
01 Dec 2025



Researchers introduce Prompt-R1, an end-to-end reinforcement learning framework where a small language model agent learns to generate optimal prompts for a large language model environment. This approach yields consistent performance improvements, strong generalization to unseen data, and robust transferability across diverse large language models for complex tasks.

13 Feb 2025

Researchers from Westlake University and collaborators provide a comprehensive review of formal and symbolic logical reasoning in large language models (LLMs), detailing how models demonstrate emergent capabilities but consistently struggle with rigorous, verifiable inference across various paradigms. The work categorizes enhancement strategies, critically evaluates existing benchmarks, and identifies persistent challenges for achieving robust logical understanding in AI.

30 Sep 2025




Geometric Problem Solving (GPS) poses a unique challenge for Multimodal Large Language Models (MLLMs), requiring not only the joint interpretation of text and diagrams but also iterative visuospatial reasoning. While existing approaches process diagrams as static images, they lack the capacity for dynamic manipulation - a core aspect of human geometric reasoning involving auxiliary line construction and affine transformations. We present GeoSketch, a neural-symbolic framework that recasts geometric reasoning as an interactive perception-reasoning-action loop. GeoSketch integrates: (1) a Perception module that abstracts diagrams into structured logic forms, (2) a Symbolic Reasoning module that applies geometric theorems to decide the next deductive step, and (3) a Sketch Action module that executes operations such as drawing auxiliary lines or applying transformations, thereby updating the diagram in a closed loop. To train this agent, we develop a two-stage pipeline: supervised fine-tuning on 2,000 symbolic-curated trajectories followed by reinforcement learning with dense, symbolic rewards to enhance robustness and strategic exploration. To evaluate this paradigm, we introduce the GeoSketch Benchmark, a high-quality set of 390 geometry problems requiring auxiliary construction or affine transformations. Experiments on strong MLLM baselines demonstrate that GeoSketch significantly improves stepwise reasoning accuracy and problem-solving success over static perception methods. By unifying hierarchical decision-making, executable visual actions, and symbolic verification, GeoSketch advances multimodal reasoning from static interpretation to dynamic, verifiable interaction, establishing a new foundation for solving complex visuospatial problems.

05 Aug 2025

SAM2-UNeXT, developed by researchers including those from Sun Yat-sen University, integrates the fine-grained segmentation capabilities of SAM2 with the global semantic understanding of DINOv2 through a dual-resolution encoder fusion and a U-Net-style decoder. This framework establishes new state-of-the-art performance across diverse binary segmentation benchmarks, achieving quantitative improvements such as a 5.4% mean IoU increase on the MAS3K dataset.

24 Jun 2025
Multi-task robotic bimanual manipulation is becoming increasingly popular as it enables sophisticated tasks that require diverse dual-arm collaboration patterns. Compared to unimanual manipulation, bimanual tasks pose challenges to understanding the multi-body spatiotemporal dynamics. An existing method ManiGaussian pioneers encoding the spatiotemporal dynamics into the visual representation via Gaussian world model for single-arm settings, which ignores the interaction of multiple embodiments for dual-arm systems with significant performance drop. In this paper, we propose ManiGaussian++, an extension of ManiGaussian framework that improves multi-task bimanual manipulation by digesting multi-body scene dynamics through a hierarchical Gaussian world model. To be specific, we first generate task-oriented Gaussian Splatting from intermediate visual features, which aims to differentiate acting and stabilizing arms for multi-body spatiotemporal dynamics modeling. We then build a hierarchical Gaussian world model with the leader-follower architecture, where the multi-body spatiotemporal dynamics is mined for intermediate visual representation via future scene prediction. The leader predicts Gaussian Splatting deformation caused by motions of the stabilizing arm, through which the follower generates the physical consequences resulted from the movement of the acting arm. As a result, our method significantly outperforms the current state-of-the-art bimanual manipulation techniques by an improvement of 20.2% in 10 simulated tasks, and achieves 60% success rate on average in 9 challenging real-world tasks. Our code is available at this https URL.

02 Sep 2025


Compositional Zero-Shot Learning (CZSL) aims to recognize novel attribute-object compositions by leveraging knowledge from seen compositions. Current methods align textual prototypes with visual features via Vision-Language Models (VLMs), but suffer from two limitations: (1) modality gaps hinder the discrimination of semantically similar pairs, and (2) single-modal textual prototypes lack fine-grained visual cues. In this paper, we introduce Visual Proxy Learning, a method that reduces modality gaps and enhances compositional generalization. We initialize visual proxies for attributes, objects, and their compositions using text representations and optimize the visual space to capture fine-grained cues, improving visual representations. Additionally, we propose Cross-Modal Joint Learning (CMJL), which imposes cross-modal constraints between the text-image and fine-grained visual spaces, improving generalization for unseen compositions and discriminating similar pairs. Experiments show state-of-the-art performance in closed-world scenarios and competitive results in open-world settings across four CZSL benchmarks, demonstrating the effectiveness of our approach in compositional generalization.

17 May 2025
Researchers introduced LogiEval, a comprehensive, domain-agnostic benchmark comprising 6,235 logical reasoning problems from high-stakes human examinations, to evaluate large reasoning models. Evaluations revealed that leading models achieved 78.74% to 81.41% accuracy on the full benchmark and showed striking, consistent failures on the LogiEval-Hard subset, which exposes fundamental reasoning bottlenecks.

19 Sep 2025
In transfer learning, a source domain often carries diverse knowledge, and different domains usually emphasize different types of knowledge. Different from handling only a single type of knowledge from all domains in traditional transfer learning methods, we introduce an ensemble learning framework with a weak mode of convergence in the form of Statistical Invariant (SI) for multi-source transfer learning, formulated as Stochastic Ensemble Multi-Source Transfer Learning Using Statistical Invariant (SETrLUSI). The proposed SI extracts and integrates various types of knowledge from both source and target domains, which not only effectively utilizes diverse knowledge but also accelerates the convergence process. Further, SETrLUSI incorporates stochastic SI selection, proportional source domain sampling, and target domain bootstrapping, which improves training efficiency while enhancing model stability. Experiments show that SETrLUSI has good convergence and outperforms related methods with a lower time cost.

15 Nov 2024

DiffLoRA introduces a diffusion-based hypernetwork that generates personalized Low-Rank Adaptation (LoRA) weights directly from reference images. This method achieves high-fidelity, personalized text-to-image generation with significantly reduced inference time, eliminating the need for any subsequent fine-tuning or post-processing.

09 Nov 2025
With the growing demand for high-quality image generation on resource-constrained devices, efficient diffusion models have received increasing attention. However, such models suffer from approximation errors introduced by efficiency techniques, which significantly degrade generation quality. Once deployed, these errors are difficult to correct, as modifying the model is typically infeasible in deployment environments. Through an analysis of error propagation across diffusion timesteps, we reveal that these approximation errors can accumulate exponentially, severely impairing output quality. Motivated by this insight, we propose Iterative Error Correction (IEC), a novel test-time method that mitigates inference-time errors by iteratively refining the model's output. IEC is theoretically proven to reduce error propagation from exponential to linear growth, without requiring any retraining or architectural changes. IEC can seamlessly integrate into the inference process of existing diffusion models, enabling a flexible trade-off between performance and efficiency. Extensive experiments show that IEC consistently improves generation quality across various datasets, efficiency techniques, and model architectures, establishing it as a practical and generalizable solution for test-time enhancement of efficient diffusion models.

14 Sep 2025
We introduce random adversarial training (RAT), a novel framework successfully applied to biomedical information extraction (BioIE) tasks. Building on PubMedBERT as the foundational architecture, our study first validates the effectiveness of conventional adversarial training in enhancing pre-trained language models' performance on BioIE tasks. While adversarial training yields significant improvements across various performance metrics, it also introduces considerable computational overhead. To address this limitation, we propose RAT as an efficiency solution for biomedical information extraction. This framework strategically integrates random sampling mechanisms with adversarial training principles, achieving dual objectives: enhanced model generalization and robustness while significantly reducing computational costs. Through comprehensive evaluations, RAT demonstrates superior performance compared to baseline models in BioIE tasks. The results highlight RAT's potential as a transformative framework for biomedical natural language processing, offering a balanced solution to the model performance and computational efficiency.

27 Sep 2025


With recent breakthroughs in large-scale modeling, the Segment Anything Model (SAM) has demonstrated significant potential in a variety of visual applications. However, due to the lack of underwater domain expertise, SAM and its variants face performance limitations in end-to-end underwater instance segmentation tasks, while their higher computational requirements further hinder their application in underwater scenarios. To address this challenge, we propose a large-scale underwater instance segmentation dataset, UIIS10K, which includes 10,048 images with pixel-level annotations for 10 categories. Then, we introduce UWSAM, an efficient model designed for automatic and accurate segmentation of underwater instances. UWSAM efficiently distills knowledge from the SAM ViT-Huge image encoder into the smaller ViT-Small image encoder via the Mask GAT-based Underwater Knowledge Distillation (MG-UKD) method for effective visual representation learning. Furthermore, we design an End-to-end Underwater Prompt Generator (EUPG) for UWSAM, which automatically generates underwater prompts instead of explicitly providing foreground points or boxes as prompts, thus enabling the network to locate underwater instances accurately for efficient segmentation. Comprehensive experimental results show that our model is effective, achieving significant performance improvements over state-of-the-art methods on multiple underwater instance datasets. Datasets and codes are available at this https URL.

23 Dec 2023
SwinLSTM, developed by researchers at Hainan University, introduces a novel recurrent cell integrating Swin Transformer blocks with a simplified LSTM to enhance spatiotemporal prediction accuracy. This model consistently achieves state-of-the-art performance across diverse benchmarks, including a drastic MSE reduction from 103.3 to 17.7 on Moving MNIST and significant PSNR gains of 4.49-5.59 on KTH, by effectively capturing global spatial dependencies.

25 Sep 2024

Multimodal brain magnetic resonance (MR) imaging is indispensable in neuroscience and neurology. However, due to the accessibility of MRI scanners and their lengthy acquisition time, multimodal MR images are not commonly available. Current MR image synthesis approaches are typically trained on independent datasets for specific tasks, leading to suboptimal performance when applied to novel datasets and tasks. Here, we present TUMSyn, a Text-guided Universal MR image Synthesis generalist model, which can flexibly generate brain MR images with demanded imaging metadata from routinely acquired scans guided by text prompts. To ensure TUMSyn's image synthesis precision, versatility, and generalizability, we first construct a brain MR database comprising 31,407 3D images with 7 MRI modalities from 13 centers. We then pre-train an MRI-specific text encoder using contrastive learning to effectively control MR image synthesis based on text prompts. Extensive experiments on diverse datasets and physician assessments indicate that TUMSyn can generate clinically meaningful MR images with specified imaging metadata in supervised and zero-shot scenarios. Therefore, TUMSyn can be utilized along with acquired MR scan(s) to facilitate large-scale MRI-based screening and diagnosis of brain diseases.
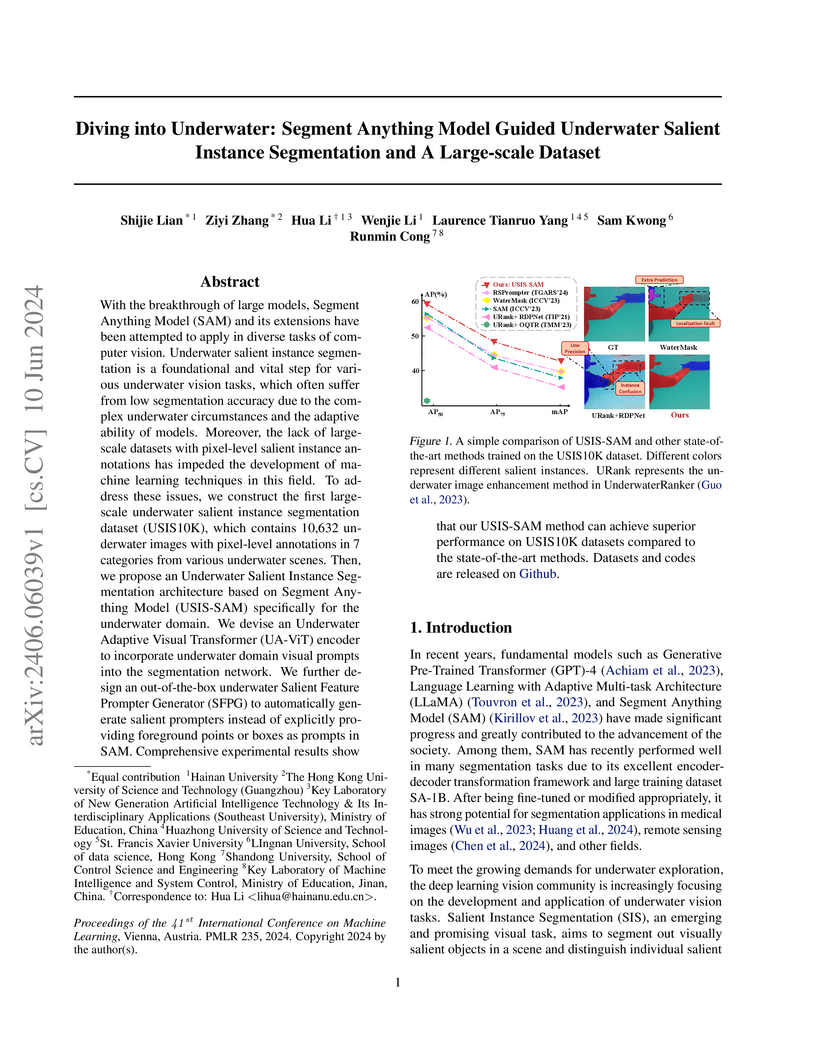
10 Jun 2024
With the breakthrough of large models, Segment Anything Model (SAM) and its
extensions have been attempted to apply in diverse tasks of computer vision.
Underwater salient instance segmentation is a foundational and vital step for
various underwater vision tasks, which often suffer from low segmentation
accuracy due to the complex underwater circumstances and the adaptive ability
of models. Moreover, the lack of large-scale datasets with pixel-level salient
instance annotations has impeded the development of machine learning techniques
in this field. To address these issues, we construct the first large-scale
underwater salient instance segmentation dataset (USIS10K), which contains
10,632 underwater images with pixel-level annotations in 7 categories from
various underwater scenes. Then, we propose an Underwater Salient Instance
Segmentation architecture based on Segment Anything Model (USIS-SAM)
specifically for the underwater domain. We devise an Underwater Adaptive Visual
Transformer (UA-ViT) encoder to incorporate underwater domain visual prompts
into the segmentation network. We further design an out-of-the-box underwater
Salient Feature Prompter Generator (SFPG) to automatically generate salient
prompters instead of explicitly providing foreground points or boxes as prompts
in SAM. Comprehensive experimental results show that our USIS-SAM method can
achieve superior performance on USIS10K datasets compared to the
state-of-the-art methods. Datasets and codes are released on
https://github.com/LiamLian0727/USIS10K.

17 Jul 2025



Gravitational wave (GW) observations are expected to serve as a powerful and independent probe of the expansion history of the universe. By providing direct and calibration-free measurements of luminosity distances through waveform analysis, GWs provide a fundamentally different and potentially more robust approach to measuring cosmic-scale distances compared to traditional electromagnetic observations, which is known as the standard siren method. In this review, we present an overview of recent developments in GW standard siren cosmology, the latest observational results, and prospects for constraining cosmological parameters using future GW detections. We first introduce standard sirens based on how redshift information is obtained and outline the Bayesian framework used in cosmological parameter estimation. We then review the measurements on the Hubble constant from the LIGO-Virgo-KAGRA network and present the potential role of future standard siren observations in cosmological parameter estimations. A central focus of this review is the unique ability of GW observations to break cosmological parameter degeneracies inherent in the EM observations. Since the cosmological parameter degeneracy directions of GW and EM observations are quite different (roughly orthogonal in some cases), their combination can significantly improve constraints on cosmological parameters. This complementarity is expected to become one of the most critical advantages for GW standard siren cosmology. Looking forward, we highlight the importance of combining GW standard sirens with other emerging late-universe cosmological probes such as fast radio bursts, 21 cm intensity mapping, and strong gravitational lensing to forge a precise cosmological probe for exploring the late universe. Finally, we introduce the challenges and the role of machine learning in future standard siren analysis.

02 May 2025
Time series anomaly detection holds notable importance for risk identification and fault detection across diverse application domains. Unsupervised learning methods have become popular because they have no requirement for labels. However, due to the challenges posed by the multiplicity of abnormal patterns, the sparsity of anomalies, and the growth of data scale and complexity, these methods often fail to capture robust and representative dependencies within the time series for identifying anomalies. To enhance the ability of models to capture normal patterns of time series and avoid the retrogression of modeling ability triggered by the dependencies on high-quality prior knowledge, we propose a differencing-based contrastive representation learning framework for time series anomaly detection (DConAD). Specifically, DConAD generates differential data to provide additional information about time series and utilizes transformer-based architecture to capture spatiotemporal dependencies, which enhances the robustness of unbiased representation learning ability. Furthermore, DConAD implements a novel KL divergence-based contrastive learning paradigm that only uses positive samples to avoid deviation from reconstruction and deploys the stop-gradient strategy to compel convergence. Extensive experiments on five public datasets show the superiority and effectiveness of DConAD compared with nine baselines. The code is available at this https URL.

30 Aug 2024
Temporal knowledge graph (TKG) reasoning predicts future events based on
historical data, but it's challenging due to the complex semantic and
hierarchical information involved. Existing Euclidean models excel at capturing
semantics but struggle with hierarchy. Conversely, hyperbolic models manage
hierarchical features well but fail to represent complex semantics due to
limitations in shallow models' parameters and the absence of proper
normalization in deep models relying on the L2 norm. Current solutions, as
curvature transformations, are insufficient to address these issues. In this
work, a novel hybrid geometric space approach that leverages the strengths of
both Euclidean and hyperbolic models is proposed. Our approach transitions from
single-space to multi-space parameter modeling, effectively capturing both
semantic and hierarchical information. Initially, complex semantics are
captured through a fact co-occurrence and autoregressive method with
normalizations in Euclidean space. The embeddings are then transformed into
Tangent space using a scaling mechanism, preserving semantic information while
relearning hierarchical structures through a query-candidate separated modeling
approach, which are subsequently transformed into Hyperbolic space. Finally, a
hybrid inductive bias for hierarchical and semantic learning is achieved by
combining hyperbolic and Euclidean scoring functions through a learnable
query-specific mixing coefficient, utilizing embeddings from hyperbolic and
Euclidean spaces. Experimental results on four TKG benchmarks demonstrate that
our method reduces error relatively by up to 15.0% in mean reciprocal rank on
YAGO compared to previous single-space models. Additionally, enriched
visualization analysis validates the effectiveness of our approach, showing
adaptive capabilities for datasets with varying levels of semantic and
hierarchical complexity.

20 Jun 2025
Large Language Models (LLMs) are rapidly transforming the landscape of digital content creation. However, the prevalent black-box Application Programming Interface (API) access to many LLMs introduces significant challenges in accountability, governance, and security. LLM fingerprinting, which aims to identify the source model by analyzing statistical and stylistic features of generated text, offers a potential solution. Current progress in this area is hindered by a lack of dedicated datasets and the need for efficient, practical methods that are robust against adversarial manipulations. To address these challenges, we introduce FD-Dataset, a comprehensive bilingual fingerprinting benchmark comprising 90,000 text samples from 20 famous proprietary and open-source LLMs. Furthermore, we present FDLLM, a novel fingerprinting method that leverages parameter-efficient Low-Rank Adaptation (LoRA) to fine-tune a foundation model. This approach enables LoRA to extract deep, persistent features that characterize each source LLM. Through our analysis, we find that LoRA adaptation promotes the aggregation of outputs from the same LLM in representation space while enhancing the separation between different LLMs. This mechanism explains why LoRA proves particularly effective for LLM fingerprinting. Extensive empirical evaluations on FD-Dataset demonstrate FDLLM's superiority, achieving a Macro F1 score 22.1% higher than the strongest baseline. FDLLM also exhibits strong generalization to newly released models, achieving an average accuracy of 95% on unseen models. Notably, FDLLM remains consistently robust under various adversarial attacks, including polishing, translation, and synonym substitution. Experimental results show that FDLLM reduces the average attack success rate from 49.2% (LM-D) to 23.9%.

12 May 2025
TUGS introduces a physics-based compact representation of underwater scenes by leveraging tensorized Gaussians. This approach accurately models light propagation and achieves superior reconstruction quality, significantly reduced memory footprints, and faster rendering speeds compared to previous methods, making it suitable for practical underwater robotic applications.
There are no more papers matching your filters at the moment.
