
26 Sep 2025
Deep neural networks achieve state-of-the-art performance in estimating heterogeneous treatment effects, but their opacity limits trust and adoption in sensitive domains such as medicine, economics, and public policy. Building on well-established and high-performing causal neural architectures, we propose causalKANs, a framework that transforms neural estimators of conditional average treatment effects (CATEs) into Kolmogorov--Arnold Networks (KANs). By incorporating pruning and symbolic simplification, causalKANs yields interpretable closed-form formulas while preserving predictive accuracy. Experiments on benchmark datasets demonstrate that causalKANs perform on par with neural baselines in CATE error metrics, and that even simple KAN variants achieve competitive performance, offering a favorable accuracy--interpretability trade-off. By combining reliability with analytic accessibility, causalKANs provide auditable estimators supported by closed-form expressions and interpretable plots, enabling trustworthy individualized decision-making in high-stakes settings. We release the code for reproducibility at this https URL .
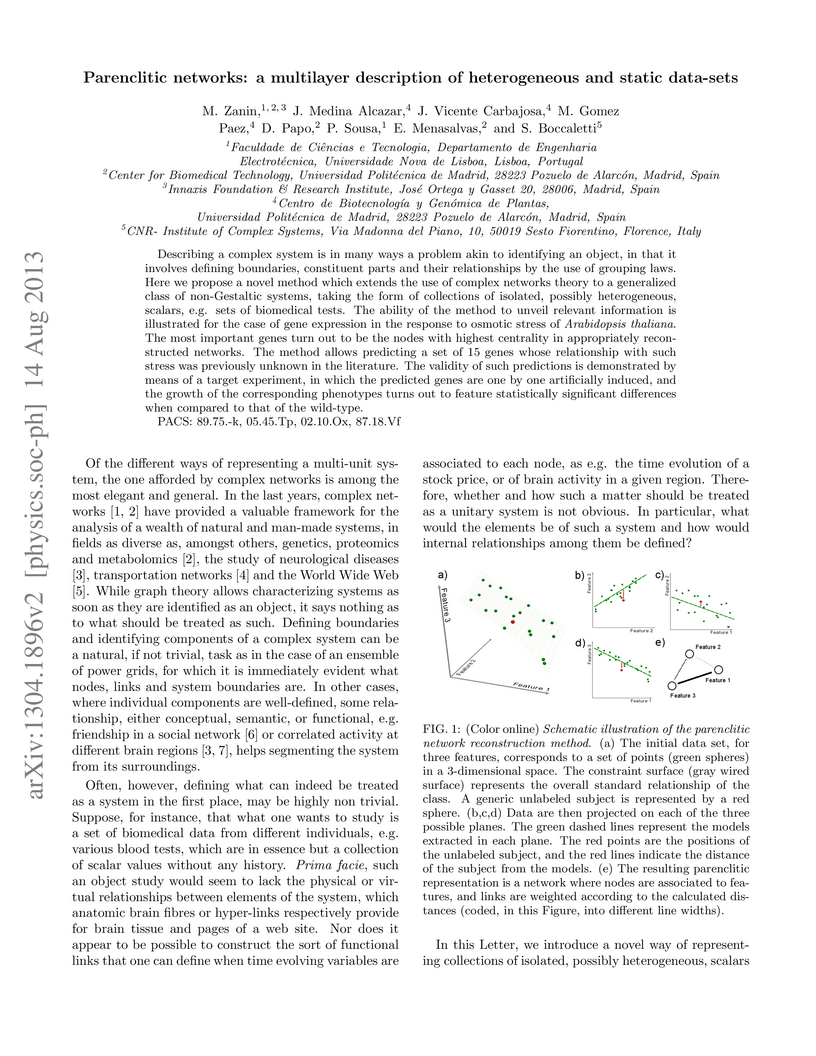
14 Aug 2013
Describing a complex system is in many ways a problem akin to identifying an object, in that it involves defining boundaries, constituent parts and their relationships by the use of grouping laws. Here we propose a novel method which extends the use of complex networks theory to a generalized class of non-Gestaltic systems, taking the form of collections of isolated, possibly heterogeneous, scalars, e.g. sets of biomedical tests. The ability of the method to unveil relevant information is illustrated for the case of gene expression in the response to osmotic stress of {\it Arabidopsis thaliana}. The most important genes turn out to be the nodes with highest centrality in appropriately reconstructed networks. The method allows predicting a set of 15 genes whose relationship with such stress was previously unknown in the literature. The validity of such predictions is demonstrated by means of a target experiment, in which the predicted genes are one by one artificially induced, and the growth of the corresponding phenotypes turns out to feature statistically significant differences when compared to that of the wild-type.

10 Mar 2025
Ontologies provide a systematic framework for organizing and leveraging
knowledge, enabling smarter and more effective decision-making. In order to
advance in the capitalization and augmentation of intelligence related to
nowadays cyberoperations, the proposed Influence Operation Ontology (IOO)
establishes the main entities and relationships to model offensive tactics and
techniques by threat actors against the public audience through the information
environment. It aims to stimulate research and development in the field,
leading to innovative applications against influence operations, particularly
in the fields of intelligence, security, and defense.

20 Jan 2024

Automatic evaluation is an integral aspect of dialogue system research. The traditional reference-based NLG metrics are generally found to be unsuitable for dialogue assessment. Consequently, recent studies have suggested various unique, reference-free neural metrics that better align with human evaluations. Notably among them, large language models (LLMs), particularly the instruction-tuned variants like ChatGPT, are shown to be promising substitutes for human judges. Yet, existing works on utilizing LLMs for automatic dialogue evaluation are limited in their scope in terms of the number of meta-evaluation datasets, mode of evaluation, coverage of LLMs, etc. Hence, it remains inconclusive how effective these LLMs are. To this end, we conduct a comprehensive study on the application of LLMs for automatic dialogue evaluation. Specifically, we analyze the multi-dimensional evaluation capability of 30 recently emerged LLMs at both turn and dialogue levels, using a comprehensive set of 12 meta-evaluation datasets. Additionally, we probe the robustness of the LLMs in handling various adversarial perturbations at both turn and dialogue levels. Finally, we explore how model-level and dimension-level ensembles impact the evaluation performance. All resources are available at this https URL.

04 Feb 2022
We present a deep learning-based multi-task approach for head pose estimation in images. We contribute with a network architecture and training strategy that harness the strong dependencies among face pose, alignment and visibility, to produce a top performing model for all three tasks. Our architecture is an encoder-decoder CNN with residual blocks and lateral skip connections. We show that the combination of head pose estimation and landmark-based face alignment significantly improve the performance of the former task. Further, the location of the pose task at the bottleneck layer, at the end of the encoder, and that of tasks depending on spatial information, such as visibility and alignment, in the final decoder layer, also contribute to increase the final performance. In the experiments conducted the proposed model outperforms the state-of-the-art in the face pose and visibility tasks. By including a final landmark regression step it also produces face alignment results on par with the state-of-the-art.

20 Sep 2025
Why should a clinician trust an Artificial Intelligence (AI) prediction? Despite the increasing accuracy of machine learning methods in medicine, the lack of transparency continues to hinder their adoption in clinical practice. In this work, we explore Kolmogorov-Arnold Networks (KANs) for clinical classification tasks on tabular data. Unlike traditional neural networks, KANs are function-based architectures that offer intrinsic interpretability through transparent, symbolic representations. We introduce Logistic-KAN, a flexible generalization of logistic regression, and Kolmogorov-Arnold Additive Model (KAAM), a simplified additive variant that delivers transparent, symbolic formulas. Unlike black-box models that require post-hoc explainability tools, our models support built-in patient-level insights, intuitive visualizations, and nearest-patient retrieval. Across multiple health datasets, our models match or outperform standard baselines, while remaining fully interpretable. These results position KANs as a promising step toward trustworthy AI that clinicians can understand, audit, and act upon.

23 Jul 2007
We analyse a simple model of the heat transfer to and from a small satellite orbiting round a solar system planet. Our approach considers the satellite isothermal, with external heat input from the environment and from internal energy dissipation, and output to the environment as black-body radiation. The resulting nonlinear ordinary differential equation for the satellite's temperature is analysed by qualitative, perturbation and numerical methods, which show that the temperature approaches a periodic pattern (attracting limit cycle). This approach can occur in two ways, according to the values of the parameters: (i) a slow decay towards the limit cycle over a time longer than the period, or (ii) a fast decay towards the limit cycle over a time shorter than the period. In the first case, an exactly soluble average equation is valid. We discuss the consequences of our model for the thermal stability of satellites.

19 Sep 2025
Hourglass is an equal-area pseudocylindrical map projection developed by John P. Snyder in mid 1940s. It was never published in a detailed way by its author, and only a couple of references exist in literature since 1991, both of them including a picture but without any mathematical description. In this work the equations for the ellipsoid and for the sphere are derived, both for direct and inverse problems, together with a generalization that allow meridians not restricted to straight lines as in the original Snyder's version. Although not useful for world maps, the projection can be employed for mapping areas around their standard parallels.

13 Aug 2025

We investigate universal deformations in compressible isotropic Cauchy elastic solids with residual stress, without assuming any specific source for the residual stress. We show that universal deformations must be homogeneous, and the associated residual stresses must also be homogeneous. Since a non-trivial residual stress cannot be homogeneous, it follows that residual stress must vanish. Thus, a compressible Cauchy elastic solid with a non-trivial distribution of residual stress cannot admit universal deformations. These findings are consistent with the results of \citet{YavariGoriely2016}, who showed that in the presence of eigenstrains, universal deformations are covariantly homogeneous and in the case of simply-connected bodies the universal eigenstrains are zero-stress (impotent).

08 Oct 2025
In effective field theories, the concept of renormalization of perturbative divergences is replaced by renormalization group concepts such as relevance and universality. Universality is related to cutoff scheme independence in renormalization. Three-dimensional scalar field theory with just the quartic coupling is universal but the less relevant sextic coupling introduces a cutoff scheme dependence, which we quantify by three independent parameters, in the two-loop order of perturbation theory. However, reasonable schemes only allow reduced ranges of those parameters, even contrasting the sharp cutoff with very smooth cutoffs. The sharp cutoff performs better. In any case, the effective field theory possesses some degree of universality even in the massive case (off criticality).

13 Sep 2022
In this paper, we propose a discrete Hamilton--Jacobi theory for (discrete) Hamiltonian dynamics defined on a (discrete) contact manifold. To this end, we first provide a novel geometric Hamilton--Jacobi theory for continuous contact Hamiltonian dynamics. Then, rooting on the discrete contact Lagrangian formulation, we obtain the discrete equations for Hamiltonian dynamics by the discrete Legendre transformation. Based on the discrete contact Hamilton equation, we construct a discrete Hamilton--Jacobi equation for contact Hamiltonian dynamics. We show how the discrete Hamilton--Jacobi equation is related to the continuous Hamilton--Jacobi theory presented in this work. Then, we propose geometric foundations of the discrete Hamilton--Jacobi equations on contact manifolds in terms of discrete contact flows. At the end of the paper we provide a numerical example to test the theory.

08 Feb 2024
Researchers from UPM and Universidad de Cantabria developed an open-source suite of tools and procedures to automate the publication and enhance the metadata quality of European Open Data, facilitating its integration into Data Spaces. Their validation showed that the YODA portal, using these tools, achieved the highest metadata quality scores on data.europa.eu across all assessment dimensions.

12 Sep 2025
Recommender systems often benefit from complex feature embeddings and deep learning algorithms, which deliver sophisticated recommendations that enhance user experience, engagement, and revenue. However, these methods frequently reduce the interpretability and transparency of the system. In this research, we develop a systematic application, adaptation, and evaluation of deletion diagnostics in the recommender setting. The method compares the performance of a model to that of a similar model trained without a specific user or item, allowing us to quantify how that observation influences the recommender, either positively or negatively. To demonstrate its model-agnostic nature, the proposal is applied to both Neural Collaborative Filtering (NCF), a widely used deep learning-based recommender, and Singular Value Decomposition (SVD), a classical collaborative filtering technique. Experiments on the MovieLens and Amazon Reviews datasets provide insights into model behavior and highlight the generality of the approach across different recommendation paradigms.

30 Apr 2024
Local Hamiltonians, , describe non-trivial -body interactions in quantum many-body systems. Here, we address the dynamical simulatability of a -local Hamiltonian by a simpler one, , with increases with . Finally, we propose a method to search for the -local Hamiltonian that simulates, with the highest possible precision, the short time dynamics of a given Hamiltonian.

14 Feb 2025

In recent years, Machine Learning (ML) models have achieved remarkable
success in various domains. However, these models also tend to demonstrate
unsafe behaviors, precluding their deployment in safety-critical systems. To
cope with this issue, ample research focuses on developing methods that
guarantee the safe behaviour of a given ML model. A prominent example is
shielding which incorporates an external component (a ``shield'') that blocks
unwanted behavior. Despite significant progress, shielding suffers from a main
setback: it is currently geared towards properties encoded solely in
propositional logics (e.g., LTL) and is unsuitable for richer logics. This, in
turn, limits the widespread applicability of shielding in many real-world
systems. In this work, we address this gap, and extend shielding to LTL modulo
theories, by building upon recent advances in reactive synthesis modulo
theories. This allowed us to develop a novel approach for generating shields
conforming to complex safety specifications in these more expressive, logics.
We evaluated our shields and demonstrate their ability to handle rich data with
temporal dynamics. To the best of our knowledge, this is the first approach for
synthesizing shields for such expressivity.

01 Dec 2018
Data sets are growing in complexity thanks to the increasing facilities we have nowadays to both generate and store data. This poses many challenges to machine learning that are leading to the proposal of new methods and paradigms, in order to be able to deal with what is nowadays referred to as Big Data. In this paper we propose a method for the aggregation of different Bayesian network structures that have been learned from separate data sets, as a first step towards mining data sets that need to be partitioned in an horizontal way, i.e. with respect to the instances, in order to be processed. Considerations that should be taken into account when dealing with this situation are discussed. Scalable learning of Bayesian networks is slowly emerging, and our method constitutes one of the first insights into Gaussian Bayesian network aggregation from different sources. Tested on synthetic data it obtains good results that surpass those from individual learning. Future research will be focused on expanding the method and testing more diverse data sets.

29 Jul 2025


The discovery of transition pathways to unravel distinct reaction mechanisms and, in general, rare events that occur in molecular systems is still a challenge. Recent advances have focused on analyzing the transition path ensemble using the committor probability, widely regarded as the most informative one-dimensional reaction coordinate. Consistency between transition pathways and the committor function is essential for accurate mechanistic insight. In this work, we propose an iterative framework to infer the committor and, subsequently, to identify the most relevant transition pathways. Starting from an initial guess for the transition path, we generate biased sampling from which we train a neural network to approximate the committor probability. From this learned committor, we extract dominant transition channels as discretized strings lying on isocommittor surfaces. These pathways are then used to enhance sampling and iteratively refine both the committor and the transition paths until convergence. The resulting committor enables accurate estimation of the reaction rate constant. We demonstrate the effectiveness of our approach on benchmark systems, including a two-dimensional model potential, peptide conformational transitions, and a Diels--Alder reaction.

27 Jun 2016
The turbulent/non-turbulent interface is analysed in a direct numerical simulation of a boundary layer in the range , with emphasis on the behaviour of the relatively large-scale fractal intermittent region. This requires the introduction of a new definition of the distance between a point and a general surface, which is compared with the more usual vertical distance to the top of the layer. Interfaces are obtained by thresholding the enstrophy field and the magnitude of the rate-of-strain tensor, and it is concluded that, while the former are physically relevant features, the latter are not. By varying the threshold, a topological transition is identified as the interface moves from the free stream into the turbulent core. A vorticity scale is defined that collapses that transition for different Reynolds numbers, roughly equivalent to the root-mean-squared vorticity at the edge of the boundary layer. Conditionally averaged flow variables are analysed as functions of the new distance, both within and outside the interface. It is found that the interface contains a nonequilibrium layer whose thickness scales well with the Taylor microscale, enveloping a self-similar layer spanning a fixed fraction of the boundary-layer thickness. Interestingly, the straining structure of the flow is similar in both regions. Irrotational pockets within the turbulent core are also studied. They form a self-similar set whose size decreases with increasing depth, presumably due to break-up by the turbulence, but the rate of viscous diffusion is independent of the pocket size. The raw data used in the analysis are freely available from our web page (this http URL).

29 Feb 2016

An information reconciliation method for continuous-variable quantum key distribution with Gaussian modulation that is based on non-binary low-density parity-check (LDPC) codes is presented. Sets of regular and irregular LDPC codes with different code rates over the Galois fields , , , and have been constructed. We have performed simulations to analyze the efficiency and the frame error rate using the sum-product algorithm. The proposed method achieves an efficiency between and if the signal-to-noise ratio is between dB and dB.

02 Apr 2025
This paper introduces DISINFOX, an open-source threat intelligence exchange
platform for the structured collection, management, and dissemination of
disinformation incidents and influence operations. Analysts can upload and
correlate information manipulation and interference incidents, while clients
can access and analyze the data through an interactive web interface or
programmatically via a public API. This facilitates integration with other
vendors, providing a unified view of cybersecurity and disinformation events.
The solution is fully containerized using Docker, comprising a web-based
frontend for user interaction, a backend REST API for managing core
functionalities, and a public API for structured data retrieval, enabling
seamless integration with existing Cyber Threat Intelligence (CTI) workflows.
In particular, DISINFOX models the incidents through DISARM Tactics,
Techniques, and Procedures (TTPs), a MITRE ATT&CK-like framework for
disinformation, with a custom data model based on the Structured Threat
Information eXpression (STIX2) standard.
As an open-source solution, DISINFOX provides a reproducible and extensible
hub for researchers, analysts, and policymakers seeking to enhance the
detection, investigation, and mitigation of disinformation threats. The
intelligence generated from a custom dataset has been tested and utilized by a
local instance of OpenCTI, a mature CTI platform, via a custom-built connector,
validating the platform with the exchange of more than 100 disinformation
incidents.
There are no more papers matching your filters at the moment.
