
03 Dec 2025



A comprehensive survey evaluates geometric, neural (NeRF, 3DGS), and foundation models as 3D scene representations for robotics, assessing their performance across perception, mapping, localization, manipulation, and navigation modules. The analysis outlines the strengths and limitations of each representation type and points to 3D Foundation Models as a promising future direction for unified robotic intelligence.

19 Feb 2025
 University of Toronto
University of Toronto Google DeepMind
Google DeepMind University of WaterlooCharles University
University of WaterlooCharles University Harvard University
Harvard University Anthropic
Anthropic Carnegie Mellon University
Carnegie Mellon University Université de Montréal
Université de Montréal University College London
University College London University of OxfordUniversity of Bonn
University of OxfordUniversity of Bonn Stanford University
Stanford University University of Michigan
University of Michigan Meta
Meta Johns Hopkins UniversitySingapore University of Technology and Design
Johns Hopkins UniversitySingapore University of Technology and Design University of St AndrewsÉcole Polytechnique Fédérale de LausanneMax Planck Institute for Human DevelopmentCzech Technical UniversityTeesside UniversityCentre for the Governance of AIApollo ResearchFAR AIApart ResearchCenter on Long-Term RiskUniversity of StirlingCooperative AI FoundationPRISM AI
University of St AndrewsÉcole Polytechnique Fédérale de LausanneMax Planck Institute for Human DevelopmentCzech Technical UniversityTeesside UniversityCentre for the Governance of AIApollo ResearchFAR AIApart ResearchCenter on Long-Term RiskUniversity of StirlingCooperative AI FoundationPRISM AI

A landmark collaborative study from 44 researchers across 30 major institutions establishes the first comprehensive framework for understanding multi-agent AI risks, identifying three critical failure modes and seven key risk factors while providing concrete evidence from both historical examples and novel experiments to guide future safety efforts.

01 Dec 2025
Register Any Point (RAP) presents a scalable, single-stage framework for multi-view 3D point cloud registration by reframing the task as conditional flow matching with explicit rigidity enforcement. The model achieves state-of-the-art performance, demonstrating superior robustness in low-overlap scenarios and strong zero-shot generalization across 17 diverse datasets, including previously unseen outdoor LiDAR and Terrestrial Laser Scanner data.

10 Nov 2025

Mercedes-Benz AG and University of Tübingen researchers developed AGO, a framework for adaptive grounding in open-world 3D occupancy prediction, enabling recognition of both known and novel objects from multi-camera inputs. The model achieved a state-of-the-art 19.23 mIoU on the Occ3D-nuScenes benchmark, showing robust generalization to unknown categories and outperforming previous methods by 4.09 mIoU.

11 Sep 2021
Rensselaer Polytechnic InstituteUniversity of Bonn University of SouthamptonUniversität Stuttgart
University of SouthamptonUniversität Stuttgart Rutgers UniversitySapienza University of RomeUniversidad de ChileLinköping UniversityVrije UniversiteitUniversidad de OviedoUniversity of BariUniversität PaderbornWU ViennaUniversität Koblenz–Landaudata.worldÉcole des mines de Saint-ÉtienneUniversity of Milano
Bicocca
Rutgers UniversitySapienza University of RomeUniversidad de ChileLinköping UniversityVrije UniversiteitUniversidad de OviedoUniversity of BariUniversität PaderbornWU ViennaUniversität Koblenz–Landaudata.worldÉcole des mines de Saint-ÉtienneUniversity of Milano
Bicocca
University of SouthamptonUniversität StuttgartRutgers UniversitySapienza University of RomeUniversidad de ChileLinköping UniversityVrije UniversiteitUniversidad de OviedoUniversity of BariUniversität PaderbornWU ViennaUniversität Koblenz–Landaudata.worldÉcole des mines de Saint-ÉtienneUniversity of Milano
BicoccaThis collaborative tutorial from 18 leading researchers provides a comprehensive, unifying summary of knowledge graphs, consolidating fragmented knowledge from diverse fields. It defines core concepts, surveys techniques across data models, knowledge representation, and AI, and outlines lifecycle management and governance for knowledge graphs.

13 Oct 2025

The NAVIS model, developed at Ben-Gurion University of the Negev and the University of Bonn, resolves the issue where simple heuristics often surpass sophisticated Temporal Graph Neural Networks in node affinity prediction. It consistently outperforms state-of-the-art TGNNs and heuristics across various temporal graph datasets, including notable improvements such as +12.8% in NDCG@10 over TGNv2 on the `tgbn-trade` dataset.

19 Sep 2025



In real-world scenarios, achieving domain adaptation and generalization poses significant challenges, as models must adapt to or generalize across unknown target distributions. Extending these capabilities to unseen multimodal distributions, i.e., multimodal domain adaptation and generalization, is even more challenging due to the distinct characteristics of different modalities. Significant progress has been made over the years, with applications ranging from action recognition to semantic segmentation. Besides, the recent advent of large-scale pre-trained multimodal foundation models, such as CLIP, has inspired works leveraging these models to enhance adaptation and generalization performances or adapting them to downstream tasks. This survey provides the first comprehensive review of recent advances from traditional approaches to foundation models, covering: (1) Multimodal domain adaptation; (2) Multimodal test-time adaptation; (3) Multimodal domain generalization; (4) Domain adaptation and generalization with the help of multimodal foundation models; and (5) Adaptation of multimodal foundation models. For each topic, we formally define the problem and thoroughly review existing methods. Additionally, we analyze relevant datasets and applications, highlighting open challenges and potential future research directions. We maintain an active repository that contains up-to-date literature at this https URL.

22 Nov 2025

EgoControl introduces a method for generating future egocentric video frames, utilizing 3D full-body pose sequences as explicit control. The model significantly improves visual fidelity, achieving an FVD of 20.18, and demonstrates enhanced accuracy in reproducing articulated body movements with a mean Intersection-over-Union (mIoU) of 52.13 for arm masks.
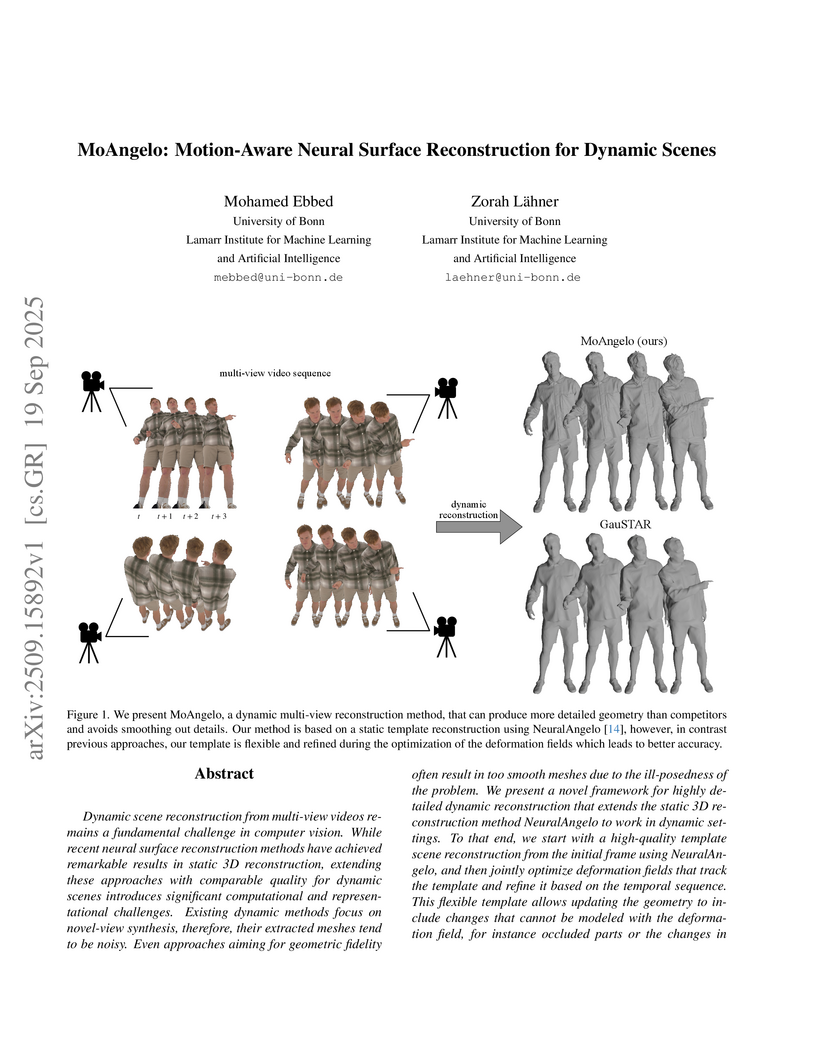
19 Sep 2025
Dynamic scene reconstruction from multi-view videos remains a fundamental challenge in computer vision. While recent neural surface reconstruction methods have achieved remarkable results in static 3D reconstruction, extending these approaches with comparable quality for dynamic scenes introduces significant computational and representational challenges. Existing dynamic methods focus on novel-view synthesis, therefore, their extracted meshes tend to be noisy. Even approaches aiming for geometric fidelity often result in too smooth meshes due to the ill-posedness of the problem. We present a novel framework for highly detailed dynamic reconstruction that extends the static 3D reconstruction method NeuralAngelo to work in dynamic settings. To that end, we start with a high-quality template scene reconstruction from the initial frame using NeuralAngelo, and then jointly optimize deformation fields that track the template and refine it based on the temporal sequence. This flexible template allows updating the geometry to include changes that cannot be modeled with the deformation field, for instance occluded parts or the changes in the topology. We show superior reconstruction accuracy in comparison to previous state-of-the-art methods on the ActorsHQ dataset.

14 Dec 2023
The paper introduces the Grounding Everything Module (GEM), a training-free method that leverages inherent localization capabilities within pre-trained Vision-Language Models for zero-shot open-vocabulary object localization and semantic segmentation. GEM achieves state-of-the-art results among training-free approaches and is competitive with many fine-tuned methods across multiple datasets, including PascalVOC, PascalContext, ADE20K, and OpenImagesV7.

08 Apr 2025
Robotics applications often rely on scene reconstructions to enable
downstream tasks. In this work, we tackle the challenge of actively building an
accurate map of an unknown scene using an RGB-D camera on a mobile platform. We
propose a hybrid map representation that combines a Gaussian splatting map with
a coarse voxel map, leveraging the strengths of both representations: the
high-fidelity scene reconstruction capabilities of Gaussian splatting and the
spatial modelling strengths of the voxel map. At the core of our framework is
an effective confidence modelling technique for the Gaussian splatting map to
identify under-reconstructed areas, while utilising spatial information from
the voxel map to target unexplored areas and assist in collision-free path
planning. By actively collecting scene information in under-reconstructed and
unexplored areas for map updates, our approach achieves superior Gaussian
splatting reconstruction results compared to state-of-the-art approaches.
Additionally, we demonstrate the real-world applicability of our framework
using an unmanned aerial vehicle.

25 Jul 2025

Robust and accurate proprioceptive state estimation of the main body is crucial for legged robots to execute tasks in extreme environments where exteroceptive sensors, such as LiDARs and cameras, may become unreliable. In this paper, we propose DogLegs, a state estimation system for legged robots that fuses the measurements from a body-mounted inertial measurement unit (Body-IMU), joint encoders, and multiple leg-mounted IMUs (Leg-IMU) using an extended Kalman filter (EKF). The filter system contains the error states of all IMU frames. The Leg-IMUs are used to detect foot contact, thereby providing zero-velocity measurements to update the state of the Leg-IMU frames. Additionally, we compute the relative position constraints between the Body-IMU and Leg-IMUs by the leg kinematics and use them to update the main body state and reduce the error drift of the individual IMU frames. Field experimental results have shown that our proposed DogLegs system achieves better state estimation accuracy compared to the traditional leg odometry method (using only Body-IMU and joint encoders) across various terrains. We make our datasets publicly available to benefit the research community (this https URL).

05 Sep 2025



Monocular 3D object detection is valuable for various applications such as robotics and AR/VR. Existing methods are confined to closed-set settings, where the training and testing sets consist of the same scenes and/or object categories. However, real-world applications often introduce new environments and novel object categories, posing a challenge to these methods. In this paper, we address monocular 3D object detection in an open-set setting and introduce the first end-to-end 3D Monocular Open-set Object Detector (3D-MOOD). We propose to lift the open-set 2D detection into 3D space through our designed 3D bounding box head, enabling end-to-end joint training for both 2D and 3D tasks to yield better overall performance. We condition the object queries with geometry prior and overcome the generalization for 3D estimation across diverse scenes. To further improve performance, we design the canonical image space for more efficient cross-dataset training. We evaluate 3D-MOOD on both closed-set settings (Omni3D) and open-set settings (Omni3D to Argoverse 2, ScanNet), and achieve new state-of-the-art results. Code and models are available at this http URL.

05 May 2025
The paper introduces VELM, a two-stage pipeline that combines a fast vision-based anomaly detector with multi-modal large language models (MLLMs) to classify industrial anomalies into specific types. VELM achieved 81.4% accuracy on the MVTec-AD dataset, surpassing previous methods, and enabled nuanced distinction between critical defects and negligible anomalies, showing 89.8% accuracy in a simulated scenario. The work also provides new, refined benchmarks, MVTec-AC and VisA-AC, for multi-class anomaly classification.

26 Nov 2025
SAVi-DNO enables pre-trained diffusion models for video prediction to continuously adapt to live video streams by optimizing diffusion noise during inference. This method improves prediction accuracy and video quality across diverse datasets and diffusion models, offering an efficient and privacy-preserving solution for real-world continuous adaptation.

03 Apr 2025
STING-BEE is a vision-language model designed for real-world X-ray baggage security inspection, trained on STCray, the first multimodal X-ray dataset featuring detailed image-caption pairs and diverse threat concealment scenarios. The model achieves state-of-the-art performance across scene comprehension, visual question answering, and threat localization, demonstrating robust cross-domain generalization to varied X-ray scanners and complex, unseen threats.

04 Dec 2025

The "Hoi!" dataset provides synchronized multimodal data, including RGB-D, force, and tactile feedback, for human and robotic manipulation of articulated objects across various viewpoints and real-world environments. This resource reveals limitations of current state-of-the-art methods in articulation, tactile, and visual force estimation, facilitating research into robust embodied AI.

09 Sep 2025
Robots benefit from high-fidelity reconstructions of their environment, which should be geometrically accurate and photorealistic to support downstream tasks. While this can be achieved by building distance fields from range sensors and radiance fields from cameras, realising scalable incremental mapping of both fields consistently and at the same time with high quality is challenging. In this paper, we propose a novel map representation that unifies a continuous signed distance field and a Gaussian splatting radiance field within an elastic and compact point-based implicit neural map. By enforcing geometric consistency between these fields, we achieve mutual improvements by exploiting both modalities. We present a novel LiDAR-visual SLAM system called PINGS using the proposed map representation and evaluate it on several challenging large-scale datasets. Experimental results demonstrate that PINGS can incrementally build globally consistent distance and radiance fields encoded with a compact set of neural points. Compared to state-of-the-art methods, PINGS achieves superior photometric and geometric rendering at novel views by constraining the radiance field with the distance field. Furthermore, by utilizing dense photometric cues and multi-view consistency from the radiance field, PINGS produces more accurate distance fields, leading to improved odometry estimation and mesh reconstruction. We also provide an open-source implementation of PING at: this https URL.

07 Feb 2025
Researchers at the University of Bonn developed SOLD, the first object-centric model-based reinforcement learning algorithm that learns complex manipulation skills directly from raw pixel data. This approach integrates Slot Attention for structured scene representation with a Dreamer-like control framework, leading to superior performance, enhanced sample efficiency, and interpretable dynamics on relational manipulation tasks.

01 Jun 2023

Researchers from Google Research and Technical University of Dortmund introduce Deep Modularity Networks (DMoN), an unsupervised Graph Neural Network method for graph clustering. DMoN consistently outperforms existing GNN-based clustering and pooling methods, achieving over 40% average improvement in conductance, modularity, and NMI across various real-world datasets, while also scaling effectively to large graphs.
There are no more papers matching your filters at the moment.
