17 Nov 2025
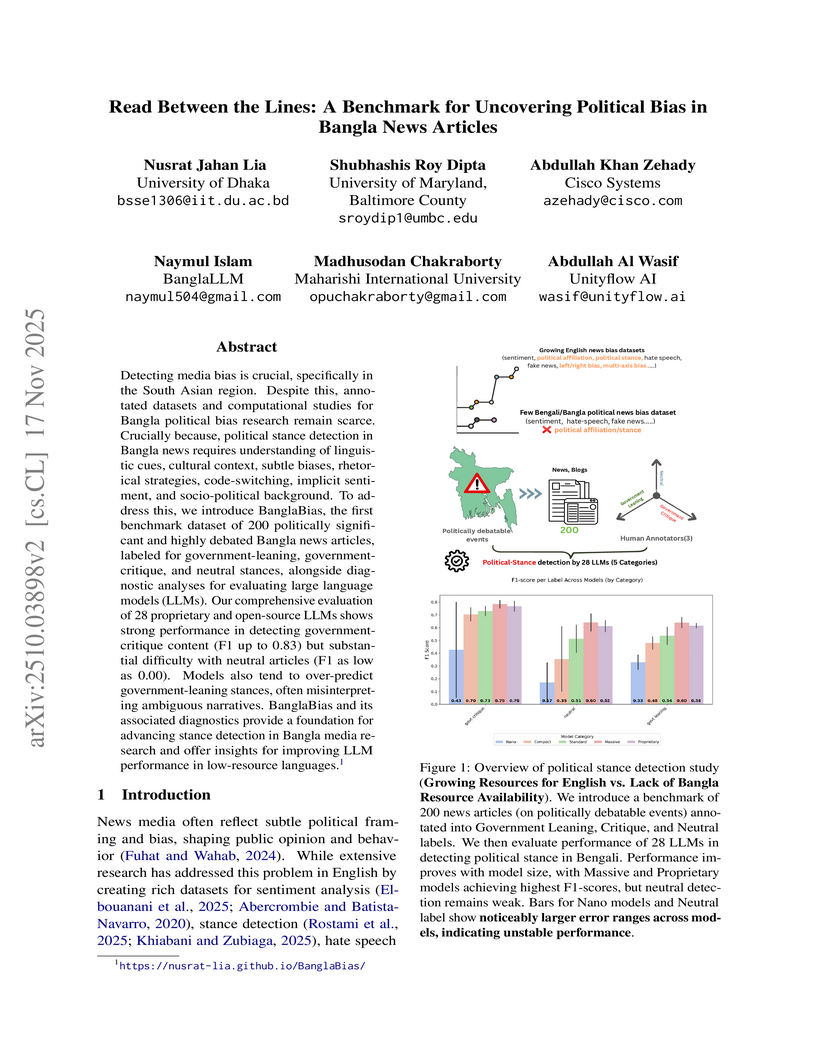
Researchers introduced BanglaBias, the first benchmark dataset for identifying political stances in Bangla news articles, comprising 200 meticulously annotated items. Their evaluation of 28 large language models revealed strong performance in detecting government critique (F1 scores up to 0.83) but consistent difficulty with neutral content and a tendency to over-predict government-leaning stances.

23 Nov 2025

Large language models (LLMs) and emerging agentic frameworks are beginning to transform single-cell biology by enabling natural-language reasoning, generative annotation, and multimodal data integration. However, progress remains fragmented across data modalities, architectures, and evaluation standards. LLM4Cell presents the first unified survey of 58 foundation and agentic models developed for single-cell research, spanning RNA, ATAC, multi-omic, and spatial modalities. We categorize these methods into five families-foundation, text-bridge, spatial, multimodal, epigenomic, and agentic-and map them to eight key analytical tasks including annotation, trajectory and perturbation modeling, and drug-response prediction. Drawing on over 40 public datasets, we analyze benchmark suitability, data diversity, and ethical or scalability constraints, and evaluate models across 10 domain dimensions covering biological grounding, multi-omics alignment, fairness, privacy, and explainability. By linking datasets, models, and evaluation domains, LLM4Cell provides the first integrated view of language-driven single-cell intelligence and outlines open challenges in interpretability, standardization, and trustworthy model development.

04 Oct 2025
Urban safety and infrastructure maintenance are critical components of smart city development. Manual monitoring of road damages is time-consuming, highly costly, and error-prone. This paper presents a deep learning approach for automated road damage and manhole detection using the YOLOv9 algorithm with polygonal annotations. Unlike traditional bounding box annotation, we employ polygonal annotations for more precise localization of road defects. We develop a novel dataset comprising more than one thousand images which are mostly collected from Dhaka, Bangladesh. This dataset is used to train a YOLO-based model for three classes, namely Broken, Not Broken, and Manhole. We achieve 78.1% overall image-level accuracy. The YOLOv9 model demonstrates strong performance for Broken (86.7% F1-score) and Not Broken (89.2% F1-score) classes, with challenges in Manhole detection (18.2% F1-score) due to class imbalance. Our approach offers an efficient and scalable solution for monitoring urban infrastructure in developing countries.

28 Aug 2025
PlantVillageVQA is a large-scale visual question answering (VQA) dataset derived from the widely used PlantVillage image corpus. It was designed to advance the development and evaluation of vision-language models for agricultural decision-making and analysis. The PlantVillageVQA dataset comprises 193,609 high-quality question-answer (QA) pairs grounded over 55,448 images spanning 14 crop species and 38 disease conditions. Questions are organised into 3 levels of cognitive complexity and 9 distinct categories. Each question category was phrased manually following expert guidance and generated via an automated two-stage pipeline: (1) template-based QA synthesis from image metadata and (2) multi-stage linguistic re-engineering. The dataset was iteratively reviewed by domain experts for scientific accuracy and relevancy. The final dataset was evaluated using three state-of-the-art models for quality assessment. Our objective remains to provide a publicly available, standardised and expert-verified database to enhance diagnostic accuracy for plant disease identifications and advance scientific research in the agricultural domain. Our dataset will be open-sourced at this https URL.

11 Nov 2025
Practitioners and researchers trying to strike a balance between accuracy and transparency center Explainable Artificial Intelligence (XAI) at the junction of finance. This paper offers a thorough overview of the changing scene of XAI applications in finance together with domain-specific implementations, methodological developments, and trend mapping of research. Using bibliometric and content analysis, we find topic clusters, significant research, and most often used explainability strategies used in financial industries. Our results show a substantial dependence on post-hoc interpretability techniques; attention mechanisms, feature importance analysis and SHAP are the most often used techniques among them. This review stresses the need of multidisciplinary approaches combining financial knowledge with improved explainability paradigms and exposes important shortcomings in present XAI systems.

17 Sep 2025


The Fermi-Hubbard model is a fundamental model in condensed matter physics that describes strongly correlated electrons. On the other hand, quantum computers are emerging as powerful tools for exploring the complex dynamics of these quantum many-body systems. In this work, we demonstrate the quantum simulation of the one-dimensional Fermi-Hubbard model using IBM's superconducting quantum computers, employing over 100 qubits. We introduce a first-order Trotterization scheme and extend it to an optimized second-order Trotterization for the time evolution in the Fermi-Hubbard model, specifically tailored for the limited qubit connectivity of quantum architectures, such as IBM's platforms. Notably, both Trotterization approaches are scalable and maintain a constant circuit depth at each Trotter step, regardless of the qubit count, enabling us to precisely investigate the relaxation dynamics in the Fermi-Hubbard model by measuring the expectation value of the Néel observable (staggered magnetization) for time-evolved quantum states. Finally, our successful measurement of expectation values in such large-scale quantum many-body systems, especially at longer time scales with larger entanglement, highlights the quantum utility of superconducting quantum platforms over conventional classical approximation methods.

09 Oct 2025
We introduce the largest real-world image deblurring dataset constructed from smartphone slow-motion videos. Using 240 frames captured over one second, we simulate realistic long-exposure blur by averaging frames to produce blurry images, while using the temporally centered frame as the sharp reference. Our dataset contains over 42,000 high-resolution blur-sharp image pairs, making it approximately 10 times larger than widely used datasets, with 8 times the amount of different scenes, including indoor and outdoor environments, with varying object and camera motions. We benchmark multiple state-of-the-art (SOTA) deblurring models on our dataset and observe significant performance degradation, highlighting the complexity and diversity of our benchmark. Our dataset serves as a challenging new benchmark to facilitate robust and generalizable deblurring models.

22 Sep 2025
Despite Bengali being the sixth most spoken language in the world, handwritten text recognition (HTR) systems for Bengali remain severely underdeveloped. The complexity of Bengali script--featuring conjuncts, diacritics, and highly variable handwriting styles--combined with a scarcity of annotated datasets makes this task particularly challenging. We present GraDeT-HTR, a resource-efficient Bengali handwritten text recognition system based on a Grapheme-aware Decoder-only Transformer architecture. To address the unique challenges of Bengali script, we augment the performance of a decoder-only transformer by integrating a grapheme-based tokenizer and demonstrate that it significantly improves recognition accuracy compared to conventional subword tokenizers. Our model is pretrained on large-scale synthetic data and fine-tuned on real human-annotated samples, achieving state-of-the-art performance on multiple benchmark datasets.

06 Dec 2025


Researchers from the University of Virginia developed Refer360, a large-scale, multi-view dataset for embodied referring expression comprehension, along with MuRes, a multimodal guided residual module. The MuRes module consistently improved performance on E-RFE tasks and achieved notable gains in Visual Question Answering, for instance, boosting CLIP's VQA accuracy on ScienceQA from 21.31% to 51.85%.

27 Jun 2025
Neural Quantum States (NQS) are a class of variational wave functions parametrized by neural networks (NNs) to study quantum many-body systems. In this work, we propose \texttt{SineKAN}, a NQS \textit{ansatz} based on Kolmogorov-Arnold Networks (KANs), to represent quantum mechanical wave functions as nested univariate functions. We show that \texttt{SineKAN} wavefunction with learnable sinusoidal activation functions can capture the ground state energies, fidelities and various correlation functions of the one dimensional Transverse-Field Ising model, Anisotropic Heisenberg model, and Antiferromagnetic model with different chain lengths. In our study of the model with sites, we find that the \texttt{SineKAN} model outperforms several previously explored neural quantum state \textit{ansätze}, including Restricted Boltzmann Machines (RBMs), Long Short-Term Memory models (LSTMs), and Multi-layer Perceptrons (MLP) \textit{a.k.a.} Feed Forward Neural Networks, when compared to the results obtained from the Density Matrix Renormalization Group (DMRG) algorithm. We find that \texttt{SineKAN} models can be trained to high precisions and accuracies with minimal computational costs.

17 Aug 2022
In modern capital market the price of a stock is often considered to be highly volatile and unpredictable because of various social, financial, political and other dynamic factors. With calculated and thoughtful investment, stock market can ensure a handsome profit with minimal capital investment, while incorrect prediction can easily bring catastrophic financial loss to the investors. This paper introduces the application of a recently introduced machine learning model - the Transformer model, to predict the future price of stocks of Dhaka Stock Exchange (DSE), the leading stock exchange in Bangladesh. The transformer model has been widely leveraged for natural language processing and computer vision tasks, but, to the best of our knowledge, has never been used for stock price prediction task at DSE. Recently the introduction of time2vec encoding to represent the time series features has made it possible to employ the transformer model for the stock price prediction. This paper concentrates on the application of transformer-based model to predict the price movement of eight specific stocks listed in DSE based on their historical daily and weekly data. Our experiments demonstrate promising results and acceptable root mean squared error on most of the stocks.

02 Nov 2024
Time series forecasting is a key tool in financial markets, helping to predict asset prices and guide investment decisions. In highly volatile markets, such as cryptocurrencies like Bitcoin (BTC) and Ethereum (ETH), forecasting becomes more difficult due to extreme price fluctuations driven by market sentiment, technological changes, and regulatory shifts. Traditionally, forecasting relied on statistical methods, but as markets became more complex, deep learning models like LSTM, Bi-LSTM, and the newer FinBERT-LSTM emerged to capture intricate patterns. Building upon recent advancements and addressing the volatility inherent in cryptocurrency markets, we propose a hybrid model that combines Bidirectional Long Short-Term Memory (Bi-LSTM) networks with FinBERT to enhance forecasting accuracy for these assets. This approach fills a key gap in forecasting volatile financial markets by blending advanced time series models with sentiment analysis, offering valuable insights for investors and analysts navigating unpredictable markets.

19 Nov 2025

Recent advances in large language models (LLMs) have accelerated their adoption in software engineering contexts. However, concerns persist about the structural quality of the code they produce. In particular, LLMs often replicate poor coding practices, introducing code smells (i.e., patterns that hinder readability, maintainability, or design integrity). Although prior research has examined the detection or repair of smells, we still lack a clear understanding of how and when these issues emerge in generated code.
This paper addresses this gap by systematically measuring, explaining and mitigating smell propensity in LLM-generated code. We build on the Propensity Smelly Score (PSC), a probabilistic metric that estimates the likelihood of generating particular smell types, and establish its robustness as a signal of structural quality. Using PSC as an instrument for causal analysis, we identify how generation strategy, model size, model architecture and prompt formulation shape the structural properties of generated code. Our findings show that prompt design and architectural choices play a decisive role in smell propensity and motivate practical mitigation strategies that reduce its occurrence. A user study further demonstrates that PSC helps developers interpret model behavior and assess code quality, providing evidence that smell propensity signals can support human judgement. Taken together, our work lays the groundwork for integrating quality-aware assessments into the evaluation and deployment of LLMs for code.

08 Dec 2024
Emotion artificial intelligence is a field of study that focuses on figuring out how to recognize emotions, especially in the area of text mining. Today is the age of social media which has opened a door for us to share our individual expressions, emotions, and perspectives on any event. We can analyze sentiment on social media posts to detect positive, negative, or emotional behavior toward society. One of the key challenges in sentiment analysis is to identify depressed text from social media text that is a root cause of mental ill-health. Furthermore, depression leads to severe impairment in day-to-day living and is a major source of suicide incidents. In this paper, we apply natural language processing techniques on Facebook texts for conducting emotion analysis focusing on depression using multiple machine learning algorithms. Preprocessing steps like stemming, stop word removal, etc. are used to clean the collected data, and feature extraction techniques like stylometric feature, TF-IDF, word embedding, etc. are applied to the collected dataset which consists of 983 texts collected from social media posts. In the process of class prediction, LSTM, GRU, support vector machine, and Naive-Bayes classifiers have been used. We have presented the results using the primary classification metrics including F1-score, and accuracy. This work focuses on depression detection from social media posts to help psychologists to analyze sentiment from shared posts which may reduce the undesirable behaviors of depressed individuals through diagnosis and treatment.

23 Aug 2025
Despite progress in AI-based plant diagnostics, sugarcane farmers in low-resource regions remain vulnerable to leaf diseases due to the lack of scalable, efficient, and interpretable tools. Many deep learning models fail to generalize under real-world conditions and require substantial computational resources, limiting their use in resource-constrained regions. In this paper, we present SugarcaneLD-BD, a curated dataset for sugarcane leaf-disease classification; SugarcaneShuffleNet, an optimized lightweight model for rapid on-device diagnosis; and SugarcaneAI, a Progressive Web Application for field deployment. SugarcaneLD-BD contains 638 curated images across five classes, including four major sugarcane diseases, collected in Bangladesh under diverse field conditions and verified by expert pathologists. To enhance diversity, we combined SugarcaneLD-BD with two additional datasets, yielding a larger and more representative corpus. Our optimized model, SugarcaneShuffleNet, offers the best trade-off between speed and accuracy for real-time, on-device diagnosis. This 9.26 MB model achieved 98.02% accuracy, an F1-score of 0.98, and an average inference time of 4.14 ms per image. For comparison, we fine-tuned five other lightweight convolutional neural networks: MnasNet, EdgeNeXt, EfficientNet-Lite, MobileNet, and SqueezeNet via transfer learning and Bayesian optimization. MnasNet and EdgeNeXt achieved comparable accuracy to SugarcaneShuffleNet, but required significantly more parameters, memory, and computation, limiting their suitability for low-resource deployment. We integrate SugarcaneShuffleNet into SugarcaneAI, delivering Grad-CAM-based explanations in the field. Together, these contributions offer a diverse benchmark, efficient models for low-resource environments, and a practical tool for sugarcane disease classification. It spans varied lighting, backgrounds and devices used on-farm

21 Oct 2025
The hexagonal multiferroic oxide YMnO has demonstrated applications in various fields and is widely researched due to its interesting properties. Since Mn(3d)--O(2p) interactions predominate close to the Fermi level, doping in the B-site (Mn) with Fe provides a way to modulate the band gap and magnetic order of YMnO. The need for a lead-free ferroelectric material with a narrow band gap is crucial for absorbing a wide range of the solar spectrum. Density functional theory calculations were carried out using GGA and meta-GGA (for an accurate description of the band gap) exchange correlation functional for the Fe-doped YMnO multiferroics. Various magnetic configurations were analyzed, finding collinear G-type AFM as the least energy state. The hexagonal lattice is retained after Fe doping with slight distortions and a change in lattice constants. Fe doping reduces spin frustration and induces magnetization, while reducing the band gap from 1.88 eV for pure to 1.19 eV for a 25 percent doping concentration. Additionally, Fe doping exhibits an enhanced dielectric response, characterized by an increase in the static dielectric constant and the presence of strong absorption peaks in the visible and UV energy ranges. Thermoelectric studies illustrate enhanced conductivity due to increased charge carriers induced by doping. In summary, first-principles predictions of structural, electronic, optical, and transport behavior in Fe-doped YMnO provide a foundation for tailoring this oxide in photovoltaic, thermoelectric, and optoelectronic applications.

07 Dec 2024
Hypergraph is a data structure that enables us to model higher-order
associations among data entities. Conventional graph-structured data can
represent pairwise relationships only, whereas hypergraph enables us to
associate any number of entities, which is essential in many real-life
applications. Hypergraph learning algorithms have been well-studied for
numerous problem settings, such as node classification, link prediction, etc.
However, much less research has been conducted on anomaly detection from
hypergraphs. Anomaly detection identifies events that deviate from the usual
pattern and can be applied to hypergraphs to detect unusual higher-order
associations. In this work, we propose an end-to-end hypergraph neural
network-based model for identifying anomalous associations in a hypergraph. Our
proposed algorithm operates in an unsupervised manner without requiring any
labeled data. Extensive experimentation on several real-life datasets
demonstrates the effectiveness of our model in detecting anomalous hyperedges.

17 Apr 2024
This research focused on the development of a cost-effective IoT solution for energy and environment monitoring geared towards manufacturing industries. The proposed system is developed using open-source software that can be easily deployed in any manufacturing environment. The system collects real-time temperature, humidity, and energy data from different devices running on different communication such as TCP/IP, Modbus, etc., and the data is transferred wirelessly using an MQTT client to a database working as a cloud storage solution. The collected data is then visualized and analyzed using a website running on a host machine working as a web client.

18 Sep 2024
Road traffic accidents (RTA) pose a significant public health threat worldwide, leading to considerable loss of life and economic burdens. This is particularly acute in developing countries like Bangladesh. Building reliable models to forecast crash outcomes is crucial for implementing effective preventive measures. To aid in developing targeted safety interventions, this study presents a machine learning-based approach for classifying fatal and non-fatal road accident outcomes using data from the Dhaka metropolitan traffic crash database from 2017 to 2022. Our framework utilizes a range of machine learning classification algorithms, comprising Logistic Regression, Support Vector Machines, Naive Bayes, Random Forest, Decision Tree, Gradient Boosting, LightGBM, and Artificial Neural Network. We prioritize model interpretability by employing the SHAP (SHapley Additive exPlanations) method, which elucidates the key factors influencing accident fatality. Our results demonstrate that LightGBM outperforms other models, achieving a ROC-AUC score of 0.72. The global, local, and feature dependency analyses are conducted to acquire deeper insights into the behavior of the model. SHAP analysis reveals that casualty class, time of accident, location, vehicle type, and road type play pivotal roles in determining fatality risk. These findings offer valuable insights for policymakers and road safety practitioners in developing countries, enabling the implementation of evidence-based strategies to reduce traffic crash fatalities.

22 Dec 2020
The problem of class imbalance is extensive for focusing on numerous
applications in the real world. In such a situation, nearly all of the examples
are labeled as one class called majority class, while far fewer examples are
labeled as the other class usually, the more important class is called
minority. Over the last few years, several types of research have been carried
out on the issue of class imbalance, including data sampling, cost-sensitive
analysis, Genetic Programming based models, bagging, boosting, etc.
Nevertheless, in this survey paper, we enlisted the 24 related studies in the
years 2003, 2008, 2010, 2012 and 2014 to 2019, focusing on the architecture of
single, hybrid, and ensemble method design to understand the current status of
improving classification output in machine learning techniques to fix problems
with class imbalances. This survey paper also includes a statistical analysis
of the classification algorithms under various methods and several other
experimental conditions, as well as datasets used in different research papers.
There are no more papers matching your filters at the moment.
