
24 Oct 2025


Researchers from Rice University, University of Minnesota, and Adobe Inc. systematically investigated numerical precision as a source of non-determinism in Large Language Model (LLM) inference. They demonstrated that 16-bit precision (BF16) leads to substantial variability in outputs and performance, even under greedy decoding, and proposed LayerCast, a hybrid precision inference pipeline that achieves FP32-level reproducibility with reduced memory usage.

10 Oct 2025



An empirical study clarifies the impact of memory addition and deletion on the long-term performance of Large Language Model (LLM) agents, identifying the "experience-following property" and demonstrating how reliable trajectory evaluators are essential for managing self-generated, noisy experiences to achieve consistent self-improvement.

23 Jun 2025

CAD-GPT, developed at Shanghai Jiao Tong University, synthesizes precise CAD construction sequences from natural language descriptions or single images by integrating a 3D Modeling Spatial Localization Mechanism into Multimodal Large Language Models. The model reduces Chamfer Distance by 48% and Invalidity Ratio by 91% compared to prior methods for image-to-CAD generation, demonstrating enhanced geometric accuracy and reliability.

19 Oct 2025

MuonBP introduces a block-periodic orthogonalization scheme to address the communication overhead of the Muon optimizer in distributed training for large language models. The method achieves an 8% increase in per-iteration throughput and reduces wall-clock time by 10-13% to reach target perplexity, while maintaining or slightly improving validation perplexity compared to baseline Muon.

01 Nov 2025


Recent progress in large language model (LLM)-based multi-agent collaboration highlights the power of structured communication in enabling collective intelligence. However, existing methods largely rely on static or graph-based inter-agent topologies, lacking the potential adaptability and flexibility in communication. In this work, we propose a new framework that rethinks multi-agent coordination through a sequential structure rather than a graph structure, offering a significantly larger topology space for multi-agent communication. Our method focuses on two key directions: (1) Next-Agent Prediction, which selects the most suitable agent role at each step, and (2) Next-Context Selection (NCS), which enables each agent to selectively access relevant information from any previous step. Together, these components construct task-adaptive communication pipelines that support both role flexibility and global information flow. Extensive evaluations across multiple benchmarks demonstrate that our approach achieves superior performance while substantially reducing communication overhead.

23 Sep 2025
Multimodal intent recognition (MMIR) suffers from weak semantic grounding and poor robustness under noisy or rare-class conditions. We propose MVCL-DAF++, which extends MVCL-DAF with two key modules: (1) Prototype-aware contrastive alignment, aligning instances to class-level prototypes to enhance semantic consistency; and (2) Coarse-to-fine attention fusion, integrating global modality summaries with token-level features for hierarchical cross-modal interaction. On MIntRec and MIntRec2.0, MVCL-DAF++ achieves new state-of-the-art results, improving rare-class recognition by +1.05\% and +4.18\% WF1, respectively. These results demonstrate the effectiveness of prototype-guided learning and coarse-to-fine fusion for robust multimodal understanding. The source code is available at this https URL.

07 Aug 2025


With the rapid evolution of large language models (LLM), reinforcement learning (RL) has emerged as a pivotal technique for code generation and optimization in various domains. This paper presents a systematic survey of the application of RL in code optimization and generation, highlighting its role in enhancing compiler optimization, resource allocation, and the development of frameworks and tools. Subsequent sections first delve into the intricate processes of compiler optimization, where RL algorithms are leveraged to improve efficiency and resource utilization. The discussion then progresses to the function of RL in resource allocation, emphasizing register allocation and system optimization. We also explore the burgeoning role of frameworks and tools in code generation, examining how RL can be integrated to bolster their capabilities. This survey aims to serve as a comprehensive resource for researchers and practitioners interested in harnessing the power of RL to advance code generation and optimization techniques.

28 May 2024

A comprehensive benchmark of zeroth-order (ZO) optimization methods for fine-tuning Large Language Models (LLMs) reveals their significant memory efficiency, particularly for longer sequence lengths. The study demonstrates the critical role of task alignment and introduces novel techniques like block-wise ZO optimization, which improves accuracy by reducing gradient estimation variance, and hybrid ZO-FO training, which offers flexible memory-performance trade-offs.

22 May 2025

Investigating large language models, researchers from Case Western Reserve University and collaborators demonstrate that a model's long-context capacity fundamentally underpins its reasoning ability. They show that enhancing context length prior to reasoning fine-tuning, a proposed 'Recipe for Reasoning Fine-Tuning,' significantly improves performance on mathematical benchmarks like MATH500 and AIME.

14 Dec 2021

Federated Learning (FL) is a method of training machine learning models on
private data distributed over a large number of possibly heterogeneous clients
such as mobile phones and IoT devices. In this work, we propose a new federated
learning framework named HeteroFL to address heterogeneous clients equipped
with very different computation and communication capabilities. Our solution
can enable the training of heterogeneous local models with varying computation
complexities and still produce a single global inference model. For the first
time, our method challenges the underlying assumption of existing work that
local models have to share the same architecture as the global model. We
demonstrate several strategies to enhance FL training and conduct extensive
empirical evaluations, including five computation complexity levels of three
model architecture on three datasets. We show that adaptively distributing
subnetworks according to clients' capabilities is both computation and
communication efficient.

30 Aug 2025
Parallel Application of Slitless Spectroscopy to Analyze Galaxy Evolution (PASSAGE): Survey Overview
Parallel Application of Slitless Spectroscopy to Analyze Galaxy Evolution (PASSAGE): Survey Overview
 California Institute of Technology
California Institute of Technology University of California, Santa Barbara
University of California, Santa Barbara UCLA
UCLA Chinese Academy of Sciences
Chinese Academy of Sciences University of Oxford
University of Oxford the University of Tokyo
the University of Tokyo University of CopenhagenUniversity of MelbourneUniversity of Ljubljana
University of CopenhagenUniversity of MelbourneUniversity of Ljubljana The University of Texas at Austin
The University of Texas at Austin University of California, San DiegoXiamen University
University of California, San DiegoXiamen University Space Telescope Science Institute
Space Telescope Science Institute Stockholm UniversityRochester Institute of Technology
Stockholm UniversityRochester Institute of Technology Australian National University
Australian National University CEAUniversity of GenevaThe Johns Hopkins UniversityUniversity of Minnesota Twin CitiesNational Astronomical Research Institute of Thailand (NARIT)ARC Centre of Excellence for All Sky Astrophysics in 3 Dimensions (ASTRO 3D)INAF-Istituto di RadioastronomiaInstitut d'Astrophysique de ParisInstitute for Frontiers in Astronomy and Astrophysics, Beijing Normal UniversityIPAC, California Institute of TechnologyInternational Centre for Radio Astronomy Research (ICRAR), University of Western AustraliaMinnesota State University MankatoThe National Astronomical Observatories, Chinese Academy of SciencesUniversit´e Paris Cit´eCosmic Dawn Center(DAWN)Université Paris-SaclayINAF
Osservatorio Astronomico di Padova
CEAUniversity of GenevaThe Johns Hopkins UniversityUniversity of Minnesota Twin CitiesNational Astronomical Research Institute of Thailand (NARIT)ARC Centre of Excellence for All Sky Astrophysics in 3 Dimensions (ASTRO 3D)INAF-Istituto di RadioastronomiaInstitut d'Astrophysique de ParisInstitute for Frontiers in Astronomy and Astrophysics, Beijing Normal UniversityIPAC, California Institute of TechnologyInternational Centre for Radio Astronomy Research (ICRAR), University of Western AustraliaMinnesota State University MankatoThe National Astronomical Observatories, Chinese Academy of SciencesUniversit´e Paris Cit´eCosmic Dawn Center(DAWN)Université Paris-SaclayINAF
Osservatorio Astronomico di PadovaDuring the second half of Cycle 1 of the James Webb Space Telescope (JWST), we conducted the Parallel Application of Slitless Spectroscopy to Analyze Galaxy Evolution (PASSAGE) program. PASSAGE received the largest allocation of JWST observing time in Cycle 1, 591 hours of NIRISS observations to obtain direct near-IR imaging and slitless spectroscopy. About two thirds of these were ultimately executed, to observe 63 high-latitude fields in Pure Parallel mode. These have provided more than ten thousand near-infrared grism spectrograms of faint galaxies.
PASSAGE brings unique advantages in studying galaxy evolution: A) Unbiased spectroscopic search, without prior photometric pre-selection. By including the most numerous galaxies, with low masses and strong emission lines, slitless spectroscopy is the indispensable complement to any pre-targeted spectroscopy; B) The combination of several dozen independent fields to overcome cosmic variance; C) Near-infrared spectral coverage, often spanning the full range from 1.0--2.3 m, with minimal wavelength gaps, to measure multiple diagnostic rest-frame optical lines, minimizing sensitivity to dust reddening; D) JWST's unprecedented spatial resolution, in some cases using two orthogonal grism orientations, to overcome contamination due to blending of overlapping spectra; E) Discovery of rare bright objects especially for detailed JWST followup. PASSAGE data are public immediately, and our team plans to deliver fully-processed high-level data products.
In this PASSAGE overview, we describe the survey and data quality, and present examples of these accomplishments in several areas of current interest in the evolution of emission-line galaxy properties, particularly at low masses.

02 Apr 2025
Top-k selection algorithms are fundamental in a wide range of applications,
including high-performance computing, information retrieval, big data
processing, and neural network model training. In this paper, we present
RTop-K, a highly efficient parallel row-wise top-k selection algorithm
specifically designed for GPUs. RTop-K leverages a binary search-based approach
to optimize row-wise top-k selection, providing a scalable and accelerated
solution. We conduct a detailed analysis of early stopping in our algorithm,
showing that it effectively maintains the testing accuracy of neural network
models while substantially improving performance. Our GPU implementation of
RTop-K demonstrates superior performance over state-of-the-art row-wise top-k
GPU implementations, achieving an average speed-up of up to 11.49 with
early stopping and 7.29 without early stopping. Moreover, RTop-K
accelerates the overall training workflow of MaxK-GNNs, delivering speed-ups
ranging from 11.97% to 33.29% across different models and datasets.
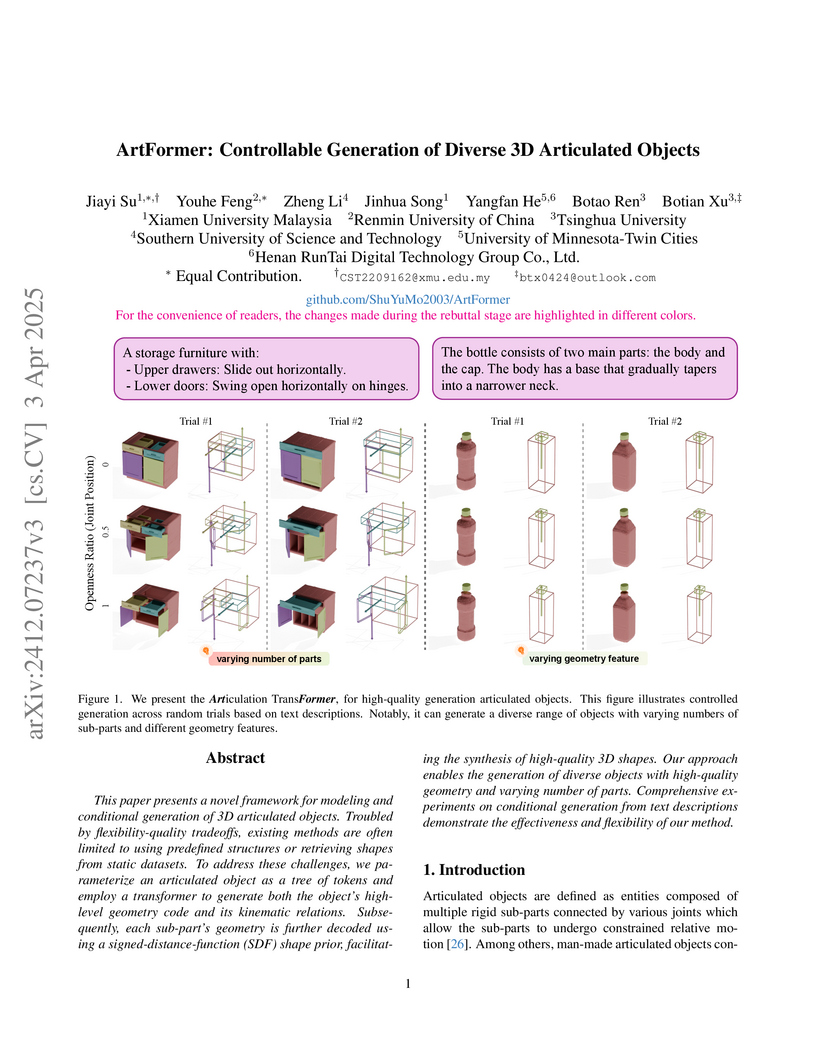
03 Apr 2025



This paper presents a novel framework for modeling and conditional generation
of 3D articulated objects. Troubled by flexibility-quality tradeoffs, existing
methods are often limited to using predefined structures or retrieving shapes
from static datasets. To address these challenges, we parameterize an
articulated object as a tree of tokens and employ a transformer to generate
both the object's high-level geometry code and its kinematic relations.
Subsequently, each sub-part's geometry is further decoded using a
signed-distance-function (SDF) shape prior, facilitating the synthesis of
high-quality 3D shapes. Our approach enables the generation of diverse objects
with high-quality geometry and varying number of parts. Comprehensive
experiments on conditional generation from text descriptions demonstrate the
effectiveness and flexibility of our method.

26 Sep 2025



Zero-shot Dialog State Tracking (zs-DST) is essential for enabling Task-Oriented Dialog Systems (TODs) to generalize to new domains without costly data annotation. A central challenge lies in the semantic misalignment between dynamic dialog contexts and static prompts, leading to inflexible cross-layer coordination, domain interference, and catastrophic forgetting. To tackle this, we propose Hierarchical Collaborative Low-Rank Adaptation (HiCoLoRA), a framework that enhances zero-shot slot inference through robust prompt alignment. It features a hierarchical LoRA architecture for dynamic layer-specific processing (combining lower-layer heuristic grouping and higher-layer full interaction), integrates Spectral Joint Domain-Slot Clustering to identify transferable associations (feeding an Adaptive Linear Fusion Mechanism), and employs Semantic-Enhanced SVD Initialization (SemSVD-Init) to preserve pre-trained knowledge. Experiments on multi-domain datasets MultiWOZ and SGD show that HiCoLoRA outperforms baselines, achieving SOTA in zs-DST. Code is available at this https URL.

17 Sep 2025


Large Language Models (LLMs) can generate creative and engaging narratives from user-specified input, but maintaining coherence and emotional depth throughout these AI-generated stories remains a challenge. In this work, we propose SCORE, a framework for Story Coherence and Retrieval Enhancement, designed to detect and resolve narrative inconsistencies. By tracking key item statuses and generating episode summaries, SCORE uses a Retrieval-Augmented Generation (RAG) approach to identify related episodes and enhance the overall story structure. Experimental results from testing multiple LLM-generated stories demonstrate that SCORE significantly improves the consistency and stability of narrative coherence compared to baseline GPT models, providing a more robust method for evaluating and refining AI-generated narratives.

19 Mar 2025

A framework called SAFER is introduced, which integrates multi-LLM collaboration for task planning with Control Barrier Functions (CBFs) for low-level safety guarantees in robotics. This approach reduces safety violations by an average of 77.5% in simulations and demonstrates robust, safe execution in real-world multi-robot tasks.

24 Sep 2025

Chinese Patronizing and Condescending Language (CPCL) is an implicitly discriminatory toxic speech targeting vulnerable groups on Chinese video platforms. The existing dataset lacks user comments, which are a direct reflection of video content. This undermines the model's understanding of video content and results in the failure to detect some CPLC videos. To make up for this loss, this research reconstructs a new dataset PCLMMPLUS that includes 103k comment entries and expands the dataset size. We also propose the CPCLDetector model with alignment selection and knowledge-enhanced comment content modules. Extensive experiments show the proposed CPCLDetector outperforms the SOTA on PCLMM and achieves higher performance on PCLMMPLUS . CPLC videos are detected more accurately, supporting content governance and protecting vulnerable groups. Code and dataset are available at this https URL.

23 Jul 2025

A critical review systematically assesses ten early electroencephalography (EEG) foundation models (EEG-FMs), synthesizing their methodologies and empirical findings to highlight common design choices and significant research gaps. The analysis offers a principled understanding of current EEG-FM progress and proposes future directions to enhance their translational utility and real-world adoption.

13 Sep 2025

Correlated equilibrium generalizes Nash equilibrium by allowing a central coordinator to guide players' actions through shared recommendations, similar to how routing apps guide drivers. We investigate how a coordinator can learn a correlated equilibrium in convex games where each player minimizes a convex cost function that depends on other players' actions, subject to convex constraints without knowledge of the players' cost functions. We propose a learning framework that learns an approximate correlated equilibrium by actively querying players' regrets, \emph{i.e.}, the cost saved by deviating from the coordinator's recommendations. We first show that a correlated equilibrium in convex games corresponds to a joint action distribution over an infinite joint action space that minimizes all players' regrets. To make the learning problem tractable, we introduce a heuristic that selects finitely many representative joint actions by maximizing their pairwise differences. We then apply Bayesian optimization to learn a probability distribution over the selected joint actions by querying all players' regrets. The learned distribution approximates a correlated equilibrium by minimizing players' regrets. We demonstrate the proposed approach via numerical experiments on multi-user traffic assignment games in a shared transportation network.

22 Jun 2024
The Edge-LLM framework from Georgia Tech and collaborators introduces a holistic co-design approach to enable efficient Large Language Model adaptation on resource-constrained edge devices. It achieves a 2.92x speedup and a 4x memory overhead reduction during each iteration while maintaining comparable task accuracy to vanilla tuning, making on-device LLM finetuning feasible.
There are no more papers matching your filters at the moment.
