
18 Feb 2024
A new Chinese legal LLM benchmark, LAiW, aligns evaluation with legal syllogism across three levels of difficulty, revealing that existing LLMs often exhibit strong text generation but weak foundational legal reasoning, which could hinder their practical adoption.

25 Mar 2025

A framework for zero-shot multilingual speech emotion recognition (MSER) integrates large language models with contrastive learning to interpret emotions across diverse, unseen languages. The method demonstrates meaningful recognition scores, such as 57.4% unweighted accuracy on Persian, and introduces M5SER, a 1000+ hour synthetic multilingual dataset to support such generalization.

13 Mar 2025
In this research, we propose a novel denoising diffusion model based on
shortest-path modeling that optimizes residual propagation to enhance both
denoising efficiency and quality. Drawing on Denoising Diffusion Implicit
Models (DDIM) and insights from graph theory, our model, termed the Shortest
Path Diffusion Model (ShortDF), treats the denoising process as a shortest-path
problem aimed at minimizing reconstruction error. By optimizing the initial
residuals, we improve the efficiency of the reverse diffusion process and the
quality of the generated samples. Extensive experiments on multiple standard
benchmarks demonstrate that ShortDF significantly reduces diffusion time (or
steps) while enhancing the visual fidelity of generated samples compared to
prior arts. This work, we suppose, paves the way for interactive
diffusion-based applications and establishes a foundation for rapid data
generation. Code is available at this https URL

25 Apr 2024
Hypertrophic cardiomyopathy (HCM) and cardiac amyloidosis (CA) are both heart
conditions that can progress to heart failure if untreated. They exhibit
similar echocardiographic characteristics, often leading to diagnostic
challenges. This paper introduces a novel multi-view deep learning approach
that utilizes 2D echocardiography for differentiating between HCM and CA. The
method begins by classifying 2D echocardiography data into five distinct
echocardiographic views: apical 4-chamber, parasternal long axis of left
ventricle, parasternal short axis at levels of the mitral valve, papillary
muscle, and apex. It then extracts features of each view separately and
combines five features for disease classification. A total of 212 patients
diagnosed with HCM, and 30 patients diagnosed with CA, along with 200
individuals with normal cardiac function(Normal), were enrolled in this study
from 2018 to 2022. This approach achieved a precision, recall of 0.905, and
micro-F1 score of 0.904, demonstrating its effectiveness in accurately
identifying HCM and CA using a multi-view analysis.

23 Apr 2025
Quantum algorithms rely on quantum computers for implementation, but the
physical connectivity constraints of modern quantum processors impede the
efficient realization of quantum algorithms. Qubit mapping, a critical
technology for practical quantum computing applications, directly determines
the execution efficiency and feasibility of algorithms on superconducting
quantum processors. Existing mapping methods overlook intractable quantum
hardware fidelity characteristics, reducing circuit execution quality. They
also exhibit prolonged solving times or even failure to complete when handling
large-scale quantum architectures, compromising efficiency. To address these
challenges, we propose a novel qubit mapping method HAQA. HAQA first introduces
a community-based iterative region identification strategy leveraging hardware
connection topology, achieving effective dimensionality reduction of mapping
space. This strategy avoids global search procedures, with complexity analysis
demonstrating quadratic polynomial-level acceleration. Furthermore, HAQA
implements a hardware-characteristic-based region evaluation mechanism,
enabling quantitative selection of mapping regions based on fidelity metrics.
This approach effectively integrates hardware fidelity information into the
mapping process, enabling fidelity-aware qubit allocation. Experimental results
demonstrate that HAQA significantly improves solving speed and fidelity while
ensuring solution quality. When applied to state-of-the-art quantum mapping
techniques Qsynth-v2 and TB-OLSQ2, HAQA achieves acceleration ratios of 632.76
and 286.87 respectively, while improving fidelity by up to 52.69% and 238.28%

08 Jun 2025
Due to the emergence of many sign language datasets, isolated sign language recognition (ISLR) has made significant progress in recent years. In addition, the development of various advanced deep neural networks is another reason for this breakthrough. However, challenges remain in applying the technique in the real world. First, existing sign language datasets do not cover the whole sign vocabulary. Second, most of the sign language datasets provide only single view RGB videos, which makes it difficult to handle hand occlusions when performing ISLR. To fill this gap, this paper presents a dual-view sign language dataset for ISLR named NationalCSL-DP, which fully covers the Chinese national sign language vocabulary. The dataset consists of 134140 sign videos recorded by ten signers with respect to two vertical views, namely, the front side and the left side. Furthermore, a CNN transformer network is also proposed as a strong baseline and an extremely simple but effective fusion strategy for prediction. Extensive experiments were conducted to prove the effectiveness of the datasets as well as the baseline. The results show that the proposed fusion strategy can significantly increase the performance of the ISLR, but it is not easy for the sequence-to-sequence model, regardless of whether the early-fusion or late-fusion strategy is applied, to learn the complementary features from the sign videos of two vertical views.
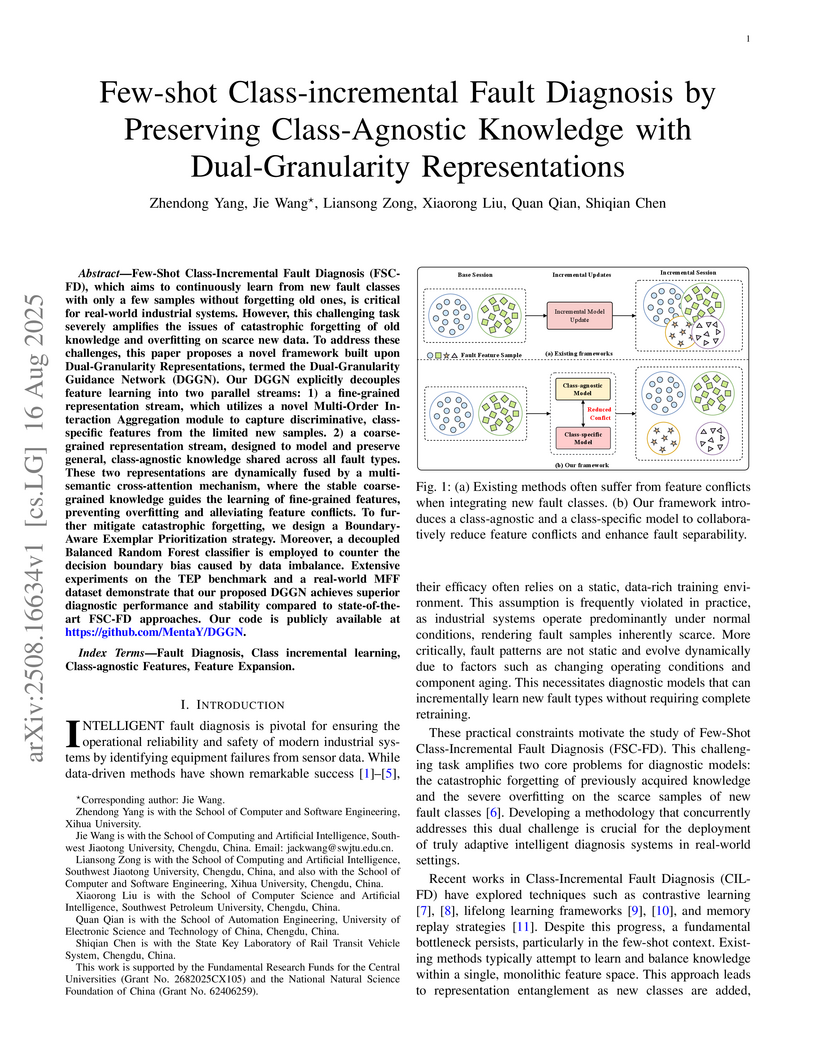
16 Aug 2025
Few-Shot Class-Incremental Fault Diagnosis (FSC-FD), which aims to continuously learn from new fault classes with only a few samples without forgetting old ones, is critical for real-world industrial systems. However, this challenging task severely amplifies the issues of catastrophic forgetting of old knowledge and overfitting on scarce new data. To address these challenges, this paper proposes a novel framework built upon Dual-Granularity Representations, termed the Dual-Granularity Guidance Network (DGGN). Our DGGN explicitly decouples feature learning into two parallel streams: 1) a fine-grained representation stream, which utilizes a novel Multi-Order Interaction Aggregation module to capture discriminative, class-specific features from the limited new samples. 2) a coarse-grained representation stream, designed to model and preserve general, class-agnostic knowledge shared across all fault types. These two representations are dynamically fused by a multi-semantic cross-attention mechanism, where the stable coarse-grained knowledge guides the learning of fine-grained features, preventing overfitting and alleviating feature conflicts. To further mitigate catastrophic forgetting, we design a Boundary-Aware Exemplar Prioritization strategy. Moreover, a decoupled Balanced Random Forest classifier is employed to counter the decision boundary bias caused by data imbalance. Extensive experiments on the TEP benchmark and a real-world MFF dataset demonstrate that our proposed DGGN achieves superior diagnostic performance and stability compared to state-of-the-art FSC-FD approaches. Our code is publicly available at this https URL

10 Jul 2025
In the field of deep learning, traditional attention mechanisms face significant challenges related to high computational complexity and large memory consumption when processing long sequence data. To address these limitations, we propose Opt-GPTQ, an optimized Gradient-based Post Training Quantization (GPTQ) combining the Grouped Query Attention (GQA) mechanism with paging memory management, optimizing the traditional Multi-Head Attention (MHA) mechanism by grouping query heads and sharing key-value vectors. Optimized GQA (Opt-GQA) effectively reduces computational complexity, minimizes memory fragmentation, and enhances memory utilization for large-scale models. Opt-GPTQ is optimized for Data Center Units (DCUs) and integrated into the vLLM model to maximize hardware efficiency. It customizes GPU kernels to further enhance attention computation by reducing memory access latency and boosting parallel computing capabilities. Opt-GQA integrates Attention with Linear Biases (ALiBi) to reduce overhead and enhance long-sequence processing. Experimental results show that Opt-GPTQ significantly reduces computation time and memory usage while improving model performance.

28 Jul 2024
Physics-informed neural networks (PINNs) integrate fundamental physical principles with advanced data-driven techniques, driving significant advancements in scientific computing. However, PINNs face persistent challenges with stiffness in gradient flow, which limits their predictive capabilities. This paper presents an improved PINN (I-PINN) to mitigate gradient-related failures. The core of I-PINN is to combine the respective strengths of neural networks with an improved architecture and adaptive weights containingupper bounds. The capability to enhance accuracy by at least one order of magnitude and accelerate convergence, without introducing extra computational complexity relative to the baseline model, is achieved by I-PINN. Numerical experiments with a variety of benchmarks illustrate the improved accuracy and generalization of I-PINN. The supporting data and code are accessible at this https URL, enabling broader research engagement.

26 Sep 2024
Accurate power load forecasting is crucial for improving energy efficiency and ensuring power supply quality. Considering the power load forecasting problem involves not only dynamic factors like historical load variations but also static factors such as climate conditions that remain constant over specific periods. From the model-agnostic perspective, this paper proposes a parallel structure network to extract important information from both dynamic and static data. Firstly, based on complexity learning theory, it is demonstrated that models integrated through parallel structures exhibit superior generalization abilities compared to individual base learners. Additionally, the higher the independence between base learners, the stronger the generalization ability of the parallel structure model. This suggests that the structure of machine learning models inherently contains significant information. Building on this theoretical foundation, a parallel convolutional neural network (CNN)-gate recurrent unit (GRU) attention model (PCGA) is employed to address the power load forecasting issue, aiming to effectively integrate the influences of dynamic and static features. The CNN module is responsible for capturing spatial characteristics from static data, while the GRU module captures long-term dependencies in dynamic time series data. The attention layer is designed to focus on key information from the spatial-temporal features extracted by the parallel CNN-GRU. To substantiate the advantages of the parallel structure model in extracting and integrating multi-source information, a series of experiments are conducted.

21 Dec 2022
Machine learning approaches are widely studied in the production prediction
of CBM wells after hydraulic fracturing, but merely used in practice due to the
low generalization ability and the lack of interpretability. A novel
methodology is proposed in this article to discover the latent causality from
observed data, which is aimed at finding an indirect way to interpret the
machine learning results. Based on the theory of causal discovery, a causal
graph is derived with explicit input, output, treatment and confounding
variables. Then, SHAP is employed to analyze the influence of the factors on
the production capability, which indirectly interprets the machine learning
models. The proposed method can capture the underlying nonlinear relationship
between the factors and the output, which remedies the limitation of the
traditional machine learning routines based on the correlation analysis of
factors. The experiment on the data of CBM shows that the detected relationship
between the production and the geological/engineering factors by the presented
method, is coincident with the actual physical mechanism. Meanwhile, compared
with traditional methods, the interpretable machine learning models have better
performance in forecasting production capability, averaging 20% improvement in
accuracy.

09 Dec 2024
The igneous rocks in deep formation have the characteristics of hardness, poor drillability and high abrasiveness, which is a difficulty in speeding up drilling. The drilling efficiency of existing conventional bits is low in igneous rocks. Based on the characteristics of igneous rocks, rock mechanical parameters and drillability experiments of granite, sandstone and other rocks were carried out. The rock drilling experiments of composite bit, tri-cone bit and PDC bit were carried out. Experiments have shown that in granite with very high strength, the drilling efficiency of conventional cone bit is very low, and it is extremely difficult for PDC bit to penetrate. The impact crushing effect of the cone of the composite bit can make the rock at the bottom of the well produce pits and cracks, which can assist the PDC cutters to penetrate into the formation, and solve the problem of the PDC cutters difficulty in penetrating in hard formations. In softer formations, the rock-breaking advantage of composite bit is not obvious, and the rock-breaking efficiency is lower than that of PDC bit. However, in hard formations, the advantage of composite bit is obvious, with higher drilling efficiency than PDC bit and cone bits. The personalized composite bit developed for deep igneous rocks formations has fast drilling speed, strong sustained drilling ability, long footage, and significant drilling speed-up effect. It significantly reduces the number of runs in deep drilling operations and achieves good application results. The composite bit is suitable for drilling in deep igneous hard-to-drill formations, and it has obvious advantages in deep igneous formations. It is a good choice for drilling speed-up in this kind of hard-to-drill formation.

05 Sep 2024
The porous media community extensively utilizes digital rock images for core analysis. High-resolution digital rock images that possess sufficient quality are essential but often challenging to acquire. Super-resolution (SR) approaches enhance the resolution of digital rock images and provide improved visualization of fine features and structures, aiding in the analysis and interpretation of rock properties, such as pore connectivity and mineral distribution. However, there is a current shortage of real paired microscopic images for super-resolution training. In this study, we used two types of Scanning Electron Microscopes (SEM) to obtain the images of shale samples in five regions, with 1X, 2X, 4X, 8X and 16X magnifications. We used these real scanned paired images as a reference to select the optimal method of image generation and validated it using Enhanced Deep Super Resolution (EDSR) and Very Deep Super Resolution (VDSR) methods. Our experiments show that the bilinear algorithm is more suitable than the commonly used bicubic method, for establishing low-resolution datasets in the SR approaches, which is partially attributed to the mechanism of Scanning Electron Microscopes (SEM).

08 Apr 2022

The picture fuzzy set, characterized by three membership degrees, is a
helpful tool for multi-criteria decision making (MCDM). This paper investigates
the structure of the closed operational laws in the picture fuzzy numbers
(PFNs) and proposes efficient picture fuzzy MCDM methods. We first introduce an
admissible order for PFNs and prove that all PFNs form a complete lattice under
this order. Then, we give some specific examples to show the non-closeness of
some existing picture fuzzy aggregation operators. To ensure the closeness of
the operational laws in PFNs, we construct a new class of picture fuzzy
operators based on strict triangular norms, which consider the interaction
between the positive degrees (negative degrees) and the neutral degrees. Based
on these new operators, we obtain the picture fuzzy interactional weighted
average (PFIWA) operator and the picture fuzzy interactional weighted geometric
(PFIWG) operator. They are proved to be monotonous, idempotent, bounded,
shift-invariant, and homogeneous. We also establish a novel MCDM method under
the picture fuzzy environment applying PFIWA and PFIWG operators. Furthermore,
we present an illustrative example for a clear understanding of our method. We
also give the comparative analysis among the operators induced by six classes
of famous triangular norms.

19 May 2025
Neutral atom quantum computers are one of the most promising quantum
architectures, offering advantages in scalability, dynamic reconfigurability,
and potential for large-scale implementations. These characteristics create
unique compilation challenges, especially regarding compilation efficiency
while adapting to hardware flexibility. However, existing methods encounter
significant performance bottlenecks at scale, hindering practical applications.
We propose Physics-Aware Compilation (PAC), a method that improves compilation
efficiency while preserving the inherent flexibility of neutral atom systems.
PAC introduces physics-aware hardware plane partitioning that strategically
allocates hardware resources based on physical device characteristics like AOD
and SLM trap properties and qubit mobility constraints. Additionally, it
implements parallel quantum circuit division with an improved Kernighan-Lin
algorithm that enables simultaneous execution across independent regions while
maintaining circuit fidelity. Our experimental evaluation compares PAC with
state-of-the-art methods across increasingly larger array sizes ranging from
16x16 to 64x64 qubits. Results demonstrate that PAC achieves up to 78.5x
speedup on 16x16 arrays while maintaining comparable circuit quality. PAC's
compilation efficiency advantage increases with system scale, demonstrating
scalability for practical quantum applications on larger arrays. PAC explores a
viable path for practical applications of neutral atom quantum computers by
effectively addressing the tension between compilation efficiency and hardware
flexibility.
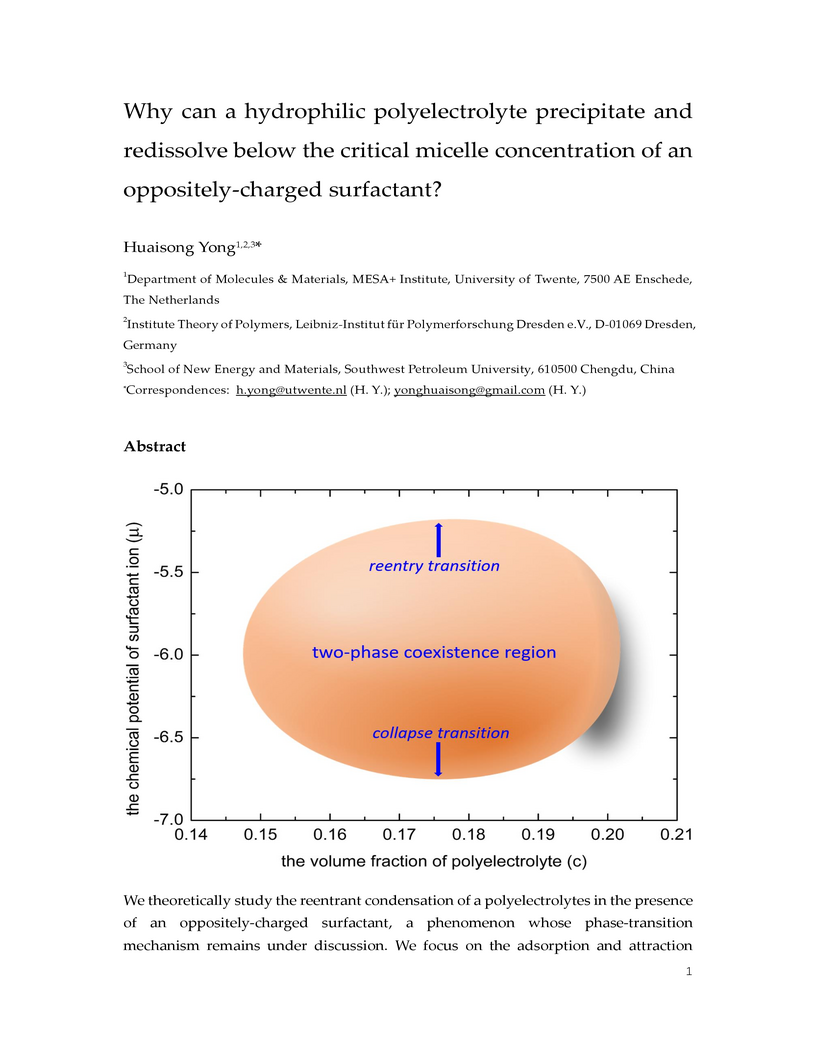
10 Nov 2024
We theoretically study the reentrant condensation of a polyelectrolyte in the presence of an oppositely-charged surfactant,a phenomenon whose phase-transition mechanism remains under discussion. We focus on the adsorption and attraction effects of surfactant near/on polymer chains, and ignore their own non-essential mixing effects if surfactant molecules are far away from polymer chains. This approach allows us to construct a simple mean-field theory and solve it analytically, and finally rationalize the essential features (such as the "egg shape" of spinodal phase diagrams) of the reentrant condensation of a polyelectrolyte induced by diluted oppositely-charged surfactants. By theoretical analysis, we found that a strong electrostatic adsorption between the ionic monomers and surfactant ions is critical to understand the peculiar phenomenon that both the collapse and reentry transitions of polyelectrolytes can occur when the concentration of surfactant is lower than its bulk critical micelle concentration (CMC). The analytical solution of the theory indicates that a minimum coupling energy for the nonlinear hydrophobic-aggregation effect of adsorbed surfactant is essential for phase transition to occur,which explains why polyelectrolytes show phase transition only if the surfactant chain length is longer than a minimum length. The obtained results will shed light on a deep understanding of liquid-liquid phase separation in biological systems where ionic surfactant-like proteins/peptides bound to bio-polyelectrolytes play an important role.

02 Mar 2025

Reducing radiation doses benefits patients, however, the resultant low-dose
computed tomography (LDCT) images often suffer from clinically unacceptable
noise and artifacts. While deep learning (DL) shows promise in LDCT
reconstruction, it requires large-scale data collection from multiple clients,
raising privacy concerns. Federated learning (FL) has been introduced to
address these privacy concerns; however, current methods are typically tailored
to specific scanning protocols, which limits their generalizability and makes
them less effective for unseen protocols. To address these issues, we propose
SCAN-PhysFed, a novel SCanning- and ANatomy-level personalized Physics-Driven
Federated learning paradigm for LDCT reconstruction. Since the noise
distribution in LDCT data is closely tied to scanning protocols and anatomical
structures being scanned, we design a dual-level physics-informed way to
address these challenges. Specifically, we incorporate physical and anatomical
prompts into our physics-informed hypernetworks to capture scanning- and
anatomy-specific information, enabling dual-level physics-driven
personalization of imaging features. These prompts are derived from the
scanning protocol and the radiology report generated by a medical large
language model (MLLM), respectively. Subsequently, client-specific decoders
project these dual-level personalized imaging features back into the image
domain. Besides, to tackle the challenge of unseen data, we introduce a novel
protocol vector-quantization strategy (PVQS), which ensures consistent
performance across new clients by quantifying the unseen scanning code as one
of the codes in the scanning codebook. Extensive experimental results
demonstrate the superior performance of SCAN-PhysFed on public datasets.

15 May 2024

This paper numerically investigates the influence of a fixed downstream control cylinder on the flow-induced vibration of an elastically-supported primary cylinder. These two cylinders are situated in a tandem arrangement with small dimensionless centre-to-centre spacing (, is the intermediate spacing, and is the cylinder diameter). The present two-dimensional (2D) simulations are carried out in the low Reynolds number () regime. The primary focus of this study is to reveal the underlying flow physics behind the transition from vortex-induced vibration to galloping in the response of the primary cylinder due to the presence of another fixed downstream cylinder. Two distinct flow field regimes, namely steady flow and alternate attachment regimes, are observed for different and Re values. Depending on the evolution of the near-field flow structures, four different wake patterns - `2S', `2P', `2C', and `aperiodic' - are observed. The corresponding vibration response of the upstream cylinder is characterized as interference galloping and extended vortex-induced vibration. As the ratio increases, the lift enhancement due to flow-induced vibration is seen to be weakened. The detailed correlation between the force generation and the near-wake interactions is investigated. The present findings will augment the understanding of vibration reduction or flow-induced energy harvesting of tandem cylindrical structures.

08 Aug 2022
Feature extraction is critical for TLS traffic analysis using machine
learning techniques, which it is also very difficult and time-consuming
requiring huge engineering efforts. We designed and implemented DeepTLS, a
system which extracts full spectrum of features from pcaps across meta,
statistical, SPLT, byte distribution, TLS header and certificates. The backend
is written in C++ to achieve high performance, which can analyze a GB-size pcap
in a few minutes. DeepTLS was thoroughly evaluated against two state-of-the-art
tools Joy and Zeek with four well-known malicious traffic datasets consisted of
160 pcaps. Evaluation results show DeepTLS has advantage of analyzing large
pcaps with half analysis time, and identified more certificates with acceptable
performance loss compared with Joy. DeepTLS can significantly accelerate
machine learning pipeline by reducing feature extraction time from hours even
days to minutes. The system is online at this https URL, where test
artifacts can be viewed and validated. In addition, two open source tools
Pysharkfeat and Tlsfeatmark are also released.

14 Mar 2023
Naked eye recognition of age is usually based on comparison with the age of others. However, this idea is ignored by computer tasks because it is difficult to obtain representative contrast images of each age. Inspired by the transfer learning, we designed the Delta Age AdaIN (DAA) operation to obtain the feature difference with each age, which obtains the style map of each age through the learned values representing the mean and standard deviation. We let the input of transfer learning as the binary code of age natural number to obtain continuous age feature information. The learned two groups of values in Binary code mapping are corresponding to the mean and standard deviation of the comparison ages. In summary, our method consists of four parts: FaceEncoder, DAA operation, Binary code mapping, and AgeDecoder modules. After getting the delta age via AgeDecoder, we take the average value of all comparison ages and delta ages as the predicted age. Compared with state-of-the-art methods, our method achieves better performance with fewer parameters on multiple facial age datasets.
There are no more papers matching your filters at the moment.
