
08 Dec 2025
Utilizing multi-band JWST observations, this research reveals that high-redshift submillimeter galaxies primarily form through secular evolution and internal processes rather than major mergers, uncovering a significant population of central stellar structures that do not conform to established local galaxy classifications.

16 Oct 2025
Researchers at the Chinese Academy of Sciences developed QDepth-VLA, a framework that enhances Vision-Language-Action (VLA) models with robust 3D geometric understanding through quantized depth prediction as auxiliary supervision. This approach improves performance on fine-grained robotic manipulation tasks, achieving up to 29.7% higher success rates on complex simulated tasks and 20.0% gains in real-world pick-and-place scenarios compared to existing baselines.

13 Oct 2025
Researchers from the Chinese Academy of Sciences and collaborating institutions developed InstructSAM, a training-free framework for instruction-oriented remote sensing object counting, detection, and segmentation. It combines large vision-language models, SAM2, and CLIP with a novel counting-constrained mask-label matching, enabling robust performance on diverse tasks and reducing inference time by over 32% compared to generative VLM methods.

11 Jun 2024

Developed by Huawei Co., Ltd., CODER introduces a multi-agent framework guided by pre-defined task graphs to automate GitHub issue resolution. The system achieved a 28.33% resolved rate on SWE-bench lite, establishing a new state-of-the-art for the benchmark.

01 Oct 2025


While Large Language Models (LLMs) have become the predominant paradigm for automated code generation, current single-model approaches fundamentally ignore the heterogeneous computational strengths that different models exhibit across programming languages, algorithmic domains, and development stages. This paper challenges the single-model convention by introducing a multi-stage, performance-guided orchestration framework that dynamically routes coding tasks to the most suitable LLMs within a structured generate-fix-refine workflow. Our approach is grounded in a comprehensive empirical study of 17 state-of-the-art LLMs across five programming languages (Python, Java, C++, Go, and Rust) using HumanEval-X benchmark. The study, which evaluates both functional correctness and runtime performance metrics (execution time, mean/max memory utilization, and CPU efficiency), reveals pronounced performance heterogeneity by language, development stage, and problem category. Guided by these empirical insights, we present PerfOrch, an LLM agent that orchestrates top-performing LLMs for each task context through stage-wise validation and rollback mechanisms. Without requiring model fine-tuning, PerfOrch achieves substantial improvements over strong single-model baselines: average correctness rates of 96.22% and 91.37% on HumanEval-X and EffiBench-X respectively, surpassing GPT-4o's 78.66% and 49.11%. Beyond correctness gains, the framework delivers consistent performance optimizations, improving execution time for 58.76% of problems with median speedups ranging from 17.67% to 27.66% across languages on two benchmarks. The framework's plug-and-play architecture ensures practical scalability, allowing new LLMs to be profiled and integrated seamlessly, thereby offering a paradigm for production-grade automated software engineering that adapts to the rapidly evolving generative AI landscape.

01 Apr 2025

Researchers developed LARF (Let AI Read First), an AI-powered system leveraging GPT-4 to annotate important information in texts with visual cues, improving reading performance and subjective experience for individuals with dyslexia, particularly those with more severe conditions. The system enhanced objective detail retrieval and comprehension while preserving original content.

07 Dec 2025
 Chinese Academy of Sciences
Chinese Academy of Sciences Fudan University
Fudan University University of Science and Technology of China
University of Science and Technology of China Shanghai Jiao Tong UniversityAerospace Information Research InstituteInstitute of Trustworthy Embodied AI, Fudan UniversityKey Laboratory of Target Cognition and Application Technology, Aerospace Information Research Institute, Chinese Academy of Sciences
Shanghai Jiao Tong UniversityAerospace Information Research InstituteInstitute of Trustworthy Embodied AI, Fudan UniversityKey Laboratory of Target Cognition and Application Technology, Aerospace Information Research Institute, Chinese Academy of SciencesResearchers from Fudan University and Shanghai Jiao Tong University established a spatial retrieval augmented autonomous driving paradigm, integrating offline geographic images to enhance autonomous vehicle robustness. This approach boosted online mapping performance by up to 11.9% mAP and reduced collision rates in planning, particularly under challenging conditions.

27 Feb 2025
Landslides are among the most common natural disasters globally, posing
significant threats to human society. Deep learning (DL) has proven to be an
effective method for rapidly generating landslide inventories in large-scale
disaster areas. However, DL models rely heavily on high-quality labeled
landslide data for strong feature extraction capabilities. And landslide
detection using DL urgently needs a benchmark dataset to evaluate the
generalization ability of the latest models. To solve the above problems, we
construct a Large-scale Multi-source High-resolution Landslide Dataset (LMHLD)
for Landslide Detection based on DL. LMHLD collects remote sensing images from
five different satellite sensors across seven study areas worldwide: Wenchuan,
China (2008); Rio de Janeiro, Brazil (2011); Gorkha, Nepal (2015); Jiuzhaigou,
China (2015); Taiwan, China (2018); Hokkaido, Japan (2018); Emilia-Romagna,
Italy (2023). The dataset includes a total of 25,365 patches, with different
patch sizes to accommodate different landslide scales. Additionally, a training
module, LMHLDpart, is designed to accommodate landslide detection tasks at
varying scales and to alleviate the issue of catastrophic forgetting in
multi-task learning. Furthermore, the models trained by LMHLD is applied in
other datasets to highlight the robustness of LMHLD. Five dataset quality
evaluation experiments designed by using seven DL models from the U-Net family
demonstrate that LMHLD has the potential to become a benchmark dataset for
landslide detection. LMHLD is open access and can be accessed through the link:
this https URL This dataset provides a strong
foundation for DL models, accelerates the development of DL in landslide
detection, and serves as a valuable resource for landslide prevention and
mitigation efforts.

30 Sep 2025
PolSAR data presents unique challenges due to its rich and complex characteristics. Existing data representations, such as complex-valued data, polarimetric features, and amplitude images, are widely used. However, these formats often face issues related to usability, interpretability, and data integrity. Most feature extraction networks for PolSAR are small, limiting their ability to capture features effectively. To address these issues, We propose the Polarimetric Scattering Mechanism-Informed SAM (PolSAM), an enhanced Segment Anything Model (SAM) that integrates domain-specific scattering characteristics and a novel prompt generation strategy. PolSAM introduces Microwave Vision Data (MVD), a lightweight and interpretable data representation derived from polarimetric decomposition and semantic correlations. We propose two key components: the Feature-Level Fusion Prompt (FFP), which fuses visual tokens from pseudo-colored SAR images and MVD to address modality incompatibility in the frozen SAM encoder, and the Semantic-Level Fusion Prompt (SFP), which refines sparse and dense segmentation prompts using semantic information. Experimental results on the PhySAR-Seg datasets demonstrate that PolSAM significantly outperforms existing SAM-based and multimodal fusion models, improving segmentation accuracy, reducing data storage, and accelerating inference time. The source code and datasets will be made publicly available at this https URL.

23 Dec 2024

Large Language Models (LLMs) have advanced rapidly in recent years, with their applications in software engineering expanding to more complex repository-level tasks. GitHub issue resolving is a key challenge among these tasks. While recent approaches have made progress on this task, they focus on textual data within issues, neglecting visual data. However, this visual data is crucial for resolving issues as it conveys additional knowledge that text alone cannot. We propose CodeV, the first approach to leveraging visual data to enhance the issue-resolving capabilities of LLMs. CodeV resolves each issue by following a two-phase process: data processing and patch generation. To evaluate CodeV, we construct a benchmark for visual issue resolving, namely Visual SWE-bench. Through extensive experiments, we demonstrate the effectiveness of CodeV, as well as provide valuable insights into leveraging visual data to resolve GitHub issues.

15 Oct 2025
Integrated photonic circuits are foundational for versatile applications, where high-performance traveling-wave optical resonators are critical. Conventional whispering-gallery mode microresonators (WGMRs) confine light in closed-loop waveguide paths, thus inevitably occupy large footprints. Here, we report an ultracompact high loaded Q silicon photonic WGMR in an open curved path instead. By leveraging spatial mode multiplexing, low-loss mode converter-based photonic routers enable reentrant photon recycling in a single non-closed waveguide. The fabricated device achieves a measured loaded Q-factor of 1.78*10^5 at 1554.3 nm with a 1.05 nm free spectral range in a ultracompact footprint of 0.00137 mm^2-6*smaller than standard WGMRs while delivering 100*higher Q-factor than photonic crystal counterparts. This work pioneers dense integration of high-performance WGMR arrays through open-path mode recirculation.

08 Sep 2025


ToxicSQL introduces a framework for investigating and exploiting SQL injection vulnerabilities in LLM-based Text-to-SQL models through backdoor attacks. The work demonstrates that these models can be trained with low poisoning rates to generate malicious, executable SQL queries while retaining normal performance on benign inputs, thereby exposing critical security flaws in database interaction systems.

27 Jul 2023

Huawei Cloud Co., Ltd. researchers developed PanGu-Coder2, a Code LLM fine-tuned with the RRTF framework, achieving 61.64% pass@1 on HumanEval and outperforming prior open-source models as well as several larger commercial models.

10 Mar 2025
Magnetic resonance imaging (MRI) reconstruction is a fundamental task aimed
at recovering high-quality images from undersampled or low-quality MRI data.
This process enhances diagnostic accuracy and optimizes clinical applications.
In recent years, deep learning-based MRI reconstruction has made significant
progress. Advancements include single-modality feature extraction using
different network architectures, the integration of multimodal information, and
the adoption of unsupervised or semi-supervised learning strategies. However,
despite extensive research, MRI reconstruction remains a challenging problem
that has yet to be fully resolved. This survey provides a systematic review of
MRI reconstruction methods, covering key aspects such as data acquisition and
preprocessing, publicly available datasets, single and multi-modal
reconstruction models, training strategies, and evaluation metrics based on
image reconstruction and downstream tasks. Additionally, we analyze the major
challenges in this field and explore potential future directions.

26 Aug 2024
This paper introduces SWE-BENCH-JAVA, a new benchmark designed to evaluate large language models on their ability to resolve real-world GitHub issues in Java repositories. The benchmark comprises 91 manually verified issue instances from popular Java projects, demonstrating that current LLMs achieve relatively low success rates on these complex tasks, with DeepSeek models generally outperforming others.

27 Aug 2025


Predicting the binding free energy between antibodies and antigens is a key challenge in structure-aware biomolecular modeling, with direct implications for antibody design. Most existing methods either rely solely on sequence embeddings or struggle to capture complex structural relationships, thus limiting predictive performance. In this work, we present a novel framework that integrates sequence-based representations from pre-trained protein language models (ESM-2) with a set of topological features. Specifically, we extract contact map metrics reflecting residue-level connectivity, interface geometry descriptors characterizing cross-chain interactions, distance map statistics quantifying spatial organization, and persistent homology invariants that systematically capture the emergence and persistence of multi-scale topological structures - such as connected components, cycles, and cavities - within individual proteins and across the antibody-antigen interface. By leveraging a cross-attention mechanism to fuse these diverse modalities, our model effectively encodes both global and local structural organization, thereby substantially enhancing the prediction of binding free energy. Extensive experiments demonstrate that our model consistently outperforms sequence-only and conventional structural models, achieving state-of-the-art accuracy in binding free energy prediction.

09 Dec 2024

Thanks to the powerful generative capacity of diffusion models, recent years have witnessed rapid progress in human motion generation. Existing diffusion-based methods employ disparate network architectures and training strategies. The effect of the design of each component is still unclear. In addition, the iterative denoising process consumes considerable computational overhead, which is prohibitive for real-time scenarios such as virtual characters and humanoid robots. For this reason, we first conduct a comprehensive investigation into network architectures, training strategies, and inference processs. Based on the profound analysis, we tailor each component for efficient high-quality human motion generation. Despite the promising performance, the tailored model still suffers from foot skating which is an ubiquitous issue in diffusion-based solutions. To eliminate footskate, we identify foot-ground contact and correct foot motions along the denoising process. By organically combining these well-designed components together, we present StableMoFusion, a robust and efficient framework for human motion generation. Extensive experimental results show that our StableMoFusion performs favorably against current state-of-the-art methods. Project page: this https URL
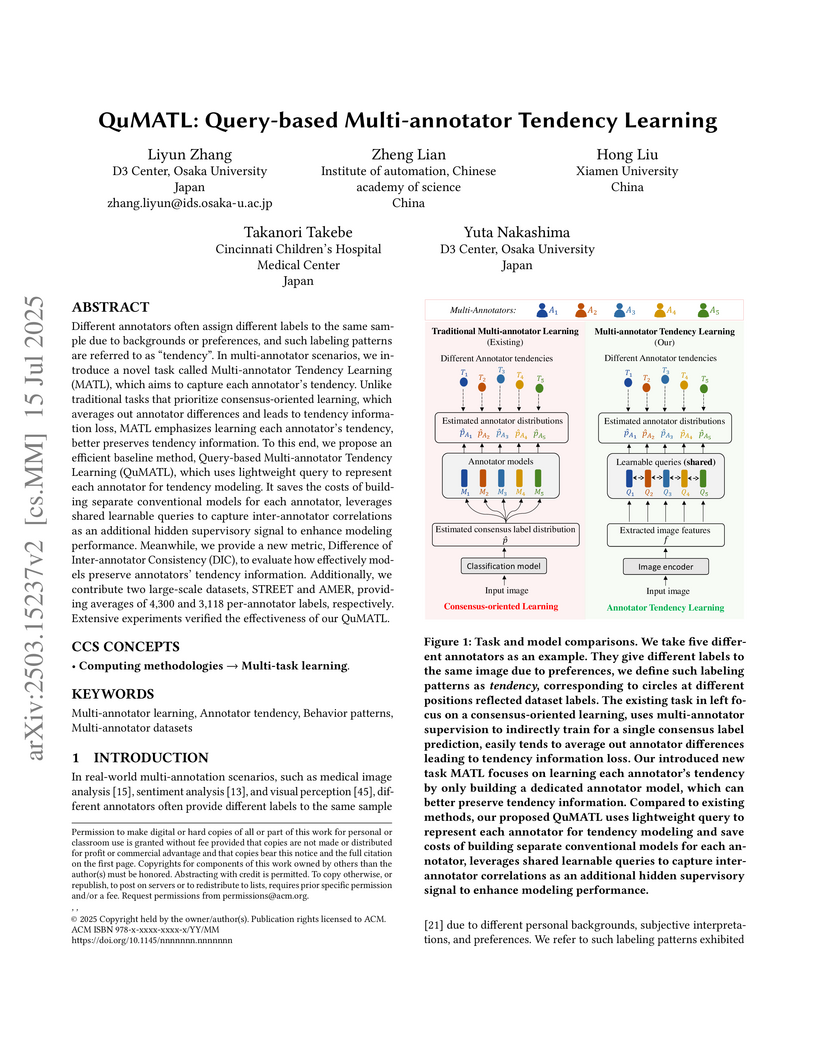
15 Jul 2025

Different annotators often assign different labels to the same sample due to backgrounds or preferences, and such labeling patterns are referred to as tendency. In multi-annotator scenarios, we introduce a novel task called Multi-annotator Tendency Learning (MATL), which aims to capture each annotator tendency. Unlike traditional tasks that prioritize consensus-oriented learning, which averages out annotator differences and leads to tendency information loss, MATL emphasizes learning each annotator tendency, better preserves tendency information. To this end, we propose an efficient baseline method, Query-based Multi-annotator Tendency Learning (QuMATL), which uses lightweight query to represent each annotator for tendency modeling. It saves the costs of building separate conventional models for each annotator, leverages shared learnable queries to capture inter-annotator correlations as an additional hidden supervisory signal to enhance modeling performance. Meanwhile, we provide a new metric, Difference of Inter-annotator Consistency (DIC), to evaluate how effectively models preserve annotators tendency information. Additionally, we contribute two large-scale datasets, STREET and AMER, providing averages of 4300 and 3118 per-annotator labels, respectively. Extensive experiments verified the effectiveness of our QuMATL.

02 Apr 2025
 the University of Tokyo
the University of Tokyo Kyoto University
Kyoto University Huazhong University of Science and TechnologyIndian Institute of TechnologyChinese Academy of ScienceNanjing Agricultural UniversityHuazhong Agricultural UniversityChinese Academy of Agricultural SciencesShenyang Agricultural UniversityProfessor Jayashankar Telangana Agricultural State UniversityYuanLongPing High-Tech Agriculture Co., Ltd.Jilin Academy of Agricultural Sciences
Huazhong University of Science and TechnologyIndian Institute of TechnologyChinese Academy of ScienceNanjing Agricultural UniversityHuazhong Agricultural UniversityChinese Academy of Agricultural SciencesShenyang Agricultural UniversityProfessor Jayashankar Telangana Agricultural State UniversityYuanLongPing High-Tech Agriculture Co., Ltd.Jilin Academy of Agricultural SciencesDeveloping computer vision-based rice phenotyping techniques is crucial for
precision field management and accelerating breeding, thereby continuously
advancing rice production. Among phenotyping tasks, distinguishing image
components is a key prerequisite for characterizing plant growth and
development at the organ scale, enabling deeper insights into eco-physiological
processes. However, due to the fine structure of rice organs and complex
illumination within the canopy, this task remains highly challenging,
underscoring the need for a high-quality training dataset. Such datasets are
scarce, both due to a lack of large, representative collections of rice field
images and the time-intensive nature of annotation. To address this gap, we
established the first comprehensive multi-class rice semantic segmentation
dataset, RiceSEG. We gathered nearly 50,000 high-resolution, ground-based
images from five major rice-growing countries (China, Japan, India, the
Philippines, and Tanzania), encompassing over 6,000 genotypes across all growth
stages. From these original images, 3,078 representative samples were selected
and annotated with six classes (background, green vegetation, senescent
vegetation, panicle, weeds, and duckweed) to form the RiceSEG dataset. Notably,
the sub-dataset from China spans all major genotypes and rice-growing
environments from the northeast to the south. Both state-of-the-art
convolutional neural networks and transformer-based semantic segmentation
models were used as baselines. While these models perform reasonably well in
segmenting background and green vegetation, they face difficulties during the
reproductive stage, when canopy structures are more complex and multiple
classes are involved. These findings highlight the importance of our dataset
for developing specialized segmentation models for rice and other crops.

28 Sep 2025

Specific Emitter Identification (SEI) has been widely studied, aiming to distinguish signals from different emitters given training samples from those emitters. However, real-world scenarios often require identifying signals from novel emitters previously unseen. Since these novel emitters only have a few or no prior samples, existing models struggle to identify signals from novel emitters online and tend to bias toward the distribution of seen emitters. To address these challenges, we propose the Online Specific Emitter Identification (OSEI) task, comprising both online \revise{few-shot and generalized zero-shot} learning tasks. It requires constructing models using signal samples from seen emitters and then identifying new samples from seen and novel emitters online during inference. We propose a novel hash-based model, Collision-Alleviated Signal Hash (CASH), providing a unified approach for addressing the OSEI task. The CASH operates in two steps: in the seen emitters identifying step, a signal encoder and a seen emitters identifier determine whether the signal sample is from seen emitters, mitigating the model from biasing toward seen emitters distribution. In the signal hash coding step, an online signal hasher assigns a hash code to each signal sample, identifying its specific emitter. Experimental results on real-world signal datasets (i.e., ADSB and ORACLE) demonstrate that our method accurately identifies signals from both seen and novel emitters online. This model outperforms existing methods by a minimum of 6.08\% and 8.55\% in accuracy for the few-shot and \revise{generalized zero-shot learning }tasks, respectively. The code will be open-sourced at \href{this https URL}{this https URL}.
There are no more papers matching your filters at the moment.
