
31 Jan 2024

In this paper, we propose two new performance metrics, coined the Version
Innovation Age (VIA) and the Age of Incorrect Version (AoIV) for real-time
monitoring of a two-state Markov process over an unreliable channel. We analyze
their performance under the change-aware, semantics-aware, and randomized
stationary sampling and transmission policies. We derive closed-form
expressions for the distribution and the average of VIA, AoIV, and AoII for
these policies. We then formulate and solve an optimization problem to minimize
the average VIA, subject to constraints on the time-averaged sampling cost and
time-averaged reconstruction error. Finally, we compare the performance of
various sampling and transmission policies and identify the conditions under
which each policy outperforms the others in optimizing the proposed metrics.

29 Sep 2025

A self-supervised post-training framework, Visual Jigsaw, enhances Multimodal Large Language Models' (MLLMs) intrinsic visual understanding by framing visual ordering as a verifiable task for reinforcement learning. This method, applied across images, videos, and 3D data, yields quantitative improvements such as a +6.00 gain on MMVP for image understanding and +17.11 on DA-2K for 3D depth perception.

20 Nov 2025


RoMa v2 introduces a dense feature matching model that establishes new state-of-the-art accuracy and robustness across diverse benchmarks by leveraging DINOv3 features and novel multi-view context. The model achieves 1.7 times faster throughput than its predecessor while maintaining a similar memory footprint and also predicts pixel-wise error covariances.

02 Jun 2024




GLaMM enables Large Multimodal Models to generate pixel-level segmentation masks directly within natural language conversations, addressing a critical limitation in dense visual grounding. Researchers at MBZUAI and collaborating institutions developed a new architecture and the massive, automatically annotated Grounding-anything Dataset (GranD), achieving state-of-the-art performance in pixel-grounded conversation generation and referring expression segmentation.

11 Dec 2023
RoMa introduces a robust dense feature matching model that combines frozen DINOv2 features for coarse matching with specialized ConvNet features for fine localization, alongside a Transformer decoder and a scale-aware loss formulation. The approach achieves state-of-the-art performance across multiple benchmarks, including a 36% improvement in mean Average Accuracy on the WxBS benchmark for robustness.

14 Oct 2025

Recent advances in reinforcement learning (RL) have delivered strong reasoning capabilities in natural image domains, yet their potential for Earth Observation (EO) remains largely unexplored. EO tasks introduce unique challenges, spanning referred object detection, image or region captioning, change detection, grounding, and temporal analysis, that demand task aware reasoning. We propose a novel post training framework that incorporates task aware rewards to enable effective adaptation of reasoning based RL models to diverse EO tasks. This training strategy enhances reasoning capabilities for remote sensing images, stabilizes optimization, and improves robustness. Extensive experiments across multiple EO benchmarks show consistent performance gains over state of the art generic and specialized vision language models. Code and models will be released publicly at this https URL .

07 Mar 2025
Researchers from multiple European institutions introduce two novel prompting techniques for automated ontology generation using LLMs, demonstrating significant improvements in modeling complex ontological requirements while establishing comprehensive evaluation criteria through a new benchmark dataset of 100 competency questions across 10 ontologies.

11 Sep 2021
Rensselaer Polytechnic InstituteUniversity of Bonn University of SouthamptonUniversität Stuttgart
University of SouthamptonUniversität Stuttgart Rutgers UniversitySapienza University of RomeUniversidad de ChileLinköping UniversityVrije UniversiteitUniversidad de OviedoUniversity of BariUniversität PaderbornWU ViennaUniversität Koblenz–Landaudata.worldÉcole des mines de Saint-ÉtienneUniversity of Milano
Bicocca
Rutgers UniversitySapienza University of RomeUniversidad de ChileLinköping UniversityVrije UniversiteitUniversidad de OviedoUniversity of BariUniversität PaderbornWU ViennaUniversität Koblenz–Landaudata.worldÉcole des mines de Saint-ÉtienneUniversity of Milano
Bicocca
University of SouthamptonUniversität StuttgartRutgers UniversitySapienza University of RomeUniversidad de ChileLinköping UniversityVrije UniversiteitUniversidad de OviedoUniversity of BariUniversität PaderbornWU ViennaUniversität Koblenz–Landaudata.worldÉcole des mines de Saint-ÉtienneUniversity of Milano
BicoccaThis collaborative tutorial from 18 leading researchers provides a comprehensive, unifying summary of knowledge graphs, consolidating fragmented knowledge from diverse fields. It defines core concepts, surveys techniques across data models, knowledge representation, and AI, and outlines lifecycle management and governance for knowledge graphs.

10 Jan 2025



This paper introduces a novel approach to enhance step-by-step visual reasoning in large language models through a comprehensive framework

25 Jul 2023
A comprehensive survey of vision foundational models categorizes them based on prompting mechanisms into textually prompted, visually prompted, heterogeneous modality-based, and embodied models. It details their architectures, training objectives, and diverse applications, highlighting capabilities like zero-shot learning and multimodal understanding.

21 Mar 2024

AdaIR presents an adaptive all-in-one image restoration network that leverages frequency mining and modulation to handle various degradation types using a single model. The approach consistently outperforms previous state-of-the-art all-in-one methods, achieving an average gain of 0.63 dB PSNR over PromptIR across multiple degradation tasks.

05 Dec 2024
A core problem in statistics and probabilistic machine learning is to compute probability distributions and expectations. This is the fundamental problem of Bayesian statistics and machine learning, which frames all inference as expectations with respect to the posterior distribution. The key challenge is to approximate these intractable expectations. In this tutorial, we review sequential Monte Carlo (SMC), a random-sampling-based class of methods for approximate inference. First, we explain the basics of SMC, discuss practical issues, and review theoretical results. We then examine two of the main user design choices: the proposal distributions and the so called intermediate target distributions. We review recent results on how variational inference and amortization can be used to learn efficient proposals and target distributions. Next, we discuss the SMC estimate of the normalizing constant, how this can be used for pseudo-marginal inference and inference evaluation. Throughout the tutorial we illustrate the use of SMC on various models commonly used in machine learning, such as stochastic recurrent neural networks, probabilistic graphical models, and probabilistic programs.

28 Nov 2025
Video-R2 introduces a reinforcement learning framework that enhances multimodal language models' ability to provide consistent and visually grounded reasoning for video content. It achieves this by employing a novel Temporal Alignment Reward, gated by reasoning consistency, resulting in improved logical coherence and higher accuracy across diverse video benchmarks.

24 Oct 2025

Previous dominant methods for scene flow estimation focus mainly on input from two consecutive frames, neglecting valuable information in the temporal domain. While recent trends shift towards multi-frame reasoning, they suffer from rapidly escalating computational costs as the number of frames grows. To leverage temporal information more efficiently, we propose DeltaFlow (Flow), a lightweight 3D framework that captures motion cues via a scheme, extracting temporal features with minimal computational cost, regardless of the number of frames. Additionally, scene flow estimation faces challenges such as imbalanced object class distributions and motion inconsistency. To tackle these issues, we introduce a Category-Balanced Loss to enhance learning across underrepresented classes and an Instance Consistency Loss to enforce coherent object motion, improving flow accuracy. Extensive evaluations on the Argoverse 2, Waymo and nuScenes datasets show that Flow achieves state-of-the-art performance with up to 22% lower error and faster inference compared to the next-best multi-frame supervised method, while also demonstrating a strong cross-domain generalization ability. The code is open-sourced at this https URL along with trained model weights.

25 Mar 2025
VideoGLaMM introduces a Large Multimodal Model designed to achieve pixel-level spatio-temporal visual grounding in videos from textual prompts, addressing a common limitation in current Video-LMMs. The model consistently outperforms existing baselines on tasks like Grounded Conversation Generation (mIOU 62.34) and Referring Video Segmentation (J&F 69.5 on Ref-DAVIS-17).

09 Oct 2025
ThinkGeo introduces the first agentic benchmark specifically designed for evaluating tool-augmented large language models on complex, multi-step remote sensing tasks using real Earth Observation imagery. The evaluation reveals that proprietary models achieve higher overall accuracy, but all tested agents show persistent challenges in precise spatial reasoning and robust multimodal grounding, particularly with SAR data.

24 Jun 2025
Mathematical reasoning in real-world video settings presents a fundamentally different challenge than in static images or text. It requires interpreting fine-grained visual information, accurately reading handwritten or digital text, and integrating spoken cues, often dispersed non-linearly over time. In such multimodal contexts, success hinges not just on perception, but on selectively identifying and integrating the right contextual details from a rich and noisy stream of content. To this end, we introduce VideoMathQA, a benchmark designed to evaluate whether models can perform such temporally extended cross-modal reasoning on videos. The benchmark spans 10 diverse mathematical domains, covering videos ranging from 10 seconds to over 1 hour. It requires models to interpret structured visual content, understand instructional narratives, and jointly ground concepts across visual, audio, and textual modalities. We employ graduate-level experts to ensure high quality, totaling over man-hours of annotation. To reflect real-world scenarios, questions are designed around three core reasoning challenges: direct problem solving, where answers are grounded in the presented question; conceptual transfer, which requires applying learned methods to new problems; and deep instructional comprehension, involving multi-step reasoning over extended explanations and partially worked-out solutions. Each question includes multi-step reasoning annotations, enabling fine-grained diagnosis of model capabilities. Through this benchmark, we highlight the limitations of existing approaches and establish a systematic evaluation framework for models that must reason, rather than merely perceive, across temporally extended and modality-rich mathematical problem settings. Our benchmark and evaluation code are available at: this https URL

29 Sep 2025

Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at this https URL.

19 Aug 2025
Researchers from MBZUAI and collaborating institutions introduced Dense-WebVid-CoVR, a new large-scale dataset for Composed Video Retrieval (CoVR) featuring modification texts that are seven times more detailed than prior benchmarks, and proposed a unified fusion model architecture. Their approach achieved 71.26% Recall@1 on the new dataset, surpassing prior methods by 3.4%, and demonstrated a 3x faster inference speed.
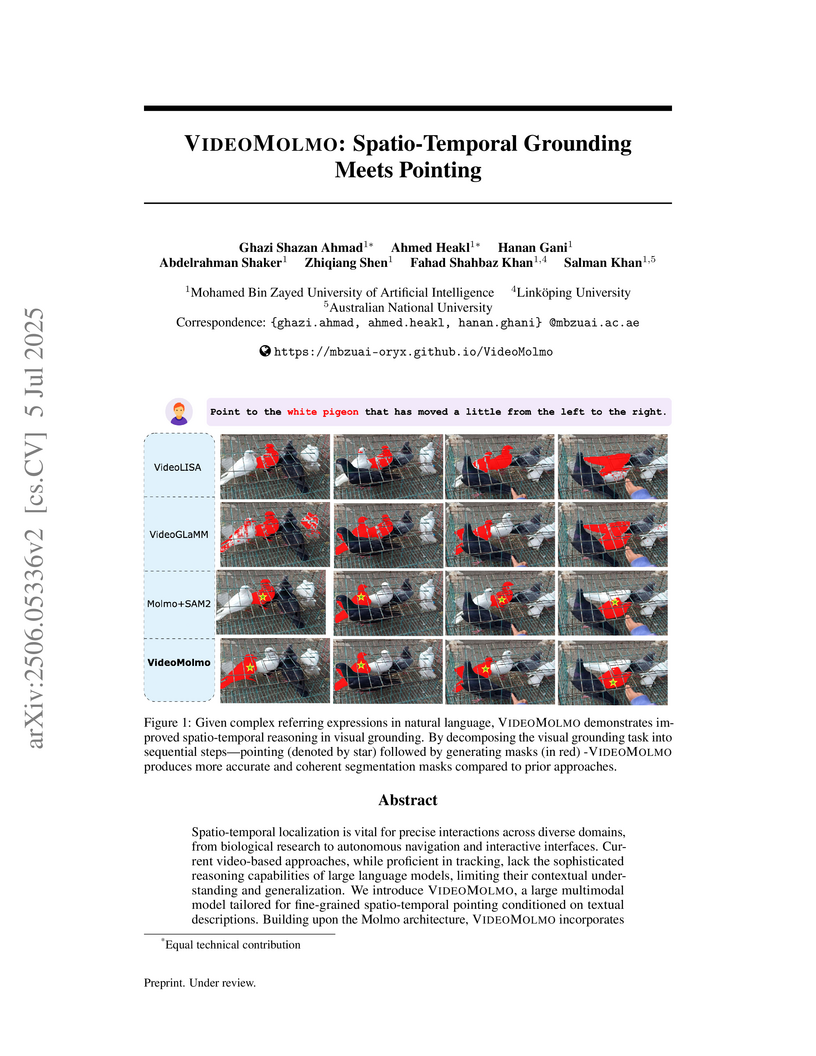
05 Jul 2025


Spatio-temporal localization is vital for precise interactions across diverse domains, from biological research to autonomous navigation and interactive interfaces. Current video-based approaches, while proficient in tracking, lack the sophisticated reasoning capabilities of large language models, limiting their contextual understanding and generalization. We introduce VideoMolmo, a large multimodal model tailored for fine-grained spatio-temporal pointing conditioned on textual descriptions. Building upon the Molmo architecture, VideoMolmo incorporates a temporal module utilizing an attention mechanism to condition each frame on preceding frames, ensuring temporal consistency. Additionally, our novel temporal mask fusion pipeline employs SAM2 for bidirectional point propagation, significantly enhancing coherence across video sequences. This two-step decomposition, i.e., first using the LLM to generate precise pointing coordinates, then relying on a sequential mask-fusion module to produce coherent segmentation, not only simplifies the task for the language model but also enhances interpretability. Due to the lack of suitable datasets, we curate a comprehensive dataset comprising 72k video-caption pairs annotated with 100k object points. To evaluate the generalization of VideoMolmo, we introduce VPoS-Bench, a challenging out-of-distribution benchmark spanning five real-world scenarios: Cell Tracking, Egocentric Vision, Autonomous Driving, Video-GUI Interaction, and Robotics. We also evaluate our model on Referring Video Object Segmentation (Refer-VOS) and Reasoning VOS tasks. In comparison to existing models, VideoMolmo substantially improves spatio-temporal pointing accuracy and reasoning capability. Our code and models are publicly available at this https URL.
There are no more papers matching your filters at the moment.
