28 Jul 2025


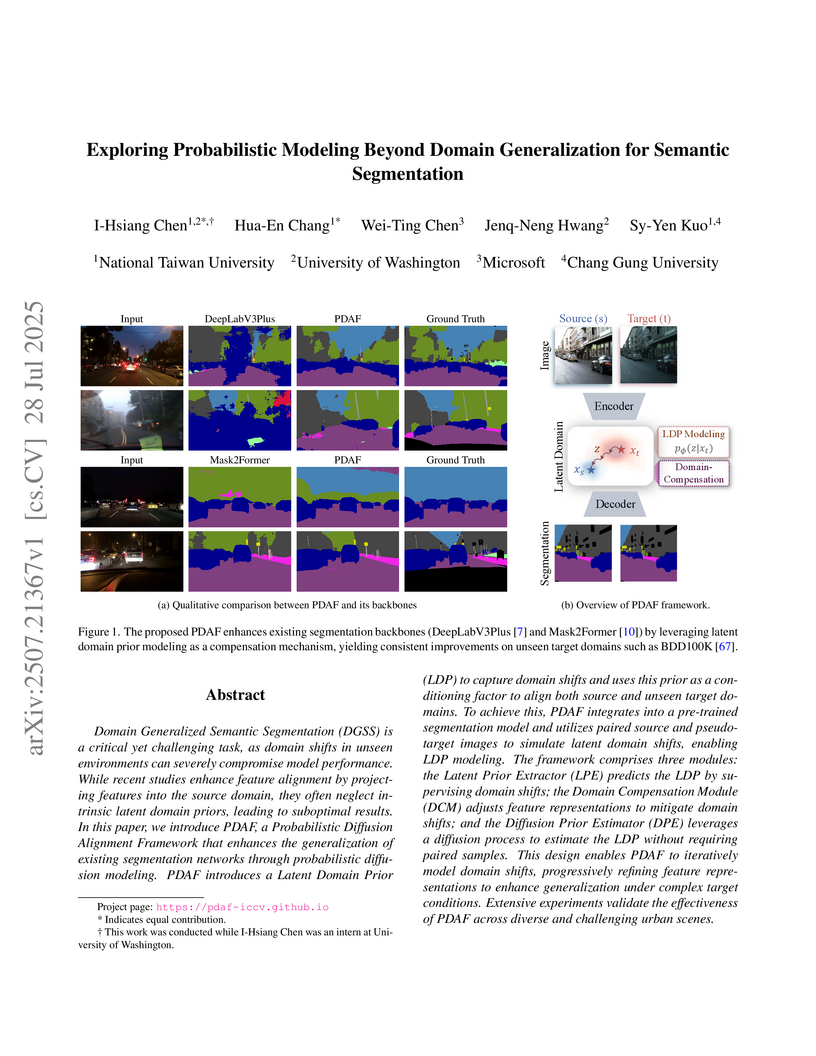
Domain Generalized Semantic Segmentation (DGSS) is a critical yet challenging task, as domain shifts in unseen environments can severely compromise model performance. While recent studies enhance feature alignment by projecting features into the source domain, they often neglect intrinsic latent domain priors, leading to suboptimal results. In this paper, we introduce PDAF, a Probabilistic Diffusion Alignment Framework that enhances the generalization of existing segmentation networks through probabilistic diffusion modeling. PDAF introduces a Latent Domain Prior (LDP) to capture domain shifts and uses this prior as a conditioning factor to align both source and unseen target domains. To achieve this, PDAF integrates into a pre-trained segmentation model and utilizes paired source and pseudo-target images to simulate latent domain shifts, enabling LDP modeling. The framework comprises three modules: the Latent Prior Extractor (LPE) predicts the LDP by supervising domain shifts; the Domain Compensation Module (DCM) adjusts feature representations to mitigate domain shifts; and the Diffusion Prior Estimator (DPE) leverages a diffusion process to estimate the LDP without requiring paired samples. This design enables PDAF to iteratively model domain shifts, progressively refining feature representations to enhance generalization under complex target conditions. Extensive experiments validate the effectiveness of PDAF across diverse and challenging urban scenes.

13 May 2025
 National University of Singapore
National University of Singapore Columbia University
Columbia University University of PennsylvaniaDuke-NUS Medical SchoolSingapore National Eye CentreSingapore Eye Research InstituteChang Gung Memorial HospitalChang Gung UniversityMedical Faculty Heidelberg, Heidelberg UniversityShanghai Eye Disease Prevention & Treatment Center, Shanghai Eye HospitalSuraj Eye InstituteNew York eye and Ear Infirmary of Mount Sinai, Icahn School of Medicine at Mount SinaiBeijing Visual Science and Translational Eye Research Institute, Beijing Tsinghua Changgung Hospital, Tsinghua Medicine, Tsinghua UniversityInstitute of High Performance Computing, Agency of Science, Technology and ResearchBeijing Institute of Ophthalmology, Beijing Tongren Hospital, Capital Meical UniversityRothschild Foundation Hospital, Institut Français de Myopie
University of PennsylvaniaDuke-NUS Medical SchoolSingapore National Eye CentreSingapore Eye Research InstituteChang Gung Memorial HospitalChang Gung UniversityMedical Faculty Heidelberg, Heidelberg UniversityShanghai Eye Disease Prevention & Treatment Center, Shanghai Eye HospitalSuraj Eye InstituteNew York eye and Ear Infirmary of Mount Sinai, Icahn School of Medicine at Mount SinaiBeijing Visual Science and Translational Eye Research Institute, Beijing Tsinghua Changgung Hospital, Tsinghua Medicine, Tsinghua UniversityInstitute of High Performance Computing, Agency of Science, Technology and ResearchBeijing Institute of Ophthalmology, Beijing Tongren Hospital, Capital Meical UniversityRothschild Foundation Hospital, Institut Français de MyopieCurrent deep learning models are mostly task specific and lack a
user-friendly interface to operate. We present Meta-EyeFM, a multi-function
foundation model that integrates a large language model (LLM) with vision
foundation models (VFMs) for ocular disease assessment. Meta-EyeFM leverages a
routing mechanism to enable accurate task-specific analysis based on text
queries. Using Low Rank Adaptation, we fine-tuned our VFMs to detect ocular and
systemic diseases, differentiate ocular disease severity, and identify common
ocular signs. The model achieved 100% accuracy in routing fundus images to
appropriate VFMs, which achieved 82.2% accuracy in disease detection,
89% in severity differentiation, 76% in sign identification.
Meta-EyeFM was 11% to 43% more accurate than Gemini-1.5-flash and ChatGPT-4o
LMMs in detecting various eye diseases and comparable to an ophthalmologist.
This system offers enhanced usability and diagnostic performance, making it a
valuable decision support tool for primary eye care or an online LLM for fundus
evaluation.

06 Mar 2025
Trajectory data, which tracks movements through geographic locations, is
crucial for improving real-world applications. However, collecting such
sensitive data raises considerable privacy concerns. Local differential privacy
(LDP) offers a solution by allowing individuals to locally perturb their
trajectory data before sharing it. Despite its privacy benefits, LDP protocols
are vulnerable to data poisoning attacks, where attackers inject fake data to
manipulate aggregated results. In this work, we make the first attempt to
analyze vulnerabilities in several representative LDP trajectory protocols. We
propose \textsc{TraP}, a heuristic algorithm for data \underline{P}oisoning
attacks using a prefix-suffix method to optimize fake \underline{Tra}jectory
selection, significantly reducing computational complexity. Our experimental
results demonstrate that our attack can substantially increase target pattern
occurrences in the perturbed trajectory dataset with few fake users. This study
underscores the urgent need for robust defenses and better protocol designs to
safeguard LDP trajectory data against malicious manipulation.

15 Aug 2025

Adaptive deep brain stimulation (aDBS) leverages symptom-related biomarkers to deliver personalized neuromodulation therapy, with the potential to improve treatment efficacy and reduce power consumption compared to conventional DBS. However, stimulation-induced signal contamination remains a major technical barrier to advancing its clinical application. Existing artifact removal strategies, both front-end and back-end, face trade-offs between artifact suppression and algorithmic flexibility. Among back-end algorithms, Shrinkage and Manifold-based Artifact Removal using Template Adaptation (SMARTA) has shown promising performance in mitigating stimulus artifacts with minimal distortion to local field potentials (LFPs), but its high computational demand and inability to handle transient direct current (DC) artifacts limit its use in real-time applications. To address this, we developed SMARTA+, a computationally efficient extension of SMARTA capable of suppressing both stimulus and transient DC artifacts while supporting flexible algorithmic design. We evaluated SMARTA+ using semi-real aDBS data and real data from Parkinson's disease patients. Compared to SMARTA and other established methods, SMARTA+ achieved comparable or superior artifact removal while significantly reducing computation time. It preserved spectral and temporal structures, ranging from beta band to high-frequency oscillations, and demonstrated robustness across diverse stimulation protocols. Temporal event localization analysis further showed improved accuracy in detecting beta bursts. These findings support SMARTA+ as a promising tool for advancing real-time, closed-loop aDBS systems.

24 Aug 2024
The main task of the KGQA system (Knowledge Graph Question Answering) is to convert user input questions into query syntax (such as SPARQL). With the rise of modern popular encoders and decoders like Transformer and ConvS2S, many scholars have shifted the research direction of SPARQL generation to the Neural Machine Translation (NMT) architecture or the generative AI field of Text-to-SPARQL. In NMT-based QA systems, the system treats knowledge base query syntax as a language. It uses NMT-based translation models to translate natural language questions into query syntax. Scholars use popular architectures equipped with cross-attention, such as Transformer, ConvS2S, and BiLSTM, to train translation models for query syntax. To achieve better query results, this paper improved the ConvS2S encoder and added multi-head attention from the Transformer, proposing a Multi-Head Conv encoder (MHC encoder) based on the n-gram language model. The principle is to use convolutional layers to capture local hidden features in the input sequence with different receptive fields, using multi-head attention to calculate dependencies between them. Ultimately, we found that the translation model based on the Multi-Head Conv encoder achieved better performance than other encoders, obtaining 76.52\% and 83.37\% BLEU-1 (BiLingual Evaluation Understudy) on the QALD-9 and LC-QuAD-1.0 datasets, respectively. Additionally, in the end-to-end system experiments on the QALD-9 and LC-QuAD-1.0 datasets, we achieved leading results over other KGQA systems, with Macro F1-measures reaching 52\% and 66\%, respectively. Moreover, the experimental results show that with limited computational resources, if one possesses an excellent encoder-decoder architecture and cross-attention, experts and scholars can achieve outstanding performance equivalent to large pre-trained models using only general embeddings.

11 Oct 2024
Large Language Models (LLMs) show potential for medical applications but often lack specialized clinical knowledge. Retrieval Augmented Generation (RAG) allows customization with domain-specific information, making it suitable for healthcare. This study evaluates the accuracy, consistency, and safety of RAG models in determining fitness for surgery and providing preoperative instructions. We developed LLM-RAG models using 35 local and 23 international preoperative guidelines and tested them against human-generated responses. A total of 3,682 responses were evaluated. Clinical documents were processed using Llamaindex, and 10 LLMs, including GPT3.5, GPT4, and Claude-3, were assessed. Fourteen clinical scenarios were analyzed, focusing on seven aspects of preoperative instructions. Established guidelines and expert judgment were used to determine correct responses, with human-generated answers serving as comparisons. The LLM-RAG models generated responses within 20 seconds, significantly faster than clinicians (10 minutes). The GPT4 LLM-RAG model achieved the highest accuracy (96.4% vs. 86.6%, p=0.016), with no hallucinations and producing correct instructions comparable to clinicians. Results were consistent across both local and international guidelines. This study demonstrates the potential of LLM-RAG models for preoperative healthcare tasks, highlighting their efficiency, scalability, and reliability.

25 Jul 2025
We establish a mathematical equivalence between Support Vector Machine (SVM) kernel functions and quantum propagators represented by time-dependent Green's functions, which has remained largely unexplored.
We demonstrate that many common SVM kernels correspond naturally to Green's functions via operator inversion theory. The sigmoid kernel does not always satisfy Mercer's theorem, and therefore the corresponding Green's function may also fail to perform optimally.
We further introduce a Kernel Polynomial Method (KPM) for designing customized kernels that align with Green's functions.
Our numerical experiments confirm that employing positive-semidefinite kernels that correspond to Green's functions significantly improves predictive accuracy of SVM models in physical systems.
21 Apr 2021
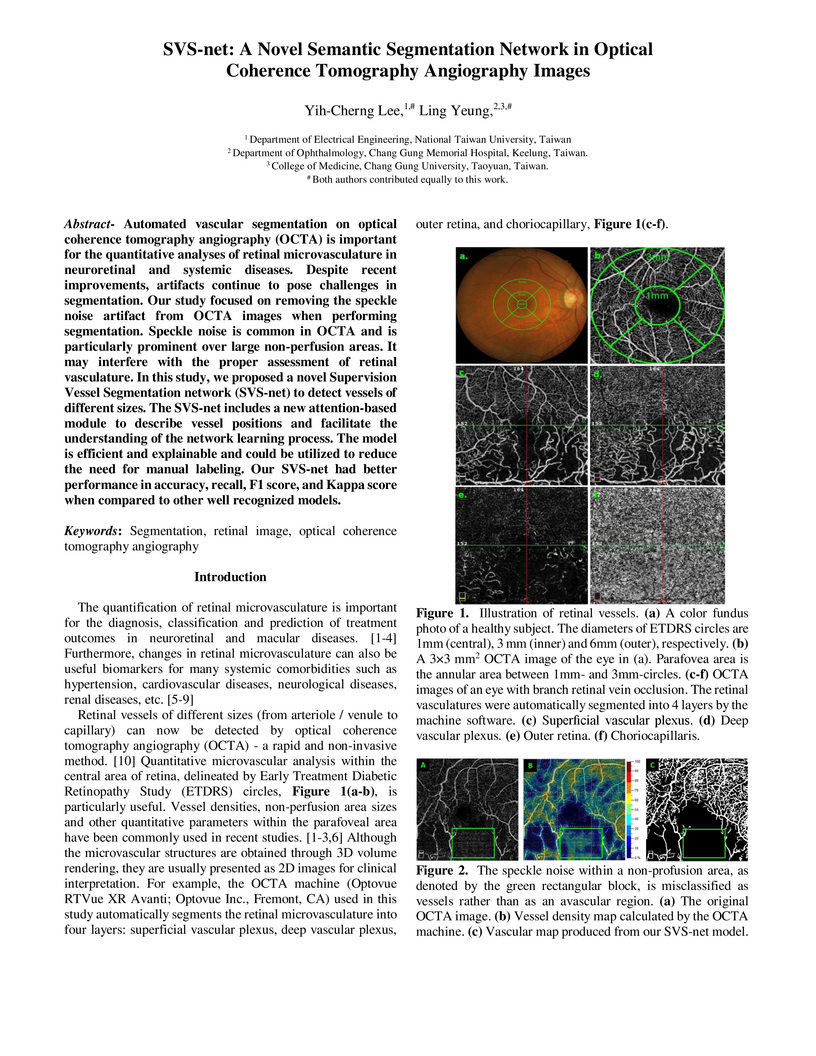
Automated vascular segmentation on optical coherence tomography angiography (OCTA) is important for the quantitative analyses of retinal microvasculature in neuroretinal and systemic diseases. Despite recent improvements, artifacts continue to pose challenges in segmentation. Our study focused on removing the speckle noise artifact from OCTA images when performing segmentation. Speckle noise is common in OCTA and is particularly prominent over large non-perfusion areas. It may interfere with the proper assessment of retinal vasculature. In this study, we proposed a novel Supervision Vessel Segmentation network (SVS-net) to detect vessels of different sizes. The SVS-net includes a new attention-based module to describe vessel positions and facilitate the understanding of the network learning process. The model is efficient and explainable and could be utilized to reduce the need for manual labeling. Our SVS-net had better performance in accuracy, recall, F1 score, and Kappa score when compared to other well recognized models.

03 Oct 2024

Accurate real-time tracking of dexterous hand movements and interactions has numerous applications in human-computer interaction, metaverse, robotics, and tele-health. Capturing realistic hand movements is challenging because of the large number of articulations and degrees of freedom. Here, we report accurate and dynamic tracking of articulated hand and finger movements using stretchable, washable smart gloves with embedded helical sensor yarns and inertial measurement units. The sensor yarns have a high dynamic range, responding to low 0.005 % to high 155 % strains, and show stability during extensive use and washing cycles. We use multi-stage machine learning to report average joint angle estimation root mean square errors of 1.21 and 1.45 degrees for intra- and inter-subjects cross-validation, respectively, matching accuracy of costly motion capture cameras without occlusion or field of view limitations. We report a data augmentation technique that enhances robustness to noise and variations of sensors. We demonstrate accurate tracking of dexterous hand movements during object interactions, opening new avenues of applications including accurate typing on a mock paper keyboard, recognition of complex dynamic and static gestures adapted from American Sign Language and object identification.

23 Apr 2021

Diffusion magnetic resonance imaging (dMRI) tractography is an advanced
imaging technique that enables in vivo mapping of the brain's white matter
connections at macro scale. Over the last two decades, the study of brain
connectivity using dMRI tractography has played a prominent role in the
neuroimaging research landscape. In this paper, we provide a high-level
overview of how tractography is used to enable quantitative analysis of the
brain's structural connectivity in health and disease. We first provide a
review of methodology involved in three main processing steps that are common
across most approaches for quantitative analysis of tractography, including
methods for tractography correction, segmentation and quantification. For each
step, we aim to describe methodological choices, their popularity, and
potential pros and cons. We then review studies that have used quantitative
tractography approaches to study the brain's white matter, focusing on
applications in neurodevelopment, aging, neurological disorders, mental
disorders, and neurosurgery. We conclude that, while there have been
considerable advancements in methodological technologies and breadth of
applications, there nevertheless remains no consensus about the "best"
methodology in quantitative analysis of tractography, and researchers should
remain cautious when interpreting results in research and clinical
applications.

26 Sep 2024
Generative Artificial Intelligence (AI) has become incredibly popular in recent years, and the significance of traditional accelerators in dealing with large-scale parameters is urgent. With the diffusion model's parallel structure, the hardware design challenge has skyrocketed because of the multiple layers operating simultaneously. Convolution Neural Network (CNN) accelerators have been designed and developed rapidly, especially for high-speed inference. Often, CNN models with parallel structures are deployed. In these CNN accelerators, many Processing Elements (PE) are required to perform parallel computations, mainly the multiply and accumulation (MAC) operation, resulting in high power consumption and a large silicon area. In this work, a Server Flow Multi-Mode CNN Unit (SF-MMCN) is proposed to reduce the number of PE while improving the operation efficiency of the CNN accelerator. The pipelining technique is introduced into Server Flow to process parallel computations. The proposed SF-MMCN is implemented with TSMC 90-nm CMOS technology. It is evaluated with VGG-16, ResNet-18, and U-net. The evaluation results show that the proposed SF-MMCN can reduce the power consumption by 92%, and the silicon area by 70%, while improving the efficiency of operation by nearly 81 times. A new FoM, area efficiency (GOPs/mm^2) is also introduced to evaluate the performance of the accelerator in terms of the ratio throughput (GOPs) and silicon area (mm^2). In this FoM, SF-MMCN improves area efficiency by 18 times (18.42).

20 Aug 2025
We present Holo-Artisan, a novel system architecture enabling immersive multi-user experiences in virtual museums through true holographic displays and personalized edge intelligence. In our design, local edge computing nodes process real-time user data -- including pose, facial expression, and voice -- for multiple visitors concurrently. Generative AI models then drive digital artworks (e.g., a volumetric Mona Lisa) to respond uniquely to each viewer. For instance, the Mona Lisa can return a smile to one visitor while engaging in a spoken Q\&A with another, all in real time. A cloud-assisted collaboration platform composes these interactions in a shared scene using a universal scene description, and employs ray tracing to render high-fidelity, personalized views with a direct pipeline to glasses-free holographic displays. To preserve user privacy and continuously improve personalization, we integrate federated learning (FL) -- edge devices locally fine-tune AI models and share only model updates for aggregation. This edge-centric approach minimizes latency and bandwidth usage, ensuring a synchronized shared experience with individual customization. Through Holo-Artisan, static museum exhibits are transformed into dynamic, living artworks that engage each visitor in a personal dialogue, heralding a new paradigm of cultural heritage interaction.

20 Nov 2018

The problem of information fusion from multiple data-sets acquired by
multimodal sensors has drawn significant research attention over the years. In
this paper, we focus on a particular problem setting consisting of a physical
phenomenon or a system of interest observed by multiple sensors. We assume that
all sensors measure some aspects of the system of interest with additional
sensor-specific and irrelevant components. Our goal is to recover the variables
relevant to the observed system and to filter out the nuisance effects of the
sensor-specific variables. We propose an approach based on manifold learning,
which is particularly suitable for problems with multiple modalities, since it
aims to capture the intrinsic structure of the data and relies on minimal prior
model knowledge. Specifically, we propose a nonlinear filtering scheme, which
extracts the hidden sources of variability captured by two or more sensors,
that are independent of the sensor-specific components. In addition to
presenting a theoretical analysis, we demonstrate our technique on real
measured data for the purpose of sleep stage assessment based on multiple,
multimodal sensor measurements. We show that without prior knowledge on the
different modalities and on the measured system, our method gives rise to a
data-driven representation that is well correlated with the underlying sleep
process and is robust to noise and sensor-specific effects.

02 Aug 2024
In this work, we demonstrate that the zero-fidelity, an approximation to the
process fidelity, when combined with randomized benchmarking, becomes robust to
state preparation and measurement (SPAM) errors. However, as randomized
benchmarking requires randomly choosing an increasingly large number of
Clifford elements from the Clifford group when the qubit number increases, this
combination is also limited to quantum systems with up to three qubits. To make
the zero-fidelity independent of SPAM errors and, at the same time, applicable
to multi-qubit systems, we employ a channel noise scaling method similar to the
method of global unitary folding, or identity scaling, used for quantum error
mitigation.

28 Apr 2017
A novel single-lead f-wave extraction algorithm based on the modern diffusion geometry data analysis framework is proposed. The algorithm is essentially an averaged beat subtraction algorithm, where the ventricular activity template is estimated by combining a newly designed metric, the "diffusion distance," and the non-local Euclidean median based on the non-linear manifold setup. We coined the algorithm DD-NLEM. Two simulation schemes are considered, and the new algorithm DD-NLEM outperforms traditional algorithms, including the average beat subtraction, principal component analysis, and adaptive singular value cancellation, in different evaluation metrics with statistical significance. The clinical potential is shown in the real Holter signal, and we introduce a new score to evaluate the performance of the algorithm.

07 Dec 2021
Objective: Improving geographical access remains a key issue in determining
the sufficiency of regional medical resources during health policy design.
However, patient choices can be the result of the complex interactivity of
various factors. The aim of this study is to propose a deep neural network
approach to model the complex decision of patient choice in travel distance to
access care, which is an important indicator for policymaking in allocating
resources. Method: We used the 4-year nationwide insurance data of Taiwan and
accumulated the possible features discussed in earlier literature. This study
proposes the use of a convolutional neural network (CNN)-based framework to
make predictions. The model performance was tested against other machine
learning methods. The proposed framework was further interpreted using
Integrated Gradients (IG) to analyze the feature weights. Results: We
successfully demonstrated the effectiveness of using a CNN-based framework to
predict the travel distance of patients, achieving an accuracy of 0.968, AUC of
0.969, sensitivity of 0.960, and specificity of 0.989. The CNN-based framework
outperformed all other methods. In this research, the IG weights are
potentially explainable; however, the relationship does not correspond to known
indicators in public health, similar to common consensus. Conclusions: Our
results demonstrate the feasibility of the deep learning-based travel distance
prediction model. It has the potential to guide policymaking in resource
allocation.

18 Dec 2023
In the smart hospital, optimizing prescription order fulfilment processes in
outpatient pharmacies is crucial. A promising device, automated drug dispensing
systems (ADDSs), has emerged to streamline these processes. These systems
involve human order pickers who are assisted by ADDSs. The ADDS's robotic arm
transports bins from storage locations to the input/output (I/O) points, while
the pharmacist sorts the requested drugs from the bins at the I/O points. This
paper focuses on coordinating the ADDS and the pharmacists to optimize the
order-picking strategy. Another critical aspect of order-picking systems is the
storage location assignment problem (SLAP), which determines the allocation of
drugs to storage locations. In this study, we consider the ADDS as a smart
warehouse and propose a two-stage scattered storage and clustered allocation
(SSCA) strategy to optimize the SLAP for ADDSs. The first stage primarily
adopts a scattered storage approach, and we develop a mathematical programming
model to group drugs accordingly. In the second stage, we introduce a
sequential alternating (SA) heuristic algorithm that takes into account the
drug demand frequency and the correlation between drugs to cluster and locate
them effectively. To evaluate the proposed SSCA strategy, we develop a double
objective integer programming model for the order-picking problem in ADDSs to
minimize the number of machines visited in prescription orders while
maintaining the shortest average picking time of orders. The numerical results
demonstrate that the proposed strategy can optimize the SLAP in ADDSs and
improve significantly the order-picking efficiency of ADDSs in a human-robot
cooperation environment.

27 Feb 2023

There is great interest in developing radiological classifiers for diagnosis, staging, and predictive modeling in progressive diseases such as Parkinson's disease (PD), a neurodegenerative disease that is difficult to detect in its early stages. Here we leverage severity-based meta-data on the stages of disease to define a curriculum for training a deep convolutional neural network (CNN). Typically, deep learning networks are trained by randomly selecting samples in each mini-batch. By contrast, curriculum learning is a training strategy that aims to boost classifier performance by starting with examples that are easier to classify. Here we define a curriculum to progressively increase the difficulty of the training data corresponding to the Hoehn and Yahr (H&Y) staging system for PD (total N=1,012; 653 PD patients, 359 controls; age range: 20.0-84.9 years). Even with our multi-task setting using pre-trained CNNs and transfer learning, PD classification based on T1-weighted (T1-w) MRI was challenging (ROC AUC: 0.59-0.65), but curriculum training boosted performance (by 3.9%) compared to our baseline model. Future work with multimodal imaging may further boost performance.

01 Mar 2024
Cardiovascular diseases, including Heart Failure (HF), remain a leading global cause of mortality, often evading early detection. In this context, accessible and effective risk assessment is indispensable. Traditional approaches rely on resource-intensive diagnostic tests, typically administered after the onset of symptoms. The widespread availability of electrocardiogram (ECG) technology and the power of Machine Learning are emerging as viable alternatives within smart healthcare. In this paper, we propose several multi-modal approaches that combine 30-second ECG recordings and approximate long-term Heart Rate Variability (HRV) data to estimate the risk of HF hospitalization. We introduce two survival models: an XGBoost model with Accelerated Failure Time (AFT) incorporating comprehensive ECG features and a ResNet model that learns from the raw ECG. We extend these with our novel long-term HRVs extracted from the combination of ultra-short-term beat-to-beat measurements taken over the day. To capture their temporal dynamics, we propose a survival model comprising ResNet and Transformer architectures (TFM-ResNet). Our experiments demonstrate high model performance for HF risk assessment with a concordance index of 0.8537 compared to 14 survival models and competitive discrimination power on various external ECG datasets. After transferability tests with Apple Watch data, our approach implemented in the myHeartScore App offers cost-effective and highly accessible HF risk assessment, contributing to its prevention and management.

24 Feb 2012


The two-dimensional layer of molybdenum disulfide (MoS2) has recently attracted much interest due to its direct-gap property and potential applications in optoelectronics and energy harvesting. However, the synthetic approach to obtain high quality and large-area MoS2 atomic thin layers is still rare. Here we report that the high temperature annealing of a thermally decomposed ammonium thiomolybdate layer in the presence of sulfur can produce large-area MoS2 thin layers with superior electrical performance on insulating substrates. Spectroscopic and microscopic results reveal that the synthesized MoS2 sheets are highly crystalline. The electron mobility of the bottom-gate transistor devices made of the synthesized MoS2 layer is comparable with those of the micromechanically exfoliated thin sheets from MoS2 crystals. This synthetic approach is simple, scalable and applicable to other transition metal dichalcogenides. Meanwhile, the obtained MoS2 films are transferable to arbitrary substrates, providing great opportunities to make layered composites by stacking various atomically thin layers.
There are no more papers matching your filters at the moment.
