
14 Jan 2023
 the University of TokyoKeio University
the University of TokyoKeio University Queen Mary University of LondonThe University of Electro-CommunicationsRitsumeikan UniversityUniversity of EssexDonders Institute for Brain, Cognition, and BehaviourBogazici UniversityNational Autonomous University of MexicoCajal International Neuroscience CenterUniversità Milano-BicoccaUniversidad Autónoma del Estado de MorelosInstitute of Cognitive Sciences and Technologies, National Research Council of Italy
Queen Mary University of LondonThe University of Electro-CommunicationsRitsumeikan UniversityUniversity of EssexDonders Institute for Brain, Cognition, and BehaviourBogazici UniversityNational Autonomous University of MexicoCajal International Neuroscience CenterUniversità Milano-BicoccaUniversidad Autónoma del Estado de MorelosInstitute of Cognitive Sciences and Technologies, National Research Council of Italy
An international consortium of researchers provides a comprehensive survey unifying the concepts of world models from AI and predictive coding from neuroscience, highlighting their shared principles for how agents build and use internal representations to predict and interact with their environment. The paper outlines six key research frontiers for integrating these two fields to advance cognitive and developmental robotics, offering a roadmap for creating more intelligent and adaptable robots.

15 Oct 2025

This work introduces training-free metrics (Ratio Spread, Similarity Distribution, and Statistical Uncertainty) that analyze Visual Place Recognition (VPR) similarity scores to estimate uncertainty. These metrics offer robust and computationally efficient uncertainty quantification for VPR systems, achieving high accuracy in distinguishing correct from incorrect matches across diverse VPR architectures and challenging datasets.

12 Sep 2025

In the upcoming 6G networks, integrated sensing and communications (ISAC) will be able to provide a performance boost in both perception and wireless connectivity. This paper considers a multiple base station (BS) architecture to support the comprehensive services of data transmission and multi-target sensing. In this context, a cooperative BS assignment and resource allocation (CBARA) strategy is proposed in this paper, aiming at jointly optimizing the communication and sensing (C&S) performance. The posterior Cramer-Rao lower bound and the achievable rate with respect to transmit power and bandwidth are derived and utilized as optimization criteria for the CBARA scheme. We develop a heuristic alternating optimization algorithm to obtain an effective sub-optimal solution for the non-convex optimization problem caused by multiple coupled variables. Numerical results show the effectiveness of the proposed solution, which achieves a performance improvement of 117% in communication rate and 40% in sensing accuracy, compared to the classic scheme.

25 Aug 2025
Understanding the dynamic organization and homeostasis of living tissues requires high-resolution, time-resolved imaging coupled with methods capable of extracting interpretable, predictive insights from complex datasets. Here, we present the Vision Transformer Digital Twin Surrogate Network (VT-DTSN), a deep learning framework for predictive modeling of 3D+T imaging data from biological tissue. By leveraging Vision Transformers pretrained with DINO (Self-Distillation with NO Labels) and employing a multi-view fusion strategy, VT-DTSN learns to reconstruct high-fidelity, time-resolved dynamics of a Drosophila midgut while preserving morphological and feature-level integrity across imaging depths. The model is trained with a composite loss prioritizing pixel-level accuracy, perceptual structure, and feature-space alignment, ensuring biologically meaningful outputs suitable for in silico experimentation and hypothesis testing. Evaluation across layers and biological replicates demonstrates VT-DTSN's robustness and consistency, achieving low error rates and high structural similarity while maintaining efficient inference through model optimization. This work establishes VT-DTSN as a feasible, high-fidelity surrogate for cross-timepoint reconstruction and for studying tissue dynamics, enabling computational exploration of cellular behaviors and homeostasis to complement time-resolved imaging studies in biological research.

26 Sep 2025
Large language model (LLM) agents typically adopt a step-by-step reasoning framework, in which they interleave the processes of thinking and acting to accomplish the given task. However, this paradigm faces a deep-rooted one-pass issue whereby each generated intermediate thought is plugged into the trajectory regardless of its correctness, which can cause irreversible error propagation. To address the issue, this paper proposes a novel framework called Generator-Assistant Stepwise Rollback (GA-Rollback) to induce better decision-making for LLM agents. Particularly, GA-Rollback utilizes a generator to interact with the environment and an assistant to examine each action produced by the generator, where the assistant triggers a rollback operation upon detection of incorrect actions. Moreover, we introduce two additional strategies tailored for the rollback scenario to further improve its effectiveness. Extensive experiments show that GA-Rollback achieves significant improvements over several strong baselines on three widely used benchmarks. Our analysis further reveals that GA-Rollback can function as a robust plug-and-play module, integrating seamlessly with other methods.

04 Aug 2024
An approach to multimodal semantic communication (LAM-MSC) leverages large AI models for unifying diverse data types, personalizing semantic interpretation, and robustly estimating wireless channels. Simulations indicate the framework achieves high compression rates and maintains robust performance.
07 Dec 2024
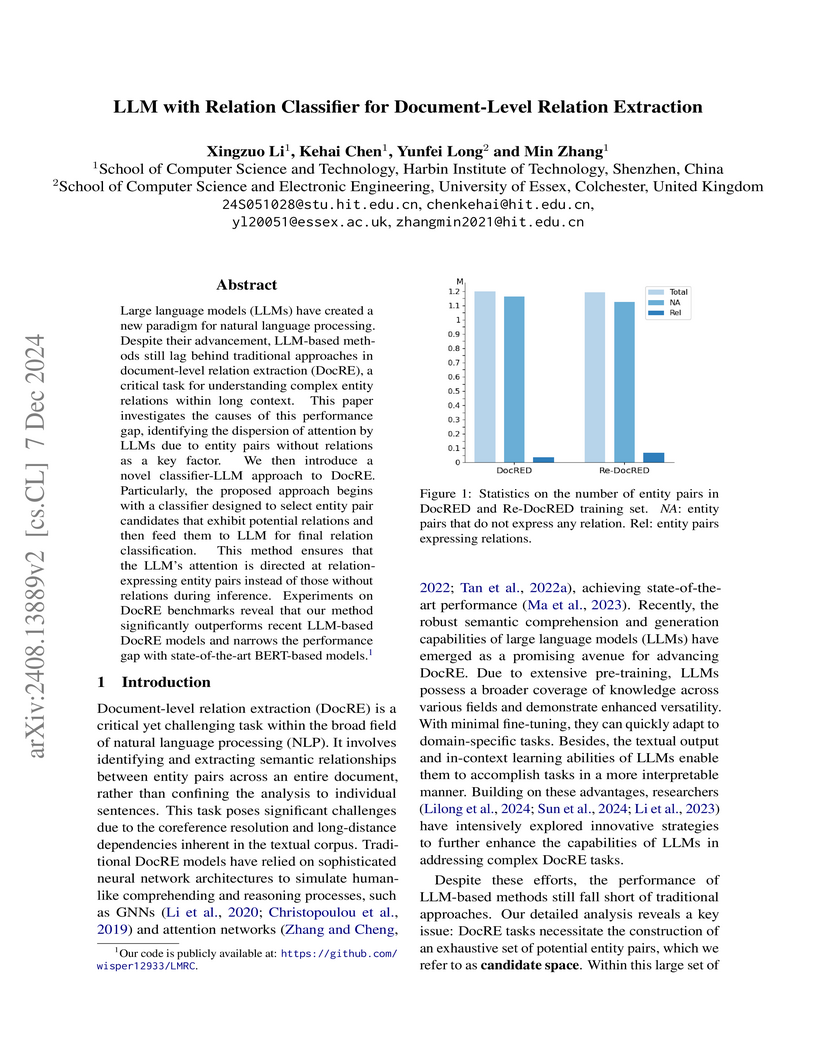
Large language models (LLMs) have created a new paradigm for natural language
processing. Despite their advancement, LLM-based methods still lag behind
traditional approaches in document-level relation extraction (DocRE), a
critical task for understanding complex entity relations within long context.
This paper investigates the causes of this performance gap, identifying the
dispersion of attention by LLMs due to entity pairs without relations as a key
factor. We then introduce a novel classifier-LLM approach to DocRE.
Particularly, the proposed approach begins with a classifier designed to select
entity pair candidates that exhibit potential relations and then feed them to
LLM for final relation classification. This method ensures that the LLM's
attention is directed at relation-expressing entity pairs instead of those
without relations during inference. Experiments on DocRE benchmarks reveal that
our method significantly outperforms recent LLM-based DocRE models and narrows
the performance gap with state-of-the-art BERT-based models.

10 Apr 2025

Following the widespread adoption of ChatGPT in early 2023, numerous studies
reported that large language models (LLMs) can match or even surpass human
performance in creative tasks. However, it remains unclear whether LLMs have
become more creative over time, and how consistent their creative output is. In
this study, we evaluated 14 widely used LLMs -- including GPT-4, Claude, Llama,
Grok, Mistral, and DeepSeek -- across two validated creativity assessments: the
Divergent Association Task (DAT) and the Alternative Uses Task (AUT). Contrary
to expectations, we found no evidence of increased creative performance over
the past 18-24 months, with GPT-4 performing worse than in previous studies.
For the more widely used AUT, all models performed on average better than the
average human, with GPT-4o and o3-mini performing best. However, only 0.28% of
LLM-generated responses reached the top 10% of human creativity benchmarks.
Beyond inter-model differences, we document substantial intra-model
variability: the same LLM, given the same prompt, can produce outputs ranging
from below-average to original. This variability has important implications for
both creativity research and practical applications. Ignoring such variability
risks misjudging the creative potential of LLMs, either inflating or
underestimating their capabilities. The choice of prompts affected LLMs
differently. Our findings underscore the need for more nuanced evaluation
frameworks and highlight the importance of model selection, prompt design, and
repeated assessment when using Generative AI (GenAI) tools in creative
contexts.

18 Jun 2024

Automated medical image analysis systems often require large amounts of training data with high quality labels, which are difficult and time consuming to generate. This paper introduces Radiology Object in COntext version 2 (ROCOv2), a multimodal dataset consisting of radiological images and associated medical concepts and captions extracted from the PMC Open Access subset. It is an updated version of the ROCO dataset published in 2018, and adds 35,705 new images added to PMC since 2018. It further provides manually curated concepts for imaging modalities with additional anatomical and directional concepts for X-rays. The dataset consists of 79,789 images and has been used, with minor modifications, in the concept detection and caption prediction tasks of ImageCLEFmedical Caption 2023. The dataset is suitable for training image annotation models based on image-caption pairs, or for multi-label image classification using Unified Medical Language System (UMLS) concepts provided with each image. In addition, it can serve for pre-training of medical domain models, and evaluation of deep learning models for multi-task learning.

28 Apr 2025

PhenoAssistant is an open-source, conversational multi-agent AI system developed to automate complex plant phenotyping analyses using natural language interactions. It significantly lowers technical barriers for plant scientists by orchestrating specialized computer vision models and LLM agents, achieving high success rates in tasks like data analysis and vision model selection across diverse plant species.

03 Nov 2025
Large Language Models (LLMs) have demonstrated remarkable instruction-following capabilities across various applications. However, their performance in multilingual settings lacks systematic investigation, with existing evaluations lacking fine-grained constraint analysis across diverse linguistic contexts. We introduce XIFBench, a comprehensive constraint-based benchmark for evaluating multilingual instruction-following abilities of LLMs, comprising 558 instructions with 0-5 additional constraints across five categories (Content, Style, Situation, Format, and Numerical) in six languages spanning different resource levels. To support reliable and consistent cross-lingual evaluation, we implement three methodological innovations: cultural accessibility annotation, constraint-level translation validation, and requirement-based evaluation using English requirements as semantic anchors across languages. Extensive experiments with various LLMs not only quantify performance disparities across resource levels but also provide detailed insights into how language resources, constraint categories, instruction complexity, and cultural specificity influence multilingual instruction-following. Our code and data are available at this https URL.

03 Aug 2024
Semantic communication (SC) is an emerging intelligent paradigm, offering solutions for various future applications like metaverse, mixed reality, and the Internet of Everything. However, in current SC systems, the construction of the knowledge base (KB) faces several issues, including limited knowledge representation, frequent knowledge updates, and insecure knowledge sharing. Fortunately, the development of the large AI model (LAM) provides new solutions to overcome the above issues. Here, we propose a LAM-based SC framework (LAM-SC) specifically designed for image data, where we first apply the segment anything model (SAM)-based KB (SKB) that can split the original image into different semantic segments by universal semantic knowledge. Then, we present an attention-based semantic integration (ASI) to weigh the semantic segments generated by SKB without human participation and integrate them as the semantic aware image. Additionally, we propose an adaptive semantic compression (ASC) encoding to remove redundant information in semantic features, thereby reducing communication overhead. Finally, through simulations, we demonstrate the effectiveness of the LAM-SC framework and the possibility of applying the LAM-based KB in future SC paradigms.

13 Jun 2025
GraphRAG-Causal introduces an innovative framework that combines graph-based
retrieval with large language models to enhance causal reasoning in news
analysis. Traditional NLP approaches often struggle with identifying complex,
implicit causal links, especially in low-data scenarios. Our approach addresses
these challenges by transforming annotated news headlines into structured
causal knowledge graphs. It then employs a hybrid retrieval system that merges
semantic embeddings with graph-based structural cues leveraging Neo4j to
accurately match and retrieve relevant events. The framework is built on a
three-stage pipeline: First, during Data Preparation, news sentences are
meticulously annotated and converted into causal graphs capturing cause,
effect, and trigger relationships. Next, the Graph Retrieval stage stores these
graphs along with their embeddings in a Neo4j database and utilizes hybrid
Cypher queries to efficiently identify events that share both semantic and
structural similarities with a given query. Finally, the LLM Inference stage
utilizes these retrieved causal graphs in a few-shot learning setup with
XML-based prompting, enabling robust classification and tagging of causal
relationships. Experimental evaluations demonstrate that GraphRAG-Causal
achieves an impressive F1-score of 82.1% on causal classification using just 20
few-shot examples. This approach significantly boosts accuracy and consistency,
making it highly suitable for real-time applications in news reliability
assessment, misinformation detection, and policy analysis.

21 Mar 2023
A widespread view is that Artificial Intelligence cannot be creative. We tested this assumption by comparing human-generated ideas with those generated by six Generative Artificial Intelligence (GAI) chatbots: , , ChatGPT (versions 3 and 4), , and YouChat. Humans and a specifically trained AI independently assessed the quality and quantity of ideas. We found no qualitative difference between AI and human-generated creativity, although there are differences in how ideas are generated. Interestingly, 9.4 percent of humans were more creative than the most creative GAI, GPT-4. Our findings suggest that GAIs are valuable assistants in the creative process. Continued research and development of GAI in creative tasks is crucial to fully understand this technology's potential benefits and drawbacks in shaping the future of creativity. Finally, we discuss the question of whether GAIs are capable of being truly creative.

19 Dec 2020

Algebraic codes such as BCH code are receiving renewed interest as their
short block lengths and low/no error floors make them attractive for
ultra-reliable low-latency communications (URLLC) in 5G wireless networks. This
paper aims at enhancing the traditional adaptive belief propagation (ABP)
decoding, which is a soft-in-soft-out (SISO) decoding for high-density
parity-check (HDPC) algebraic codes, such as Reed-Solomon (RS) codes,
Bose-Chaudhuri-Hocquenghem (BCH) codes, and product codes. The key idea of
traditional ABP is to sparsify certain columns of the parity-check matrix
corresponding to the least reliable bits with small log-likelihood-ratio (LLR)
values. This sparsification strategy may not be optimal when some bits have
large LLR magnitudes but wrong signs. Motivated by this observation, we propose
a Perturbed ABP (P-ABP) to incorporate a small number of unstable bits with
large LLRs into the sparsification operation of the parity-check matrix. In
addition, we propose to apply partial layered scheduling or hybrid dynamic
scheduling to further enhance the performance of P-ABP. Simulation results show
that our proposed decoding algorithms lead to improved error correction
performances and faster convergence rates than the prior-art ABP variants.

28 Aug 2025
Financial markets can be highly sensitive to news, investor sentiment, and economic indicators, leading to important asset price fluctuations. In this study we focus on crude oil, due to its crucial role in commodity markets and the global economy. Specifically, we are interested in understanding the directional changes of oil price volatility, and for this purpose we investigate whether news alone -- without incorporating traditional market data -- can effectively predict the direction of oil price movements. Using a decade-long dataset from Eikon (2014-2024), we develop an ensemble learning framework to extract predictive signals from financial news. Our approach leverages diverse sentiment analysis techniques and modern language models, including FastText, FinBERT, Gemini, and LLaMA, to capture market sentiment and textual patterns. We benchmark our model against the Heterogeneous Autoregressive (HAR) model and assess statistical significance using the McNemar test. While most sentiment-based indicators do not consistently outperform HAR, the raw news count emerges as a robust predictor. Among embedding techniques, FastText proves most effective for forecasting directional movements. Furthermore, SHAP-based interpretation at the word level reveals evolving predictive drivers across market regimes: pre-pandemic emphasis on supply-demand and economic terms; early pandemic focus on uncertainty and macroeconomic instability; post-shock attention to long-term recovery indicators; and war-period sensitivity to geopolitical and regional oil market disruptions. These findings highlight the predictive power of news-driven features and the value of explainable NLP in financial forecasting.

15 Sep 2025

Language and embodied perspective taking are essential for human collaboration, yet few computational models address both simultaneously. This work investigates the PerspAct system [1], which integrates the ReAct (Reason and Act) paradigm with Large Language Models (LLMs) to simulate developmental stages of perspective taking, grounded in Selman's theory [2]. Using an extended director task, we evaluate GPT's ability to generate internal narratives aligned with specified developmental stages, and assess how these influence collaborative performance both qualitatively (action selection) and quantitatively (task efficiency). Results show that GPT reliably produces developmentally-consistent narratives before task execution but often shifts towards more advanced stages during interaction, suggesting that language exchanges help refine internal representations. Higher developmental stages generally enhance collaborative effectiveness, while earlier stages yield more variable outcomes in complex contexts. These findings highlight the potential of integrating embodied perspective taking and language in LLMs to better model developmental dynamics and stress the importance of evaluating internal speech during combined linguistic and embodied tasks.

01 Mar 2024
In this paper, we propose a deep learning based model for Acoustic Anomaly
Detection of Machines, the task for detecting abnormal machines by analysing
the machine sound. By conducting extensive experiments, we indicate that
multiple techniques of pseudo audios, audio segment, data augmentation,
Mahalanobis distance, and narrow frequency bands, which mainly focus on feature
engineering, are effective to enhance the system performance. Among the
evaluating techniques, the narrow frequency bands presents a significant
impact. Indeed, our proposed model, which focuses on the narrow frequency
bands, outperforms the DCASE baseline on the benchmark dataset of DCASE 2022
Task 2 Development set. The important role of the narrow frequency bands
indicated in this paper inspires the research community on the task of Acoustic
Anomaly Detection of Machines to further investigate and propose novel network
architectures focusing on the frequency bands.

16 Sep 2025
A particularly intriguing and unique feature of fractional dynamical systems is the cascade of bifurcations type trajectories (CBTT). We examine the CBTTs in a generalized version of the standard map that incorporates the Riemann-Liouville fractional derivative, known as the Riemann-Liouville Fractional Standard Map (RLFSM). We propose a methodology that uses two quantifiers based solely on the system's time series: the Hurst exponent and the recurrence time entropy, for characterizing such dynamics. This approach allows us to effectively characterize the dynamics of the RLFSM, including regions of CBTT and chaotic behavior. Our analysis demonstrates that regions of CBTT are associated with trajectories that exhibit lower values of these quantifiers compared to strong chaotic regions, indicating weakly chaotic dynamics during the CBTTs.

02 Apr 2025

Graph-based personality detection constructs graph structures from textual
data, particularly social media posts. Current methods often struggle with
sparse or noisy data and rely on static graphs, limiting their ability to
capture dynamic changes between nodes and relationships. This paper introduces
LL4G, a self-supervised framework leveraging large language models (LLMs) to
optimize graph neural networks (GNNs). LLMs extract rich semantic features to
generate node representations and to infer explicit and implicit relationships.
The graph structure adaptively adds nodes and edges based on input data,
continuously optimizing itself. The GNN then uses these optimized
representations for joint training on node reconstruction, edge prediction, and
contrastive learning tasks. This integration of semantic and structural
information generates robust personality profiles. Experimental results on
Kaggle and Pandora datasets show LL4G outperforms state-of-the-art models.
There are no more papers matching your filters at the moment.
