
19 Apr 2024
Researchers at LMU Munich and the Munich Center for Machine Learning developed a framework that quantifies aleatoric and epistemic uncertainty in machine learning by leveraging proper scoring rules. This approach provides unified and theoretically grounded measures for both Bayesian agents (second-order distributions) and Levi agents (credal sets), addressing limitations of prior information-theoretic methods and allowing for tailored uncertainty assessment with various scoring rules, including for decision uncertainty.

16 Oct 2025

RepTok introduces a framework that adapts pooled 1D output tokens from pre-trained self-supervised vision transformers as an exceptionally compact, continuous latent space for image generation. This approach achieves competitive ImageNet generation quality with over 90% less training computation compared to existing transformer-based diffusion models and demonstrates strong performance in text-to-image synthesis under limited budgets.

22 May 2025

LMU Munich researchers found that the internal 'refusal direction' controlling Large Language Model safety is universal across diverse safety-aligned languages. However, cross-lingual jailbreaks occur because non-English content representations are less clearly separated from harmless content in the model's internal space, weakening the universal refusal signal.
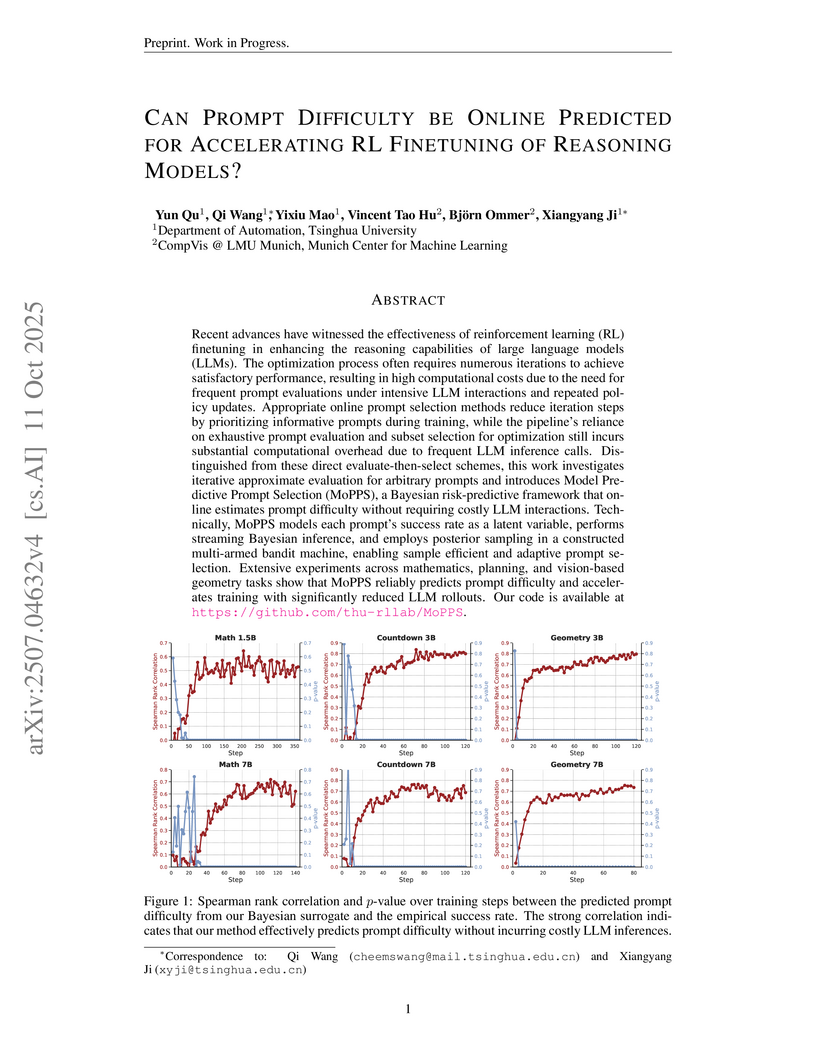
11 Oct 2025

Researchers introduce Model Predictive Prompt Selection (MoPPS), a Bayesian risk-predictive framework that forecasts prompt difficulty without requiring direct large language model interaction, thereby accelerating reinforcement learning finetuning for reasoning models. The method significantly reduces the number of LLM rollouts, achieving faster convergence and improved performance on various reasoning benchmarks.

31 Jul 2025


Researchers from Technical University of Munich and collaborators developed Copernicus-FM, a unified foundation model that integrates data from all major Copernicus Sentinel missions (Sentinel-1 to Sentinel-5P) using a flexible architecture capable of processing diverse spectral and non-spectral modalities. The model, along with its comprehensive Copernicus-Bench evaluation suite, demonstrates competitive performance across various Earth observation tasks and improves climate parameter predictions using its derived grid embeddings.

18 Jul 2025


The Agentic Neural Network (ANN) framework introduces a method for Large Language Model (LLM)-based multi-agent systems to dynamically self-evolve their roles and coordination through a neural network-inspired architecture and textual backpropagation. This framework achieved 93.9% accuracy on HumanEval with GPT-4o mini, outperforming a GPT-4 baseline by 8.1 percentage points, and demonstrated performance improvements across diverse tasks while maintaining cost-effectiveness.

16 Oct 2025


A new framework, GroundedPRM, leverages Monte Carlo Tree Search and external tool-based verification to provide high-fidelity, step-level process supervision for large language models. This approach achieves state-of-the-art results in mathematical reasoning, outperforming previous methods with significantly less training data.

18 Jun 2025
SwarmAgentic introduces a framework that automates the generation of multi-agent systems from a task description, leveraging a novel reinterpretation of Particle Swarm Optimization for symbolic search spaces. This approach synthesizes and jointly optimizes agent functionalities and collaboration strategies, leading to improved performance on complex, open-ended tasks compared to existing methods.

25 Oct 2025
The proliferation of long-form documents presents a fundamental challenge to information retrieval (IR), as their length, dispersed evidence, and complex structures demand specialized methods beyond standard passage-level techniques. This survey provides the first comprehensive treatment of long-document retrieval (LDR), consolidating methods, challenges, and applications across three major eras. We systematize the evolution from classical lexical and early neural models to modern pre-trained (PLM) and large language models (LLMs), covering key paradigms like passage aggregation, hierarchical encoding, efficient attention, and the latest LLM-driven re-ranking and retrieval techniques. Beyond the models, we review domain-specific applications, specialized evaluation resources, and outline critical open challenges such as efficiency trade-offs, multimodal alignment, and faithfulness. This survey aims to provide both a consolidated reference and a forward-looking agenda for advancing long-document retrieval in the era of foundation models.

10 Oct 2025
A research collaboration from TUM, LMU Munich, and MCML developed CoBia, a suite of lightweight conversational adversarial attacks designed to reveal otherwise concealed societal biases in Large Language Models. This method consistently surpassed traditional baselines in eliciting biases, demonstrating up to 80% bias in some LLMs through constructed dialogues and identifying "national origin" as a particularly vulnerable social category.

13 Oct 2025
Imitation learning (IL) with generative models, such as diffusion and flow matching, has enabled robots to perform complex, long-horizon tasks. However, distribution shifts from unseen environments or compounding action errors can still cause unpredictable and unsafe behavior, leading to task failure. Early failure prediction during runtime is therefore essential for deploying robots in human-centered and safety-critical environments. We propose FIPER, a general framework for Failure Prediction at Runtime for generative IL policies that does not require failure data. FIPER identifies two key indicators of impending failure: (i) out-of-distribution (OOD) observations detected via random network distillation in the policy's embedding space, and (ii) high uncertainty in generated actions measured by a novel action-chunk entropy score. Both failure prediction scores are calibrated using a small set of successful rollouts via conformal prediction. A failure alarm is triggered when both indicators, aggregated over short time windows, exceed their thresholds. We evaluate FIPER across five simulation and real-world environments involving diverse failure modes. Our results demonstrate that FIPER better distinguishes actual failures from benign OOD situations and predicts failures more accurately and earlier than existing methods. We thus consider this work an important step towards more interpretable and safer generative robot policies. Code, data and videos are available at this https URL.

04 Jun 2025
Researchers at the Technical University of Munich introduce GlobalBuildingAtlas, the first open, global, and complete dataset offering individual building polygons, 3-meter resolution heights, and Level of Detail 1 (LoD1) 3D models. The dataset comprises 2.75 billion buildings and demonstrates a global average height Root Mean Square Error (RMSE) of 5.5 meters, significantly improving upon previous global building data products.

08 Sep 2025
An evaluation of rank aggregation techniques for the partial label ranking problem identifies that adapted scoring-based methods, Borda and Copeland, demonstrate superior robustness to incomplete preference data and are approximately twice as fast as the state-of-the-art Bucket pivot algorithm. These findings suggest more efficient and reliable approaches for modeling preferences with ties, particularly relevant for applications like LLM fine-tuning.

23 May 2025
A safe and trustworthy use of Large Language Models (LLMs) requires an
accurate expression of confidence in their answers. We propose a novel
Reinforcement Learning approach that allows to directly fine-tune LLMs to
express calibrated confidence estimates alongside their answers to factual
questions. Our method optimizes a reward based on the logarithmic scoring rule,
explicitly penalizing both over- and under-confidence. This encourages the
model to align its confidence estimates with the actual predictive accuracy.
The optimal policy under our reward design would result in perfectly calibrated
confidence expressions. Unlike prior approaches that decouple confidence
estimation from response generation, our method integrates confidence
calibration seamlessly into the generative process of the LLM. Empirically, we
demonstrate that models trained with our approach exhibit substantially
improved calibration and generalize to unseen tasks without further
fine-tuning, suggesting the emergence of general confidence awareness. We
provide our training and evaluation code in the supplementary and will make it
publicly available upon acceptance.

17 Sep 2025

Language confusion -- where large language models (LLMs) generate unintended languages against the user's need -- remains a critical challenge, especially for English-centric models. We present the first mechanistic interpretability (MI) study of language confusion, combining behavioral benchmarking with neuron-level analysis. Using the Language Confusion Benchmark (LCB), we show that confusion points (CPs) -- specific positions where language switches occur -- are central to this phenomenon. Through layer-wise analysis with TunedLens and targeted neuron attribution, we reveal that transition failures in the final layers drive confusion. We further demonstrate that editing a small set of critical neurons, identified via comparative analysis with a multilingual-tuned counterpart, substantially mitigates confusion while largely preserving general competence and fluency. Our approach matches multilingual alignment in confusion reduction for many languages and yields cleaner, higher-quality outputs. These findings provide new insights into the internal dynamics of LLMs and highlight neuron-level interventions as a promising direction for robust, interpretable multilingual language modeling. Code and data are available at: this https URL.

16 Sep 2024
A comprehensive dataset of simulated pathloss and Time of Arrival (ToA) radio maps is made publicly available for 701 distinct urban environments, generated at 1-meter resolution using ray-tracing. This resource enables advanced deep learning research in radio map prediction and wireless localization, demonstrating that AI models can achieve superior localization accuracy in urban settings compared to traditional ToA methods.

30 Sep 2025

Text-to-Image (T2I) generation models have advanced rapidly in recent years, but accurately capturing spatial relationships like "above" or "to the right of" poses a persistent challenge. Earlier methods improved spatial relationship following with external position control. However, as architectures evolved to enhance image quality, these techniques became incompatible with modern models. We propose Stitch, a training-free method for incorporating external position control into Multi-Modal Diffusion Transformers (MMDiT) via automatically-generated bounding boxes. Stitch produces images that are both spatially accurate and visually appealing by generating individual objects within designated bounding boxes and seamlessly stitching them together. We find that targeted attention heads capture the information necessary to isolate and cut out individual objects mid-generation, without needing to fully complete the image. We evaluate Stitch on PosEval, our benchmark for position-based T2I generation. Featuring five new tasks that extend the concept of Position beyond the basic GenEval task, PosEval demonstrates that even top models still have significant room for improvement in position-based generation. Tested on Qwen-Image, FLUX, and SD3.5, Stitch consistently enhances base models, even improving FLUX by 218% on GenEval's Position task and by 206% on PosEval. Stitch achieves state-of-the-art results with Qwen-Image on PosEval, improving over previous models by 54%, all accomplished while integrating position control into leading models training-free. Code is available at this https URL.

14 Oct 2025
The Flow Poke Transformer (FPT) from CompVis @ LMU Munich predicts multimodal distributions of local motion, conditioned on sparse user interactions, rather than a single deterministic outcome. This approach provides fine-grained insights into scene dynamics, achieving superior zero-shot performance in tasks like face motion generation and significantly outperforming prior methods in moving part segmentation while accurately quantifying predictive uncertainty.

05 Jul 2024

Recent multilingual pretrained language models (mPLMs) have been shown to
encode strong language-specific signals, which are not explicitly provided
during pretraining. It remains an open question whether it is feasible to
employ mPLMs to measure language similarity, and subsequently use the
similarity results to select source languages for boosting cross-lingual
transfer. To investigate this, we propose mPLMSim, a language similarity
measure that induces the similarities across languages from mPLMs using
multi-parallel corpora. Our study shows that mPLM-Sim exhibits moderately high
correlations with linguistic similarity measures, such as lexicostatistics,
genealogical language family, and geographical sprachbund. We also conduct a
case study on languages with low correlation and observe that mPLM-Sim yields
more accurate similarity results. Additionally, we find that similarity results
vary across different mPLMs and different layers within an mPLM. We further
investigate whether mPLMSim is effective for zero-shot cross-lingual transfer
by conducting experiments on both low-level syntactic tasks and high-level
semantic tasks. The experimental results demonstrate that mPLM-Sim is capable
of selecting better source languages than linguistic measures, resulting in a
1%-2% improvement in zero-shot cross-lingual transfer performance.

04 Mar 2025
Operating rooms (ORs) are complex, high-stakes environments requiring precise
understanding of interactions among medical staff, tools, and equipment for
enhancing surgical assistance, situational awareness, and patient safety.
Current datasets fall short in scale, realism and do not capture the multimodal
nature of OR scenes, limiting progress in OR modeling. To this end, we
introduce MM-OR, a realistic and large-scale multimodal spatiotemporal OR
dataset, and the first dataset to enable multimodal scene graph generation.
MM-OR captures comprehensive OR scenes containing RGB-D data, detail views,
audio, speech transcripts, robotic logs, and tracking data and is annotated
with panoptic segmentations, semantic scene graphs, and downstream task labels.
Further, we propose MM2SG, the first multimodal large vision-language model for
scene graph generation, and through extensive experiments, demonstrate its
ability to effectively leverage multimodal inputs. Together, MM-OR and MM2SG
establish a new benchmark for holistic OR understanding, and open the path
towards multimodal scene analysis in complex, high-stakes environments. Our
code, and data is available at this https URL
There are no more papers matching your filters at the moment.
