
19 Sep 2025
Large Language Models (LLMs) have emerged as powerful tools capable of understanding and generating human-like text, offering transformative potential across diverse domains. The Security Operations Center (SOC), responsible for safeguarding digital infrastructure, represents one of these domains. SOCs serve as the frontline of defense in cybersecurity, tasked with continuous monitoring, detection, and response to incidents. However, SOCs face persistent challenges such as high alert volumes, limited resources, high demand for experts with advanced knowledge, delayed response times, and difficulties in leveraging threat intelligence effectively. In this context, LLMs can offer promising solutions by automating log analysis, streamlining triage, improving detection accuracy, and providing the required knowledge in less time. This survey systematically explores the integration of generative AI and more specifically LLMs into SOC workflow, providing a structured perspective on its capabilities, challenges, and future directions. We believe that this survey offers researchers and SOC managers a broad overview of the current state of LLM integration within academic study. To the best of our knowledge, this is the first comprehensive study to examine LLM applications in SOCs in details.

09 Feb 2025
This paper presents HamRaz, a novel Persian-language mental health dataset
designed for Person-Centered Therapy (PCT) using Large Language Models (LLMs).
Despite the growing application of LLMs in AI-driven psychological counseling,
existing datasets predominantly focus on Western and East Asian contexts,
overlooking cultural and linguistic nuances essential for effective
Persian-language therapy. To address this gap, HamRaz combines script-based
dialogues with adaptive LLM role-playing, ensuring coherent and dynamic therapy
interactions. We also introduce HamRazEval, a dual evaluation framework that
measures conversational quality and therapeutic effectiveness using General
Dialogue Metrics and the Barrett-Lennard Relationship Inventory (BLRI).
Experimental results show HamRaz outperforms conventional Script Mode and
Two-Agent Mode, producing more empathetic, context-aware, and realistic therapy
sessions. By releasing HamRaz, we contribute a culturally adapted, LLM-driven
resource to advance AI-powered psychotherapy research in diverse communities.

19 Oct 2025
Quantum coherence is a key resource underpinning quantum technologies, yet it is highly susceptible to environmental decoherence, especially in thermal settings. While frequency modulation (FM) has shown promise in preserving coherence at zero temperature, its effectiveness in realistic, noisy thermal environments remains unclear. In this work, we investigate a single frequency-modulated qubit interacting with a thermal phase-covariant reservoir composed of dissipative and dephasing channels. We demonstrate that FM significantly preserves coherence in the presence of thermal dissipation while being ineffective under thermal pure-dephasing noise due to commutation between system and interaction Hamiltonians. When both noise channels are present, FM offers protection only for weak dephasing coupling. Our findings clarify the limitations and potential of FM-based coherence protection under thermal noise, supplying practical insights into designing robust quantum systems for quantum applications.

26 Feb 2025

The rise of Large Language Models (LLMs) has boosted the use of Few-Shot
Learning (FSL) methods in natural language processing, achieving acceptable
performance even when working with limited training data. The goal of FSL is to
effectively utilize a small number of annotated samples in the learning
process. However, the performance of FSL suffers when unsuitable support
samples are chosen. This problem arises due to the heavy reliance on a limited
number of support samples, which hampers consistent performance improvement
even when more support samples are added. To address this challenge, we propose
an active learning-based instance selection mechanism that identifies effective
support instances from the unlabeled pool and can work with different LLMs. Our
experiments on five tasks show that our method frequently improves the
performance of FSL. We make our implementation available on GitHub.

01 Jan 2021
Sentiment Analysis (SA) is a major field of study in natural language
processing, computational linguistics and information retrieval. Interest in SA
has been constantly growing in both academia and industry over the recent
years. Moreover, there is an increasing need for generating appropriate
resources and datasets in particular for low resource languages including
Persian. These datasets play an important role in designing and developing
appropriate opinion mining platforms using supervised, semi-supervised or
unsupervised methods. In this paper, we outline the entire process of
developing a manually annotated sentiment corpus, SentiPers, which covers
formal and informal written contemporary Persian. To the best of our knowledge,
SentiPers is a unique sentiment corpus with such a rich annotation in three
different levels including document-level, sentence-level, and
entity/aspect-level for Persian. The corpus contains more than 26000 sentences
of users opinions from digital product domain and benefits from special
characteristics such as quantifying the positiveness or negativity of an
opinion through assigning a number within a specific range to any given
sentence. Furthermore, we present statistics on various components of our
corpus as well as studying the inter-annotator agreement among the annotators.
Finally, some of the challenges that we faced during the annotation process
will be discussed as well.

10 Oct 2021


Phonocardiogram (PCG) signal analysis is a critical, widely-studied
technology to noninvasively analyze the heart's mechanical activity. Through
evaluating heart sounds, this technology has been chiefly leveraged as a
preliminary solution to automatically diagnose Cardiovascular diseases among
adults; however, prenatal tasks such as fetal gender identification have been
relatively less studied using fetal Phonocardiography (FPCG). In this work, we
apply common PCG signal processing techniques on the gender-tagged Shiraz
University Fetal Heart Sounds Database and study the applicability of
previously proposed features in classifying fetal gender using both Machine
Learning and Deep Learning models. Even though PCG data acquisition's
cost-effectiveness and feasibility make it a convenient method of Fetal Heart
Rate (FHR) monitoring, the contaminated nature of PCG signals with the noise of
various types makes it a challenging modality. To address this problem, we
experimented with both static and adaptive noise reduction techniques such as
Low-pass filtering, Denoising Autoencoders, and Source Separators. We apply a
wide range of previously proposed classifiers to our dataset and propose a
novel ensemble method of Fetal Gender Identification (FGI). Our method
substantially outperformed the baseline and reached up to 91% accuracy in
classifying fetal gender of unseen subjects.

14 Aug 2025
Detecting plant diseases is a crucial aspect of modern agriculture, as it plays a key role in maintaining crop health and increasing overall yield. Traditional approaches, though still valuable, often rely on manual inspection or conventional machine learning techniques, both of which face limitations in scalability and accuracy. Recently, Vision Transformers (ViTs) have emerged as a promising alternative, offering advantages such as improved handling of long-range dependencies and better scalability for visual tasks. This review explores the application of ViTs in precision agriculture, covering a range of tasks. We begin by introducing the foundational architecture of ViTs and discussing their transition from Natural Language Processing (NLP) to Computer Vision. The discussion includes the concept of inductive bias in traditional models like Convolutional Neural Networks (CNNs), and how ViTs mitigate these biases. We provide a comprehensive review of recent literature, focusing on key methodologies, datasets, and performance metrics. This study also includes a comparative analysis of CNNs and ViTs, along with a review of hybrid models and performance enhancements. Technical challenges such as data requirements, computational demands, and model interpretability are addressed, along with potential solutions. Finally, we outline future research directions and technological advancements that could further support the integration of ViTs in real-world agricultural settings. Our goal with this study is to offer practitioners and researchers a deeper understanding of how ViTs are poised to transform smart and precision agriculture.
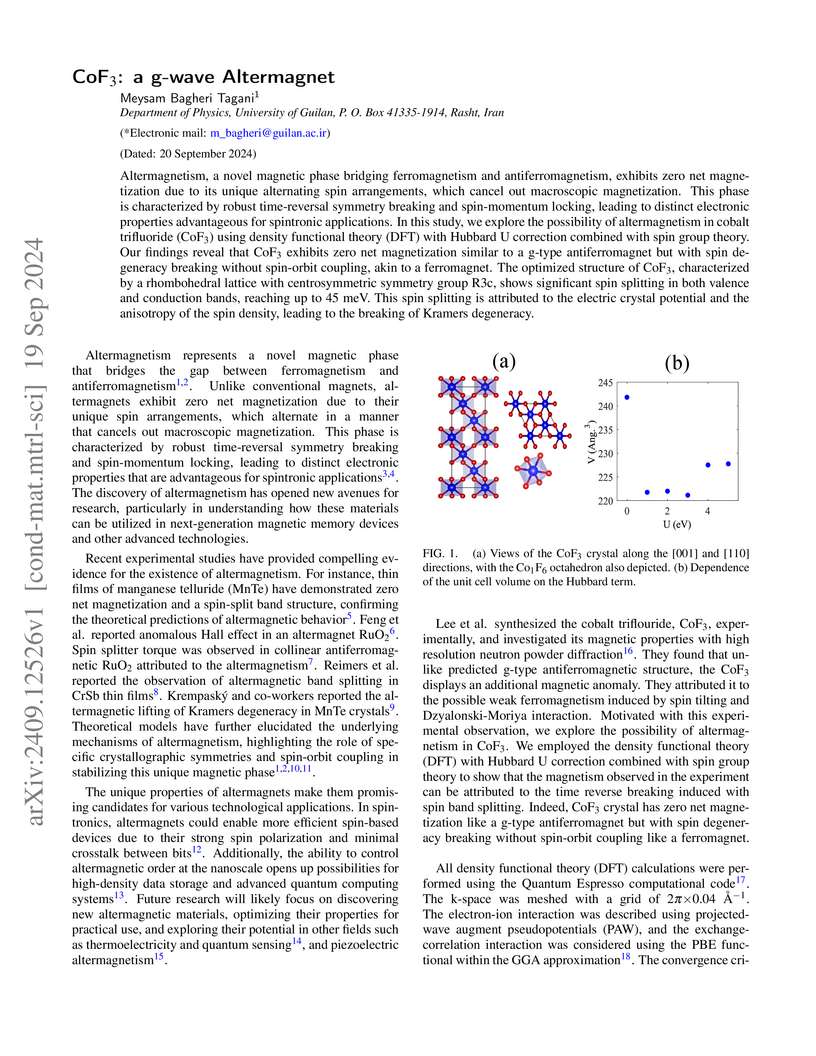
19 Sep 2024
Altermagnetism, a novel magnetic phase bridging ferromagnetism and
antiferromagnetism, exhibits zero net magnetization due to its unique
alternating spin arrangements, which cancel out macroscopic magnetization. This
phase is characterized by robust time-reversal symmetry breaking and
spin-momentum locking, leading to distinct electronic properties advantageous
for spintronic applications. In this study, we explore the possibility of
altermagnetism in cobalt trifluoride (CoF3) using density functional theory
(DFT) with Hubbard U correction combined with spin group theory. Our findings
reveal that CoF3 exhibits zero net magnetization similar to a g-type
antiferromagnet but with spin degeneracy breaking without spin-orbit coupling,
akin to a ferromagnet. The optimized structure of CoF3, characterized by a
rhombohedral lattice with centrosymmetric symmetry group R3c, shows significant
spin splitting in both valence and conduction bands, reaching up to 45 meV.
This spin splitting is attributed to the electric crystal potential and the
anisotropy of the spin density, leading to the breaking of Kramers degeneracy.

08 Mar 2024
Transformer-based models have made remarkable advancements in various NLP
areas. Nevertheless, these models often exhibit vulnerabilities when confronted
with adversarial attacks. In this paper, we explore the effect of quantization
on the robustness of Transformer-based models. Quantization usually involves
mapping a high-precision real number to a lower-precision value, aiming at
reducing the size of the model at hand. To the best of our knowledge, this work
is the first application of quantization on the robustness of NLP models. In
our experiments, we evaluate the impact of quantization on BERT and DistilBERT
models in text classification using SST-2, Emotion, and MR datasets. We also
evaluate the performance of these models against TextFooler, PWWS, and PSO
adversarial attacks. Our findings show that quantization significantly improves
(by an average of 18.68%) the adversarial accuracy of the models. Furthermore,
we compare the effect of quantization versus that of the adversarial training
approach on robustness. Our experiments indicate that quantization increases
the robustness of the model by 18.80% on average compared to adversarial
training without imposing any extra computational overhead during training.
Therefore, our results highlight the effectiveness of quantization in improving
the robustness of NLP models.

01 Jan 2021
Providing huge amounts of data is a fundamental demand when dealing with Deep Neural Networks (DNNs). Employing these algorithms to solve computer vision problems resulted in the advent of various image datasets to feed the most common visual imagery deep structures, known as Convolutional Neural Networks (CNNs). In this regard, some datasets can be found that contain hundreds or even thousands of images for license plate detection and optical character recognition purposes. However, no publicly available image dataset provides such data for the recognition of Farsi characters used in car license plates. The gap has to be filled due to the numerous advantages of developing accurate deep learning-based systems for law enforcement and surveillance purposes. This paper introduces a large-scale dataset that includes images of numbers and characters used in Iranian car license plates. The dataset, named Iranis, contains more than 83,000 images of Farsi numbers and letters collected from real-world license plate images captured by various cameras. The variety of instances in terms of camera shooting angle, illumination, resolution, and contrast make the dataset a proper choice for training DNNs. Dataset images are manually annotated for object detection and image classification. Finally, and to build a baseline for Farsi character recognition, the paper provides a performance analysis using a YOLO v.3 object detector.

14 Mar 2024
The accuracy of absolute parameters' estimation in contact binary systems is important for investigating their evolution and solving some challenges. The Gaia DR3 parallax is one of the methods used for estimating the absolute parameters, in cases where photometric data is the only one that is available. The use of this method includes advantages and limitations that we have described and examined in this study. We selected 48 contact binary systems whose mass ratios were mostly obtained by spectroscopic data, in addition to a number of photometric studies. The target systems were suitable for A_V and the Re-normalised Unit Weight Error (RUWE), and their absolute parameters were calculated based on Gaia DR3 parallax, observational information, orbital period, and light cure solution from the literature and catalogs. The outcomes of OO Aql differed significantly from those reported in the literature. Upon analyzing the system's light curve with TESS data, we concluded that the stars' temperatures were the reason for this difference, and utilizing Gaia DR3 parallax provided reasonable results. We displayed the target systems on the Hertzsprung-Russell (HR), q-L_ratio, P-M_V, and logM_tot-logJ_0 diagrams, and the systems are in good agreement with the theoretical fits. We showed that the estimation of absolute parameters with this method might be acceptable if Delta a(R_Sun) is less than about 0.1(R_Sun). There are open questions regarding the existence of l_3 in the light curve analysis and its effect on the estimation of absolute parameters with this method.

31 Aug 2011
Compression is a technique to reduce the quantity of data without excessively
reducing the quality of the multimedia data. The transition and storing of
compressed multimedia data is much faster and more efficient than original
uncompressed multimedia data. There are various techniques and standards for
multimedia data compression, especially for image compression such as the JPEG
and JPEG2000 standards. These standards consist of different functions such as
color space conversion and entropy coding. Arithmetic and Huffman coding are
normally used in the entropy coding phase. In this paper we try to answer the
following question. Which entropy coding, arithmetic or Huffman, is more
suitable compared to other from the compression ratio, performance, and
implementation points of view? We have implemented and tested Huffman and
arithmetic algorithms. Our implemented results show that compression ratio of
arithmetic coding is better than Huffman coding, while the performance of the
Huffman coding is higher than Arithmetic coding. In addition, implementation of
Huffman coding is much easier than the Arithmetic coding.

04 Apr 2022
Machine Learning (ML) algorithms are increasingly used as surrogate models to increase the efficiency of stochastic reliability analyses in geotechnical engineering. This paper presents a highly efficient ML aided reliability technique that is able to accurately predict the results of a Monte Carlo (MC) reliability study, and yet performs 500 times faster. A complete MC reliability analysis on anisotropic heterogeneous slopes consisting of 120,000 simulated samples is conducted in parallel to the proposed ML aided stochastic technique. Comparing the results of the complete MC study and the proposed ML aided technique, the expected errors of the proposed method are realistically examined. Circumventing the time-consuming computation of factors of safety for the training datasets, the proposed technique is more efficient than previous methods. Different ML models, including Random Forest (RF), Support Vector Machine (SVM) and Artificial Neural Networks (ANN) are presented, optimised and compared. The effects of the size and type of training and testing datasets are discussed. The expected errors of the ML predicted probability of failure are characterised by different levels of soil heterogeneity and anisotropy. Using only 1% of MC samples to train ML surrogate models, the proposed technique can accurately predict the probability of failure with mean errors limited to 0.7%. The proposed technique reduces the computational time required for our study from 306 days to only 14 hours, providing 500 times higher efficiency.

17 Sep 2020

Male infertility is a disease which affects approximately 7% of men. Sperm
morphology analysis (SMA) is one of the main diagnosis methods for this
problem. Manual SMA is an inexact, subjective, non-reproducible, and hard to
teach process. As a result, in this paper, we introduce a novel automatic SMA
based on a neural architecture search algorithm termed Genetic Neural
Architecture Search (GeNAS). For this purpose, we used a collection of images
called MHSMA dataset contains 1,540 sperm images which have been collected from
235 patients with infertility problems. GeNAS is a genetic algorithm that acts
as a meta-controller which explores the constrained search space of plain
convolutional neural network architectures. Every individual of the genetic
algorithm is a convolutional neural network trained to predict morphological
deformities in different segments of human sperm (head, vacuole, and acrosome),
and its fitness is calculated by a novel proposed method named GeNAS-WF
especially designed for noisy, low resolution, and imbalanced datasets. Also, a
hashing method is used to save each trained neural architecture fitness, so we
could reuse them during fitness evaluation and speed up the algorithm. Besides,
in terms of running time and computation power, our proposed architecture
search method is far more efficient than most of the other existing neural
architecture search algorithms. Additionally, other proposed methods have been
evaluated on balanced datasets, whereas GeNAS is built specifically for noisy,
low quality, and imbalanced datasets which are common in the field of medical
imaging. In our experiments, the best neural architecture found by GeNAS has
reached an accuracy of 91.66%, 77.33%, and 77.66% in the vacuole, head, and
acrosome abnormality detection, respectively. In comparison to other proposed
algorithms for MHSMA dataset, GeNAS achieved state-of-the-art results.

19 Nov 2016
Credit card plays a very important rule in today's economy. It becomes an
unavoidable part of household, business and global activities. Although using
credit cards provides enormous benefits when used carefully and
responsibly,significant credit and financial damages may be caused by
fraudulent activities. Many techniques have been proposed to confront the
growth in credit card fraud. However, all of these techniques have the same
goal of avoiding the credit card fraud; each one has its own drawbacks,
advantages and characteristics. In this paper, after investigating difficulties
of credit card fraud detection, we seek to review the state of the art in
credit card fraud detection techniques, data sets and evaluation criteria.The
advantages and disadvantages of fraud detection methods are enumerated and
compared.Furthermore, a classification of mentioned techniques into two main
fraud detection approaches, namely, misuses (supervised) and anomaly detection
(unsupervised) is presented. Again, a classification of techniques is proposed
based on capability to process the numerical and categorical data sets.
Different data sets used in literature are then described and grouped into real
and synthesized data and the effective and common attributes are extracted for
further usage.Moreover, evaluation employed criterions in literature are
collected and discussed.Consequently, open issues for credit card fraud
detection are explained as guidelines for new researchers.

22 Jan 2025
We study thermalization in closed non-integrable quantum systems using the
Krylov basis. We demonstrate that for thermalization to occur, the matrix
representation of typical local operators in the Krylov basis should exhibit a
specific tridiagonal form with all other elements in the matrix are
exponentially small, reminiscent of the eigenstate thermalization hypothesis.
Within this framework, we propose that the nature of thermalization, whether
weak or strong, can be examined by the infinite time average of the Krylov
complexity. Moreover, we analyze the variance of Lanczos coefficients as
another probe for the nature of thermalization. One observes that although the
variance of Lanczos coefficients may capture certain features of
thermalization, it is not as effective as the infinite time average of
complexity.

26 Sep 2021
Contemporary question answering (QA) systems, including transformer-based
architectures, suffer from increasing computational and model complexity which
render them inefficient for real-world applications with limited resources.
Further, training or even fine-tuning such models requires a vast amount of
labeled data which is often not available for the task at hand. In this
manuscript, we conduct a comprehensive analysis of the mentioned challenges and
introduce suitable countermeasures. We propose a novel knowledge distillation
(KD) approach to reduce the parameter and model complexity of a pre-trained
BERT system and utilize multiple active learning (AL) strategies for immense
reduction in annotation efforts. In particular, we demonstrate that our model
achieves the performance of a 6-layer TinyBERT and DistilBERT, whilst using
only 2% of their total parameters. Finally, by the integration of our AL
approaches into the BERT framework, we show that state-of-the-art results on
the SQuAD dataset can be achieved when we only use 20% of the training data.

06 Jun 2024
Evaluating the theory of mind (ToM) capabilities of language models (LMs) has
recently received a great deal of attention. However, many existing benchmarks
rely on synthetic data, which risks misaligning the resulting experiments with
human behavior. We introduce the first ToM dataset based on naturally occurring
spoken dialogs, Common-ToM, and show that LMs struggle to demonstrate ToM. We
then show that integrating a simple, explicit representation of beliefs
improves LM performance on Common-ToM.

08 Apr 2022


Point-of-Interest (POI) recommender systems provide personalized
recommendations to users and help businesses attract potential customers.
Despite their success, recent studies suggest that highly data-driven
recommendations could be impacted by data biases, resulting in unfair outcomes
for different stakeholders, mainly consumers (users) and providers (items).
Most existing fairness-related research works in recommender systems treat user
fairness and item fairness issues individually, disregarding that RS work in a
two-sided marketplace. This paper studies the interplay between (i) the
unfairness of active users, (ii) the unfairness of popular items, and (iii) the
accuracy (personalization) of recommendation as three angles of our study
triangle. We group users into advantaged and disadvantaged levels to measure
user fairness based on their activity level. For item fairness, we divide items
into short-head, mid-tail, and long-tail groups and study the exposure of these
item groups into the top-k recommendation list of users. Experimental
validation of eight different recommendation models commonly used for POI
recommendation (e.g., contextual, CF) on two publicly available POI
recommendation datasets, Gowalla and Yelp, indicate that most well-performing
models suffer seriously from the unfairness of popularity bias (provider
unfairness). Furthermore, our study shows that most recommendation models
cannot satisfy both consumer and producer fairness, indicating a trade-off
between these variables possibly due to natural biases in data. We choose the
POI recommendation as our test scenario; however, the insights should be
trivially extendable on other domains.

06 May 2018
This paper presents an application of adaptive control algorithm in order to reject the external disturbances in dual-stage hard disk drives. For this purpose, a dual PID controller is first designed without the plant exposure to external disturbances. Then, an adaptive control approach based on recursive least squares adaptive (RLS) algorithm was employed to identify and reject disturbances. The performance of the proposed technique was evaluated for hard disk track-seeking through simulation experiments. Results show the feasibility and precise tracking of the designed control system.
There are no more papers matching your filters at the moment.
