
26 Oct 2023

Researchers from Yandex, MIPT, and HSE conducted a rigorous evaluation of deep learning architectures for tabular data, introducing a ResNet-like baseline and the FT-Transformer. Their work clarifies that while the FT-Transformer achieves state-of-the-art deep learning performance and excels on certain datasets, Gradient Boosted Decision Trees retain superiority on others, underscoring that no single model universally outperforms.

08 Dec 2022

Researchers at the Neural Networks and Deep Learning Lab at MIPT and AIRI developed the Recurrent Memory Transformer (RMT), an architecture that extends Transformer models' ability to process long sequences by incorporating explicit, learnable memory tokens. RMT achieves superior long-term dependency handling and memory efficiency on algorithmic tasks and language modeling, while also enabling existing pre-trained models to process significantly longer texts for classification tasks.

01 Oct 2025
Researchers from T-Tech and HSE University investigated the internal computational changes induced by reinforcement learning (RL) in large language models (LLMs) to enhance reasoning, utilizing lightweight steering vectors as an interpretable probe. The study identified distinct, layer-specific mechanisms responsible for improving mathematical reasoning, such as token substitution at the last layer and the suppression of non-English tokens in mid-layers.

06 Oct 2025
Researchers introduce PsiloQA, a large-scale, multilingual dataset with span-level hallucination annotations for large language models, generated via an automated, cost-effective pipeline using GPT-4o. Models fine-tuned on PsiloQA, especially multilingual encoder architectures like mmBERT, demonstrate superior performance in identifying factual errors and exhibit robust cross-lingual and cross-dataset transferability.

17 Jul 2025
Researchers at Sber AI developed ∇NABLA, an adaptive sparse attention mechanism for video Diffusion Transformers, which achieves up to 2.67x faster inference and 1.46x faster training while maintaining video generation quality comparable to full attention models. This approach combines a static local attention pattern with a dynamic, content-aware selection of important blocks, enabling efficient processing of high-resolution and long-duration video.
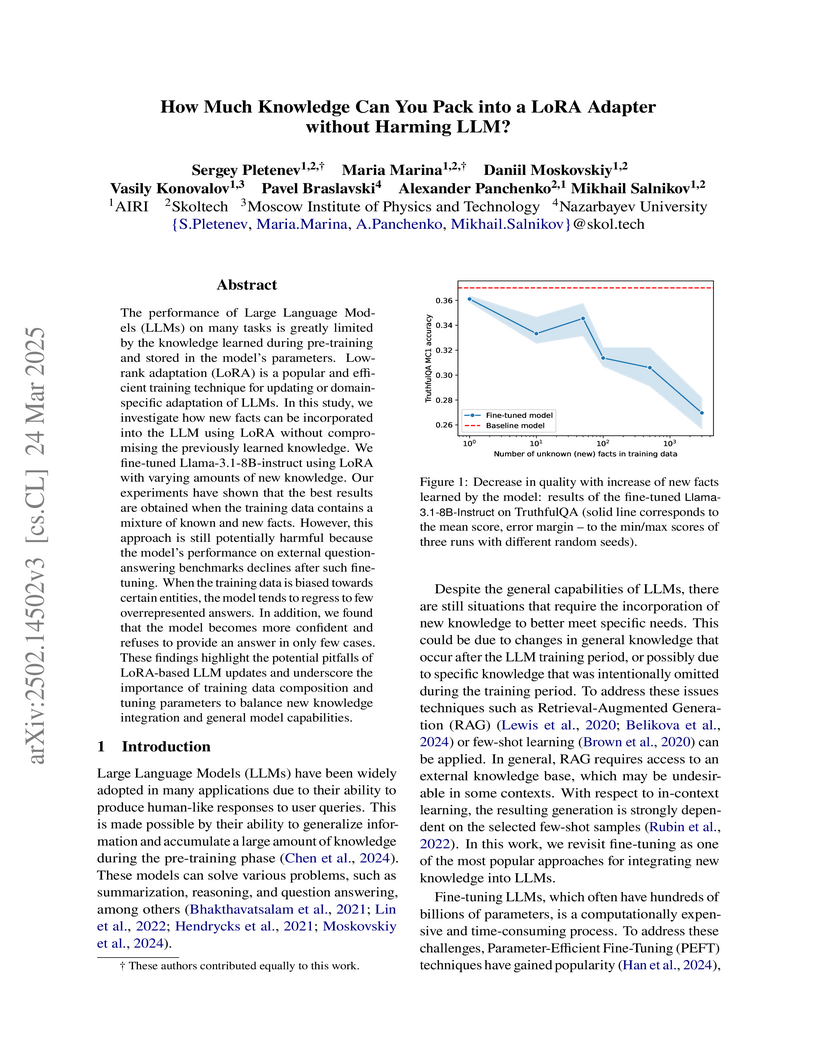
24 Mar 2025
A study examined the extent to which new factual knowledge can be integrated into Large Language Models using LoRA adapters, demonstrating that while LoRA reliably learns hundreds of new facts, this process frequently degrades general reasoning abilities and truthfulness, and can lead to models confidently generating incorrect answers.

06 Aug 2025
A 3D scene graph represents a compact scene model by capturing both the objects present and the semantic relationships between them, making it a promising structure for robotic applications. To effectively interact with users, an embodied intelligent agent should be able to answer a wide range of natural language queries about the surrounding 3D environment. Large Language Models (LLMs) are beneficial solutions for user-robot interaction due to their natural language understanding and reasoning abilities. Recent methods for learning scene representations have shown that adapting these representations to the 3D world can significantly improve the quality of LLM responses. However, existing methods typically rely only on geometric information, such as object coordinates, and overlook the rich semantic relationships between objects. In this work, we propose 3DGraphLLM, a method for constructing a learnable representation of a 3D scene graph that explicitly incorporates semantic relationships. This representation is used as input to LLMs for performing 3D vision-language tasks. In our experiments on popular ScanRefer, Multi3DRefer, ScanQA, Sqa3D, and Scan2cap datasets, we demonstrate that our approach outperforms baselines that do not leverage semantic relationships between objects. The code is publicly available at this https URL.

05 Mar 2025


Skoltech and CNRS researchers leverage sparse autoencoders to extract interpretable features from LLM residual streams for artificial text detection, revealing distinct patterns in AI-generated content while demonstrating superior classification performance and robustness through innovative feature steering and systematic analysis of model behaviors across different domains.

07 Jun 2019

Researchers at Yandex and collaborating universities demonstrated that only a small subset of Transformer attention heads are crucial for neural machine translation, identifying specialized functions like positional, syntactic, and rare word attention. Their novel pruning method allows removing up to 90% of encoder heads with minimal BLEU score degradation, enhancing efficiency and interpretability.

16 Oct 2025

Fine-tuning Large Language Models (LLMs) is essential for adapting pre-trained models to downstream tasks. Yet traditional first-order optimizers such as Stochastic Gradient Descent (SGD) and Adam incur prohibitive memory and computational costs that scale poorly with model size. In this paper, we investigate zero-order (ZO) optimization methods as a memory- and compute-efficient alternative, particularly in the context of parameter-efficient fine-tuning techniques like LoRA. We propose , a ZO momentum-based algorithm that extends ZO SignSGD, requiring the same number of parameters as the standard ZO SGD and only function evaluations per iteration. To the best of our knowledge, this is the first study to establish rigorous convergence guarantees for SignSGD in the stochastic ZO case. We further propose , a novel ZO extension of the Muon optimizer that leverages the matrix structure of model parameters, and we provide its convergence rate under arbitrary stochastic noise. Through extensive experiments on challenging LLM fine-tuning benchmarks, we demonstrate that the proposed algorithms meet or exceed the convergence quality of standard first-order methods, achieving significant memory reduction. Our theoretical and empirical results establish new ZO optimization methods as a practical and theoretically grounded approach for resource-constrained LLM adaptation. Our code is available at this https URL

16 Feb 2021
Transformer-based models have achieved state-of-the-art results in many natural language processing tasks. The self-attention architecture allows transformer to combine information from all elements of a sequence into context-aware representations. However, information about the context is stored mostly in the same element-wise representations. This might limit the processing of properties related to the sequence as a whole more difficult. Adding trainable memory to selectively store local as well as global representations of a sequence is a promising direction to improve the Transformer model. Memory-augmented neural networks (MANNs) extend traditional neural architectures with general-purpose memory for representations. MANNs have demonstrated the capability to learn simple algorithms like Copy or Reverse and can be successfully trained via backpropagation on diverse tasks from question answering to language modeling outperforming RNNs and LSTMs of comparable complexity. In this work, we propose and study few extensions of the Transformer baseline (1) by adding memory tokens to store non-local representations, (2) creating memory bottleneck for the global information, (3) controlling memory update with dedicated layer. We evaluate these memory augmented Transformers and demonstrate that presence of memory positively correlates with the model performance for machine translation and language modelling tasks. Augmentation of pre-trained masked language model with memory tokens shows mixed results for tasks from GLUE benchmark. Visualization of attention patterns over the memory suggest that it improves the model's ability to process a global context.

25 Sep 2025

While traditional Deep Learning (DL) optimization methods treat all training samples equally, Distributionally Robust Optimization (DRO) adaptively assigns importance weights to different samples. However, a significant gap exists between DRO and current DL practices. Modern DL optimizers require adaptivity and the ability to handle stochastic gradients, as these methods demonstrate superior performance. Additionally, for practical applications, a method should allow weight assignment not only to individual samples, but also to groups of objects (for example, all samples of the same class). This paper aims to bridge this gap by introducing ALSO Adaptive Loss Scaling Optimizer an adaptive algorithm for a modified DRO objective that can handle weight assignment to sample groups. We prove the convergence of our proposed algorithm for non-convex objectives, which is the typical case for DL models. Empirical evaluation across diverse Deep Learning tasks, from Tabular DL to Split Learning tasks, demonstrates that ALSO outperforms both traditional optimizers and existing DRO methods.

29 Apr 2025
 University of California, Santa Barbara
University of California, Santa Barbara University of Copenhagen
University of Copenhagen Cohere
Cohere ETH ZürichCONICET
ETH ZürichCONICET Aalborg University
Aalborg University Emory UniversityTU DresdenUppsala UniversityUniversidad de Buenos Aires
Emory UniversityTU DresdenUppsala UniversityUniversidad de Buenos Aires Karlsruhe Institute of TechnologyFederal University of São CarlosMoscow Institute of Physics and TechnologyUniversity of BathUniversity of MontrealUniversity of São PauloComenius University in BratislavaPioneer Center for AICiscoNational University, PhilippinesHSE University (Higher School of Economics)
Karlsruhe Institute of TechnologyFederal University of São CarlosMoscow Institute of Physics and TechnologyUniversity of BathUniversity of MontrealUniversity of São PauloComenius University in BratislavaPioneer Center for AICiscoNational University, PhilippinesHSE University (Higher School of Economics)

The evaluation of vision-language models (VLMs) has mainly relied on
English-language benchmarks, leaving significant gaps in both multilingual and
multicultural coverage. While multilingual benchmarks have expanded, both in
size and languages, many rely on translations of English datasets, failing to
capture cultural nuances. In this work, we propose Kaleidoscope, as the most
comprehensive exam benchmark to date for the multilingual evaluation of
vision-language models. Kaleidoscope is a large-scale, in-language multimodal
benchmark designed to evaluate VLMs across diverse languages and visual inputs.
Kaleidoscope covers 18 languages and 14 different subjects, amounting to a
total of 20,911 multiple-choice questions. Built through an open science
collaboration with a diverse group of researchers worldwide, Kaleidoscope
ensures linguistic and cultural authenticity. We evaluate top-performing
multilingual vision-language models and find that they perform poorly on
low-resource languages and in complex multimodal scenarios. Our results
highlight the need for progress on culturally inclusive multimodal evaluation
frameworks.

03 Oct 2024
New scoring methods based on internal attention head mechanics, called QK-score and Attention-score, reveal an LLM's latent knowledge in multiple-choice question answering tasks. By identifying specific "select-and-copy" attention heads, the approach improves accuracy by 7-16% on LLaMA2-7B and up to 10% on larger LLaMA models across various benchmarks, while enhancing robustness to prompt variations.

27 Sep 2025
Physics-informed neural networks (PINNs) have gained prominence in recent years and are now effectively used in a number of applications. However, their performance remains unstable due to the complex landscape of the loss function. To address this issue, we reformulate PINN training as a nonconvex-strongly concave saddle-point problem. After establishing the theoretical foundation for this approach, we conduct an extensive experimental study, evaluating its effectiveness across various tasks and architectures. Our results demonstrate that the proposed method outperforms the current state-of-the-art techniques.

16 Oct 2025
The widespread utilization of language models in modern applications is inconceivable without Parameter-Efficient Fine-Tuning techniques, such as low-rank adaptation (), which adds trainable adapters to selected layers. Although may obtain accurate solutions, it requires significant memory to train large models and intuition on which layers to add adapters. In this paper, we propose a novel method, , which overcomes this issue by adaptive selection of the most critical heads throughout the optimization process. As a result, we can significantly reduce the number of trainable parameters while maintaining the capability to obtain consistent or even superior metric values. We conduct experiments for a series of competitive benchmarks and DeBERTa, BART, and Llama models, comparing our method with different adaptive approaches. The experimental results demonstrate the efficacy of and the superior performance of in almost all cases.

29 Oct 2024



Electrons in solids owe their properties to the periodic potential landscapes they experience. The advent of moiré lattices has revolutionized our ability to engineer such landscapes on nanometer scales, leading to numerous groundbreaking discoveries. Despite this progress, direct imaging of these electrostatic potential landscapes remains elusive. In this work, we introduce the Atomic Single Electron Transistor (SET), a novel scanning probe utilizing a single atomic defect in a van der Waals (vdW) material, which serves as an ultrasensitive, high-resolution potential imaging sensor. Built upon the quantum twisting microscope (QTM) platform, this probe leverages the QTM's distinctive capability to form a pristine, scannable 2D interface between vdW heterostructures. Using the Atomic SET, we present the first direct images of the electrostatic potential in one of the most canonical moiré interfaces: graphene aligned to hexagonal boron nitride. Our results reveal that this potential exhibits an approximate C6 symmetry, has minimal dependence on the carrier density, and has a substantial magnitude of ~60 mV even in the absence of carriers. Theoretically, the observed symmetry can only be explained by a delicate interplay of physical mechanisms with competing symmetries. Intriguingly, the magnitude of the measured potential significantly exceeds theoretical predictions, suggesting that current understanding may be incomplete. With a spatial resolution of 1 nm and a sensitivity to detect the potential of even a few millionths of an electron charge, the Atomic SET opens the door for ultrasensitive imaging of charge order and thermodynamic properties for a range of quantum phenomena, including various symmetry-broken phases, quantum crystals, vortex charges, and fractionalized quasiparticles.

04 Apr 2024

We propose a novel architecture and method of explainable classification with
Concept Bottleneck Models (CBMs). While SOTA approaches to Image Classification
task work as a black box, there is a growing demand for models that would
provide interpreted results. Such a models often learn to predict the
distribution over class labels using additional description of this target
instances, called concepts. However, existing Bottleneck methods have a number
of limitations: their accuracy is lower than that of a standard model and CBMs
require an additional set of concepts to leverage. We provide a framework for
creating Concept Bottleneck Model from pre-trained multi-modal encoder and new
CLIP-like architectures. By introducing a new type of layers known as Concept
Bottleneck Layers, we outline three methods for training them: with
-loss, contrastive loss and loss function based on Gumbel-Softmax
distribution (Sparse-CBM), while final FC layer is still trained with
Cross-Entropy. We show a significant increase in accuracy using sparse hidden
layers in CLIP-based bottleneck models. Which means that sparse representation
of concepts activation vector is meaningful in Concept Bottleneck Models.
Moreover, with our Concept Matrix Search algorithm we can improve CLIP
predictions on complex datasets without any additional training or fine-tuning.
The code is available at: this https URL

29 May 2025
Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) systems
are increasingly deployed in industry applications, yet their reliability
remains hampered by challenges in detecting hallucinations. While supervised
state-of-the-art (SOTA) methods that leverage LLM hidden states -- such as
activation tracing and representation analysis -- show promise, their
dependence on extensively annotated datasets limits scalability in real-world
applications. This paper addresses the critical bottleneck of data annotation
by investigating the feasibility of reducing training data requirements for two
SOTA hallucination detection frameworks: Lookback Lens, which analyzes
attention head dynamics, and probing-based approaches, which decode internal
model representations. We propose a methodology combining efficient
classification algorithms with dimensionality reduction techniques to minimize
sample size demands while maintaining competitive performance. Evaluations on
standardized question-answering RAG benchmarks show that our approach achieves
performance comparable to strong proprietary LLM-based baselines with only 250
training samples. These results highlight the potential of lightweight,
data-efficient paradigms for industrial deployment, particularly in
annotation-constrained scenarios.

29 Aug 2025
In this paper, we focus on the problem of minimizing a continuously differentiable convex objective function, . Recently, Malitsky (2020); Alacaoglu et al.(2023) developed an adaptive first-order method, GRAAL. This algorithm computes stepsizes by estimating the local curvature of the objective function without any line search procedures or hyperparameter tuning, and attains the standard iteration complexity of fixed-stepsize gradient descent for -smooth functions. However, a natural question arises: is it possible to accelerate the convergence of GRAAL to match the optimal complexity of the accelerated gradient descent of Nesterov (1983)? Although some attempts have been made by Li and Lan (2025); Suh and Ma (2025), the ability of existing accelerated algorithms to adapt to the local curvature of the objective function is highly limited. We resolve this issue and develop GRAAL with Nesterov acceleration, which can adapt its stepsize to the local curvature at a geometric, or linear, rate just like non-accelerated GRAAL. We demonstrate the adaptive capabilities of our algorithm by proving that it achieves near-optimal iteration complexities for -smooth functions, as well as under a more general -smoothness assumption (Zhang et al., 2019).
There are no more papers matching your filters at the moment.
