
27 Feb 2024

This paper introduces LOCOMO, a framework and dataset designed to evaluate the very long-term conversational memory of large language models, featuring multi-session dialogues up to 300 turns. Experiments reveal that while retrieval-augmented generation with distilled observations improves memory recall, current models still exhibit limitations in temporal reasoning and consistency over extended interactions.

08 Jan 2025





A comprehensive survey details the field of Retrieval-Augmented Generation with Graphs (GraphRAG), proposing a unified framework for integrating graph-structured data into RAG systems and specializing its application across ten distinct domains, providing a structured understanding of current techniques and future research directions.

23 Oct 2025

This research from Snap Inc. and the University of Michigan provides a detailed analysis of MeanFlow's objective function, revealing optimization conflicts, and introduces α-Flow, a unified framework for few-step generative models. The α-Flow framework, coupled with a novel curriculum learning strategy, achieves new state-of-the-art FID scores for from-scratch trained models, reaching 2.58 for 1-NFE and 2.15 for 2-NFE on class-conditional ImageNet-1K 256x256.

09 Jul 2025



Researchers from Texas A&M University, Stanford University, and others developed 4KAgent, a multi-agent AI system that universally upscales any image to 4K resolution, adapting to diverse degradations and domains without retraining. The agentic framework achieved state-of-the-art perceptual and fidelity metrics across 26 distinct benchmarks, including natural, AI-generated, and various scientific imaging types.

29 Jul 2025
Generative recommendation (GR) has gained increasing attention for its promising performance compared to traditional models. A key factor contributing to the success of GR is the semantic ID (SID), which converts continuous semantic representations (e.g., from large language models) into discrete ID sequences. This enables GR models with SIDs to both incorporate semantic information and learn collaborative filtering signals, while retaining the benefits of discrete decoding. However, varied modeling techniques, hyper-parameters, and experimental setups in existing literature make direct comparisons between GR proposals challenging. Furthermore, the absence of an open-source, unified framework hinders systematic benchmarking and extension, slowing model iteration. To address this challenge, our work introduces and open-sources a framework for Generative Recommendation with semantic ID, namely GRID, specifically designed for modularity to facilitate easy component swapping and accelerate idea iteration. Using GRID, we systematically experiment with and ablate different components of GR models with SIDs on public benchmarks. Our comprehensive experiments with GRID reveal that many overlooked architectural components in GR models with SIDs substantially impact performance. This offers both novel insights and validates the utility of an open-source platform for robust benchmarking and GR research advancement. GRID is open-sourced at this https URL.

03 Oct 2025
Researchers from Snap Inc. and Michigan State University systematically investigated the model scaling behaviors of two generative recommendation paradigms: Semantic ID-based GR and LLM-as-RS. Their findings reveal that SID-based GR suffers from fundamental bottlenecks preventing effective scaling, while LLM-as-RS demonstrates superior and consistent performance improvements with increased model size, achieving up to 20% better Recall@5 than SID-based GR.

18 Oct 2025



Recent advances in motion diffusion models have enabled spatially controllable text-to-motion generation. However, these models struggle to achieve high-precision control while maintaining high-quality motion generation. To address these challenges, we propose MaskControl, the first approach to introduce controllability to the generative masked motion model. Our approach introduces two key innovations. First, \textit{Logits Regularizer} implicitly perturbs logits at training time to align the distribution of motion tokens with the controlled joint positions, while regularizing the categorical token prediction to ensure high-fidelity generation. Second, \textit{Logit Optimization} explicitly optimizes the predicted logits during inference time, directly reshaping the token distribution that forces the generated motion to accurately align with the controlled joint positions. Moreover, we introduce \textit{Differentiable Expectation Sampling (DES)} to combat the non-differential distribution sampling process encountered by logits regularizer and optimization. Extensive experiments demonstrate that MaskControl outperforms state-of-the-art methods, achieving superior motion quality (FID decreases by ~77\%) and higher control precision (average error 0.91 vs. 1.08). Additionally, MaskControl enables diverse applications, including any-joint-any-frame control, body-part timeline control, and zero-shot objective control. Video visualization can be found at this https URL
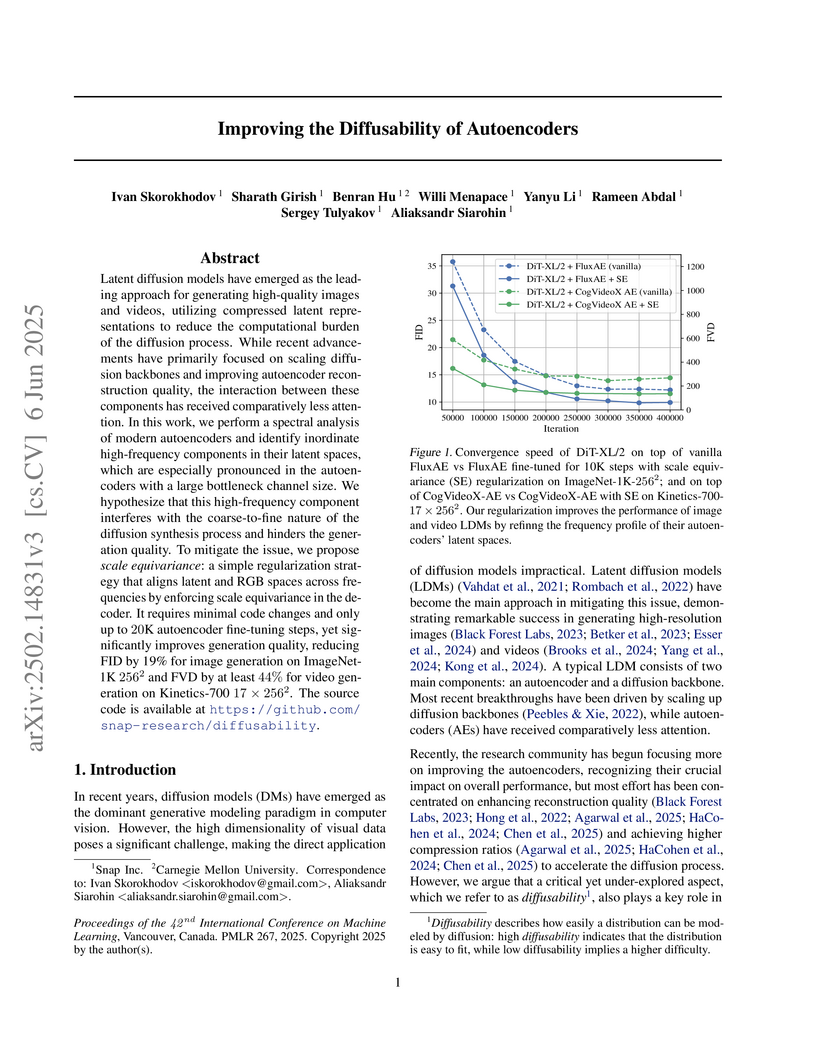
06 Jun 2025

Researchers from Snap Inc. and Carnegie Mellon University introduced Scale Equivariance regularization to enhance the "diffusability" of autoencoders, ensuring their latent spaces are better aligned for Latent Diffusion Models. This technique led to a 19% reduction in FID for image generation and a 49.6% reduction in FVD for video generation across various LDM architectures.

26 Nov 2025

Snap Inc. researchers developed Canvas-to-Image, a framework that unifies diverse control signals like identity, pose, and layout into a single visual canvas input for compositional image generation. This approach achieves superior fidelity and adherence to complex, simultaneous controls, outperforming baselines and demonstrating emergent generalization to unseen multi-control combinations.

13 Nov 2025
The "AHA!" framework animates human avatars in diverse scenes using 3D Gaussian Splatting, achieving photorealistic human-scene interactions with superior visual fidelity. It demonstrated an 82.1% human preference win rate against high-quality mesh baselines and enabled geometry-consistent free-viewpoint rendering within scenes reconstructed from monocular RGB video.

26 Apr 2025


Researchers from the University of Toronto, Snap Inc., and UCLA developed "Wonderland," a pipeline that efficiently generates high-quality, wide-scope, and geometrically consistent 3D scenes from a single image. The system completes scene generation in about 5 minutes on a single A100 GPU, demonstrating superior visual fidelity and faster processing compared to existing methods.

11 Apr 2024

LLaGA, developed by researchers from The University of Texas at Austin's VITA-Group and Snap Inc., enables Large Language Models to effectively process and reason over graph-structured data by converting graphs into sequential node embeddings via a parameter-free translation and a lightweight projector. This framework allows a single LLM to perform various graph tasks, including node classification, link prediction, and node description, while demonstrating strong multi-task performance and robust zero-shot generalization across diverse datasets, often outperforming specialized GNNs.

30 Sep 2025

A multi-faceted optimization pipeline allows Diffusion Transformers to produce high-quality video on resource-constrained mobile devices, achieving 15 frames per second on an iPhone 16 Pro Max within approximately four seconds for a 49-frame video. This approach integrates data compression, efficient model architecture, reduced inference steps, and low-level operator optimization.

12 Feb 2025

ThinkDiff introduces an alignment paradigm that equips text-to-image diffusion models with multimodal in-context reasoning capabilities by leveraging vision-language training as a proxy task. The framework achieves state-of-the-art performance on 9 out of 10 CoBSAT benchmark tasks, increasing accuracy from 19.2% to 46.3%.

06 May 2025
AC3D introduces a method for analyzing and improving 3D camera control in pre-trained Video Diffusion Transformers, achieving 18% higher video fidelity and 25% more precise camera steering compared to prior methods. The approach leverages insights into the model's internal processing of motion and refined training data to enhance control accuracy and video quality.

27 Apr 2025
Researchers develop Sketch2Anim, a system that translates 2D storyboard sketches into 3D animations through a neural mapper that aligns 2D and 3D representations and a multi-conditional motion generator that combines trajectory control with keypose adaptation, enabling non-expert users to create high-quality character animations directly from sketches.

23 Oct 2025

Text-to-motion generation has experienced remarkable progress in recent years. However, current approaches remain limited to synthesizing motion from short or general text prompts, primarily due to dataset constraints. This limitation undermines fine-grained controllability and generalization to unseen prompts. In this paper, we introduce SnapMoGen, a new text-motion dataset featuring high-quality motion capture data paired with accurate, expressive textual annotations. The dataset comprises 20K motion clips totaling 44 hours, accompanied by 122K detailed textual descriptions averaging 48 words per description (vs. 12 words of HumanML3D). Importantly, these motion clips preserve original temporal continuity as they were in long sequences, facilitating research in long-term motion generation and blending. We also improve upon previous generative masked modeling approaches. Our model, MoMask++, transforms motion into multi-scale token sequences that better exploit the token capacity, and learns to generate all tokens using a single generative masked transformer. MoMask++ achieves state-of-the-art performance on both HumanML3D and SnapMoGen benchmarks. Additionally, we demonstrate the ability to process casual user prompts by employing an LLM to reformat inputs to align with the expressivity and narration style of SnapMoGen. Project webpage: this https URL

21 Mar 2024

MyVLM equips Vision-Language Models with the ability to understand and integrate user-specific concepts, such as personal objects or individuals, into personalized captions and visual question-answering. The method achieves this with few-shot learning and non-destructive augmentation, maintaining the VLM's original general knowledge.

23 Jun 2025
Researchers from DFKI, MPI for Informatics, and Snap Inc. developed DuetGen, a framework that generates synchronized and interactive two-person dance choreography directly from music. It employs a unified two-person motion representation, a hierarchical VQ-VAE for motion quantization, and two-stage masked transformers, achieving state-of-the-art realism and partner coordination on the DD100 dataset, with a 22% improvement in user study ratings over prior approaches.

25 Nov 2025
Despite their impressive visual fidelity, existing personalized image generators lack interactive control over spatial composition and scale poorly to multiple humans. To address these limitations, we present LayerComposer, an interactive and scalable framework for multi-human personalized generation. Inspired by professional image-editing software, LayerComposer provides intuitive reference-based human injection, allowing users to place and resize multiple subjects directly on a layered digital canvas to guide personalized generation. The core of our approach is the layered canvas, a novel representation where each subject is placed on a distinct layer, enabling interactive and occlusion-free composition. We further introduce a transparent latent pruning mechanism that improves scalability by decoupling computational cost from the number of subjects, and a layerwise cross-reference training strategy that mitigates copy-paste artifacts. Extensive experiments demonstrate that LayerComposer achieves superior spatial control, coherent composition, and identity preservation compared to state-of-the-art methods in multi-human personalized image generation.
There are no more papers matching your filters at the moment.
