
21 Mar 2017
Deep SORT enhances the Simple Online and Realtime Tracking (SORT) framework by incorporating a deep appearance metric for data association, leading to an approximate 45% reduction in identity switches while maintaining real-time processing speeds of around 20 Hz. The method improves track consistency, making it a more robust solution for multiple object tracking in challenging environments.

23 Apr 2019
 ETH Zurich
ETH Zurich University of Washington
University of Washington CNRS
CNRS University of Pittsburgh
University of Pittsburgh University of CambridgeUniversity of FreiburgHeidelberg UniversityLeibniz University Hannover
University of CambridgeUniversity of FreiburgHeidelberg UniversityLeibniz University Hannover Northeastern University
Northeastern University UCLA
UCLA Imperial College London
Imperial College London University of ManchesterUniversity of Zurich
University of ManchesterUniversity of Zurich New York UniversityUniversity of BernUniversity of Stuttgart
New York UniversityUniversity of BernUniversity of Stuttgart UC Berkeley
UC Berkeley University College London
University College London Fudan University
Fudan University Georgia Institute of TechnologyNational Taiwan University
Georgia Institute of TechnologyNational Taiwan University the University of Tokyo
the University of Tokyo University of California, IrvineUniversity of BonnTechnical University of Berlin
University of California, IrvineUniversity of BonnTechnical University of Berlin University of Bristol
University of Bristol University of MichiganUniversity of EdinburghUniversity of Hong KongUniversity of Alabama at Birmingham
University of MichiganUniversity of EdinburghUniversity of Hong KongUniversity of Alabama at Birmingham Northwestern UniversityUniversity of Bamberg
Northwestern UniversityUniversity of Bamberg University of Florida
University of Florida Emory UniversityUniversity of CologneHarvard Medical School
Emory UniversityUniversity of CologneHarvard Medical School University of Pennsylvania
University of Pennsylvania University of SouthamptonFlorida State University
University of SouthamptonFlorida State University EPFL
EPFL University of Wisconsin-MadisonMassachusetts General HospitalChongqing UniversityKeio University
University of Wisconsin-MadisonMassachusetts General HospitalChongqing UniversityKeio University University of Alberta
University of Alberta King’s College LondonFriedrich-Alexander-Universität Erlangen-NürnbergUniversity of Luxembourg
King’s College LondonFriedrich-Alexander-Universität Erlangen-NürnbergUniversity of Luxembourg Technical University of MunichUniversity of Duisburg-EssenSapienza University of RomeUniversity of HeidelbergUniversity of Sheffield
Technical University of MunichUniversity of Duisburg-EssenSapienza University of RomeUniversity of HeidelbergUniversity of Sheffield HKUSTUniversity of GenevaWashington University in St. LouisTU BerlinUniversity of GlasgowUniversity of SiegenUniversity of PotsdamUniversidade Estadual de CampinasUniversity of Oldenburg
HKUSTUniversity of GenevaWashington University in St. LouisTU BerlinUniversity of GlasgowUniversity of SiegenUniversity of PotsdamUniversidade Estadual de CampinasUniversity of Oldenburg The Ohio State UniversityUniversity of LeicesterGerman Cancer Research Center (DKFZ)University of BremenUniversity of ToulouseUniversity of Miami
The Ohio State UniversityUniversity of LeicesterGerman Cancer Research Center (DKFZ)University of BremenUniversity of ToulouseUniversity of Miami Karlsruhe Institute of TechnologyPeking Union Medical CollegeUniversity of OuluUniversity of HamburgUniversity of RegensburgUniversity of BirminghamUniversity of LeedsChinese Academy of Medical SciencesINSERM
Karlsruhe Institute of TechnologyPeking Union Medical CollegeUniversity of OuluUniversity of HamburgUniversity of RegensburgUniversity of BirminghamUniversity of LeedsChinese Academy of Medical SciencesINSERM University of BaselPeking Union Medical College HospitalUniversity of LausanneUniversity of LilleUniversity of PoitiersUniversity of PassauUniversity of LübeckKing Fahd University of Petroleum and MineralsUniversity of LondonUniversity of NottinghamUniversity of Erlangen-NurembergUniversity of BielefeldSorbonne UniversityUniversity of South FloridaWake Forest UniversityUniversity of CalgaryUniversity of Picardie Jules VerneIBM
University of BaselPeking Union Medical College HospitalUniversity of LausanneUniversity of LilleUniversity of PoitiersUniversity of PassauUniversity of LübeckKing Fahd University of Petroleum and MineralsUniversity of LondonUniversity of NottinghamUniversity of Erlangen-NurembergUniversity of BielefeldSorbonne UniversityUniversity of South FloridaWake Forest UniversityUniversity of CalgaryUniversity of Picardie Jules VerneIBM University of GöttingenUniversity of BordeauxUniversity of MannheimUniversity of California San FranciscoNIHUniversity of KonstanzUniversity of Electro-CommunicationsUniversity of WuppertalUniversity of ReunionUNICAMPUniversity of TrierHasso Plattner InstituteUniversity of BayreuthHeidelberg University HospitalUniversity of StrasbourgDKFZUniversity of LorraineInselspital, Bern University Hospital, University of BernUniversity of WürzburgUniversity of La RochelleUniversity of LyonUniversity of HohenheimUniversity Medical Center Hamburg-EppendorfUniversity of UlmUniversity Hospital ZurichUniversity of TuebingenUniversity of KaiserslauternUniversity of NantesUniversity of MainzUniversity of PaderbornUniversity of KielMedical University of South CarolinaUniversity of RostockThe University of Texas MD Anderson Cancer CenterNational Research Council (CNR)Hannover Medical SchoolItalian National Research CouncilUniversity of MuensterUniversity of MontpellierUniversity of LeipzigUniversity of GreifswaldUniversity Hospital BernSiemens HealthineersThe University of Alabama at BirminghamNational Institutes of HealthUniversity of MarburgUniversity of Paris-SaclayUniversity of LimogesUniversity of Clermont AuvergneUniversity of DortmundUniversity of GiessenKITUniversity of ToulonChildren’s Hospital of PhiladelphiaUniversity of JenaNational Taiwan University HospitalUniversity of SaarlandUniversity of ErlangenNational Cancer InstituteUniversity Hospital HeidelbergSwiss Federal Institute of Technology LausanneUniversity of Texas Health Science Center at HoustonNational Institute of Biomedical Imaging and BioengineeringUniversity of New CaledoniaUniversity of Koblenz-LandauParis Diderot UniversityUniversity of ParisInselspital, Bern University HospitalUniversity of Grenoble AlpesUniversity Hospital BaselMD Anderson Cancer CenterUniversity of AngersUniversity of French PolynesiaUniversity of MagdeburgUniversity of Geneva, SwitzerlandOulu University HospitalUniversity of ToursFriedrich-Alexander-University Erlangen-NurnbergUniversity of Rennes 1Wake Forest School of MedicineNIH Clinical CenterParis Descartes UniversityUniversity of Rouen NormandieUniversity of Aix-MarseilleUniversity of Perpignan Via DomitiaUniversity of Caen NormandieUniversity of FrankfurtUniversity of BochumUniversity of Bourgogne-Franche-ComtéUniversity of Corsica Pasquale PaoliNational Institute of Neurological Disorders and StrokeUniversity of HannoverRoche DiagnosticsUniversity of South BrittanyUniversity of DüsseldorfUniversity of Reims Champagne-ArdenneUniversity of HalleIRCCS Fondazione Santa LuciaUniversity of Applied Sciences TrierUniversity of Southampton, UKUniversity of Nice–Sophia AntipolisUniversit
de LorraineUniversité Paris-Saclay["École Polytechnique Fédérale de Lausanne"]RWTH Aachen UniversityUniversity of Bern, Institute for Advanced Study in Biomedical InnovationCRIBIS University of AlbertaThe Cancer Imaging Archive (TCIA)Fraunhofer Institute for Medical Image Computing MEVISMedical School of HannoverIstituto di Ricovero e Cura a Carattere Scientifico NeuromedFondazione Santa Lucia IRCCSCEA, LIST, Laboratory of Image and Biomedical SystemsUniversity of Alberta, CanadaHeidelberg University Hospital, Department of NeuroradiologyUniversity of Bern, SwitzerlandUniversity of DresdenUniversity of SpeyerUniversity of Trier, GermanyUniversity of Lorraine, FranceUniversity of Le Havre NormandieUniversity of Bretagne OccidentaleUniversity of French GuianaUniversity of the AntillesUniversity of Bern, Institute of Surgical Technology and BiomechanicsUniversity of Bern, ARTORG Center for Biomedical Engineering ResearchUniversity of Geneva, Department of RadiologyUniversity of Zürich, Department of NeuroradiologyRuhr-University-Bochum
University of GöttingenUniversity of BordeauxUniversity of MannheimUniversity of California San FranciscoNIHUniversity of KonstanzUniversity of Electro-CommunicationsUniversity of WuppertalUniversity of ReunionUNICAMPUniversity of TrierHasso Plattner InstituteUniversity of BayreuthHeidelberg University HospitalUniversity of StrasbourgDKFZUniversity of LorraineInselspital, Bern University Hospital, University of BernUniversity of WürzburgUniversity of La RochelleUniversity of LyonUniversity of HohenheimUniversity Medical Center Hamburg-EppendorfUniversity of UlmUniversity Hospital ZurichUniversity of TuebingenUniversity of KaiserslauternUniversity of NantesUniversity of MainzUniversity of PaderbornUniversity of KielMedical University of South CarolinaUniversity of RostockThe University of Texas MD Anderson Cancer CenterNational Research Council (CNR)Hannover Medical SchoolItalian National Research CouncilUniversity of MuensterUniversity of MontpellierUniversity of LeipzigUniversity of GreifswaldUniversity Hospital BernSiemens HealthineersThe University of Alabama at BirminghamNational Institutes of HealthUniversity of MarburgUniversity of Paris-SaclayUniversity of LimogesUniversity of Clermont AuvergneUniversity of DortmundUniversity of GiessenKITUniversity of ToulonChildren’s Hospital of PhiladelphiaUniversity of JenaNational Taiwan University HospitalUniversity of SaarlandUniversity of ErlangenNational Cancer InstituteUniversity Hospital HeidelbergSwiss Federal Institute of Technology LausanneUniversity of Texas Health Science Center at HoustonNational Institute of Biomedical Imaging and BioengineeringUniversity of New CaledoniaUniversity of Koblenz-LandauParis Diderot UniversityUniversity of ParisInselspital, Bern University HospitalUniversity of Grenoble AlpesUniversity Hospital BaselMD Anderson Cancer CenterUniversity of AngersUniversity of French PolynesiaUniversity of MagdeburgUniversity of Geneva, SwitzerlandOulu University HospitalUniversity of ToursFriedrich-Alexander-University Erlangen-NurnbergUniversity of Rennes 1Wake Forest School of MedicineNIH Clinical CenterParis Descartes UniversityUniversity of Rouen NormandieUniversity of Aix-MarseilleUniversity of Perpignan Via DomitiaUniversity of Caen NormandieUniversity of FrankfurtUniversity of BochumUniversity of Bourgogne-Franche-ComtéUniversity of Corsica Pasquale PaoliNational Institute of Neurological Disorders and StrokeUniversity of HannoverRoche DiagnosticsUniversity of South BrittanyUniversity of DüsseldorfUniversity of Reims Champagne-ArdenneUniversity of HalleIRCCS Fondazione Santa LuciaUniversity of Applied Sciences TrierUniversity of Southampton, UKUniversity of Nice–Sophia AntipolisUniversit
de LorraineUniversité Paris-Saclay["École Polytechnique Fédérale de Lausanne"]RWTH Aachen UniversityUniversity of Bern, Institute for Advanced Study in Biomedical InnovationCRIBIS University of AlbertaThe Cancer Imaging Archive (TCIA)Fraunhofer Institute for Medical Image Computing MEVISMedical School of HannoverIstituto di Ricovero e Cura a Carattere Scientifico NeuromedFondazione Santa Lucia IRCCSCEA, LIST, Laboratory of Image and Biomedical SystemsUniversity of Alberta, CanadaHeidelberg University Hospital, Department of NeuroradiologyUniversity of Bern, SwitzerlandUniversity of DresdenUniversity of SpeyerUniversity of Trier, GermanyUniversity of Lorraine, FranceUniversity of Le Havre NormandieUniversity of Bretagne OccidentaleUniversity of French GuianaUniversity of the AntillesUniversity of Bern, Institute of Surgical Technology and BiomechanicsUniversity of Bern, ARTORG Center for Biomedical Engineering ResearchUniversity of Geneva, Department of RadiologyUniversity of Zürich, Department of NeuroradiologyRuhr-University-Bochum

Gliomas are the most common primary brain malignancies, with different
degrees of aggressiveness, variable prognosis and various heterogeneous
histologic sub-regions, i.e., peritumoral edematous/invaded tissue, necrotic
core, active and non-enhancing core. This intrinsic heterogeneity is also
portrayed in their radio-phenotype, as their sub-regions are depicted by
varying intensity profiles disseminated across multi-parametric magnetic
resonance imaging (mpMRI) scans, reflecting varying biological properties.
Their heterogeneous shape, extent, and location are some of the factors that
make these tumors difficult to resect, and in some cases inoperable. The amount
of resected tumor is a factor also considered in longitudinal scans, when
evaluating the apparent tumor for potential diagnosis of progression.
Furthermore, there is mounting evidence that accurate segmentation of the
various tumor sub-regions can offer the basis for quantitative image analysis
towards prediction of patient overall survival. This study assesses the
state-of-the-art machine learning (ML) methods used for brain tumor image
analysis in mpMRI scans, during the last seven instances of the International
Brain Tumor Segmentation (BraTS) challenge, i.e., 2012-2018. Specifically, we
focus on i) evaluating segmentations of the various glioma sub-regions in
pre-operative mpMRI scans, ii) assessing potential tumor progression by virtue
of longitudinal growth of tumor sub-regions, beyond use of the RECIST/RANO
criteria, and iii) predicting the overall survival from pre-operative mpMRI
scans of patients that underwent gross total resection. Finally, we investigate
the challenge of identifying the best ML algorithms for each of these tasks,
considering that apart from being diverse on each instance of the challenge,
the multi-institutional mpMRI BraTS dataset has also been a continuously
evolving/growing dataset.

10 Jan 2022
Due to the significant advancement of Natural Language Processing and Computer Vision-based models, Visual Question Answering (VQA) systems are becoming more intelligent and advanced. However, they are still error-prone when dealing with relatively complex questions. Therefore, it is important to understand the behaviour of the VQA models before adopting their results. In this paper, we introduce an interpretability approach for VQA models by generating counterfactual images. Specifically, the generated image is supposed to have the minimal possible change to the original image and leads the VQA model to give a different answer. In addition, our approach ensures that the generated image is realistic. Since quantitative metrics cannot be employed to evaluate the interpretability of the model, we carried out a user study to assess different aspects of our approach. In addition to interpreting the result of VQA models on single images, the obtained results and the discussion provides an extensive explanation of VQA models' behaviour.

16 Mar 2017

Wikipedia is one of the most popular sites on the Web, with millions of users
relying on it to satisfy a broad range of information needs every day. Although
it is crucial to understand what exactly these needs are in order to be able to
meet them, little is currently known about why users visit Wikipedia. The goal
of this paper is to fill this gap by combining a survey of Wikipedia readers
with a log-based analysis of user activity. Based on an initial series of user
surveys, we build a taxonomy of Wikipedia use cases along several dimensions,
capturing users' motivations to visit Wikipedia, the depth of knowledge they
are seeking, and their knowledge of the topic of interest prior to visiting
Wikipedia. Then, we quantify the prevalence of these use cases via a
large-scale user survey conducted on live Wikipedia with almost 30,000
responses. Our analyses highlight the variety of factors driving users to
Wikipedia, such as current events, media coverage of a topic, personal
curiosity, work or school assignments, or boredom. Finally, we match survey
responses to the respondents' digital traces in Wikipedia's server logs,
enabling the discovery of behavioral patterns associated with specific use
cases. For instance, we observe long and fast-paced page sequences across
topics for users who are bored or exploring randomly, whereas those using
Wikipedia for work or school spend more time on individual articles focused on
topics such as science. Our findings advance our understanding of reader
motivations and behavior on Wikipedia and can have implications for developers
aiming to improve Wikipedia's user experience, editors striving to cater to
their readers' needs, third-party services (such as search engines) providing
access to Wikipedia content, and researchers aiming to build tools such as
recommendation engines.

22 Jul 2019

People's perceptions about the size of minority groups in social networks can be biased, often showing systematic over- or underestimation. These social perception biases are often attributed to biased cognitive or motivational processes. Here we show that both over- and underestimation of the size of a minority group can emerge solely from structural properties of social networks. Using a generative network model, we show analytically that these biases depend on the level of homophily and its asymmetric nature, as well as on the size of the minority group. Our model predictions correspond well with empirical data from a cross-cultural survey and with numerical calculations on six real-world networks. We also show under what circumstances individuals can reduce their biases by relying on perceptions of their neighbors. This work advances our understanding of the impact of network structure on social perception biases and offers a quantitative approach for addressing related issues in society.

30 Jul 2018
In this paper we present an approach for learning to imitate human behavior
on a semantic level by markerless visual observation. We analyze a set of
spatial constraints on human pose data extracted using convolutional pose
machines and object informations extracted from 2D image sequences. A scene
analysis, based on an ontology of objects and affordances, is combined with
continuous human pose estimation and spatial object relations. Using a set of
constraints we associate the observed human actions with a set of executable
robot commands. We demonstrate our approach in a kitchen task, where the robot
learns to prepare a meal.

16 Feb 2016
With the growing popularity of large-scale collaborative ontology-engineering
projects, such as the creation of the 11th revision of the International
Classification of Diseases, we need new methods and insights to help project-
and community-managers to cope with the constantly growing complexity of such
projects. In this paper, we present a novel application of Markov chains to
model sequential usage patterns that can be found in the change-logs of
collaborative ontology-engineering projects. We provide a detailed presentation
of the analysis process, describing all the required steps that are necessary
to apply and determine the best fitting Markov chain model. Amongst others, the
model and results allow us to identify structural properties and regularities
as well as predict future actions based on usage sequences. We are specifically
interested in determining the appropriate Markov chain orders which postulate
on how many previous actions future ones depend on. To demonstrate the
practical usefulness of the extracted Markov chains we conduct sequential
pattern analyses on a large-scale collaborative ontology-engineering dataset,
the International Classification of Diseases in its 11th revision. To further
expand on the usefulness of the presented analysis, we show that the collected
sequential patterns provide potentially actionable information for
user-interface designers, ontology-engineering tool developers and
project-managers to monitor, coordinate and dynamically adapt to the natural
development processes that occur when collaboratively engineering an ontology.
We hope that presented work will spur a new line of ontology-development tools,
evaluation-techniques and new insights, further taking the interactive nature
of the collaborative ontology-engineering process into consideration.

14 May 2019
We present Scratchy---a modular, lightweight robot built for low budget competition attendances. Its base is mainly built with standard 4040 aluminium profiles and the robot is driven by four mecanum wheels on brushless DC motors. In combination with a laser range finder we use estimated odometry -- which is calculated by encoders -- for creating maps using a particle filter. A RGB-D camera is utilized for object detection and pose estimation. Additionally, there is the option to use a 6-DOF arm to grip objects from an estimated pose or generally for manipulation tasks. The robot can be assembled in less than one hour and fits into two pieces of hand luggage or one bigger suitcase. Therefore, it provides a huge advantage for student teams that participate in robot competitions like the European Robotics League or RoboCup. Thus, this keeps the funding required for participation, which is often a big hurdle for student teams to overcome, low. The software and additional hardware descriptions are available under: this https URL.

23 Mar 2015

Wikipedia is a community-created encyclopedia that contains information about
notable people from different countries, epochs and disciplines and aims to
document the world's knowledge from a neutral point of view. However, the
narrow diversity of the Wikipedia editor community has the potential to
introduce systemic biases such as gender biases into the content of Wikipedia.
In this paper we aim to tackle a sub problem of this larger challenge by
presenting and applying a computational method for assessing gender bias on
Wikipedia along multiple dimensions. We find that while women on Wikipedia are
covered and featured well in many Wikipedia language editions, the way women
are portrayed starkly differs from the way men are portrayed. We hope our work
contributes to increasing awareness about gender biases online, and in
particular to raising attention to the different levels in which gender biases
can manifest themselves on the web.

15 May 2019
We present Simitate --- a hybrid benchmarking suite targeting the evaluation of approaches for imitation learning. A dataset containing 1938 sequences where humans perform daily activities in a realistic environment is presented. The dataset is strongly coupled with an integration into a simulator. RGB and depth streams with a resolution of 960540 at 30Hz and accurate ground truth poses for the demonstrator's hand, as well as the object in 6 DOF at 120Hz are provided. Along with our dataset we provide the 3D model of the used environment, labeled object images and pre-trained models. A benchmarking suite that aims at fostering comparability and reproducibility supports the development of imitation learning approaches. Further, we propose and integrate evaluation metrics on assessing the quality of effect and trajectory of the imitation performed in simulation. Simitate is available on our project website: \url{this https URL}.

01 Feb 2017
Homophily can put minority groups at a disadvantage by restricting their
ability to establish links with people from a majority group. This can limit
the overall visibility of minorities in the network. Building on a
Barab\'{a}si-Albert model variation with groups and homophily, we show how the
visibility of minority groups in social networks is a function of (i) their
relative group size and (ii) the presence or absence of homophilic behavior. We
provide an analytical solution for this problem and demonstrate the existence
of asymmetric behavior. Finally, we study the visibility of minority groups in
examples of real-world social networks: sexual contacts, scientific
collaboration, and scientific citation. Our work presents a foundation for
assessing the visibility of minority groups in social networks in which
homophilic or heterophilic behaviour is present.

14 Jan 2020
This paper introduces epistemic graphs as a generalization of the epistemic
approach to probabilistic argumentation. In these graphs, an argument can be
believed or disbelieved up to a given degree, thus providing a more
fine--grained alternative to the standard Dung's approaches when it comes to
determining the status of a given argument. Furthermore, the flexibility of the
epistemic approach allows us to both model the rationale behind the existing
semantics as well as completely deviate from them when required. Epistemic
graphs can model both attack and support as well as relations that are neither
support nor attack. The way other arguments influence a given argument is
expressed by the epistemic constraints that can restrict the belief we have in
an argument with a varying degree of specificity. The fact that we can specify
the rules under which arguments should be evaluated and we can include
constraints between unrelated arguments permits the framework to be more
context--sensitive. It also allows for better modelling of imperfect agents,
which can be important in multi--agent applications.

26 Mar 2015
When users interact with the Web today, they leave sequential digital trails on a massive scale. Examples of such human trails include Web navigation, sequences of online restaurant reviews, or online music play lists. Understanding the factors that drive the production of these trails can be useful for e.g., improving underlying network structures, predicting user clicks or enhancing recommendations. In this work, we present a general approach called HypTrails for comparing a set of hypotheses about human trails on the Web, where hypotheses represent beliefs about transitions between states. Our approach utilizes Markov chain models with Bayesian inference. The main idea is to incorporate hypotheses as informative Dirichlet priors and to leverage the sensitivity of Bayes factors on the prior for comparing hypotheses with each other. For eliciting Dirichlet priors from hypotheses, we present an adaption of the so-called (trial) roulette method. We demonstrate the general mechanics and applicability of HypTrails by performing experiments with (i) synthetic trails for which we control the mechanisms that have produced them and (ii) empirical trails stemming from different domains including website navigation, business reviews and online music played. Our work expands the repertoire of methods available for studying human trails on the Web.

01 Jul 2019
It is a strength of graph-based data formats, like RDF, that they are very
flexible with representing data. To avoid run-time errors, program code that
processes highly-flexible data representations exhibits the difficulty that it
must always include the most general case, in which attributes might be
set-valued or possibly not available. The Shapes Constraint Language (SHACL)
has been devised to enforce constraints on otherwise random data structures. We
present our approach, Type checking using SHACL (TyCuS), for type checking code
that queries RDF data graphs validated by a SHACL shape graph. To this end, we
derive SHACL shapes from queries and integrate data shapes and query shapes as
types into a -calculus. We provide the formal underpinnings and a
proof of type safety for TyCuS. A programmer can use our method in order to
process RDF data with simplified, type checked code that will not encounter
run-time errors (with usual exceptions as type checking cannot prevent
accessing empty lists).

20 Dec 2016
The term filter bubble has been coined to describe the situation of online users which---due to filtering algorithms---live in a personalised information universe biased towards their own this http URL this paper we use an agent-based simulation framework to measure the actual risk and impact of filter bubble effects occurring in online communities due to content or author based personalisation algorithms. Observing the strength of filter bubble effects allows for opposing the benefits to the risks of this http URL our simulation we observed, that filter bubble effects occur as soon as users indicate preferences towards certain this http URL also saw, that well connected users are affected much stronger than average or poorly connected users. Finally, our experimental setting indicated that the employed personalisation algorithm based on content features seems to bear a lower risk of filter bubble effects than one performing personalisation based on authors.

31 Dec 2019
Reducing the forces necessary to construct projects like landing pads and
blast walls is possibly one of the major drivers in reducing the costs of
establishing lunar settlements. The interlock drive system generates traction
by penetrating articulated spikes into the ground and by using the natural
strength of the ground for traction. The spikes develop a high pull to weight
ratio and promise good mobility in soft, rocky and steep terrain,
energy-efficient operation, and their design is relatively simple. By
penetrating the ground at regular intervals, the spikes also enable the in-situ
measurement of a variety of ground properties, including penetration
resistance, temperature, and pH. Here we present a concept for a light lunar
bulldozer with interlocking spikes that uses a blade and a ripper to loosen and
move soil over short distances, that maps ground properties in situ and that
uses this information to construct landing pads and blast walls, and to
otherwise interact with the ground in a targeted and efficient manner. Trials
on Mediterranean soil have shown that this concept promises to satisfy many of
the basic requirements expected of a lunar excavator. To better predict
performance in a lunar or Martian environment, experiments on relevant soil
simulants are needed.

30 Dec 2020
Understanding human activities and movements on the Web is not only important for computational social scientists but can also offer valuable guidance for the design of online systems for recommendations, caching, advertising, and personalization. In this work, we demonstrate that people tend to follow routines on the Web, and these repetitive patterns of web visits increase their browsing behavior's achievable predictability. We present an information-theoretic framework for measuring the uncertainty and theoretical limits of predictability of human mobility on the Web. We systematically assess the impact of different design decisions on the measurement. We apply the framework to a web tracking dataset of German internet users. Our empirical results highlight that individual's routines on the Web make their browsing behavior predictable to 85% on average, though the value varies across individuals. We observe that these differences in the users' predictabilities can be explained to some extent by their demographic and behavioral attributes.
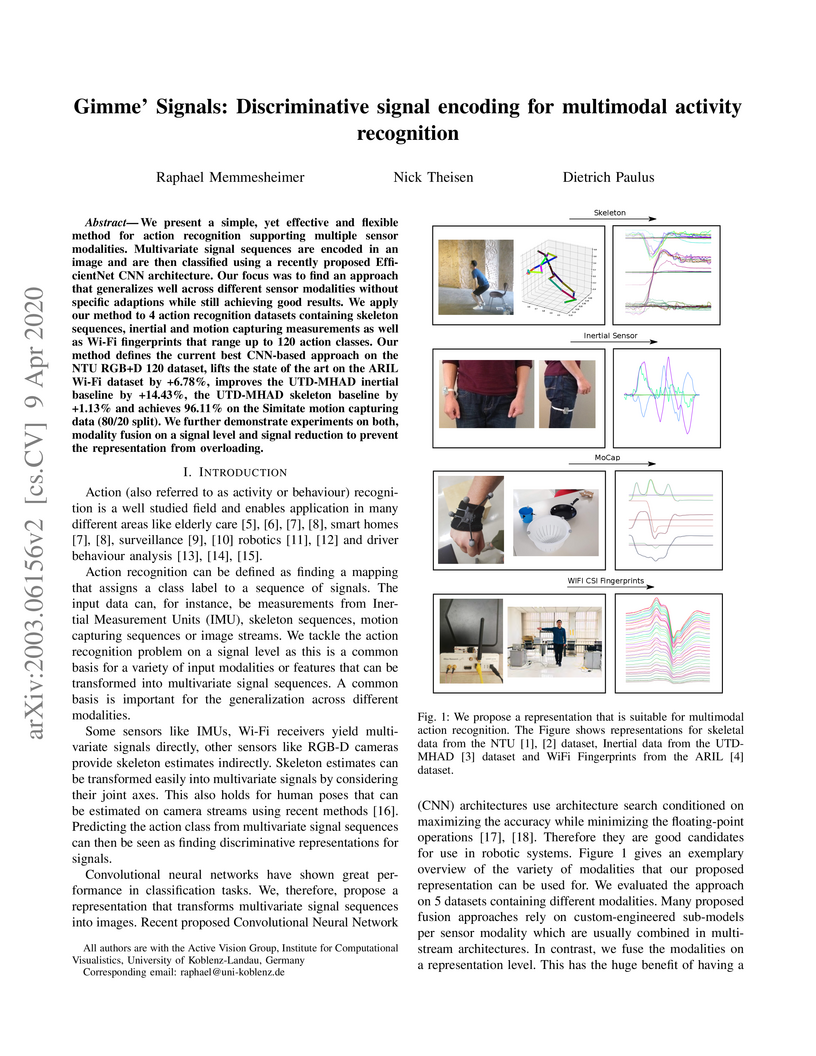
09 Apr 2020
We present a simple, yet effective and flexible method for action recognition supporting multiple sensor modalities. Multivariate signal sequences are encoded in an image and are then classified using a recently proposed EfficientNet CNN architecture. Our focus was to find an approach that generalizes well across different sensor modalities without specific adaptions while still achieving good results. We apply our method to 4 action recognition datasets containing skeleton sequences, inertial and motion capturing measurements as well as \wifi fingerprints that range up to 120 action classes. Our method defines the current best CNN-based approach on the NTU RGB+D 120 dataset, lifts the state of the art on the ARIL Wi-Fi dataset by +6.78%, improves the UTD-MHAD inertial baseline by +14.4%, the UTD-MHAD skeleton baseline by 1.13% and achieves 96.11% on the Simitate motion capturing data (80/20 split). We further demonstrate experiments on both, modality fusion on a signal level and signal reduction to prevent the representation from overloading.

23 Sep 2020
We propose a visualization application, designed for the exploration of human spine simulation data. Our goal is to support research in biomechanical spine simulation and advance efforts to implement simulation-backed analysis in surgical applications. Biomechanical simulation is a state-of-the-art technique for analyzing load distributions of spinal structures. Through the inclusion of patient-specific data, such simulations may facilitate personalized treatment and customized surgical interventions. Difficulties in spine modelling and simulation can be partly attributed to poor result representation, which may also be a hindrance when introducing such techniques into a clinical environment. Comparisons of measurements across multiple similar anatomical structures and the integration of temporal data make commonly available diagrams and charts insufficient for an intuitive and systematic display of results. Therefore, we facilitate methods such as multiple coordinated views, abstraction and focus and context to display simulation outcomes in a dedicated tool. By linking the result data with patient-specific anatomy, we make relevant parameters tangible for clinicians. Furthermore, we introduce new concepts to show the directions of impact force vectors, which were not accessible before. We integrated our toolset into a spine segmentation and simulation pipeline and evaluated our methods with both surgeons and biomechanical researchers. When comparing our methods against standard representations that are currently in use, we found increases in accuracy and speed in data exploration tasks. In a qualitative review, domain experts deemed the tool highly useful when dealing with simulation result data, which typically combines time-dependent patient movement and the resulting force distributions on spinal structures.

24 Jul 2015
In this paper, we present the Polylingual Labeled Topic Model, a model which
combines the characteristics of the existing Polylingual Topic Model and
Labeled LDA. The model accounts for multiple languages with separate topic
distributions for each language while restricting the permitted topics of a
document to a set of predefined labels. We explore the properties of the model
in a two-language setting on a dataset from the social science domain. Our
experiments show that our model outperforms LDA and Labeled LDA in terms of
their held-out perplexity and that it produces semantically coherent topics
which are well interpretable by human subjects.
There are no more papers matching your filters at the moment.
