
21 May 2023

A comprehensive review offers a consolidated understanding of Generative Pre-trained Transformers (GPTs), detailing their architectural evolution from GPT-1 to GPT-4, underlying technologies, and widespread applications across diverse sectors. The work identifies key challenges and outlines future research directions, serving as a foundational resource for the rapidly evolving field of large language models.

06 Oct 2025


Researchers from Nanyang Technological University and collaborators propose a neuroscience-inspired "Neural Brain" framework for embodied agents, integrating multimodal active sensing, perception-cognition-action loops, neuroplasticity-driven memory, and energy-efficient neuromorphic hardware. This work defines the core components and architecture for building adaptable, real-world interactive AI systems.

08 Apr 2025
ShadowCoT introduces a framework for implanting stealthy reasoning backdoors in large language models by hijacking their internal cognitive processes. This enables LLMs to generate incorrect answers through seemingly valid reasoning chains, achieving attack success rates up to 94.4% on the AQUA-RAT task and demonstrating transferability across reasoning tasks.

06 May 2024
This comprehensive survey from the University of Agder's Top Research Centre Mechatronics reviews Gaussian Splatting, an explicit point-based 3D scene representation technique. It highlights the method's ability to achieve real-time rendering and dramatically faster training times for 3D reconstruction and novel view synthesis compared to Neural Radiance Fields, while also supporting dynamic scene modeling and generative content creation.

02 Jan 2021
The Tsetlin Machine, developed by Ole-Christoffer Granmo at the University of Agder, introduces a pattern recognition paradigm that utilizes game theory and Tsetlin Automata to learn propositional logic clauses. This approach addresses the scalability limitations of traditional Learning Automata and achieves competitive accuracy while providing inherent interpretability and high computational efficiency.
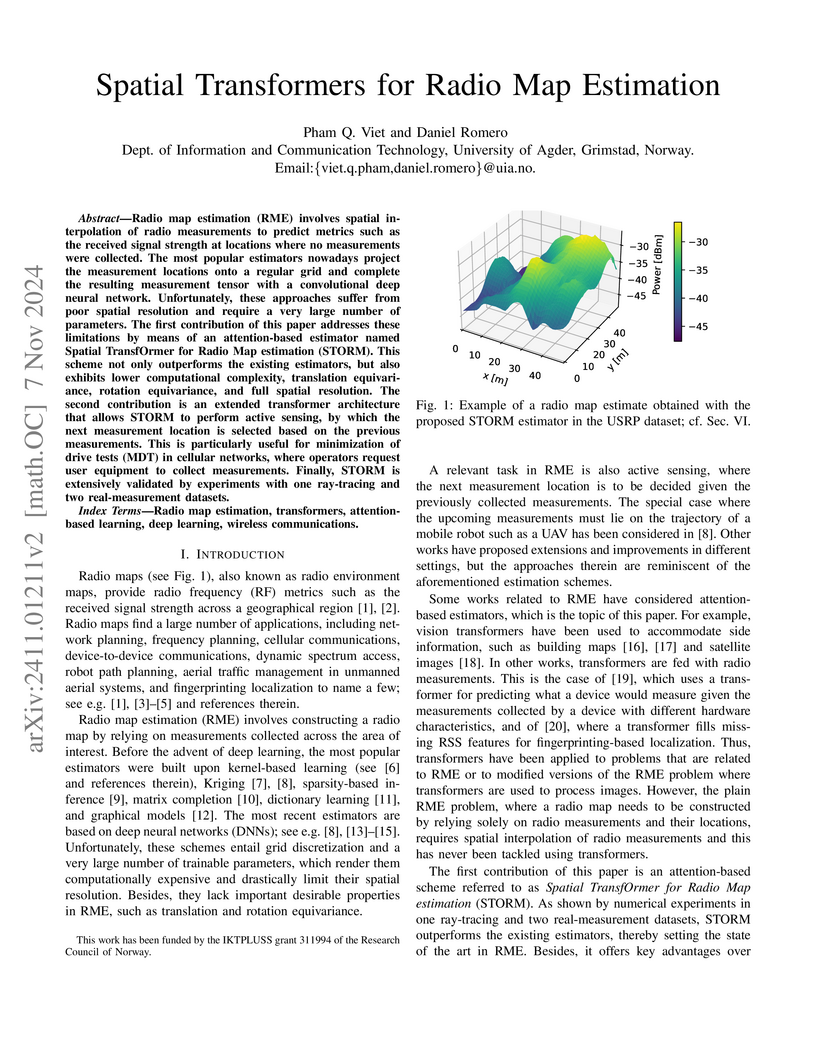
07 Nov 2024
The University of Agder researchers developed Spatial TransfOrmer for Radio Map estimation (STORM), an attention-based deep learning model that achieves state-of-the-art accuracy in radio map prediction with significantly fewer parameters. It operates in a gridless manner and effectively supports active sensing to optimize data collection.

10 Apr 2025
In recent years, text generation tools utilizing Artificial Intelligence (AI)
have occasionally been misused across various domains, such as generating
student reports or creative writings. This issue prompts plagiarism detection
services to enhance their capabilities in identifying AI-generated content.
Adversarial attacks are often used to test the robustness of AI-text generated
detectors. This work proposes a novel textual adversarial attack on the
detection models such as Fast-DetectGPT. The method employs embedding models
for data perturbation, aiming at reconstructing the AI generated texts to
reduce the likelihood of detection of the true origin of the texts.
Specifically, we employ different embedding techniques, including the Tsetlin
Machine (TM), an interpretable approach in machine learning for this purpose.
By combining synonyms and embedding similarity vectors, we demonstrates the
state-of-the-art reduction in detection scores against Fast-DetectGPT.
Particularly, in the XSum dataset, the detection score decreased from 0.4431 to
0.2744 AUROC, and in the SQuAD dataset, it dropped from 0.5068 to 0.3532 AUROC.

04 May 2025
Document chunking fundamentally impacts Retrieval-Augmented Generation (RAG)
by determining how source materials are segmented before indexing. Despite
evidence that Large Language Models (LLMs) are sensitive to the layout and
structure of retrieved data, there is currently no framework to analyze the
impact of different chunking methods. In this paper, we introduce a novel
methodology that defines essential characteristics of the chunking process at
three levels: intrinsic passage properties, extrinsic passage properties, and
passages-document coherence. We propose HOPE (Holistic Passage Evaluation), a
domain-agnostic, automatic evaluation metric that quantifies and aggregates
these characteristics. Our empirical evaluations across seven domains
demonstrate that the HOPE metric correlates significantly (p > 0.13) with
various RAG performance indicators, revealing contrasts between the importance
of extrinsic and intrinsic properties of passages. Semantic independence
between passages proves essential for system performance with a performance
gain of up to 56.2% in factual correctness and 21.1% in answer correctness. On
the contrary, traditional assumptions about maintaining concept unity within
passages show minimal impact. These findings provide actionable insights for
optimizing chunking strategies, thus improving RAG system design to produce
more factually correct responses.

25 Apr 2024

In this paper, we address the challenging source-free unsupervised domain
adaptation (SFUDA) for pinhole-to-panoramic semantic segmentation, given only a
pinhole image pre-trained model (i.e., source) and unlabeled panoramic images
(i.e., target). Tackling this problem is non-trivial due to three critical
challenges: 1) semantic mismatches from the distinct Field-of-View (FoV)
between domains, 2) style discrepancies inherent in the UDA problem, and 3)
inevitable distortion of the panoramic images. To tackle these problems, we
propose 360SFUDA++ that effectively extracts knowledge from the source pinhole
model with only unlabeled panoramic images and transfers the reliable knowledge
to the target panoramic domain. Specifically, we first utilize Tangent
Projection (TP) as it has less distortion and meanwhile slits the
equirectangular projection (ERP) to patches with fixed FoV projection (FFP) to
mimic the pinhole images. Both projections are shown effective in extracting
knowledge from the source model. However, as the distinct projections make it
less possible to directly transfer knowledge between domains, we then propose
Reliable Panoramic Prototype Adaptation Module (RP2AM) to transfer knowledge at
both prediction and prototype levels. RPAM selects the confident knowledge
and integrates panoramic prototypes for reliable knowledge adaptation.
Moreover, we introduce Cross-projection Dual Attention Module (CDAM), which
better aligns the spatial and channel characteristics across projections at the
feature level between domains. Both knowledge extraction and transfer processes
are synchronously updated to reach the best performance. Extensive experiments
on the synthetic and real-world benchmarks, including outdoor and indoor
scenarios, demonstrate that our 360SFUDA++ achieves significantly better
performance than prior SFUDA methods.

22 Sep 2025
Non-collinear antiferromagnets (NCAFMs) are appealing for antiferromagnetic spintronics, as they combine the advantages of collinear antiferromagnets with novel emergent phenomena stemming from their complex spin structures. These phenomena are often associated with the intrinsic spin chirality, which characterizes the handedness of the ground-state spin configuration. Here, we investigate a kagome NCAFM interfaced with a normal metal and demonstrate that the ground-state vector spin chirality can be probed through measurements of the spin Seebeck effect (SSE). Starting from a microscopic spin Hamiltonian, we derive the corresponding bosonic Bogoliubov-de Gennes Hamiltonians for the two chiral configurations. Using linear response theory, we obtain a general expression for the spin current thermally pumped into the normal metal by the SSE. We show that a sizable in-plane spin current emerges exclusively in the negative-chiral state, providing a direct signature for real-time detection of chirality switching in kagome NCAFMs. In addition, we find a field-dependent out-of-plane spin current whose magnitude differs between the two chiralities by about 4%, reflecting their distinct magnon band structures.

19 Oct 2025
Feature embedding has become a cornerstone technology for processing high-dimensional and complex data, which results in that Embedding as a Service (EaaS) models have been widely deployed in the cloud. To protect the intellectual property of EaaS models, existing methods apply digital watermarking to inject specific backdoor triggers into EaaS models by modifying training samples or network parameters. However, these methods inevitably produce detectable patterns through semantic analysis and exhibit susceptibility to geometric transformations including rotation, scaling, and translation (RST). To address this problem, we propose a fingerprinting framework for EaaS models, rather than merely refining existing watermarking techniques. Different from watermarking techniques, the proposed method establishes EaaS model ownership through geometric analysis of embedding space's topological structure, rather than relying on the modified training samples or triggers. The key innovation lies in modeling the victim and suspicious embeddings as point clouds, allowing us to perform robust spatial alignment and similarity measurement, which inherently resists RST attacks. Experimental results evaluated on visual and textual embedding tasks verify the superiority and applicability. This research reveals inherent characteristics of EaaS models and provides a promising solution for ownership verification of EaaS models under the black-box scenario.

18 Nov 2024
We propose an error-correcting model for the microprice, a high-frequency estimator of future prices given higher order information of imbalances in the orderbook. The model takes into account a current microprice estimate given the spread and best bid to ask imbalance, and adjusts the microprice based on recent dynamics of higher price rank imbalances. We introduce a computationally fast estimator using a recently proposed hyperdimensional vector Tsetlin machine framework and demonstrate empirically that this estimator can provide a robust estimate of future prices in the orderbook.

11 Nov 2021
The past decade has seen significant progress in artificial intelligence (AI), which has resulted in algorithms being adopted for resolving a variety of problems. However, this success has been met by increasing model complexity and employing black-box AI models that lack transparency. In response to this need, Explainable AI (XAI) has been proposed to make AI more transparent and thus advance the adoption of AI in critical domains. Although there are several reviews of XAI topics in the literature that identified challenges and potential research directions in XAI, these challenges and research directions are scattered. This study, hence, presents a systematic meta-survey for challenges and future research directions in XAI organized in two themes: (1) general challenges and research directions in XAI and (2) challenges and research directions in XAI based on machine learning life cycle's phases: design, development, and deployment. We believe that our meta-survey contributes to XAI literature by providing a guide for future exploration in the XAI area.

02 Oct 2018
Reinforcement learning has shown great potential in generalizing over raw sensory data using only a single neural network for value optimization. There are several challenges in the current state-of-the-art reinforcement learning algorithms that prevent them from converging towards the global optima. It is likely that the solution to these problems lies in short- and long-term planning, exploration and memory management for reinforcement learning algorithms. Games are often used to benchmark reinforcement learning algorithms as they provide a flexible, reproducible, and easy to control environment. Regardless, few games feature a state-space where results in exploration, memory, and planning are easily perceived. This paper presents The Dreaming Variational Autoencoder (DVAE), a neural network based generative modeling architecture for exploration in environments with sparse feedback. We further present Deep Maze, a novel and flexible maze engine that challenges DVAE in partial and fully-observable state-spaces, long-horizon tasks, and deterministic and stochastic problems. We show initial findings and encourage further work in reinforcement learning driven by generative exploration.

15 Sep 2025
Objective: Lung cancer is a leading cause of cancer-related mortality worldwide, primarily due to delayed diagnosis and poor early detection. This study aims to develop a computer-aided diagnosis (CAD) system that leverages large vision-language models (VLMs) for the accurate detection and classification of pulmonary nodules in computed tomography (CT) scans.
Methods: We propose an end-to-end CAD pipeline consisting of two modules: (i) a detection module (CADe) based on the Segment Anything Model 2 (SAM2), in which the standard visual prompt is replaced with a text prompt encoded by CLIP (Contrastive Language-Image Pretraining), and (ii) a diagnosis module (CADx) that calculates similarity scores between segmented nodules and radiomic features. To add clinical context, synthetic electronic medical records (EMRs) were generated using radiomic assessments by expert radiologists and combined with similarity scores for final classification. The method was tested on the publicly available LIDC-IDRI dataset (1,018 CT scans).
Results: The proposed approach demonstrated strong performance in zero-shot lung nodule analysis. The CADe module achieved a Dice score of 0.92 and an IoU of 0.85 for nodule segmentation. The CADx module attained a specificity of 0.97 for malignancy classification, surpassing existing fully supervised methods.
Conclusions: The integration of VLMs with radiomics and synthetic EMRs allows for accurate and clinically relevant CAD of pulmonary nodules in CT scans. The proposed system shows strong potential to enhance early lung cancer detection, increase diagnostic confidence, and improve patient management in routine clinical workflows.

02 Oct 2024
Hate speech has grown into a pervasive phenomenon, intensifying during times of crisis, elections, and social unrest. Multiple approaches have been developed to detect hate speech using artificial intelligence, but a generalized model is yet unaccomplished. The challenge for hate speech detection as text classification is the cost of obtaining high-quality training data. This study focuses on detecting bilingual hate speech in YouTube comments and measuring the impact of using additional data from other platforms in the performance of the classification model. We examine the value of additional training datasets from cross-platforms for improving the performance of classification models. We also included factors such as content similarity, definition similarity, and common hate words to measure the impact of datasets on performance. Our findings show that adding more similar datasets based on content similarity, hate words, and definitions improves the performance of classification models. The best performance was obtained by combining datasets from YouTube comments, Twitter, and Gab with an F1-score of 0.74 and 0.68 for English and German YouTube comments.

22 May 2024
The expanding research on manifold-based self-supervised learning (SSL)
builds on the manifold hypothesis, which suggests that the inherent complexity
of high-dimensional data can be unraveled through lower-dimensional manifold
embeddings. Capitalizing on this, DeepInfomax with an unbalanced atlas (DIM-UA)
has emerged as a powerful tool and yielded impressive results for state
representations in reinforcement learning. Meanwhile, Maximum Manifold Capacity
Representation (MMCR) presents a new frontier for SSL by optimizing class
separability via manifold compression. However, MMCR demands extensive input
views, resulting in significant computational costs and protracted pre-training
durations. Bridging this gap, we present an innovative integration of MMCR into
existing SSL methods, incorporating a discerning regularization strategy that
enhances the lower bound of mutual information. We also propose a novel state
representation learning method extending DIM-UA, embedding a nuclear norm loss
to enforce manifold consistency robustly. On experimentation with the Atari
Annotated RAM Interface, our method improves DIM-UA significantly with the same
number of target encoding dimensions. The mean F1 score averaged over
categories is 78% compared to 75% of DIM-UA. There are also compelling gains
when implementing SimCLR and Barlow Twins. This supports our SSL innovation as
a paradigm shift, enabling more nuanced high-dimensional data representations.

27 Dec 2019
Convolutional neural networks (CNNs) have obtained astounding successes for important pattern recognition tasks, but they suffer from high computational complexity and the lack of interpretability. The recent Tsetlin Machine (TM) attempts to address this lack by using easy-to-interpret conjunctive clauses in propositional logic to solve complex pattern recognition problems. The TM provides competitive accuracy in several benchmarks, while keeping the important property of interpretability. It further facilitates hardware-near implementation since inputs, patterns, and outputs are expressed as bits, while recognition and learning rely on straightforward bit manipulation. In this paper, we exploit the TM paradigm by introducing the Convolutional Tsetlin Machine (CTM), as an interpretable alternative to CNNs. Whereas the TM categorizes an image by employing each clause once to the whole image, the CTM uses each clause as a convolution filter. That is, a clause is evaluated multiple times, once per image patch taking part in the convolution. To make the clauses location-aware, each patch is further augmented with its coordinates within the image. The output of a convolution clause is obtained simply by ORing the outcome of evaluating the clause on each patch. In the learning phase of the TM, clauses that evaluate to 1 are contrasted against the input. For the CTM, we instead contrast against one of the patches, randomly selected among the patches that made the clause evaluate to 1. Accordingly, the standard Type I and Type II feedback of the classic TM can be employed directly, without further modification. The CTM obtains a peak test accuracy of 99.4% on MNIST, 96.31% on Kuzushiji-MNIST, 91.5% on Fashion-MNIST, and 100.0% on the 2D Noisy XOR Problem, which is competitive with results reported for simple 4-layer CNNs, BinaryConnect, Logistic Circuits and an FPGA-accelerated Binary CNN.

03 Oct 2024

In this proof-of-concept study, we conduct multivariate timeseries forecasting for the concentrations of nitrogen dioxide (NO2), ozone (O3), and (fine) particulate matter (PM10 & PM2.5) with meteorological covariates between two locations using various deep learning models, with a focus on long short-term memory (LSTM) and gated recurrent unit (GRU) architectures. In particular, we propose an integrated, hierarchical model architecture inspired by air pollution dynamics and atmospheric science that employs multi-task learning and is benchmarked by unidirectional and fully-connected models. Results demonstrate that, above all, the hierarchical GRU proves itself as a competitive and efficient method for forecasting the concentration of smog-related pollutants.

21 Jun 2019
The recently introduced Tsetlin Machine (TM) has provided competitive pattern classification accuracy in several benchmarks, composing patterns with easy-to-interpret conjunctive clauses in propositional logic. In this paper, we go beyond pattern classification by introducing a new type of TMs, namely, the Regression Tsetlin Machine (RTM). In all brevity, we modify the inner inference mechanism of the TM so that input patterns are transformed into a single continuous output, rather than to distinct categories. We achieve this by: (1) using the conjunctive clauses of the TM to capture arbitrarily complex patterns; (2) mapping these patterns to a continuous output through a novel voting and normalization mechanism; and (3) employing a feedback scheme that updates the TM clauses to minimize the regression error. The feedback scheme uses a new activation probability function that stabilizes the updating of clauses, while the overall system converges towards an accurate input-output mapping. The performance of the RTM is evaluated using six different artificial datasets with and without noise, in comparison with the Classic Tsetlin Machine (CTM) and the Multiclass Tsetlin Machine (MTM). Our empirical results indicate that the RTM obtains the best training and testing results for both noisy and noise-free datasets, with a smaller number of clauses. This, in turn, translates to higher regression accuracy, using significantly less computational resources.
There are no more papers matching your filters at the moment.
