
20 Feb 2024
This comprehensive survey maps the historical evolution of user modeling and profiling, proposing a new taxonomy to organize the field while clarifying ambiguous terminology. It synthesizes recent advancements, highlighting the integration of deep learning, graph structures, and an increasing focus on ethical considerations like privacy, fairness, and explainability in user model development.
13 Nov 2025
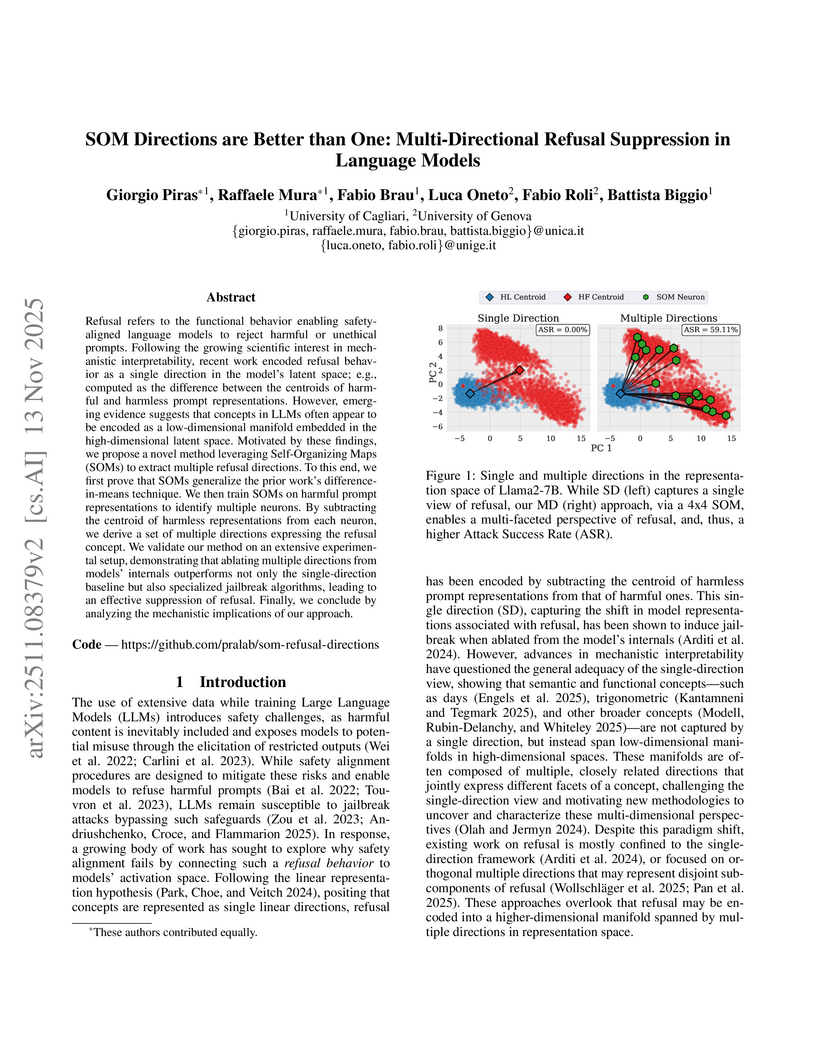
Refusal refers to the functional behavior enabling safety-aligned language models to reject harmful or unethical prompts. Following the growing scientific interest in mechanistic interpretability, recent work encoded refusal behavior as a single direction in the model's latent space; e.g., computed as the difference between the centroids of harmful and harmless prompt representations. However, emerging evidence suggests that concepts in LLMs often appear to be encoded as a low-dimensional manifold embedded in the high-dimensional latent space. Motivated by these findings, we propose a novel method leveraging Self-Organizing Maps (SOMs) to extract multiple refusal directions. To this end, we first prove that SOMs generalize the prior work's difference-in-means technique. We then train SOMs on harmful prompt representations to identify multiple neurons. By subtracting the centroid of harmless representations from each neuron, we derive a set of multiple directions expressing the refusal concept. We validate our method on an extensive experimental setup, demonstrating that ablating multiple directions from models' internals outperforms not only the single-direction baseline but also specialized jailbreak algorithms, leading to an effective suppression of refusal. Finally, we conclude by analyzing the mechanistic implications of our approach.

16 Oct 2025
Researchers from the University of Cagliari and University of Trento developed the first fully mechanized formalization of Maximal Extractable Value (MEV) using the Lean 4 theorem prover. Their framework provides machine-checked proofs for exact MEV bounds, including the optimality of sandwich attacks in Automated Market Makers.

23 Sep 2025
Ensuring the correctness of smart contracts is critical, as even subtle flaws can lead to severe financial losses. While bug detection tools able to spot common vulnerability patterns can serve as a first line of defense, most real-world exploits and losses stem from errors in the contract business logic. Formal verification tools such as SolCMC and the Certora Prover address this challenge, but their impact remains limited by steep learning curves and restricted specification languages. Recent works have begun to explore the use of large language models (LLMs) for security-related tasks such as vulnerability detection and test generation. Yet, a fundamental question remains open: can LLMs serve as verification oracles, capable of reasoning about arbitrary contract-specific properties? In this paper, we provide the first systematic evaluation of GPT-5, a state-of-the-art reasoning LLM, in this role. We benchmark its performance on a large dataset of verification tasks, compare its outputs against those of established formal verification tools, and assess its practical effectiveness in real-world auditing scenarios. Our study combines quantitative metrics with qualitative analysis, and shows that recent reasoning-oriented LLMs can be surprisingly effective as verification oracles, suggesting a new frontier in the convergence of AI and formal methods for secure smart contract development and auditing.

13 Oct 2025
To address the extremely concerning problem of software vulnerability, system security is often entrusted to Machine Learning (ML) algorithms. Despite their now established detection capabilities, such models are limited by design to flagging the entire input source code function as vulnerable, rather than precisely localizing the concerned code lines. However, the detection granularity is crucial to support human operators during software development, ensuring that such predictions reflect the true code semantics to help debug, evaluate, and fix the detected vulnerabilities. To address this issue, recent work made progress toward improving the detector's localization ability, thus narrowing down the vulnerability detection "window" and providing more fine-grained predictions. Such approaches, however, implicitly disregard the presence of spurious correlations and biases in the data, which often predominantly influence the performance of ML algorithms. In this work, we investigate how detectors comply with this requirement by proposing an explainability-based evaluation procedure. Our approach, defined as Detection Alignment (DA), quantifies the agreement between the input source code lines that most influence the prediction and the actual localization of the vulnerability as per the ground truth. Through DA, which is model-agnostic and adaptable to different detection tasks, not limited to our use case, we analyze multiple learning-based vulnerability detectors and datasets. As a result, we show how the predictions of such models are consistently biased by non-vulnerable lines, ultimately highlighting the high impact of biases and spurious correlations. The code is available at this https URL.

03 Jul 2023
In the current digitalization era, capturing and effectively representing knowledge is crucial in most real-world scenarios. In this context, knowledge graphs represent a potent tool for retrieving and organizing a vast amount of information in a properly interconnected and interpretable structure. However, their generation is still challenging and often requires considerable human effort and domain expertise, hampering the scalability and flexibility across different application fields. This paper proposes an innovative knowledge graph generation approach that leverages the potential of the latest generative large language models, such as GPT-3.5, that can address all the main critical issues in knowledge graph building. The approach is conveyed in a pipeline that comprises novel iterative zero-shot and external knowledge-agnostic strategies in the main stages of the generation process. Our unique manifold approach may encompass significant benefits to the scientific community. In particular, the main contribution can be summarized by: (i) an innovative strategy for iteratively prompting large language models to extract relevant components of the final graph; (ii) a zero-shot strategy for each prompt, meaning that there is no need for providing examples for "guiding" the prompt result; (iii) a scalable solution, as the adoption of LLMs avoids the need for any external resources or human expertise. To assess the effectiveness of our proposed model, we performed experiments on a dataset that covered a specific domain. We claim that our proposal is a suitable solution for scalable and versatile knowledge graph construction and may be applied to different and novel contexts.

25 Sep 2025
Class-incremental learning (CIL) poses significant challenges in open-world scenarios, where models must not only learn new classes over time without forgetting previous ones but also handle inputs from unknown classes that a closed-set model would misclassify. Recent works address both issues by (i)~training multi-head models using the task-incremental learning framework, and (ii) predicting the task identity employing out-of-distribution (OOD) detectors. While effective, the latter mainly relies on joint training with a memory buffer of past data, raising concerns around privacy, scalability, and increased training time. In this paper, we present an in-depth analysis of post-hoc OOD detection methods and investigate their potential to eliminate the need for a memory buffer. We uncover that these methods, when applied appropriately at inference time, can serve as a strong substitute for buffer-based OOD detection. We show that this buffer-free approach achieves comparable or superior performance to buffer-based methods both in terms of class-incremental learning and the rejection of unknown samples. Experimental results on CIFAR-10, CIFAR-100 and Tiny ImageNet datasets support our findings, offering new insights into the design of efficient and privacy-preserving CIL systems for open-world settings.

28 Sep 2021


As machine learning becomes widely used for automated decisions, attackers have strong incentives to manipulate the results and models generated by machine learning algorithms. In this paper, we perform the first systematic study of poisoning attacks and their countermeasures for linear regression models. In poisoning attacks, attackers deliberately influence the training data to manipulate the results of a predictive model. We propose a theoretically-grounded optimization framework specifically designed for linear regression and demonstrate its effectiveness on a range of datasets and models. We also introduce a fast statistical attack that requires limited knowledge of the training process. Finally, we design a new principled defense method that is highly resilient against all poisoning attacks. We provide formal guarantees about its convergence and an upper bound on the effect of poisoning attacks when the defense is deployed. We evaluate extensively our attacks and defenses on three realistic datasets from health care, loan assessment, and real estate domains.

17 Sep 2025
Digital beautification through social media filters has become increasingly popular, raising concerns about the reliability of facial images and videos and the effectiveness of automated face analysis. This issue is particularly critical for digital manipulation detectors, systems aiming at distinguishing between genuine and manipulated data, especially in cases involving deepfakes and morphing attacks designed to deceive humans and automated facial recognition. This study examines whether beauty filters impact the performance of deepfake and morphing attack detectors. We perform a comprehensive analysis, evaluating multiple state-of-the-art detectors on benchmark datasets before and after applying various smoothing filters. Our findings reveal performance degradation, highlighting vulnerabilities introduced by facial enhancements and underscoring the need for robust detection models resilient to such alterations.

26 May 2022
Boolean operations are among the most used paradigms to create and edit
digital shapes. Despite being conceptually simple, the computation of mesh
Booleans is notoriously challenging. Main issues come from numerical
approximations that make the detection and processing of intersection points
inconsistent and unreliable, exposing implementations based on floating point
arithmetic to many kinds of degeneracy and failure. Numerical methods based on
rational numbers or exact geometric predicates have the needed robustness
guarantees, that are achieved at the cost of increased computation times that,
as of today, has always restricted the use of robust mesh Booleans to offline
applications. We introduce the first algorithm for Boolean operations with
robustness guarantees that is capable of operating at interactive frame rates
on meshes with up to 200K triangles. We evaluate our tool thoroughly,
considering not only interactive applications but also batch processing of
large collections of meshes, processing of huge meshes containing millions of
elements and variadic Booleans of hundreds of shapes altogether. In all these
experiments, we consistently outperform prior art by at least one order of
magnitude.

09 Jun 2025
Researchers from multiple Italian and German universities introduce RAID, the first dataset specifically designed to test the adversarial robustness of AI-generated image detectors using transferable adversarial examples. Their work demonstrates that current state-of-the-art detectors are highly susceptible to adversarial manipulation, even in black-box scenarios, with performance often collapsing to near-random chance.

03 Oct 2025
To promote climate adaptation and mitigation, it is crucial to understand stakeholder perspectives and knowledge gaps on land use and climate changes. Stakeholders across 21 European islands were consulted on climate and land use change issues affecting ecosystem services. Climate change perceptions included temperature, precipitation, humidity, extremes, and wind. Land use change perceptions included deforestation, coastal degradation, habitat protection, renewable energy facilities, wetlands, and others. Additional concerns such as invasive species, water or energy scarcity, infrastructure problems, and austerity were also considered. Climate and land use change impact perceptions were analysed with machine learning to quantify their influence. The predominant climatic characteristic is temperature, and the predominant land use characteristic is deforestation. Water-related problems are top priorities for stakeholders. Energy-related problems, including energy deficiency and issues with wind and solar facilities, rank high as combined climate and land use risks. Stakeholders generally perceive climate change impacts on ecosystem services as negative, with natural habitat destruction and biodiversity loss identified as top issues. Land use change impacts are also negative but more complex, with more explanatory variables. Stakeholders share common perceptions on biodiversity impacts despite geographic disparity, but they differentiate between climate and land use impacts. Water, energy, and renewable energy issues pose serious concerns, requiring management measures.

16 Oct 2025
According to a recent EUROPOL report, cybercrime is still recurrent in Europe, and different activities and countermeasures must be taken to limit, prevent, detect, analyze, and fight it. Cybercrime must be prevented with specific measures, tools, and techniques, for example through automated network and malware analysis. Countermeasures against cybercrime can also be improved with proper \df analysis in order to extract data from digital devices trying to retrieve information on the cybercriminals. Indeed, results obtained through a proper \df analysis can be leveraged to train cybercrime detection systems to prevent the success of similar crimes. Nowadays, some systems have started to adopt Artificial Intelligence (AI) algorithms for cyberattack detection and \df analysis improvement. However, AI can be better applied as an additional instrument in these systems to improve the detection and in the \df analysis. For this reason, we highlight how cybercrime analysis and \df procedures can take advantage of AI. On the other hand, cybercriminals can use these systems to improve their skills, bypass automatic detection, and develop advanced attack techniques. The case study we presented highlights how it is possible to integrate the use of the three popular chatbots {\tt Gemini}, {\tt Copilot} and {\tt chatGPT} to develop a Python code to encode and decoded images with steganographic technique, even though their presence is not an indicator of crime, attack or maliciousness but used by a cybercriminal as anti-forensics technique.

27 Aug 2024

Numerous methods and pipelines have recently emerged for the automatic
extraction of knowledge graphs from documents such as scientific publications
and patents. However, adapting these methods to incorporate alternative text
sources like micro-blogging posts and news has proven challenging as they
struggle to model open-domain entities and relations, typically found in these
sources. In this paper, we propose an enhanced information extraction pipeline
tailored to the extraction of a knowledge graph comprising open-domain entities
from micro-blogging posts on social media platforms. Our pipeline leverages
dependency parsing and classifies entity relations in an unsupervised manner
through hierarchical clustering over word embeddings. We provide a use case on
extracting semantic triples from a corpus of 100 thousand tweets about digital
transformation and publicly release the generated knowledge graph. On the same
dataset, we conduct two experimental evaluations, showing that the system
produces triples with precision over 95% and outperforms similar pipelines of
around 5% in terms of precision, while generating a comparatively higher number
of triples.

10 Mar 2016
Modern malware is designed with mutation characteristics, namely polymorphism
and metamorphism, which causes an enormous growth in the number of variants of
malware samples. Categorization of malware samples on the basis of their
behaviors is essential for the computer security community, because they
receive huge number of malware everyday, and the signature extraction process
is usually based on malicious parts characterizing malware families. Microsoft
released a malware classification challenge in 2015 with a huge dataset of near
0.5 terabytes of data, containing more than 20K malware samples. The analysis
of this dataset inspired the development of a novel paradigm that is effective
in categorizing malware variants into their actual family groups. This paradigm
is presented and discussed in the present paper, where emphasis has been given
to the phases related to the extraction, and selection of a set of novel
features for the effective representation of malware samples. Features can be
grouped according to different characteristics of malware behavior, and their
fusion is performed according to a per-class weighting paradigm. The proposed
method achieved a very high accuracy ( 0.998) on the Microsoft Malware
Challenge dataset.

17 Dec 2024
Large language models (LLMs) have shown promising capabilities in healthcare
analysis but face several challenges like hallucinations, parroting, and bias
manifestation. These challenges are exacerbated in complex, sensitive, and
low-resource domains. Therefore, in this work we introduce IC-AnnoMI, an
expert-annotated motivational interviewing (MI) dataset built upon AnnoMI by
generating in-context conversational dialogues leveraging LLMs, particularly
ChatGPT. IC-AnnoMI employs targeted prompts accurately engineered through cues
and tailored information, taking into account therapy style (empathy,
reflection), contextual relevance, and false semantic change. Subsequently, the
dialogues are annotated by experts, strictly adhering to the Motivational
Interviewing Skills Code (MISC), focusing on both the psychological and
linguistic dimensions of MI dialogues. We comprehensively evaluate the
IC-AnnoMI dataset and ChatGPT's emotional reasoning ability and understanding
of domain intricacies by modeling novel classification tasks employing several
classical machine learning and current state-of-the-art transformer approaches.
Finally, we discuss the effects of progressive prompting strategies and the
impact of augmented data in mitigating the biases manifested in IC-AnnoM. Our
contributions provide the MI community with not only a comprehensive dataset
but also valuable insights for using LLMs in empathetic text generation for
conversational therapy in supervised settings.

19 Jun 2024

ModSec-Learn enhances the ModSecurity Web Application Firewall by integrating machine learning, leveraging OWASP CRS rules as features to automatically learn their optimal relevance. This approach substantially improves SQL injection detection, achieving over 99% True Positive Rate at 1% False Positive Rate, and enables efficient rule set optimization through sparse regularization.

25 Oct 2024
Dynamic analysis enables detecting Windows malware by executing programs in a controlled environment and logging their actions. Previous work has proposed training machine learning models, i.e., convolutional and long short-term memory networks, on homogeneous input features like runtime APIs to either detect or classify malware, neglecting other relevant information coming from heterogeneous data like network and file operations. To overcome these issues, we introduce Nebula, a versatile, self-attention Transformer-based neural architecture that generalizes across different behavioral representations and formats, combining diverse information from dynamic log reports. Nebula is composed by several components needed to tokenize, filter, normalize and encode data to feed the transformer architecture. We firstly perform a comprehensive ablation study to evaluate their impact on the performance of the whole system, highlighting which components can be used as-is, and which must be enriched with specific domain knowledge. We perform extensive experiments on both malware detection and classification tasks, using three datasets acquired from different dynamic analyses platforms, show that, on average, Nebula outperforms state-of-the-art models at low false positive rates, with a peak of 12% improvement. Moreover, we showcase how self-supervised learning pre-training matches the performance of fully-supervised models with only 20% of training data, and we inspect the output of Nebula through explainable AI techniques, pinpointing how attention is focusing on specific tokens correlated to malicious activities of malware families. To foster reproducibility, we open-source our findings and models at this https URL.

22 Aug 2025
Red blood cells (RBCs) are essential to human health, and their precise morphological analysis is important for diagnosing hematological disorders. Despite the promise of foundation models in medical diagnostics, comprehensive AI solutions for RBC analysis remain scarce. We present RedDino, a self-supervised foundation model designed for RBC image analysis. RedDino uses an RBC-specific adaptation of the DINOv2 self-supervised learning framework and is trained on a curated dataset of 1.25 million RBC images from diverse acquisition modalities and sources. Extensive evaluations show that RedDino outperforms existing state-of-the-art models on RBC shape classification. Through assessments including linear probing and nearest neighbor classification, we confirm its strong feature representations and generalization ability. Our main contributions are: (1) a foundation model tailored for RBC analysis, (2) ablation studies exploring DINOv2 configurations for RBC modeling, and (3) a detailed evaluation of generalization performance. RedDino addresses key challenges in computational hematology by capturing nuanced morphological features, advancing the development of reliable diagnostic tools. The source code and pretrained models for RedDino are available at this https URL, and the pretrained models can be downloaded from our Hugging Face collection at this https URL

08 Mar 2024
The recent success of machine learning (ML) has been fueled by the increasing availability of computing power and large amounts of data in many different applications. However, the trustworthiness of the resulting models can be compromised when such data is maliciously manipulated to mislead the learning process. In this article, we first review poisoning attacks that compromise the training data used to learn ML models, including attacks that aim to reduce the overall performance, manipulate the predictions on specific test samples, and even implant backdoors in the model. We then discuss how to mitigate these attacks using basic security principles, or by deploying ML-oriented defensive mechanisms. We conclude our article by formulating some relevant open challenges which are hindering the development of testing methods and benchmarks suitable for assessing and improving the trustworthiness of ML models against data poisoning attacks
There are no more papers matching your filters at the moment.
