
28 Sep 2025



Researchers from institutions including the Max Planck Institute for Intelligent Systems demonstrate that marginal gains in LLM single-step accuracy lead to exponential improvements in long-horizon task completion, challenging the perception of diminishing returns from scaling. The study identifies 'self-conditioning' as a distinct execution failure mode and shows that sequential test-time compute significantly extends reliable task execution.

04 Jun 2024
Researchers from the University of Tübingen and the Tübingen AI Center developed an axiomatic framework for loss aggregation in online learning, identifying quasi-sums as the fundamental class of aggregation functions. They adapted Vovk's Aggregating Algorithm to work with these generalized aggregations, showing how the choice of aggregation reflects a learner's risk attitude while preserving strong theoretical regret guarantees.
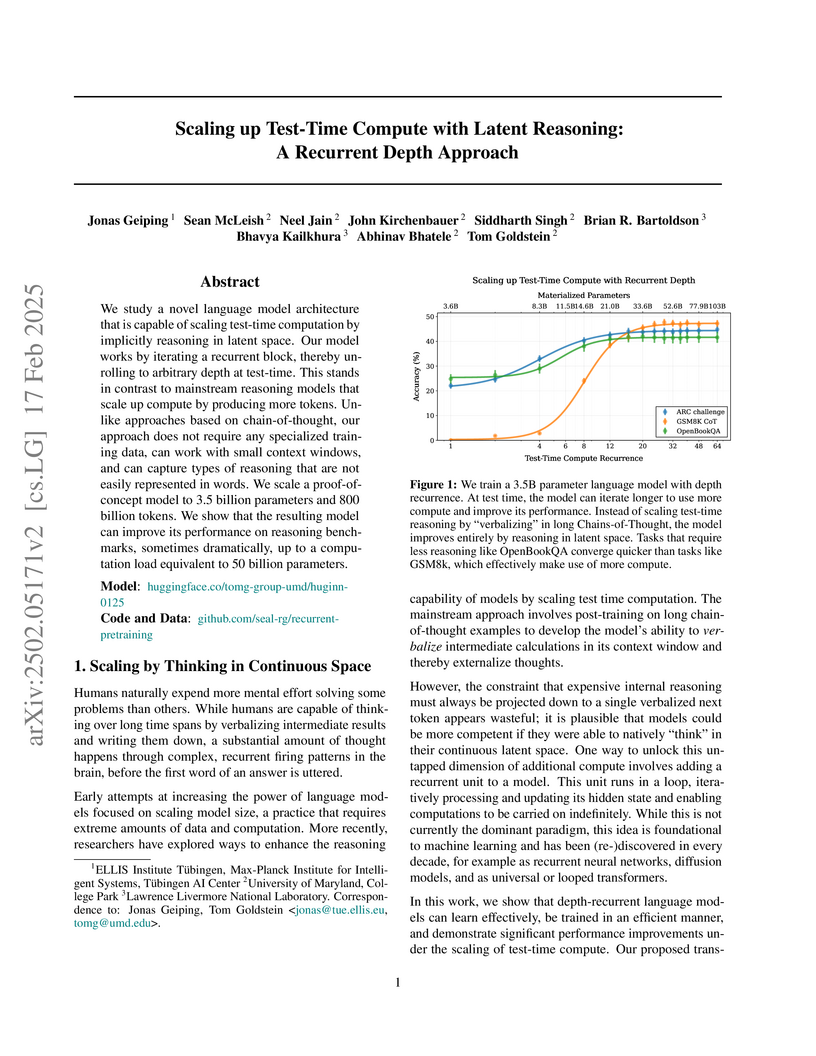
17 Feb 2025


Researchers from ELLIS Institute Tübingen, University of Maryland, and Lawrence Livermore National Laboratory introduce a recurrent depth transformer architecture that scales reasoning abilities by implicitly processing information in a continuous latent space. The 3.5 billion parameter model, Huginn-0125, trained on the Frontier supercomputer, demonstrates significant performance gains on reasoning benchmarks with increased test-time iterations, sometimes matching or exceeding larger models without requiring specialized Chain-of-Thought training data.

07 Oct 2025

HUMAN3R presents a unified, feed-forward framework for online 4D human-scene reconstruction from monocular video. The system jointly estimates multi-person global human motions, dense 3D scene geometry, and camera parameters in real-time at 15 FPS, outperforming or matching prior methods on various reconstruction benchmarks while consuming only 8 GB of GPU memory.

22 Feb 2025

Researchers from ShanghaiTech University and the University of Tübingen introduce 2D Gaussian Splatting (2DGS), a method that represents scenes with oriented planar Gaussian disks to achieve geometrically accurate 3D reconstruction and high-quality novel view synthesis. 2DGS produces detailed and noise-free explicit meshes up to 100 times faster than prior implicit methods while maintaining competitive visual quality.

28 Oct 2024

Vista introduces a driving world model that generates high-fidelity, long-horizon future predictions at 10 Hz and 576x1024 resolution, capable of cross-dataset generalization and versatile control via various action modalities. The model also functions as a generalizable reward function by leveraging its prediction uncertainty to evaluate actions.

31 Oct 2024



NAVSIM offers a data-driven non-reactive simulation and benchmarking framework for autonomous vehicles, designed to evaluate end-to-end driving policies against challenging real-world scenarios. It introduces a comprehensive scoring function, the PDM Score, which demonstrates better alignment with full closed-loop simulation compared to conventional open-loop metrics, and reveals that simpler models can achieve competitive performance against more complex architectures.

14 Oct 2025
DR.LLM introduces a retrofittable framework for Large Language Models that dynamically adjusts computational depth, achieving a mean accuracy gain of +2.25 percentage points and 5.0 fewer layers executed on average on in-domain tasks, while robustly generalizing to out-of-domain benchmarks with minimal accuracy drop.

16 Jan 2025

DriveLM introduces Graph Visual Question Answering (GVQA) as a principled framework for autonomous driving, mimicking human multi-step reasoning. This approach enhances generalization capabilities across unseen sensor configurations and novel objects while also providing explainable, language-based decision processes for end-to-end driving.

23 Sep 2025

Large language model (LLM) developers aim for their models to be honest, helpful, and harmless. However, when faced with malicious requests, models are trained to refuse, sacrificing helpfulness. We show that frontier LLMs can develop a preference for dishonesty as a new strategy, even when other options are available. Affected models respond to harmful requests with outputs that sound harmful but are crafted to be subtly incorrect or otherwise harmless in practice. This behavior emerges with hard-to-predict variations even within models from the same model family. We find no apparent cause for the propensity to deceive, but show that more capable models are better at executing this strategy. Strategic dishonesty already has a practical impact on safety evaluations, as we show that dishonest responses fool all output-based monitors used to detect jailbreaks that we test, rendering benchmark scores unreliable. Further, strategic dishonesty can act like a honeypot against malicious users, which noticeably obfuscates prior jailbreak attacks. While output monitors fail, we show that linear probes on internal activations can be used to reliably detect strategic dishonesty. We validate probes on datasets with verifiable outcomes and by using them as steering vectors. Overall, we consider strategic dishonesty as a concrete example of a broader concern that alignment of LLMs is hard to control, especially when helpfulness and harmlessness conflict.

04 Dec 2025

Existing methods for extracting reward signals in Reinforcement Learning typically rely on labeled data and dedicated training splits, a setup that contrasts with how humans learn directly from their environment. In this work, we propose TTRV to enhance vision language understanding by adapting the model on the fly at inference time, without the need for any labeled data. Concretely, we enhance the Group Relative Policy Optimization (GRPO) framework by designing rewards based on the frequency of the base model's output, while inferring on each test sample multiple times. Further, we also propose to control the diversity of the model's output by simultaneously rewarding the model for obtaining low entropy of the output empirical distribution. Our approach delivers consistent gains across both object recognition and visual question answering (VQA), with improvements of up to 52.4% and 29.8%, respectively, and average boosts of 24.6% and 10.0% across 16 datasets. Remarkably, on image recognition, TTRV applied to InternVL 8B surpasses GPT-4o by an average of 2.3% over 8 benchmarks, while remaining highly competitive on VQA, demonstrating that test-time reinforcement learning can match or exceed the strongest proprietary models. Finally, we find many interesting properties of test-time RL for VLMs: for example, even in extremely data-constrained scenarios, where adaptation is performed on a single randomly chosen unlabeled test example, TTRV still yields non-trivial improvements of up to 5.5% in recognition tasks.

25 Sep 2025
Researchers from the University of Tübingen and the Tübingen AI Center introduced MDPO, a reinforcement learning framework, and RCR, a training-free decoding strategy, to resolve the training-inference mismatch and fixed-token limitation in Masked Diffusion Language Models. These methods improve generation quality and sample efficiency, achieving a 9.6% average gain on MATH500 and 54.2% on Countdown over state-of-the-art baselines with equivalent computational budgets.

15 Aug 2024


This survey provides an in-depth analysis of end-to-end autonomous driving, tracing its historical development and detailing diverse methodologies like imitation learning and reinforcement learning. The work synthesizes over 270 papers to analyze key challenges, including multi-sensor fusion, interpretability, and robustness, while also outlining future trends and their potential to overcome limitations of traditional modular systems.

14 Jun 2025

Research from the Max Planck Institute for Intelligent Systems demonstrated that Stochastic Gradient Descent (SGD) with momentum can train Transformer-based language models effectively, performing comparably to Adam in small-batch settings. The study found that Adam exhibits batch-size dependent acceleration not present in SGD, making SGD slower to converge at larger batch sizes.

16 May 2025


Artificial Kuramoto Oscillatory Neurons (AKOrN) are presented as dynamic, N-dimensional oscillatory units interacting via a generalized Kuramoto model. This architecture enhances unsupervised object discovery, achieves near-perfect Sudoku solving, and demonstrates intrinsic robustness to adversarial attacks and well-calibrated uncertainty estimates.

10 Nov 2025

Mercedes-Benz AG and University of Tübingen researchers developed AGO, a framework for adaptive grounding in open-world 3D occupancy prediction, enabling recognition of both known and novel objects from multi-camera inputs. The model achieved a state-of-the-art 19.23 mIoU on the Occ3D-nuScenes benchmark, showing robust generalization to unknown categories and outperforming previous methods by 4.09 mIoU.

13 Nov 2025

Understanding the geometry of neural network loss landscapes is a central question in deep learning, with implications for generalization and optimization. A striking phenomenon is linear mode connectivity (LMC), where independently trained models can be connected by low- or zero-loss paths despite appearing to lie in separate loss basins. However, this is often obscured by symmetries in parameter space -- such as neuron permutations -- which make functionally equivalent models appear dissimilar. Prior work has predominantly focused on neuron reordering through permutations, but such approaches are limited in scope and fail to capture the richer symmetries exhibited by modern architectures such as Transformers. In this work, we introduce a unified framework that captures four symmetry classes -- permutations, semi-permutations, orthogonal transformations, and general invertible maps -- broadening the set of valid reparameterizations and subsuming many previous approaches as special cases. Crucially, this generalization enables, for the first time, the discovery of low- and zero-barrier linear interpolation paths between independently trained Vision Transformers and GPT-2 models. Furthermore, our framework extends beyond pairwise alignment to multi-model and width-heterogeneous settings, enabling alignment across architectures of different sizes. These results reveal deeper structure in the loss landscape and underscore the importance of symmetry-aware analysis for understanding model space geometry.

18 Apr 2025
A coordinate-based feature upsampling framework called LoftUp enables high-resolution feature maps from Vision Foundation Models through a cross-attention transformer architecture and two-stage training with pseudo-ground truth supervision, demonstrating substantial improvements across semantic segmentation, depth estimation, and video object segmentation tasks while maintaining computational efficiency.

07 Oct 2025
Research from the ELLIS Institute and Max Planck Institute demonstrates that post-training quantization (PTQ) robustness in large language models is primarily influenced by training dynamics, such as learning rate schedules and weight averaging, rather than solely by the amount of training data. Higher learning rates and strategic weight averaging during training were found to substantially improve the quality of quantized models, offering practical methods to mitigate degradation.

12 Feb 2025


This research introduces a large-scale benchmark for continual pretraining in Large Language Models (LLMs), characterizing how model scale, training data characteristics, and domain sequencing influence knowledge acquisition, retention, and transfer. The findings reveal that while smaller GPT-2 models benefit from continual learning, larger Llama2-7B models can degrade on smaller datasets, and random domain ordering generally promotes better knowledge retention.
There are no more papers matching your filters at the moment.
