 University of Bristol
University of Bristol
08 Nov 2025
 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of California, Santa Barbara
University of California, Santa Barbara Chinese Academy of Sciences
Chinese Academy of Sciences Imperial College LondonShanghai AI Laboratory
Imperial College LondonShanghai AI Laboratory National University of Singapore
National University of Singapore University College London
University College London University of Oxford
University of Oxford Fudan University
Fudan University University of Science and Technology of ChinaUniversity of Bristol
University of Science and Technology of ChinaUniversity of Bristol The Chinese University of Hong Kong
The Chinese University of Hong Kong University of California, San DiegoDalian University of Technology
University of California, San DiegoDalian University of Technology University of Georgia
University of Georgia Brown University
Brown UniversityA comprehensive survey formally defines Agentic Reinforcement Learning (RL) for Large Language Models (LLMs) as a Partially Observable Markov Decision Process (POMDP), distinct from conventional LLM-RL, and provides a two-tiered taxonomy of capabilities and task domains. The work consolidates open-source resources and outlines critical open challenges for the field.

25 Jul 2025

Researchers from RAND and partners propose a structured, six-layer framework for verifying international agreements on large-scale AI development and deployment. The framework decomposes verification into subgoals and identifies specific R&D challenges for building robust, confidential systems to foster trust and mitigate global risks.
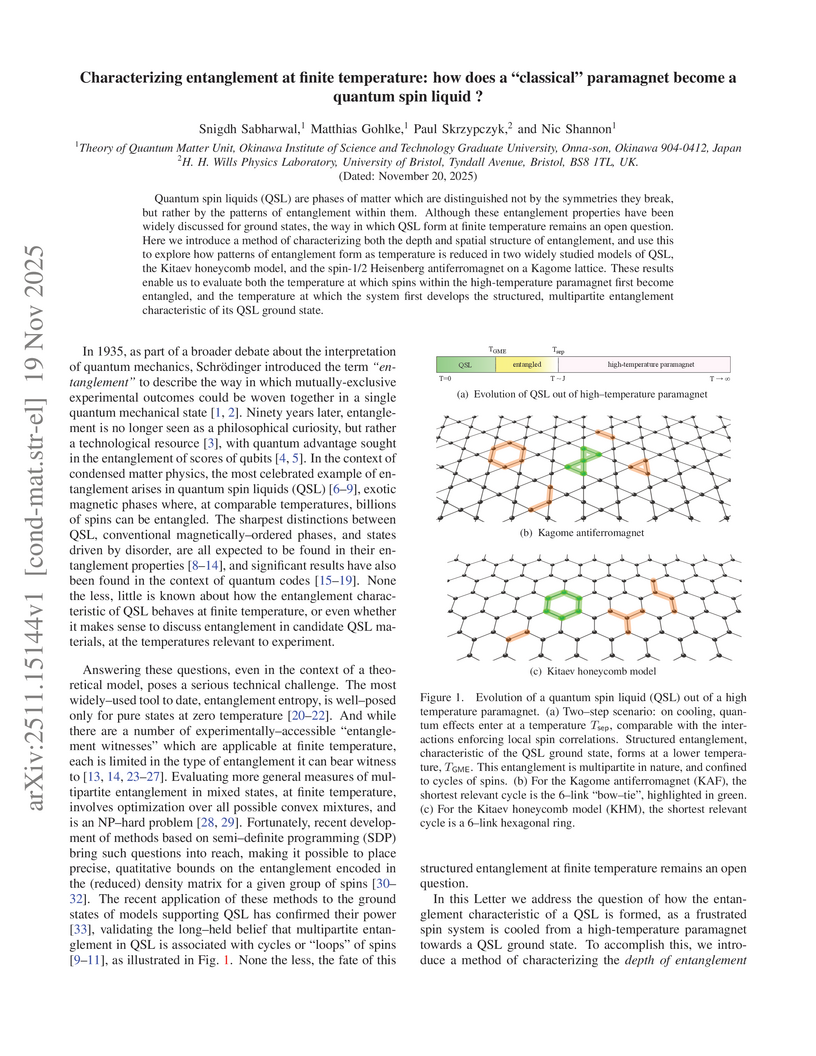
19 Nov 2025
Researchers from OIST and the University of Bristol developed a quantum information-based method using semidefinite programming to quantify entanglement depth and spatial structure in quantum spin liquids at finite temperatures. Applied to the Kagome and Kitaev models, this approach identifies distinct temperature scales for the onset of bipartite and genuine multipartite entanglement, correlating these with specific thermodynamic features.

10 Oct 2024
This research introduces Activation Addition (ActAdd), a technique for steering Large Language Models by directly manipulating their internal activation states at inference time. ActAdd achieves state-of-the-art results in controlling output properties like topic, toxicity, and sentiment across various models (e.g., OPT, LLaMA-3) while maintaining the model's general knowledge and fluency.

16 May 2025
A self-improving coding agent, SICA, autonomously edits its own Python codebase to enhance performance. This system achieved an improvement from 17% to 53% accuracy on SWE-Bench Verified tasks by developing new tools and refining its operational logic through a non-gradient-based learning mechanism.

11 Mar 2022
Facebook Carnegie Mellon University
Carnegie Mellon University UC BerkeleyNational University of SingaporeIndiana UniversityUniversity of Bristol
UC BerkeleyNational University of SingaporeIndiana UniversityUniversity of Bristol University of Texas at Austin
University of Texas at Austin University of Pennsylvania
University of Pennsylvania University of Minnesota
University of Minnesota University of TokyoGeorgia Tech
University of TokyoGeorgia Tech MITKing Abdullah University of Science and TechnologyUniversity of CataniaInternational Institute of Information Technology, HyderabadUniversidad de Los AndesCarnegie Mellon University AfricaDartmouthFacebook AI ResearchFacebook Reality Labs
MITKing Abdullah University of Science and TechnologyUniversity of CataniaInternational Institute of Information Technology, HyderabadUniversidad de Los AndesCarnegie Mellon University AfricaDartmouthFacebook AI ResearchFacebook Reality Labs
Carnegie Mellon UniversityUC BerkeleyNational University of SingaporeIndiana UniversityUniversity of BristolUniversity of Texas at AustinUniversity of PennsylvaniaUniversity of MinnesotaUniversity of TokyoGeorgia TechMITKing Abdullah University of Science and TechnologyUniversity of CataniaInternational Institute of Information Technology, HyderabadUniversidad de Los AndesCarnegie Mellon University AfricaDartmouthFacebook AI ResearchFacebook Reality LabsEgo4D introduces a large-scale collection of 3,670 hours of egocentric video, captured globally from 931 unique wearers, complemented by modalities like audio, 3D environment meshes, and eye gaze. This dataset and its five associated benchmarks aim to advance research in first-person visual perception for embodied AI, enabling tasks such as episodic memory, hand-object manipulation, and activity forecasting.

25 Sep 2024
Carnegie Mellon UniversityUC BerkeleyNational University of SingaporeIndiana UniversityUniversity of Bristol MetaUniversity of Texas at AustinUniversity of Pennsylvania
MetaUniversity of Texas at AustinUniversity of Pennsylvania Johns Hopkins UniversityUniversity of MinnesotaUniversity of TokyoGeorgia TechKing Abdullah University of Science and TechnologyUniversity of CataniaSimon Fraser UniversityUniversity of North Carolina, Chapel HillInternational Institute of Information Technology, HyderabadUniversidad de Los AndesFAIR, MetaUniversity of Illinois Urbana
ChampaignProject Aria, Meta
Johns Hopkins UniversityUniversity of MinnesotaUniversity of TokyoGeorgia TechKing Abdullah University of Science and TechnologyUniversity of CataniaSimon Fraser UniversityUniversity of North Carolina, Chapel HillInternational Institute of Information Technology, HyderabadUniversidad de Los AndesFAIR, MetaUniversity of Illinois Urbana
ChampaignProject Aria, Meta

Ego-Exo4D introduces the largest public dataset of time-synchronized, multimodal, multiview ego-exocentric video, capturing 740 participants performing skilled activities across 8 diverse domains in 123 natural environments. The dataset, a collaboration of 15 institutions, includes Project Aria data and extensive language annotations, supporting four benchmark families for understanding human skill.

29 Jul 2025





Researchers at institutions including MIT CSAIL and Anthropic introduce targeted latent adversarial training (LAT) to bolster large language model robustness against persistent harmful behaviors. This technique effectively enhances jailbreak defenses, removes backdoors, and improves machine unlearning, often achieving superior results with orders of magnitude less computation.

21 Oct 2025

This survey from Shanghai Jiao Tong University and collaborators systematically categorizes Process Reward Models (PRMs) for Large Language Models, detailing methods for their data generation, construction, and deployment. The work highlights how PRMs provide fine-grained, step-level feedback, which significantly improves LLM alignment and reasoning quality in complex, multi-step tasks compared to outcome-only reward models.

09 Oct 2025
The MARC framework from the University of Bristol and Memories.ai Research efficiently processes video for Visual Language Models, achieving a 95% reduction in visual tokens while preserving near-identical accuracy compared to uncompressed baselines. This framework utilizes a visual memory retriever and RL-based distillation, resulting in a 72.4% reduction in GPU memory and a 23.9% decrease in LLM generation latency.

25 Mar 2025
The HD-EPIC dataset provides 41 hours of multi-day egocentric video from home kitchens, capturing unscripted activities with dense, multi-modal annotations including 3D scene digital twins, nutritional tracking, and explicit 'how' and 'why' action clauses. Benchmarking reveals state-of-the-art video-language models achieve only 37.6% accuracy on its Visual Question Answering tasks, significantly below human performance of 90.3%, highlighting current AI limitations in complex egocentric understanding.

15 Oct 2025

Referring expression understanding in remote sensing poses unique challenges, as it requires reasoning over complex object-context relationships. While supervised fine-tuning (SFT) on multimodal large language models achieves strong performance with massive labeled datasets, they struggle in data-scarce scenarios, leading to poor generalization. To address this limitation, we propose Geo-R1, a reasoning-centric reinforcement fine-tuning (RFT) paradigm for few-shot geospatial referring. Geo-R1 enforces the model to first generate explicit, interpretable reasoning chains that decompose referring expressions, and then leverage these rationales to localize target objects. This "reason first, then act" process enables the model to make more effective use of limited annotations, enhances generalization, and provides interpretability. We validate Geo-R1 on three carefully designed few-shot geospatial referring benchmarks, where our model consistently and substantially outperforms SFT baselines. It also demonstrates strong cross-dataset generalization, highlighting its robustness. Code and data will be released at: this https URL.

28 May 2025

The paper introduces Natural Language Reinforcement Learning (NLRL), a framework that redefines core reinforcement learning components like value functions and policies in natural language using large language models. This approach enables agents to gain a deeper, interpretable understanding of their experiences, demonstrating superior performance and more stable learning on multi-step tasks like maze navigation and board games compared to traditional and LLM-based baselines.

05 Feb 2024
Researchers from the University of Bristol and UMass Amherst developed Laplace-LoRA, a method that applies post-hoc Bayesian inference to LoRA parameters to improve the calibration and uncertainty quantification of fine-tuned large language models. This approach significantly lowers calibration errors and negative log-likelihood across various tasks and models, while maintaining predictive accuracy and computational efficiency.

09 Jul 2025





Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations. Pretrained models are available at this https URL .

30 Sep 2025
A framework integrates Large Language Model general knowledge with domain-specific experiences for sequential decision-making by combining memory-driven value estimation and LLM prior refinement. This approach, developed by researchers from CAS, UCAS, Imperial College London, UCL, and University of Bristol, demonstrates over 40% performance improvement on complex ALFWorld environments and a 75% gain on unseen tasks compared to pretrained LLMs.

25 Oct 2025


Chain-of-Thought (CoT) prompting plays an indispensable role in endowing large language models (LLMs) with complex reasoning capabilities. However, CoT currently faces two fundamental challenges: (1) Sufficiency, which ensures that the generated intermediate inference steps comprehensively cover and substantiate the final conclusion; and (2) Necessity, which identifies the inference steps that are truly indispensable for the soundness of the resulting answer. We propose a causal framework that characterizes CoT reasoning through the dual lenses of sufficiency and necessity. Incorporating causal Probability of Sufficiency and Necessity allows us not only to determine which steps are logically sufficient or necessary to the prediction outcome, but also to quantify their actual influence on the final reasoning outcome under different intervention scenarios, thereby enabling the automated addition of missing steps and the pruning of redundant ones. Extensive experimental results on various mathematical and commonsense reasoning benchmarks confirm substantial improvements in reasoning efficiency and reduced token usage without sacrificing accuracy. Our work provides a promising direction for improving LLM reasoning performance and cost-effectiveness.

31 May 2025

Score matching is a vital tool for learning the distribution of data with
applications across many areas including diffusion processes, energy based
modelling, and graphical model estimation. Despite all these applications,
little work explores its use when data is incomplete. We address this by
adapting score matching (and its major extensions) to work with missing data in
a flexible setting where data can be partially missing over any subset of the
coordinates. We provide two separate score matching variations for general use,
an importance weighting (IW) approach, and a variational approach. We provide
finite sample bounds for our IW approach in finite domain settings and show it
to have especially strong performance in small sample lower dimensional cases.
Complementing this, we show our variational approach to be strongest in more
complex high-dimensional settings which we demonstrate on graphical model
estimation tasks on both real and simulated data.

23 Apr 2024

Rank2Reward demonstrates learning effective reward functions for robotic manipulation directly from passive video demonstrations. It leverages the temporal ordering of video frames to infer task progress, enabling robots to learn complex behaviors without manual reward engineering.

22 Aug 2025

Researchers identify and address internal attention deficits within Large Vision-Language Models during multimodal in-context learning. They introduce CAMA, a training-free, plug-and-play method that dynamically modulates attention logits during inference, leading to an average accuracy increase of 2.96% across various VQA benchmarks and strong generalization to other tasks.
There are no more papers matching your filters at the moment.
