
16 May 2018

Researchers at the U.S. Army Research Laboratory introduce EEGNet, a compact convolutional neural network for EEG-based Brain-Computer Interfaces that classifies signals across diverse BCI paradigms. This architecture achieves performance comparable to or exceeding existing methods while being two orders of magnitude smaller in terms of parameters and learning neurophysiologically interpretable features.

29 Oct 2024



Researchers from the University of Maryland, U.S. Army Research Laboratory, Princeton University, and University of Central Florida introduce AIME, a novel evaluation protocol that utilizes multiple specialized LLM evaluators within iterative AI system optimization pipelines. This approach significantly enhances error detection and achieves higher task performance in complex scenarios like code generation by addressing the limitations of single-LLM evaluators.

01 Jun 2025

DriveMind introduces a dual-VLM reinforcement learning framework for autonomous driving that integrates hierarchical safety constraints and dynamic semantic reward generation. The system achieves near-zero collisions and state-of-the-art performance in the CARLA simulator, demonstrating robust zero-shot generalization to real-world dash-cam data.

11 May 2018

A novel imitation learning algorithm, Behavioral Cloning from Observation (BCO), enables agents to learn complex tasks solely from state trajectories, circumventing the need for expert action data. This two-phase approach significantly reduces post-demonstration environment interactions, achieving performance comparable to state-of-the-art methods while requiring up to 40 times fewer subsequent interactions.

26 Sep 2025

Open-source software projects are foundational to modern software ecosystems, with the Linux kernel standing out as a critical exemplar due to its ubiquity and complexity. Although security patches are continuously integrated into the Linux mainline kernel, downstream maintainers often delay their adoption, creating windows of vulnerability. A key reason for this lag is the difficulty in identifying security-critical patches, particularly those addressing exploitable vulnerabilities such as out-of-bounds (OOB) accesses and use-after-free (UAF) bugs. This challenge is exacerbated by intentionally silent bug fixes, incomplete or missing CVE assignments, delays in CVE issuance, and recent changes to the CVE assignment criteria for the Linux kernel. While fine-grained patch classification approaches exist, they exhibit limitations in both coverage and accuracy. In this work, we identify previously unexplored opportunities to significantly improve fine-grained patch classification. Specifically, by leveraging cues from commit titles/messages and diffs alongside appropriate code context, we develop DUALLM, a dual-method pipeline that integrates two approaches based on a Large Language Model (LLM) and a fine-tuned small language model. DUALLM achieves 87.4% accuracy and an F1-score of 0.875, significantly outperforming prior solutions. Notably, DUALLM successfully identified 111 of 5,140 recent Linux kernel patches as addressing OOB or UAF vulnerabilities, with 90 true positives confirmed by manual verification (many do not have clear indications in patch descriptions). Moreover, we constructed proof-of-concepts for two identified bugs (one UAF and one OOB), including one developed to conduct a previously unknown control-flow hijack as further evidence of the correctness of the classification.

07 Mar 2022

While both navigation and manipulation are challenging topics in isolation, many tasks require the ability to both navigate and manipulate in concert. To this end, we propose a mobile manipulation system that leverages novel navigation and shape completion methods to manipulate an object with a mobile robot. Our system utilizes uncertainty in the initial estimation of a manipulation target to calculate a predicted next-best-view. Without the need of localization, the robot then uses the predicted panoramic view at the next-best-view location to navigate to the desired location, capture a second view of the object, create a new model that predicts the shape of object more accurately than a single image alone, and uses this model for grasp planning. We show that the system is highly effective for mobile manipulation tasks through simulation experiments using real world data, as well as ablations on each component of our system.

18 Jun 2019
Imitation from observation (IfO) is the problem of learning directly from state-only demonstrations without having access to the demonstrator's actions. The lack of action information both distinguishes IfO from most of the literature in imitation learning, and also sets it apart as a method that may enable agents to learn from a large set of previously inapplicable resources such as internet videos. In this paper, we propose both a general framework for IfO approaches and also a new IfO approach based on generative adversarial networks called generative adversarial imitation from observation (GAIfO). We conduct experiments in two different settings: (1) when demonstrations consist of low-dimensional, manually-defined state features, and (2) when demonstrations consist of high-dimensional, raw visual data. We demonstrate that our approach performs comparably to classical imitation learning approaches (which have access to the demonstrator's actions) and significantly outperforms existing imitation from observation methods in high-dimensional simulation environments.

19 Apr 2016
The complex compositional structure of language makes problems at the
intersection of vision and language challenging. But language also provides a
strong prior that can result in good superficial performance, without the
underlying models truly understanding the visual content. This can hinder
progress in pushing state of art in the computer vision aspects of multi-modal
AI. In this paper, we address binary Visual Question Answering (VQA) on
abstract scenes. We formulate this problem as visual verification of concepts
inquired in the questions. Specifically, we convert the question to a tuple
that concisely summarizes the visual concept to be detected in the image. If
the concept can be found in the image, the answer to the question is "yes", and
otherwise "no". Abstract scenes play two roles (1) They allow us to focus on
the high-level semantics of the VQA task as opposed to the low-level
recognition problems, and perhaps more importantly, (2) They provide us the
modality to balance the dataset such that language priors are controlled, and
the role of vision is essential. In particular, we collect fine-grained pairs
of scenes for every question, such that the answer to the question is "yes" for
one scene, and "no" for the other for the exact same question. Indeed, language
priors alone do not perform better than chance on our balanced dataset.
Moreover, our proposed approach matches the performance of a state-of-the-art
VQA approach on the unbalanced dataset, and outperforms it on the balanced
dataset.

22 Feb 2021




Existing studies on question answering on knowledge bases (KBQA) mainly operate with the standard i.i.d assumption, i.e., training distribution over questions is the same as the test distribution. However, i.i.d may be neither reasonably achievable nor desirable on large-scale KBs because 1) true user distribution is hard to capture and 2) randomly sample training examples from the enormous space would be highly data-inefficient. Instead, we suggest that KBQA models should have three levels of built-in generalization: i.i.d, compositional, and zero-shot. To facilitate the development of KBQA models with stronger generalization, we construct and release a new large-scale, high-quality dataset with 64,331 questions, GrailQA, and provide evaluation settings for all three levels of generalization. In addition, we propose a novel BERT-based KBQA model. The combination of our dataset and model enables us to thoroughly examine and demonstrate, for the first time, the key role of pre-trained contextual embeddings like BERT in the generalization of KBQA.

17 Apr 2024
Deep neural networks (DNNs) have been shown to perform well on exclusive, multi-class classification tasks. However, when different classes have similar visual features, it becomes challenging for human annotators to differentiate them. This scenario necessitates the use of composite class labels. In this paper, we propose a novel framework called Hyper-Evidential Neural Network (HENN) that explicitly models predictive uncertainty due to composite class labels in training data in the context of the belief theory called Subjective Logic (SL). By placing a grouped Dirichlet distribution on the class probabilities, we treat predictions of a neural network as parameters of hyper-subjective opinions and learn the network that collects both single and composite evidence leading to these hyper-opinions by a deterministic DNN from data. We introduce a new uncertainty type called vagueness originally designed for hyper-opinions in SL to quantify composite classification uncertainty for DNNs. Our results demonstrate that HENN outperforms its state-of-the-art counterparts based on four image datasets. The code and datasets are available at: this https URL.

07 Jun 2023
The implicit particle filter seeks to mitigate particle degeneracy by identifying particles in the target distribution's high-probability regions. This study is motivated by the need to enhance computational tractability in implementing this approach. We investigate the connection of the particle update step in the implicit particle filter with that of the Kalman filter and then formulate a novel realization of the implicit particle filter based on a bank of nonlinear Kalman filters. This realization is more amenable and efficient computationally.

13 Mar 2025
Reinforcement learning (RL) is a promising approach for robotic navigation,
allowing robots to learn through trial and error. However, real-world robotic
tasks often suffer from sparse rewards, leading to inefficient exploration and
suboptimal policies due to sample inefficiency of RL. In this work, we
introduce Confidence-Controlled Exploration (CCE), a novel method that improves
sample efficiency in RL-based robotic navigation without modifying the reward
function. Unlike existing approaches, such as entropy regularization and reward
shaping, which can introduce instability by altering rewards, CCE dynamically
adjusts trajectory length based on policy entropy. Specifically, it shortens
trajectories when uncertainty is high to enhance exploration and extends them
when confidence is high to prioritize exploitation. CCE is a principled and
practical solution inspired by a theoretical connection between policy entropy
and gradient estimation. It integrates seamlessly with on-policy and off-policy
RL methods and requires minimal modifications. We validate CCE across
REINFORCE, PPO, and SAC in both simulated and real-world navigation tasks. CCE
outperforms fixed-trajectory and entropy-regularized baselines, achieving an
18\% higher success rate, 20-38\% shorter paths, and 9.32\% lower elevation
costs under a fixed training sample budget. Finally, we deploy CCE on a
Clearpath Husky robot, demonstrating its effectiveness in complex outdoor
environments.

12 Sep 2023
In the context of the interaction between a moving plane shock wave and an inclined wall (wedge), it is possible to distinguish four distinct shock reflection configurations. These shock wave reflections, which depend on the characteristics of the incident shock wave and the geometry of the surface that it interacts with, are (i) regular reflection (RR), (ii) simple Mach reflection (SMR), (iii) transition Mach reflection (TMR), and (iv) double Mach reflection (DMR). The impact of these shock reflections on flow properties can be significant so understanding them is important when predicting the behavior of shock waves in more complex flow configurations. Previous research works have explored the referred shock reflections through both numerical and experimental approaches, employing various gases and different flow and geometrical configurations. The present study involves the use of a high-fidelity computational fluid dynamics (CFD) tool, known as PeleC, which is a compressible solver based on AMReX specifically designed to handle complex flow configurations. Accordingly, by solving the time-dependent Euler equations for various 2D flow configurations, this work studies shock wave reflections accounting for four different Mach-based operating conditions and compares and analyzes the resulting density profiles on the wedge wall with experimental data. To strike a balance between model accuracy and computational efficiency, adaptive mesh refinement (AMR) is incorporated, and a mesh independence study is performed by varying the number of AMR levels. The results of this study demonstrate the capabilities of the CFD tool employed as it accurately predicts the sensitivity of wave characteristics to different operating conditions.

15 Apr 2021



Conventional wisdom holds that macroscopic classical phenomena naturally
emerge from microscopic quantum laws. However, despite this mantra, building
direct connections between these two descriptions has remained an enduring
scientific challenge. In particular, it is difficult to quantitatively predict
the emergent "classical" properties of a system (e.g. diffusivity, viscosity,
compressibility) from a generic microscopic quantum Hamiltonian. Here, we
introduce a hybrid solid-state spin platform, where the underlying disordered,
dipolar quantum Hamiltonian gives rise to the emergence of unconventional spin
diffusion at nanometer length scales. In particular, the combination of
positional disorder and on-site random fields leads to diffusive dynamics that
are Fickian yet non-Gaussian. Finally, by tuning the underlying parameters
within the spin Hamiltonian via a combination of static and driven fields, we
demonstrate direct control over the emergent spin diffusion coefficient. Our
work opens the door to investigating hydrodynamics in many-body quantum spin
systems.

10 Jun 2022
We study the problem of developing autonomous agents that can follow human
instructions to infer and perform a sequence of actions to complete the
underlying task. Significant progress has been made in recent years, especially
for tasks with short horizons. However, when it comes to long-horizon tasks
with extended sequences of actions, an agent can easily ignore some
instructions or get stuck in the middle of the long instructions and eventually
fail the task. To address this challenge, we propose a model-agnostic
milestone-based task tracker (M-TRACK) to guide the agent and monitor its
progress. Specifically, we propose a milestone builder that tags the
instructions with navigation and interaction milestones which the agent needs
to complete step by step, and a milestone checker that systemically checks the
agent's progress in its current milestone and determines when to proceed to the
next. On the challenging ALFRED dataset, our M-TRACK leads to a notable 33% and
52% relative improvement in unseen success rate over two competitive base
models.

06 Feb 2025
Entropy-based objectives are widely used to perform state space exploration
in reinforcement learning (RL) and dataset generation for offline RL.
Behavioral entropy (BE), a rigorous generalization of classical entropies that
incorporates cognitive and perceptual biases of agents, was recently proposed
for discrete settings and shown to be a promising metric for robotic
exploration problems. In this work, we propose using BE as a principled
exploration objective for systematically generating datasets that provide
diverse state space coverage in complex, continuous, potentially
high-dimensional domains. To achieve this, we extend the notion of BE to
continuous settings, derive tractable -nearest neighbor estimators, provide
theoretical guarantees for these estimators, and develop practical reward
functions that can be used with standard RL methods to learn BE-maximizing
policies. Using standard MuJoCo environments, we experimentally compare the
performance of offline RL algorithms for a variety of downstream tasks on
datasets generated using BE, R\'{e}nyi, and Shannon entropy-maximizing
policies, as well as the SMM and RND algorithms. We find that offline RL
algorithms trained on datasets collected using BE outperform those trained on
datasets collected using Shannon entropy, SMM, and RND on all tasks considered,
and on 80% of the tasks compared to datasets collected using R\'{e}nyi entropy.

14 Nov 2018
During the last half decade, convolutional neural networks (CNNs) have
triumphed over semantic segmentation, which is one of the core tasks in many
applications such as autonomous driving. However, to train CNNs requires a
considerable amount of data, which is difficult to collect and laborious to
annotate. Recent advances in computer graphics make it possible to train CNNs
on photo-realistic synthetic imagery with computer-generated annotations.
Despite this, the domain mismatch between the real images and the synthetic
data cripples the models' performance. Hence, we propose a curriculum-style
learning approach to minimize the domain gap in urban scenery semantic
segmentation. The curriculum domain adaptation solves easy tasks first to infer
necessary properties about the target domain; in particular, the first task is
to learn global label distributions over images and local distributions over
landmark superpixels. These are easy to estimate because images of urban scenes
have strong idiosyncrasies (e.g., the size and spatial relations of buildings,
streets, cars, etc.). We then train a segmentation network while regularizing
its predictions in the target domain to follow those inferred properties. In
experiments, our method outperforms the baselines on two datasets and two
backbone networks. We also report extensive ablation studies about our
approach.

03 Apr 2020

This paper investigates how to efficiently transition and update policies, trained initially with demonstrations, using off-policy actor-critic reinforcement learning. It is well-known that techniques based on Learning from Demonstrations, for example behavior cloning, can lead to proficient policies given limited data. However, it is currently unclear how to efficiently update that policy using reinforcement learning as these approaches are inherently optimizing different objective functions. Previous works have used loss functions, which combine behavior cloning losses with reinforcement learning losses to enable this update. However, the components of these loss functions are often set anecdotally, and their individual contributions are not well understood. In this work, we propose the Cycle-of-Learning (CoL) framework that uses an actor-critic architecture with a loss function that combines behavior cloning and 1-step Q-learning losses with an off-policy pre-training step from human demonstrations. This enables transition from behavior cloning to reinforcement learning without performance degradation and improves reinforcement learning in terms of overall performance and training time. Additionally, we carefully study the composition of these combined losses and their impact on overall policy learning. We show that our approach outperforms state-of-the-art techniques for combining behavior cloning and reinforcement learning for both dense and sparse reward scenarios. Our results also suggest that directly including the behavior cloning loss on demonstration data helps to ensure stable learning and ground future policy updates.
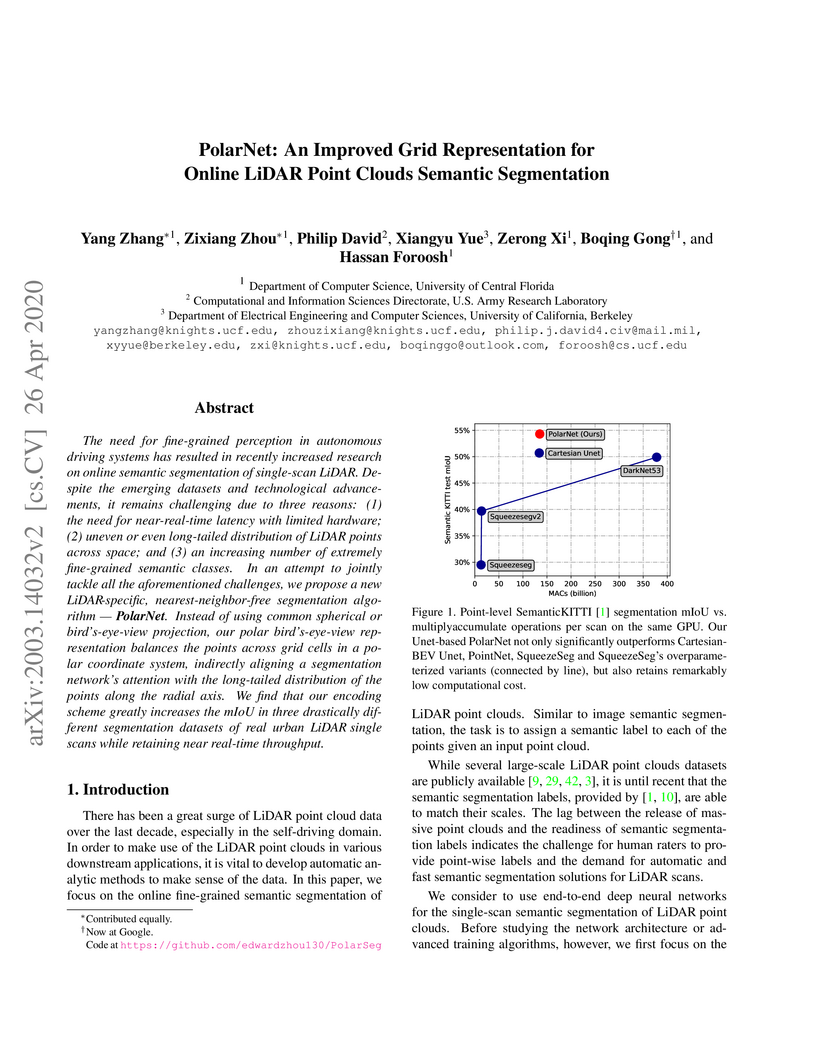
26 Apr 2020
The need for fine-grained perception in autonomous driving systems has resulted in recently increased research on online semantic segmentation of single-scan LiDAR. Despite the emerging datasets and technological advancements, it remains challenging due to three reasons: (1) the need for near-real-time latency with limited hardware; (2) uneven or even long-tailed distribution of LiDAR points across space; and (3) an increasing number of extremely fine-grained semantic classes. In an attempt to jointly tackle all the aforementioned challenges, we propose a new LiDAR-specific, nearest-neighbor-free segmentation algorithm - PolarNet. Instead of using common spherical or bird's-eye-view projection, our polar bird's-eye-view representation balances the points across grid cells in a polar coordinate system, indirectly aligning a segmentation network's attention with the long-tailed distribution of the points along the radial axis. We find that our encoding scheme greatly increases the mIoU in three drastically different segmentation datasets of real urban LiDAR single scans while retaining near real-time throughput.

12 Mar 2025

This paper considers the problem of designing motion planning algorithms for control-affine systems that generate collision-free paths from an initial to a final destination and can be executed using safe and dynamically-feasible controllers. We introduce the C-CLF-CBF-RRT algorithm, which produces paths with such properties and leverages rapidly exploring random trees (RRTs), control Lyapunov functions (CLFs) and control barrier functions (CBFs). We show that C-CLF-CBF-RRT is computationally efficient for linear systems with polytopic and ellipsoidal constraints, and establish its probabilistic completeness. We showcase the performance of C-CLF-CBF-RRT in different simulation and hardware experiments.
There are no more papers matching your filters at the moment.
