
25 Nov 2024

This empirical study from Tsinghua University and collaborators demonstrates that off-path attackers can remotely identify NAT devices via a PMTUD side channel and launch Denial-of-Service (DoS) attacks by manipulating TCP connections. Over 92% of 180 tested real-world NAT networks, including 4G/5G and public Wi-Fi, were found vulnerable, leading to the assignment of 5 CVE/CNVD identifiers.

30 Aug 2024


Researchers from SUSTech and UCL developed a data-driven framework to analyze how academic mentees achieve independence and impact, identifying an optimal moderate divergence from mentors' research topics. Their analysis, spanning 60 years and 500,000 mentee records, reveals that a 'follow and innovate' strategy and leveraging mentor's secondary topics are key pathways to surpassing mentor's impact.

04 Dec 2024

This paper presents a comprehensive conceptual framework for addressing privacy, security, and trustworthiness challenges in Distributed Wireless Large AI Models (WLAM). It synthesizes existing knowledge and proposes layered protection strategies and integrated approaches across various technical and ethical dimensions to enable robust and responsible deployment.

16 Oct 2025





This work introduces Dynamic Fine-Tuning (DFT), a method that mathematically reinterprets Supervised Fine-Tuning (SFT) as an unstable Reinforcement Learning process with an ill-posed implicit reward. By rectifying this reward structure with a single-line code change, DFT consistently enhances SFT's generalization capabilities across various LLM architectures and tasks, often outperforming complex online and offline RL methods while being more resource-efficient.

26 Sep 2025





TrustJudge introduces a probabilistic framework to systematically mitigate two fundamental inconsistencies—score-comparison and pairwise transitivity—within LLM-as-a-judge evaluation. The method significantly reduces conflict ratios and non-transitivity rates by employing distribution-sensitive scoring and likelihood-aware aggregation, while maintaining or enhancing evaluation accuracy across various large language models and tasks.

03 Jun 2025
DiffVLA introduces an end-to-end autonomous driving system that integrates a hybrid sparse-dense perception module, a vision-language model for high-level guidance, and a diffusion-based planning module. The system achieved an Extended Per-Drive Metric Score (EPDMS) of 45.007 in the challenging Navsim-v2 competition, demonstrating its ability to generate diverse and robust trajectories in reactive environments.

22 Sep 2025

A comprehensive survey proposes a novel two-dimensional taxonomy to organize research on integrating Large Language Models and Knowledge Graphs for Question Answering, detailing methods by complex QA categories and the specific functions KGs serve. The work reviews state-of-the-art techniques, highlights their utility in mitigating LLM weaknesses such as factual inaccuracy and limited reasoning, and identifies critical future research directions.

27 Oct 2025



VIDEO-THINKER, a new framework, empowers Multimodal Large Language Models to reason with videos by intrinsically developing temporal grounding and captioning abilities. The model establishes new state-of-the-art performance on various video reasoning benchmarks, achieving up to an 11.44% improvement on the VRBench out-of-domain dataset, while showcasing enhanced temporal localization (48.22% mIoU) and descriptive captioning.

19 Mar 2025


SpatialBot enhances Vision Language Models' (VLMs) ability to precisely understand 3D space by integrating RGB-D information and training on novel, depth-centric datasets. The model achieves over 99% accuracy in direct depth estimation, improves general VLM benchmark performance, and yields higher success rates in robotic manipulation tasks by leveraging its enhanced spatial reasoning.

01 Apr 2025

Research identifies that object hallucinations in large vision-language models stem from inactive or inconsistent visual attention in specific "middle layers" during image processing. Leveraging this insight, a heads-guided attention intervention method, applied during inference, reduces hallucinations by an average of 19.5% on CHAIR_S compared to the next best approach, without requiring retraining.

04 Jun 2025

Voyager introduces a video diffusion model that generates long-range, world-consistent explorable 3D scenes by jointly producing RGB and depth videos from a single image and camera trajectory. The framework enables direct 3D scene reconstruction and scalable "infinite" world exploration with high visual and geometric fidelity.

04 Aug 2025


Recently, Large Reasoning Models (LRMs) have gradually become a research hotspot due to their outstanding performance in handling complex tasks. Among them, DeepSeek R1 has garnered significant attention for its exceptional performance and open-source nature, driving advancements in the research of R1-style LRMs. Unlike traditional Large Language Models (LLMs), these models enhance logical deduction and decision-making capabilities during reasoning by incorporating mechanisms such as long chain-of-thought and self-reflection through reinforcement learning. However, with the widespread application of these models, the problem of overthinking has gradually emerged. Specifically, when generating answers, these models often construct excessively long reasoning chains with redundant or repetitive steps, which leads to reduced reasoning efficiency and may affect the accuracy of the final answer. To this end, various efficient reasoning methods have been proposed, aiming to reduce the length of reasoning paths without compromising model performance and reasoning capability. By reviewing the current research advancements in the field of efficient reasoning methods systematically, we categorize existing works into two main directions based on the lens of single-model optimization versus model collaboration: (1) Efficient Reasoning with Single Model, which focuses on improving the reasoning efficiency of individual models; and (2) Efficient Reasoning with Model Collaboration, which explores optimizing reasoning paths through collaboration among multiple models. Besides, we maintain a public GitHub repository that tracks the latest progress in efficient reasoning methods.

28 Sep 2025

Code2MCP, an agent-based framework, automatically converts GitHub repositories into standardized Model Context Protocol (MCP) services through a multi-agent workflow and a self-correction loop. This system significantly accelerates the creation of agent-ready tools, enabling AI agents to access complex functionalities from existing codebases for tasks like scientific computing.

22 May 2025
Researchers at Yongliang Wu and collaborators developed KRIS-Bench, the first comprehensive benchmark to evaluate how well instruction-based image editing models understand and apply real-world knowledge. Their evaluation of 10 state-of-the-art models reveals a consistent gap between following instructions and generating knowledge-plausible edits, with closed-source models generally performing better but all models struggling with procedural knowledge tasks.

20 Oct 2025

Text-to-motion generation is essential for advancing the creative industry but often presents challenges in producing consistent, realistic motions. To address this, we focus on fine-tuning text-to-motion models to consistently favor high-quality, human-preferred motions, a critical yet largely unexplored problem. In this work, we theoretically investigate the DPO under both online and offline settings, and reveal their respective limitation: overfitting in offline DPO, and biased sampling in online DPO. Building on our theoretical insights, we introduce Semi-online Preference Optimization (SoPo), a DPO-based method for training text-to-motion models using "semi-online" data pair, consisting of unpreferred motion from online distribution and preferred motion in offline datasets. This method leverages both online and offline DPO, allowing each to compensate for the other's limitations. Extensive experiments demonstrate that SoPo outperforms other preference alignment methods, with an MM-Dist of 3.25% (vs e.g. 0.76% of MoDiPO) on the MLD model, 2.91% (vs e.g. 0.66% of MoDiPO) on MDM model, respectively. Additionally, the MLD model fine-tuned by our SoPo surpasses the SoTA model in terms of R-precision and MM Dist. Visualization results also show the efficacy of our SoPo in preference alignment. Project page: this https URL .

11 Mar 2025



A two-stage rule-based reinforcement learning framework enables compact 3B Large Multimodal Models (LMMs) to achieve strong reasoning abilities, demonstrating performance competitive with or surpassing larger proprietary models in agent-related tasks and improving multimodal benchmarks by 4.83%.

14 Nov 2025
Post-training fundamentally alters the behavior of large language models (LLMs), yet its impact on the internal parameter space remains poorly understood. In this work, we conduct a systematic singular value decomposition (SVD) analysis of principal linear layers in pretrained LLMs, focusing on two widely adopted post-training methods: instruction tuning and long-chain-of-thought (Long-CoT) distillation. Our analysis reveals two consistent and unexpected structural changes:(1) a near-uniform geometric scaling of singular values across layers, which theoretically modulates attention scores; and (2) highly consistent orthogonal transformations are applied to the left and right singular vectors of each matrix. Disrupting this orthogonal consistency leads to catastrophic performance degradation. Based on these findings, we propose a simple yet effective framework that interprets post-training as a reparameterization of fixed subspaces in the pretrained parameter space. Further experiments reveal that singular value scaling behaves as a secondary effect, analogous to a temperature adjustment, whereas the core functional transformation lies in the coordinated rotation of singular vectors. These results challenge the prevailing view of the parameter space in large models as a black box, uncovering the first clear regularities in how parameters evolve during training, and providing a new perspective for deeper investigation into model parameter changes.
10 Oct 2025
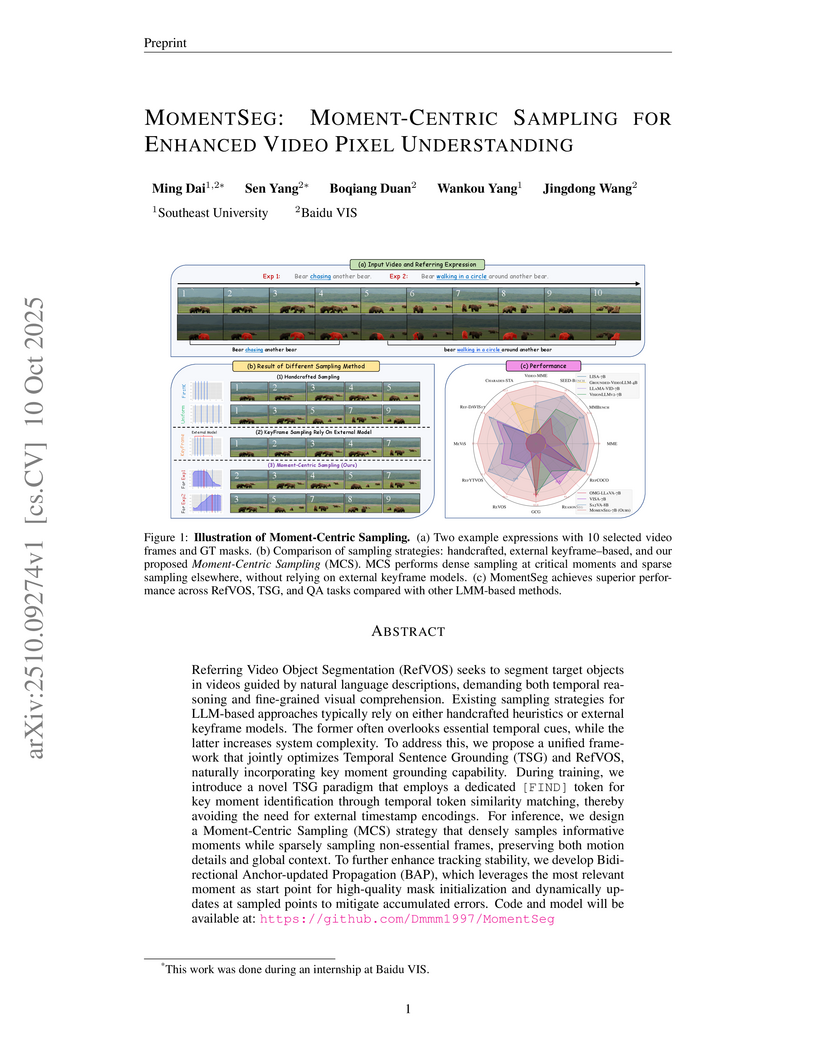
MomentSeg, developed by researchers from Southeast University and Baidu VIS, introduces a unified framework for Referring Video Object Segmentation (RefVOS) and Temporal Sentence Grounding (TSG) that enables Large Multimodal Models to natively identify text-relevant key moments. The approach achieves state-of-the-art performance on various benchmarks, demonstrating a 5% improvement on MeViS (val) and a 6% gain on ReVOS, by employing moment-centric sampling and a bidirectional anchor-updated propagation mechanism.
11 Oct 2025

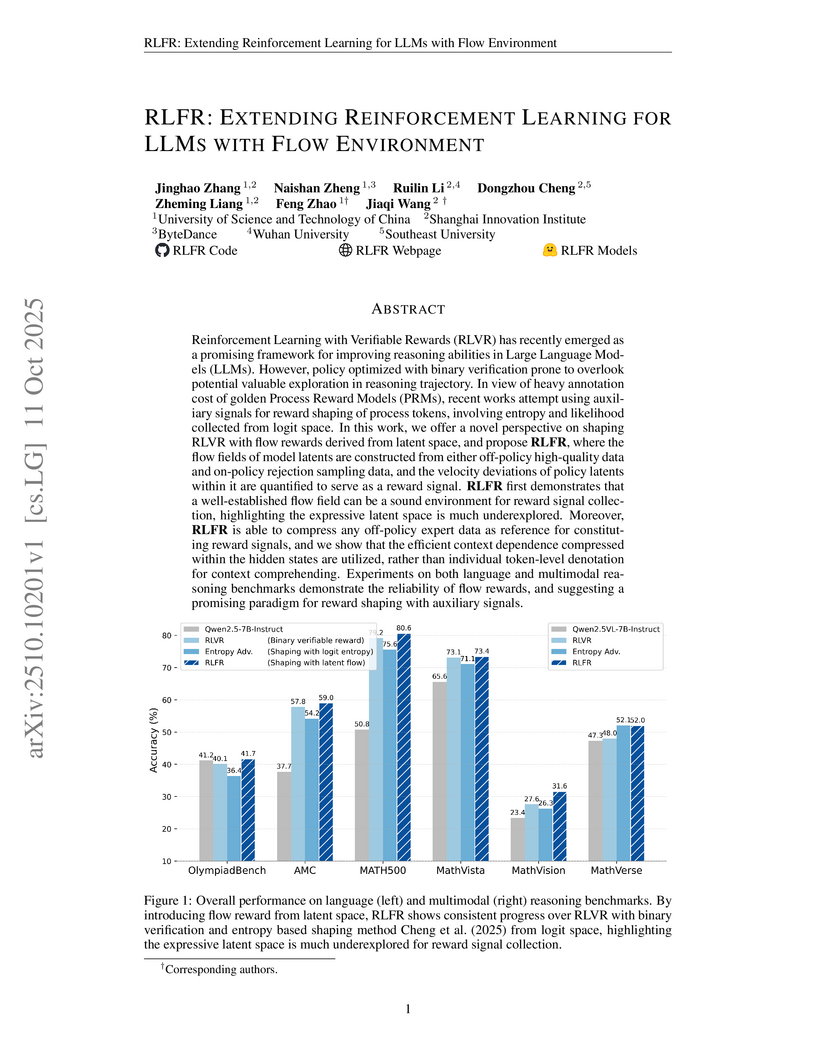
The RLFR framework enhances Large Language Models' reasoning by introducing a novel reward shaping mechanism derived from their latent space, leveraging "flow rewards" to provide dense, stable feedback during reinforcement learning. It consistently improves performance across diverse language and multimodal reasoning benchmarks, demonstrating average score increases of 1.5% to 5.3% over baselines.

02 May 2025
Mixture-of-Experts (MoE) large language models (LLMs), which leverage dynamic
routing and sparse activation to enhance efficiency and scalability, have
achieved higher performance while reducing computational costs. However, these
models face significant memory overheads, limiting their practical deployment
and broader adoption. Post-training quantization (PTQ), a widely used method
for compressing LLMs, encounters severe accuracy degradation and diminished
generalization performance when applied to MoE models. This paper investigates
the impact of MoE's sparse and dynamic characteristics on quantization and
identifies two primary challenges: (1) Inter-expert imbalance, referring to the
uneven distribution of samples across experts, which leads to insufficient and
biased calibration for less frequently utilized experts; (2) Intra-expert
imbalance, arising from MoE's unique aggregation mechanism, which leads to
varying degrees of correlation between different samples and their assigned
experts. To address these challenges, we propose MoEQuant, a novel quantization
framework tailored for MoE LLMs. MoE-Quant includes two novel techniques: 1)
Expert-Balanced Self-Sampling (EBSS) is an efficient sampling method that
efficiently constructs a calibration set with balanced expert distributions by
leveraging the cumulative probabilities of tokens and expert balance metrics as
guiding factors. 2) Affinity-Guided Quantization (AGQ), which incorporates
affinities between experts and samples into the quantization process, thereby
accurately assessing the impact of individual samples on different experts
within the MoE layer. Experiments demonstrate that MoEQuant achieves
substantial performance gains (more than 10 points accuracy gain in the
HumanEval for DeepSeekMoE-16B under 4-bit quantization) and boosts efficiency.
There are no more papers matching your filters at the moment.
