
25 Feb 2024
We demonstrate and characterize a first-principles approach to modeling the mass action dynamics of metabolism. Starting from a basic definition of entropy expressed as a multinomial probability density using Boltzmann probabilities with standard chemical potentials, we derive and compare the free energy dissipation and the entropy production rates. We express the relation between the entropy production and the chemical master equation for modeling metabolism, which unifies chemical kinetics and chemical thermodynamics. Subsequent implementation of an maximum free energy dissipation model for systems of coupled reactions is accomplished by using an approximation to the Marcelin equation for mass action kinetics that maximizes the entropy production. Because prediction uncertainty with respect to parameter variability is frequently a concern with mass action models utilizing rate constants, we compare and contrast the maximum entropy production model, which has its own set of rate parameters, to a population of standard mass action models in which the rate constants are randomly chosen. We show that a maximum entropy production model is characterized by a high probability of free energy dissipation rate, and likewise entropy production rate, relative to other models. We then characterize the variability of the maximum entropy production predictions with respect to uncertainties in parameters (standard free energies of formation) and with respect to ionic strengths typically found in a cell.

08 Jul 2025


Materials with high thermal conductivity are needed to conduct heat away from hot spots in high power electronics and optoelectronic devices. Cubic boron arsenide (c-BAs) has a high thermal conductivity due to its special phonon dispersion relation. Previous experimental studies of c-BAs report a room-temperature thermal conductivity between 1000 and 1300 W m-1 K-1. We synthesized high purity isotopically enriched c-BAs single crystals with room-temperature thermal conductivity of around 1500 W m-1 K-1. Using time-domain thermoreflectance (TDTR), we measured thermal conductivity and found a 1/T2 temperature dependence between 300 K and 600 K - slightly stronger than predictions from state-of-the-art theoretical models. Brillouin and Raman scattering revealed minimal changes in phonon frequencies over the same temperature range, suggesting that the observed 1/T2 dependence is not caused by temperature dependent changes in phonon dispersion. To probe defect densities in the BAs crystals we studied, we conducted transient reflectivity microscopy (TRM) measurements of absorption at sub-bandgap photon energies. We observe a correlation between TRM signal intensity and thermal conductivity. Notably, samples with thermal conductivity near 1500 W m-1 K-1 still exhibited nonzero TRM signals, suggesting the presence of defects despite the high thermal conductivity.
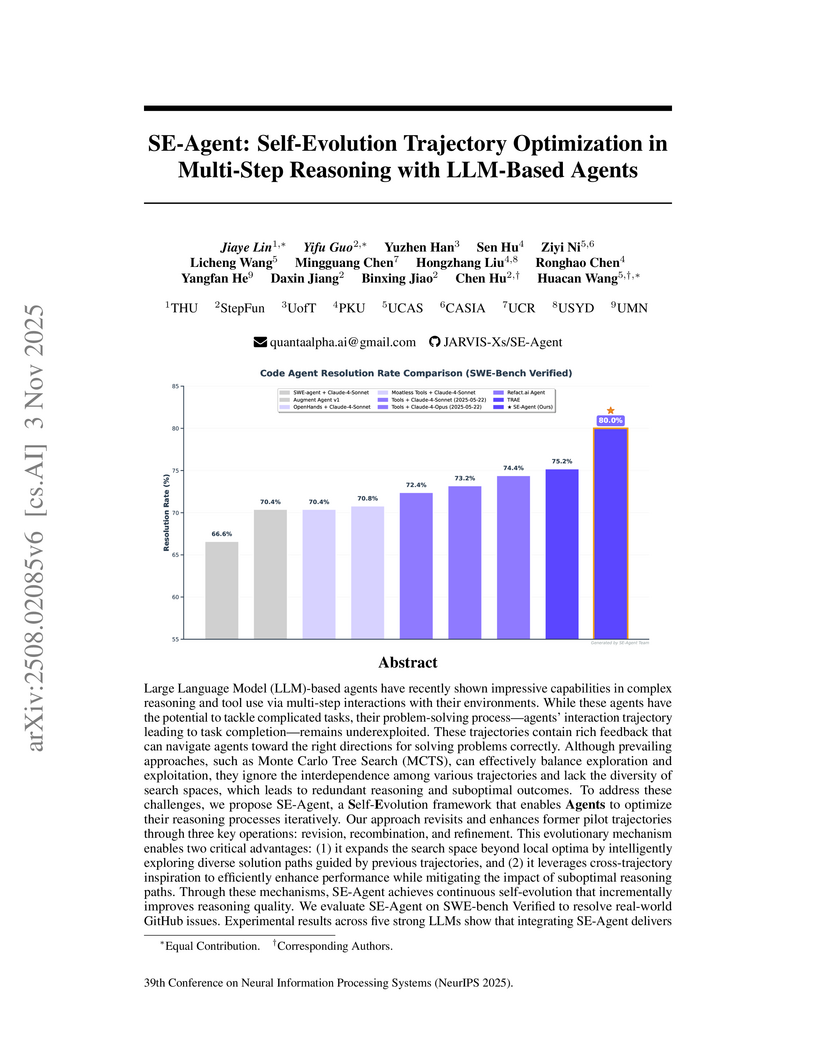
03 Nov 2025




A collaborative effort introduces SE-Agent, a self-evolutionary framework for LLM-based agents that optimizes multi-step reasoning trajectories via iterative revision, recombination, and refinement. This approach achieved state-of-the-art performance on SWE-bench Verified, improving Pass@1 by up to 112% for Llama-3.1-70b-Instruct and reaching 61.2% with Claude-3.7-Sonnet.

02 Oct 2025
Computer-Use Agents (CUAs) are an increasingly deployed class of agents that take actions on GUIs to accomplish user goals. In this paper, we show that CUAs consistently exhibit Blind Goal-Directedness (BGD): a bias to pursue goals regardless of feasibility, safety, reliability, or context. We characterize three prevalent patterns of BGD: (i) lack of contextual reasoning, (ii) assumptions and decisions under ambiguity, and (iii) contradictory or infeasible goals. We develop BLIND-ACT, a benchmark of 90 tasks capturing these three patterns. Built on OSWorld, BLIND-ACT provides realistic environments and employs LLM-based judges to evaluate agent behavior, achieving 93.75% agreement with human annotations. We use BLIND-ACT to evaluate nine frontier models, including Claude Sonnet and Opus 4, Computer-Use-Preview, and GPT-5, observing high average BGD rates (80.8%) across them. We show that BGD exposes subtle risks that arise even when inputs are not directly harmful. While prompting-based interventions lower BGD levels, substantial risk persists, highlighting the need for stronger training- or inference-time interventions. Qualitative analysis reveals observed failure modes: execution-first bias (focusing on how to act over whether to act), thought-action disconnect (execution diverging from reasoning), and request-primacy (justifying actions due to user request). Identifying BGD and introducing BLIND-ACT establishes a foundation for future research on studying and mitigating this fundamental risk and ensuring safe CUA deployment.

16 Sep 2024

This comprehensive survey by Han et al. (2024) systematically reviews Parameter-Efficient Fine-Tuning (PEFT) methods for large models, classifying algorithms into four types and detailing their application across various deep neural networks including LLMs, ViTs, and Diffusion models. It also addresses crucial system-level challenges and solutions for deploying and training PEFT-enabled models.

22 Aug 2023
 CNRS
CNRS New York University
New York University Tel Aviv University
Tel Aviv University University College London
University College London University of California, Irvine
University of California, Irvine Mila - Quebec AI InstituteThe Australian National UniversityLondon School of Economics and Political ScienceUniversity of MontrealUniversity of LondonUniversity of California RiversideThe University of SussexCenter for AI SafetyAraya, Inc.Future of Humanity Institute, University of OxfordUniversit
e de Toulouse
Mila - Quebec AI InstituteThe Australian National UniversityLondon School of Economics and Political ScienceUniversity of MontrealUniversity of LondonUniversity of California RiversideThe University of SussexCenter for AI SafetyAraya, Inc.Future of Humanity Institute, University of OxfordUniversit
e de ToulouseA collaborative report by 20 interdisciplinary researchers presents a principled, scientifically grounded methodology for assessing consciousness in AI systems. The authors propose a rubric of 13 computationally specified indicator properties derived from neuroscientific theories of consciousness, finding that while no current AI systems are conscious, no obvious technical barriers prevent building systems that satisfy these indicators in the near future using existing machine learning techniques.

14 Aug 2025


We introduce UniOcc, a comprehensive, unified benchmark and toolkit for occupancy forecasting (i.e., predicting future occupancies based on historical information) and occupancy prediction (i.e., predicting current-frame occupancy from camera images. UniOcc unifies the data from multiple real-world datasets (i.e., nuScenes, Waymo) and high-fidelity driving simulators (i.e., CARLA, OpenCOOD), providing 2D/3D occupancy labels and annotating innovative per-voxel flows. Unlike existing studies that rely on suboptimal pseudo labels for evaluation, UniOcc incorporates novel evaluation metrics that do not depend on ground-truth labels, enabling robust assessment on additional aspects of occupancy quality. Through extensive experiments on state-of-the-art models, we demonstrate that large-scale, diverse training data and explicit flow information significantly enhance occupancy prediction and forecasting performance. Our data and code are available at this https URL.

13 May 2025
University of Utah University of Notre Dame
University of Notre Dame UC Berkeley
UC Berkeley Stanford University
Stanford University University of Michigan
University of Michigan Texas A&M University
Texas A&M University NVIDIA
NVIDIA University of Texas at Austin
University of Texas at Austin Columbia UniversityLehigh University
Columbia UniversityLehigh University University of Florida
University of Florida Johns Hopkins University
Johns Hopkins University Arizona State University
Arizona State University University of Wisconsin-Madison
University of Wisconsin-Madison Purdue UniversityUniversity of California, MercedTechnische Universität MünchenBosch Research North AmericaBosch Center for Artificial Intelligence (BCAI)University of California Riverside
Purdue UniversityUniversity of California, MercedTechnische Universität MünchenBosch Research North AmericaBosch Center for Artificial Intelligence (BCAI)University of California Riverside AdobeCleveland State UniversityTexas A&M Transportation Institute
AdobeCleveland State UniversityTexas A&M Transportation Institute
University of Notre DameUC BerkeleyStanford UniversityUniversity of MichiganTexas A&M UniversityNVIDIAUniversity of Texas at AustinColumbia UniversityLehigh UniversityUniversity of FloridaJohns Hopkins UniversityArizona State UniversityUniversity of Wisconsin-MadisonPurdue UniversityUniversity of California, MercedTechnische Universität MünchenBosch Research North AmericaBosch Center for Artificial Intelligence (BCAI)University of California RiversideAdobeCleveland State UniversityTexas A&M Transportation InstituteA comprehensive survey examines how generative AI technologies (GANs, VAEs, Diffusion Models, LLMs) are being applied across the autonomous driving stack, mapping current applications while analyzing challenges in safety, evaluation, and deployment through a collaborative effort spanning 20+ institutions including Texas A&M, Stanford, and NVIDIA.

23 Oct 2025


HeadKV-R2 introduces a head-level KV cache compression method for large language models, dynamically allocating memory based on each attention head's contribution to retrieval and reasoning tasks. This approach achieves 97% of the full KV cache performance on contextual question answering benchmarks while retaining only 1.5% of the cache, significantly boosting efficiency in low-resource settings.

19 Nov 2024
Researchers introduce Selective Self-Attention (SSA), a mechanism that enhances Transformer performance by enabling principled contextual control over attention maps through adaptive inverse-temperature functions. SSA consistently improves accuracy across diverse language modeling benchmarks, accelerates training, and boosts information retrieval capabilities with a negligible increase in model parameters.

06 Aug 2025

In recent years, there has been increasing attention on the capabilities of large models, particularly in handling complex tasks that small-scale models are unable to perform. Notably, large language models (LLMs) have demonstrated ``intelligent'' abilities such as complex reasoning and abstract language comprehension, reflecting cognitive-like behaviors. However, current research on emergent abilities in large models predominantly focuses on the relationship between model performance and size, leaving a significant gap in the systematic quantitative analysis of the internal structures and mechanisms driving these emergent abilities. Drawing inspiration from neuroscience research on brain network structure and self-organization, we propose (i) a general network representation of large models, (ii) a new analytical framework, called Neuron-based Multifractal Analysis (NeuroMFA), for structural analysis, and (iii) a novel structure-based metric as a proxy for emergent abilities of large models. By linking structural features to the capabilities of large models, NeuroMFA provides a quantitative framework for analyzing emergent phenomena in large models. Our experiments show that the proposed method yields a comprehensive measure of network's evolving heterogeneity and organization, offering theoretical foundations and a new perspective for investigating emergent abilities in large models.

07 Aug 2025
Mobile robots navigating in crowds trained using reinforcement learning are known to suffer performance degradation when faced with out-of-distribution scenarios. We propose that by properly accounting for the uncertainties of pedestrians, a robot can learn safe navigation policies that are robust to distribution shifts. Our method augments agent observations with prediction uncertainty estimates generated by adaptive conformal inference, and it uses these estimates to guide the agent's behavior through constrained reinforcement learning. The system helps regulate the agent's actions and enables it to adapt to distribution shifts. In the in-distribution setting, our approach achieves a 96.93% success rate, which is over 8.80% higher than the previous state-of-the-art baselines with over 3.72 times fewer collisions and 2.43 times fewer intrusions into ground-truth human future trajectories. In three out-of-distribution scenarios, our method shows much stronger robustness when facing distribution shifts in velocity variations, policy changes, and transitions from individual to group dynamics. We deploy our method on a real robot, and experiments show that the robot makes safe and robust decisions when interacting with both sparse and dense crowds. Our code and videos are available on this https URL.

09 Jun 2025

Nowadays, regulatory compliance has become a cornerstone of corporate
governance, ensuring adherence to systematic legal frameworks. At its core,
financial regulations often comprise highly intricate provisions, layered
logical structures, and numerous exceptions, which inevitably result in
labor-intensive or comprehension challenges. To mitigate this, recent
Regulatory Technology (RegTech) and Large Language Models (LLMs) have gained
significant attention in automating the conversion of regulatory text into
executable compliance logic. However, their performance remains suboptimal
particularly when applied to Chinese-language financial regulations, due to
three key limitations: (1) incomplete domain-specific knowledge representation,
(2) insufficient hierarchical reasoning capabilities, and (3) failure to
maintain temporal and logical coherence. One promising solution is to develop a
domain specific and code-oriented datasets for model training. Existing
datasets such as LexGLUE, LegalBench, and CODE-ACCORD are often
English-focused, domain-mismatched, or lack fine-grained granularity for
compliance code generation. To fill these gaps, we present Compliance-to-Code,
the first large-scale Chinese dataset dedicated to financial regulatory
compliance. Covering 1,159 annotated clauses from 361 regulations across ten
categories, each clause is modularly structured with four logical
elements-subject, condition, constraint, and contextual information-along with
regulation relations. We provide deterministic Python code mappings, detailed
code reasoning, and code explanations to facilitate automated auditing. To
demonstrate utility, we present FinCheck: a pipeline for regulation
structuring, code generation, and report generation.

03 Jun 2025
BEVCALIB introduces a target-less LiDAR-camera calibration method that leverages geometry-guided Bird's-Eye View (BEV) representations from raw sensor data. The method achieves an average translation error of 2.4 cm and rotation error of 0.08 degrees on KITTI, outperforming previous baselines and providing a robust open-source solution for autonomous systems.

13 Mar 2025
LaMMA-P introduces a framework that integrates large language models with PDDL planning for generalizable multi-agent long-horizon task allocation and execution with heterogeneous robot teams. It achieves a 105% higher average success rate and 36% higher average efficiency compared to prior state-of-the-art methods on a new multi-agent benchmark.

16 Oct 2025

Researchers developed RDD, a retrieval-based method to automatically decompose long-horizon robotic task demonstrations into sub-tasks that align with the training data of low-level visuomotor policies. This approach consistently achieves near-expert performance on various RLBench manipulation tasks, outperforming heuristic decomposers while demonstrating high data efficiency and robust real-world application.

01 Dec 2025

The Kolmogorov-Arnold (KA) representation theorem constructs universal, but highly non-smooth inner functions (the first layer map) in a single (non-linear) hidden layer neural network. Such universal functions have a distinctive local geometry, a "texture," which can be characterized by the inner function's Jacobian , as varies over the data. It is natural to ask if this distinctive KA geometry emerges through conventional neural network optimization. We find that indeed KA geometry often is produced when training vanilla single hidden layer neural networks. We quantify KA geometry through the statistical properties of the exterior powers of : number of zero rows and various observables for the minor statistics of , which measure the scale and axis alignment of . This leads to a rough understanding for where KA geometry occurs in the space of function complexity and model hyperparameters. The motivation is first to understand how neural networks organically learn to prepare input data for later downstream processing and, second, to learn enough about the emergence of KA geometry to accelerate learning through a timely intervention in network hyperparameters. This research is the "flip side" of KA-Networks (KANs). We do not engineer KA into the neural network, but rather watch KA emerge in shallow MLPs.

08 Oct 2025
Out-of-distribution (OOD) detection is critical for the safe deployment of machine learning systems in safety-sensitive domains. Diffusion models have recently emerged as powerful generative models, capable of capturing complex data distributions through iterative denoising. Building on this progress, recent work has explored their potential for OOD detection. We propose EigenScore, a new OOD detection method that leverages the eigenvalue spectrum of the posterior covariance induced by a diffusion model. We argue that posterior covariance provides a consistent signal of distribution shift, leading to larger trace and leading eigenvalues on OOD inputs, yielding a clear spectral signature. We further provide analysis explicitly linking posterior covariance to distribution mismatch, establishing it as a reliable signal for OOD detection. To ensure tractability, we adopt a Jacobian-free subspace iteration method to estimate the leading eigenvalues using only forward evaluations of the denoiser. Empirically, EigenScore achieves SOTA performance, with up to 5% AUROC improvement over the best baseline. Notably, it remains robust in near-OOD settings such as CIFAR-10 vs CIFAR-100, where existing diffusion-based methods often fail.

18 May 2024
Denoising diffusion models enable conditional generation and density modeling of complex relationships like images and text. However, the nature of the learned relationships is opaque making it difficult to understand precisely what relationships between words and parts of an image are captured, or to predict the effect of an intervention. We illuminate the fine-grained relationships learned by diffusion models by noticing a precise relationship between diffusion and information decomposition. Exact expressions for mutual information and conditional mutual information can be written in terms of the denoising model. Furthermore, pointwise estimates can be easily estimated as well, allowing us to ask questions about the relationships between specific images and captions. Decomposing information even further to understand which variables in a high-dimensional space carry information is a long-standing problem. For diffusion models, we show that a natural non-negative decomposition of mutual information emerges, allowing us to quantify informative relationships between words and pixels in an image. We exploit these new relations to measure the compositional understanding of diffusion models, to do unsupervised localization of objects in images, and to measure effects when selectively editing images through prompt interventions.

22 Feb 2024


Since its inception in "Attention Is All You Need", transformer architecture
has led to revolutionary advancements in NLP. The attention layer within the
transformer admits a sequence of input tokens and makes them interact
through pairwise similarities computed as softmax, where
are the trainable key-query parameters. In this work, we establish a
formal equivalence between the optimization geometry of self-attention and a
hard-margin SVM problem that separates optimal input tokens from non-optimal
tokens using linear constraints on the outer-products of token pairs. This
formalism allows us to characterize the implicit bias of 1-layer transformers
optimized with gradient descent: (1) Optimizing the attention layer with
vanishing regularization, parameterized by , converges in direction to
an SVM solution minimizing the nuclear norm of the combined parameter
. Instead, directly parameterizing by minimizes a Frobenius norm
objective. We characterize this convergence, highlighting that it can occur
toward locally-optimal directions rather than global ones. (2) Complementing
this, we prove the local/global directional convergence of gradient descent
under suitable geometric conditions. Importantly, we show that
over-parameterization catalyzes global convergence by ensuring the feasibility
of the SVM problem and by guaranteeing a benign optimization landscape devoid
of stationary points. (3) While our theory applies primarily to linear
prediction heads, we propose a more general SVM equivalence that predicts the
implicit bias with nonlinear heads. Our findings are applicable to arbitrary
datasets and their validity is verified via experiments. We also introduce
several open problems and research directions. We believe these findings
inspire the interpretation of transformers as a hierarchy of SVMs that
separates and selects optimal tokens.
There are no more papers matching your filters at the moment.
