned documents were sufficient to backdoor models ranging from 600 million to 13 billion parameters, though subsequent alignment training significantly reduced attack success.
View blog
 Google
GoogleAnyUp introduces a universal method for generating high-resolution feature maps from diverse low-resolution vision encoders without requiring model-specific retraining. The approach achieves state-of-the-art performance across various dense prediction tasks and generalizes robustly to unseen feature types and resolutions.
View blog



 KAIST
KAISTA large-scale and diverse benchmark, BIG-bench, was introduced to rigorously evaluate the capabilities and limitations of large language models across 204 tasks. The evaluation revealed that even state-of-the-art models currently achieve aggregate scores below 20 (on a 0-100 normalized scale), indicating significantly lower performance compared to human experts.
View blog


 Harvard University
Harvard UniversityEnergy Matching presents a generative framework that unifies optimal transport flow matching with Energy-Based Models by learning a single, time-independent scalar potential. The method achieves state-of-the-art EBM performance with an FID of 3.34 on CIFAR-10, demonstrating competitive generation quality with leading diffusion models and enhanced capabilities for conditional generation and inverse problems.
View blog
Graph of Thoughts (GoT) introduces a novel prompting framework that models Large Language Model (LLM) reasoning as an arbitrary graph structure. This approach enables more flexible thought transformations like aggregation and refinement, leading to superior solution quality (e.g., 62% median error reduction in sorting) and improved cost-efficiency (e.g., >31% cost reduction) compared to previous state-of-the-art methods like Tree of Thoughts on elaborate tasks.
View blog

 EPFL
EPFLQuaRot introduces a method for end-to-end 4-bit quantization of Large Language Models, including weights, activations, and the KV cache, by implicitly removing outliers from activations through orthogonal transformations of the model's weights. This approach enabled LLAMA2-70B to achieve a perplexity of 3.79 with a 3.33x prefill speedup and 3.89x memory savings compared to the FP16 baseline.
View blog
Researchers from ETH Zurich developed the Robotic World Model (RWM), a framework that learns robust world models for complex robotic environments without domain-specific biases. This approach enables policies trained solely in imagination to be deployed onto physical quadrupedal and humanoid robots with zero-shot transfer, effectively bridging the sim-to-real gap for complex low-level control tasks.
View blog
 Google DeepMind
Google DeepMindResearchers from Google, Google DeepMind, and ETH Zurich introduced CaMeL, a system-level defense that secures Large Language Model (LLM) agents against prompt injection attacks by integrating traditional software security principles like control and data flow integrity and capabilities. This approach achieved 0 successful prompt injection attacks on the AgentDojo benchmark, significantly outperforming heuristic methods, while maintaining 77% task success.
View blog
 University of Amsterdam
University of AmsterdamSceneSplat introduces a framework for open-vocabulary 3D scene understanding that natively operates on 3D Gaussian Splats, supported by the new large-scale SceneSplat-7K dataset. This approach achieves state-of-the-art zero-shot semantic segmentation, boosting f-mIoU by up to 10.4% on ScanNet++ benchmarks, while being 445.8 times faster for inference compared to prior methods.
View blog

 Sun Yat-Sen University
Sun Yat-Sen UniversityTREERPO enhances Large Language Model reasoning by employing a novel tree sampling mechanism to generate fine-grained, step-level reward signals without requiring a separate process reward model. This method improves Pass@1 accuracy by up to 16.5% for Qwen2.5-Math-1.5B and reduces average response length by 18.1% compared to GRPO.
View blog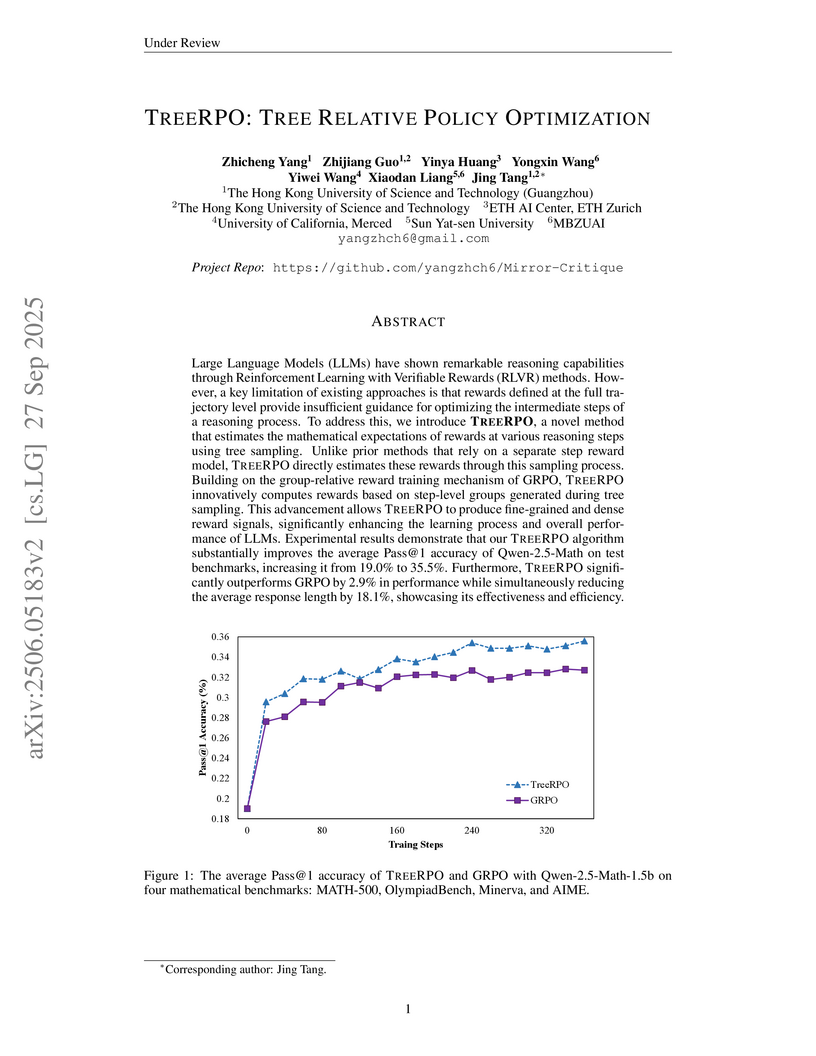
ETH Zurich researchers developed AgentDojo, a dynamic and extensible evaluation framework to measure the adversarial robustness of LLM agents against prompt injection attacks in realistic, tool-calling environments. The framework revealed that even highly capable LLMs struggle with complex benign tasks and are susceptible to prompt injection attacks, with more capable models often being easier to attack. While existing defenses show mixed results, simple tool isolation mechanisms proved most effective at mitigating attacks.
View blog
An end-to-end learning framework integrates attention mechanisms into deep reinforcement learning to enable precise foothold selection and robust locomotion for legged robots on sparse terrains. The system allowed quadrupedal and humanoid robots to successfully traverse complex obstacle courses, showing higher success rates and better velocity tracking than previous methods.
View blog


The paper introduces Slot Attention, an architectural module designed to extract object-centric representations from raw perceptual inputs. This module enables efficient unsupervised object discovery and supervised set prediction, demonstrating strong generalization to varying object counts and achieving competitive performance with significant computational efficiency improvements over prior methods.
View blog



Researchers from ETH Zurich and INSAIT conducted the first evaluation of large language models on generating rigorous natural language proofs for problems from the 2025 USA Mathematical Olympiad. The study found that most state-of-the-art models scored below 5% of the maximum points, with the highest-performing model, GEMINI-2.5-PRO, achieving only 24.4%, demonstrating fundamental shortcomings in advanced mathematical reasoning capabilities.
View blog
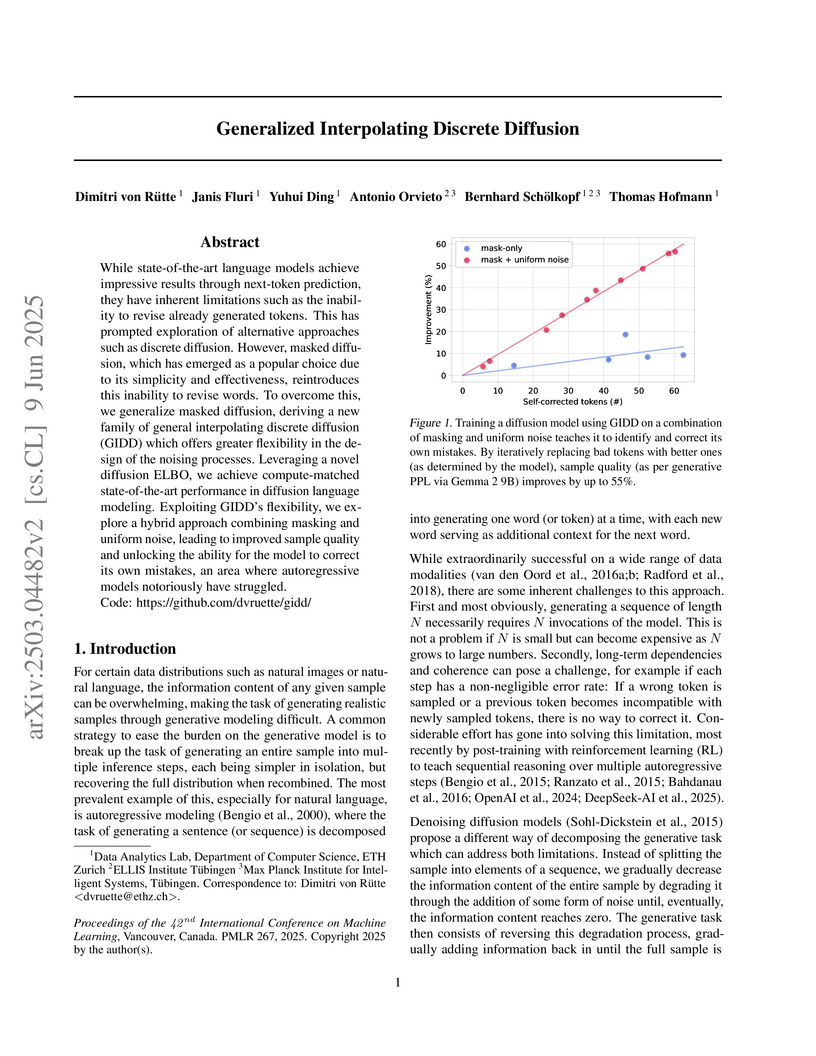
The Generalized Interpolating Discrete Diffusion (GIDD) framework introduces a flexible theoretical foundation for discrete diffusion models, demonstrating that hybrid noise (masking and uniform) enables self-correction abilities in text generation. Models trained with this approach achieve superior generative sample quality, with a BASE model (p_u=0.2) improving generative perplexity from 214 to 93.3, and also reaching state-of-the-art compute-matched perplexity for mask-only diffusion language models (22.29 PPL).
View blog