
01 Aug 2025
Princeton AI Lab University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of California, Santa Barbara
University of California, Santa Barbara Carnegie Mellon University
Carnegie Mellon University Fudan University
Fudan University Shanghai Jiao Tong University
Shanghai Jiao Tong University Tsinghua University
Tsinghua University University of Michigan
University of Michigan The Chinese University of Hong KongThe Hong Kong University of Science and Technology (Guangzhou)
The Chinese University of Hong KongThe Hong Kong University of Science and Technology (Guangzhou) University of California, San DiegoPennsylvania State University
University of California, San DiegoPennsylvania State University The University of Hong Kong
The University of Hong Kong Princeton University
Princeton University University of SydneyOregon State University
University of SydneyOregon State University
University of Illinois at Urbana-ChampaignUniversity of California, Santa BarbaraCarnegie Mellon UniversityFudan UniversityShanghai Jiao Tong UniversityTsinghua UniversityUniversity of MichiganThe Chinese University of Hong KongThe Hong Kong University of Science and Technology (Guangzhou)University of California, San DiegoPennsylvania State UniversityThe University of Hong KongPrinceton UniversityUniversity of SydneyOregon State UniversityAn extensive international collaboration offers the first systematic review of self-evolving agents, establishing a unified theoretical framework categorized by 'what to evolve,' 'when to evolve,' and 'how to evolve'. The work consolidates diverse research, highlights key challenges, and maps applications, aiming to guide the development of AI systems capable of continuous autonomous improvement.

10 Oct 2024

This research evaluates Large Language Models' (LLMs) proficiency in specialized statistical tasks, specifically their ability to assess the applicability of statistical methods. The paper introduces StatQA, a novel benchmark, and finds that fine-tuned LLMs achieve the highest accuracy at 77.13% on this benchmark, surpassing general-purpose LLMs and human experts.

22 Sep 2025


Researchers from Beijing University of Posts and Telecommunications, Westlake University, and Zhejiang University, along with the OpenHelix Team, introduce VLA-Adapter, an efficient method to bridge vision-language representations to robotic actions. The approach enables state-of-the-art level performance with a tiny-scale 0.5B parameter backbone without robotic data pre-training, achieving a 97.3% average success rate on the LIBERO benchmark and providing a 3x faster inference speed (219.2 Hz) than comparable methods.

15 Apr 2025




AFLOW introduces an automated framework for generating and optimizing agentic workflows for Large Language Models, reformulating workflow optimization as a search problem over code-represented workflows. The system leverages Monte Carlo Tree Search with LLM-based optimization to iteratively refine workflows, yielding a 19.5% average performance improvement over existing automated methods while enabling smaller, more cost-effective LLMs to achieve performance parity with larger models.

11 Jul 2022

DINO, a Transformer-based end-to-end object detector, integrates improved denoising training, mixed query selection, and a 'look forward twice' scheme to significantly advance performance. The model achieved a state-of-the-art 63.2 AP on COCO val2017 using a SwinL backbone, outperforming previous highly optimized classical detectors.

29 Jan 2024


TIME-LLM introduces a reprogramming framework that adapts large language models for general time series forecasting by keeping the LLM backbone frozen. The approach achieves state-of-the-art performance across various benchmarks, excelling particularly in data-scarce few-shot and zero-shot settings.

09 Apr 2025
This survey paper provides a comprehensive review of Mixture of Experts (MoE) in Large Language Models (LLMs), addressing the computational challenges of scaling and the lack of an up-to-date overview. It presents a novel taxonomy for MoE advancements, detailing key findings across algorithmic design, system optimizations, and diverse applications like NLP, CV, and multimodal systems.

21 Nov 2025
The primate visual cortex exhibits topographic organization, where functionally similar neurons are spatially clustered, a structure widely believed to enhance neural processing efficiency. While prior works have demonstrated that conventional deep ANNs can develop topographic representations, these models largely neglect crucial temporal dynamics. This oversight often leads to significant performance degradation in tasks like object recognition and compromises their biological fidelity. To address this, we leverage spiking neural networks (SNNs), which inherently capture spike-based temporal dynamics and offer enhanced biological plausibility. We propose a novel Spatio-Temporal Constraints (STC) loss function for topographic deep spiking neural networks (TDSNNs), successfully replicating the hierarchical spatial functional organization observed in the primate visual cortex from low-level sensory input to high-level abstract representations. Our results show that STC effectively generates representative topographic features across simulated visual cortical areas. While introducing topography typically leads to significant performance degradation in ANNs, our spiking architecture exhibits a remarkably small performance drop (No drop in ImageNet top-1 accuracy, compared to a 3% drop observed in TopoNet, which is the best-performing topographic ANN so far) and outperforms topographic ANNs in brain-likeness. We also reveal that topographic organization facilitates efficient and stable temporal information processing via the spike mechanism in TDSNNs, contributing to model robustness. These findings suggest that TDSNNs offer a compelling balance between computational performance and brain-like features, providing not only a framework for interpreting neural science phenomena but also novel insights for designing more efficient and robust deep learning models.

31 Aug 2025
SegDINO introduces an efficient segmentation framework that leverages a frozen DINOv3 Vision Transformer backbone and an uncommonly lightweight, MLP-based decoder to achieve state-of-the-art performance across diverse medical and natural image segmentation tasks with significantly reduced parameter counts and high inference speed. The framework demonstrates improved Dice scores and IoU on datasets like TN3K, Kvasir-SEG, and MSD, while maintaining high efficiency at only 2.21 million trainable parameters and 53 FPS.
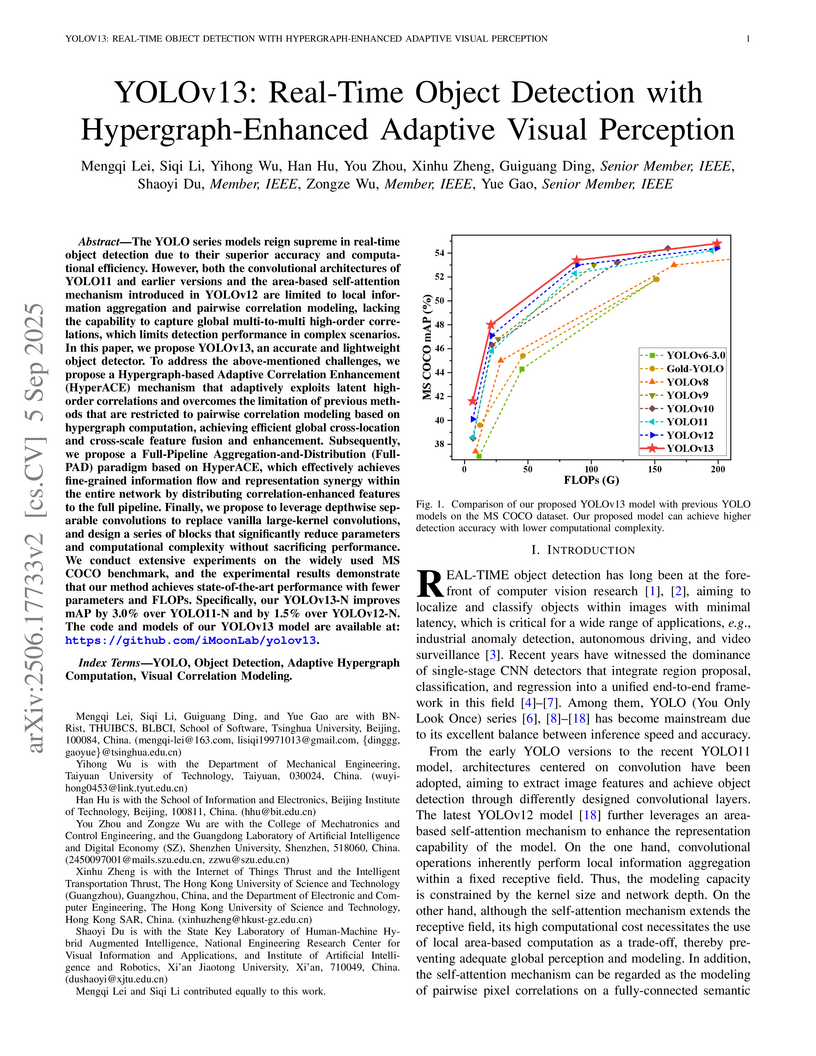
05 Sep 2025
YOLOv13 enhances real-time object detection by integrating an adaptive hypergraph computation mechanism for high-order visual correlation modeling and a full-pipeline feature distribution paradigm. The approach yields improved detection accuracy on the MS COCO benchmark, with the Nano variant achieving a 1.5% mAP@50:95 increase over YOLOv12-N, while maintaining or reducing computational cost.

20 Sep 2025
This survey paper, from researchers at CUHK, Huawei, HKUST (Guangzhou), and NUS, systematically reviews Personalized Large Language Models (PLLMs), proposing a three-level technical taxonomy and articulating a trilemma among personalization efficacy, computational efficiency, and user privacy. It consolidates existing methods and outlines future research directions for building user-specific AI systems.

25 Nov 2025
Researchers from The Hong Kong University of Science and Technology (Guangzhou) and Horizon Robotics introduced VGGT4D, a training-free framework that extends the VGGT 3D foundation model to perform robust 4D scene reconstruction by mining implicit motion cues from its global attention layers. This approach achieves state-of-the-art results across various dynamic scene benchmarks for object segmentation, camera pose, and 4D point cloud reconstruction, demonstrating superior performance on long sequences.
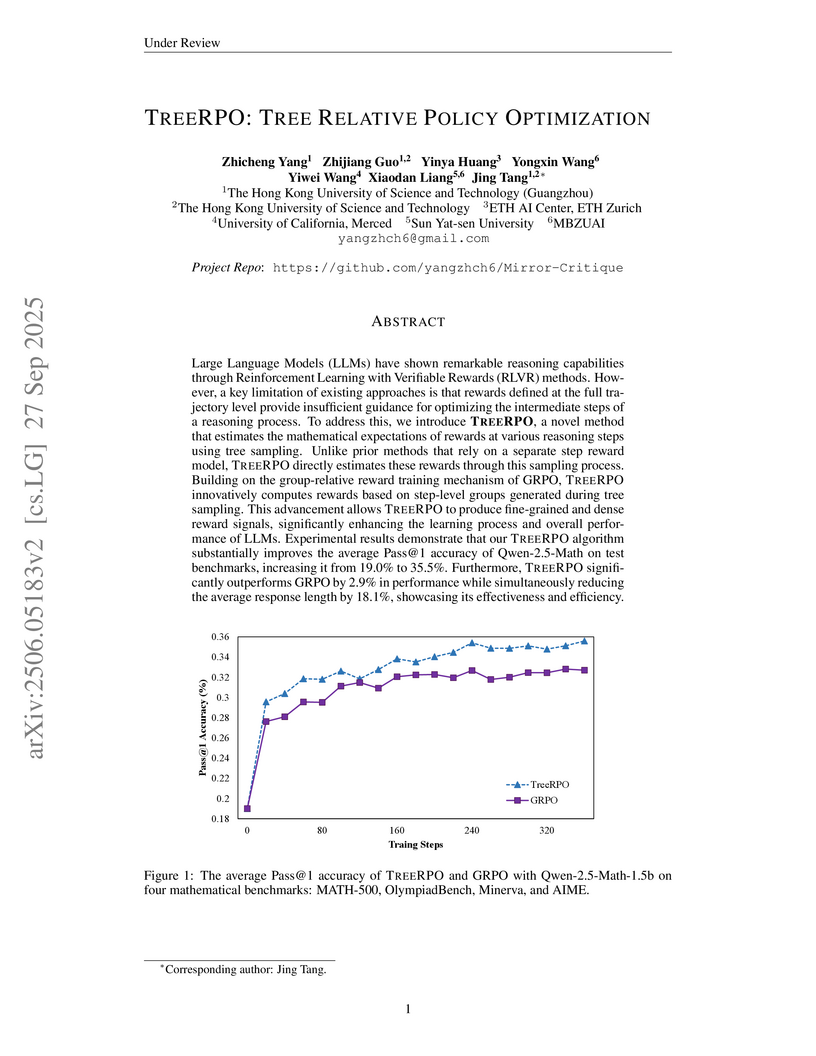
27 Sep 2025



TREERPO enhances Large Language Model reasoning by employing a novel tree sampling mechanism to generate fine-grained, step-level reward signals without requiring a separate process reward model. This method improves Pass@1 accuracy by up to 16.5% for Qwen2.5-Math-1.5B and reduces average response length by 18.1% compared to GRPO.

15 Sep 2025


SpeCa introduces a "Forecast-then-verify" acceleration framework for Diffusion Transformers, adapting principles from speculative decoding to reduce computational cost while preserving generation quality. This method achieves up to 6.34x acceleration on FLUX.1-dev with minimal quality degradation and 6.16x on HunyuanVideo, consistently outperforming existing approaches.
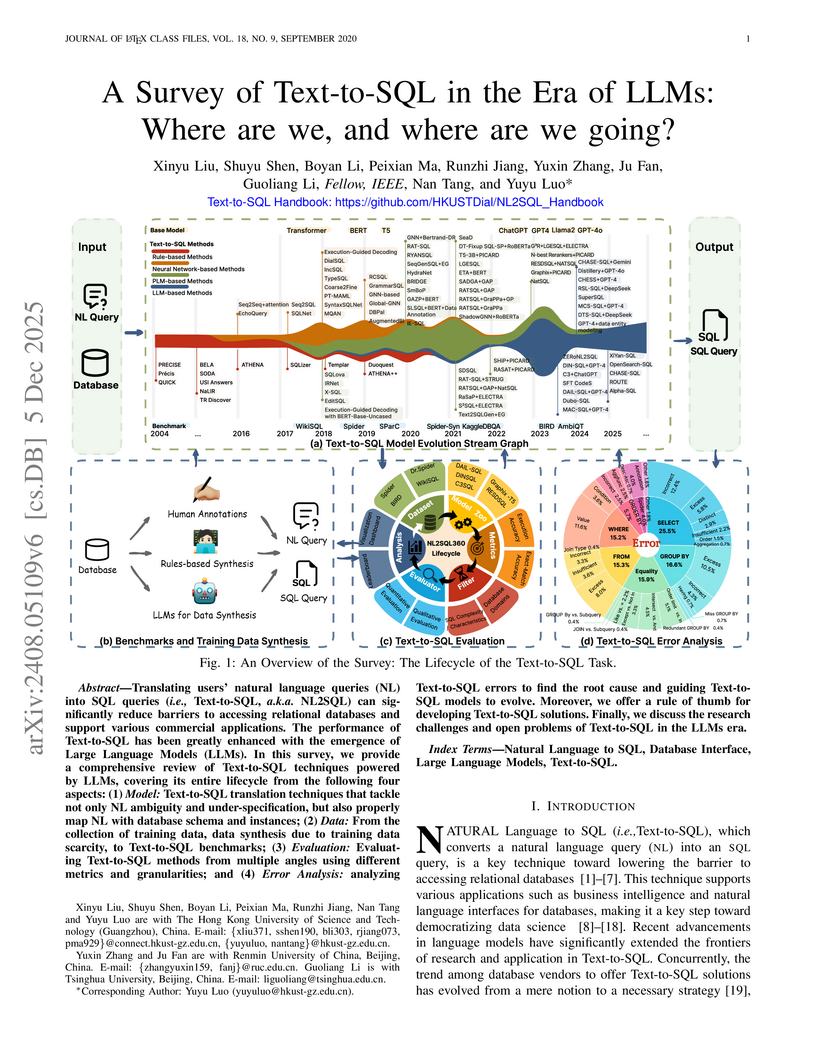
05 Dec 2025
Translating users' natural language queries (NL) into SQL queries (i.e., Text-to-SQL, a.k.a. NL2SQL) can significantly reduce barriers to accessing relational databases and support various commercial applications. The performance of Text-to-SQL has been greatly enhanced with the emergence of Large Language Models (LLMs). In this survey, we provide a comprehensive review of Text-to-SQL techniques powered by LLMs, covering its entire lifecycle from the following four aspects: (1) Model: Text-to-SQL translation techniques that tackle not only NL ambiguity and under-specification, but also properly map NL with database schema and instances; (2) Data: From the collection of training data, data synthesis due to training data scarcity, to Text-to-SQL benchmarks; (3) Evaluation: Evaluating Text-to-SQL methods from multiple angles using different metrics and granularities; and (4) Error Analysis: analyzing Text-to-SQL errors to find the root cause and guiding Text-to-SQL models to evolve. Moreover, we offer a rule of thumb for developing Text-to-SQL solutions. Finally, we discuss the research challenges and open problems of Text-to-SQL in the LLMs era. Text-to-SQL Handbook: this https URL Handbook

02 Jun 2025

Researchers from Johns Hopkins University, HKUST, and medical institutions develop Medical World Model (MeWM), the first medical AI system to simulate tumor evolution by generating realistic post-treatment CT scans and optimizing interventional protocols, achieving 52.38% F1-score in treatment selection (outperforming GPT-4o's 41.97%) and demonstrating 13% improvement in physician decision-making for hepatocellular carcinoma TACE procedures through a novel framework combining vision-language policy models with diffusion-based dynamics simulation and survival analysis, validated by radiologists who mistook 25-29% of synthetic post-treatment tumors for real images while the system's risk stratification achieved 0.752 c-index compared to traditional Cox model's 0.472, establishing a new paradigm for visually-grounded predictive medicine that moves beyond static diagnosis toward dynamic treatment outcome simulation.

18 Nov 2025
The Mixture-of-Memories (MoM) architecture replaces a single recurrent state with multiple, independent memory states and a routing mechanism, enhancing linear sequence models' ability to retain information over long sequences. This design enables performance on recall-intensive tasks comparable to Transformer models while maintaining linear time complexity during training and constant time inference.

10 Nov 2024
This comprehensive survey addresses the critical void of an up-to-date literature review specifically for Large Language Models in natural language to code generation, providing a systematic categorization of advancements and an empirical comparison of leading models. It highlights the narrowing performance gap between open and closed-source models and underscores the importance of instruction tuning and ethical alignment for practical applications.

13 Apr 2025


HM-RAG presents a hierarchical multi-agent multimodal Retrieval-Augmented Generation framework designed to integrate knowledge from text, graph, and web sources. This framework achieved state-of-the-art accuracy of 93.73% on the ScienceQA benchmark and 58.55% on CrisisMMD, demonstrating robust multimodal reasoning and an ability to outperform previous models and human experts on specific tasks.

19 May 2025
TIMEMIXER++, developed by researchers from Griffith University, Zhejiang University, and MIT, presents a general-purpose time series pattern machine capable of dynamically capturing patterns across multiple temporal scales and frequency resolutions. The model consistently achieves state-of-the-art performance across 8 diverse time series tasks, including long-term forecasting (reducing MSE on Electricity by 7.3%), imputation (outperforming TimesNet by 25.7% in MSE), and zero-shot forecasting (reducing MSE by 13.1%).
There are no more papers matching your filters at the moment.
