 Beihang University
Beihang University
21 Aug 2025

CopyrightShield, developed by researchers from Nanyang Technological University and Beihang University, establishes a defense framework to protect diffusion models from copyright infringement attacks by detecting poisoned training samples and mitigating their influence. The approach achieves an F1-score of 0.665 for poisoned sample detection, which is a 25% improvement over prior attribution methods, and reduces the copyright infringement rate by 56.7% while delaying attack initiation by 115.2%, all without compromising generative quality.

19 Oct 2025
 Chinese Academy of SciencesBeihang University
Chinese Academy of SciencesBeihang University The Hong Kong Polytechnic UniversityBeijing Academy of Artificial IntelligenceZhongguancun AcademyLuxiTechKey Laboratory of Brain Cognition and Brain-inspired Intelligence TechnologyBeijing Key Laboratory of Brain-Inspired General Intelligence Large ModelMetaX Integrated Circuit Co., Ltd.
The Hong Kong Polytechnic UniversityBeijing Academy of Artificial IntelligenceZhongguancun AcademyLuxiTechKey Laboratory of Brain Cognition and Brain-inspired Intelligence TechnologyBeijing Key Laboratory of Brain-Inspired General Intelligence Large ModelMetaX Integrated Circuit Co., Ltd.This research introduces SpikingBrain, a family of brain-inspired large models designed to address the efficiency bottlenecks of Transformer-based LLMs, particularly for long-context processing. The models achieve competitive performance, substantial speedups for long sequences, and stable deployment on non-NVIDIA GPUs, while demonstrating significant potential for energy savings through biologically inspired spiking mechanisms.

06 Dec 2025
 Monash UniversityCSIROChinese Academy of SciencesSichuan University
Monash UniversityCSIROChinese Academy of SciencesSichuan University University of ManchesterBeihang University
University of ManchesterBeihang University Nanjing University
Nanjing University Zhejiang University
Zhejiang University ByteDanceShanghai AI LabHarbin Institute of Technology
ByteDanceShanghai AI LabHarbin Institute of Technology Beijing Jiaotong University
Beijing Jiaotong University Huawei
Huawei Nanyang Technological UniversityNTUBeijing University of Posts and TelecommunicationsUniversity of Sheffield
Nanyang Technological UniversityNTUBeijing University of Posts and TelecommunicationsUniversity of Sheffield TencentAlibabaHuawei CloudStepFunTeleAIOPPOHong Kong University of Science and Technology (Guangzhou)KuaiShouM-A-PChinese Academy of Sciences, Institute of AutomationUOM
TencentAlibabaHuawei CloudStepFunTeleAIOPPOHong Kong University of Science and Technology (Guangzhou)KuaiShouM-A-PChinese Academy of Sciences, Institute of AutomationUOMA comprehensive synthesis of Large Language Models for automated software development covers the entire model lifecycle, from data curation to autonomous agents, and offers practical guidance derived from empirical experiments on pre-training, fine-tuning, and reinforcement learning, alongside a detailed analysis of challenges and future directions.

03 Dec 2025





MemOS, a memory operating system for AI systems, redefines memory as a first-class system resource to address current Large Language Model limitations in long-context reasoning, continuous personalization, and knowledge evolution. This framework unifies heterogeneous memory types (plaintext, activation, parameter) using a standardized MemCube unit, achieving superior performance on benchmarks like LoCoMo and PreFEval, and demonstrating robust, low-latency memory operations.

25 Oct 2025

RoboRefer introduces a 3D-aware Vision-Language Model that achieves precise spatial understanding and generalized multi-step spatial reasoning for robotics through a dedicated depth encoder and a sequential SFT-RFT training strategy. It outperforms state-of-the-art models on spatial referring benchmarks, improving average accuracy by 17.4% on RefSpatial-Bench, and successfully executes long-horizon tasks across diverse real-world robots.

29 Oct 2025



SciReasoner, a scientific reasoning large language model, integrates diverse scientific data representations with natural language across multiple disciplines. The model achieved state-of-the-art performance on 54 scientific tasks and ranked among the top-2 on 101 tasks by employing a three-stage training framework that incorporates multi-representation scientific data.
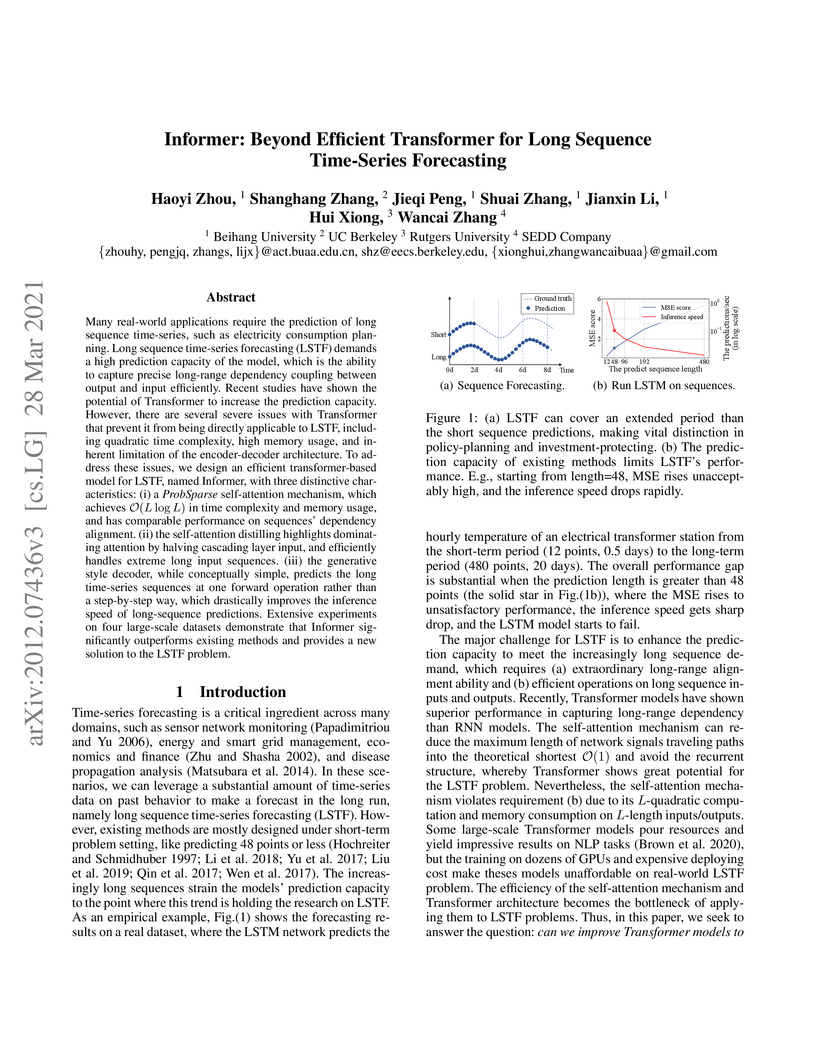
28 Mar 2021



Informer, a Transformer-based model, significantly improves long sequence time-series forecasting (LSTF) by tackling the quadratic complexity of self-attention, high memory usage, and slow dynamic decoding. It achieves substantial reductions in MSE and MAE across various LSTF datasets, demonstrating enhanced prediction capacity and efficiency.

11 Nov 2025

The "Bee" project releases Honey-Data-15M, a meticulously curated high-quality supervised fine-tuning dataset with dual-level Chain-of-Thought reasoning, alongside the open-source HoneyPipe data curation pipeline. This full-stack suite enables Bee-8B, a trained multimodal LLM, to achieve new state-of-the-art performance among fully open models and excel in complex reasoning tasks, scoring 67.0 on MathVerse and 57.3 on CharXiv-RQ.

12 Oct 2025
UniFlow introduces a unified pixel flow tokenizer designed to reconcile the performance trade-off between visual understanding and generation in a single framework. The model achieves state-of-the-art results across 13 benchmarks for both high-level semantic comprehension and high-fidelity pixel reconstruction, providing a versatile foundation for generalist multimodal AI models.

05 Dec 2025
The EditThinker framework enhances instruction-following in any image editor by introducing an iterative reasoning process. It leverages a Multimodal Large Language Model to critique, reflect, and refine editing instructions, leading to consistent performance gains across diverse benchmarks and excelling in complex reasoning tasks.

19 Sep 2025

RLinf introduces a high-performance system for large-scale reinforcement learning, employing a Macro-to-Micro Flow Transformation (M2Flow) paradigm to dynamically optimize execution. The system achieves 1.10x to 1.58x speedup over existing RLHF systems and up to 2.13x speedup in embodied RL training, leading to state-of-the-art model quality in reasoning and embodied tasks.

29 May 2025

Researchers from Peking University, BAAI, and Galbot develop TrackVLA, a unified Vision-Language-Action model that integrates target recognition and trajectory planning within a single LLM backbone for embodied visual tracking, achieving 10 FPS inference speed while outperforming existing methods on zero-shot tracking benchmarks and demonstrating robust sim-to-real transfer on a quadruped robot through joint training on 855K tracking samples and 855K video question-answering samples using an anchor-based diffusion action model that generates continuous waypoint trajectories from natural language instructions.

14 Oct 2025

The advancement of Embodied AI heavily relies on large-scale, simulatable 3D scene datasets characterized by scene diversity and realistic layouts. However, existing datasets typically suffer from limitations in data scale or diversity, sanitized layouts lacking small items, and severe object collisions. To address these shortcomings, we introduce \textbf{InternScenes}, a novel large-scale simulatable indoor scene dataset comprising approximately 40,000 diverse scenes by integrating three disparate scene sources, real-world scans, procedurally generated scenes, and designer-created scenes, including 1.96M 3D objects and covering 15 common scene types and 288 object classes. We particularly preserve massive small items in the scenes, resulting in realistic and complex layouts with an average of 41.5 objects per region. Our comprehensive data processing pipeline ensures simulatability by creating real-to-sim replicas for real-world scans, enhances interactivity by incorporating interactive objects into these scenes, and resolves object collisions by physical simulations. We demonstrate the value of InternScenes with two benchmark applications: scene layout generation and point-goal navigation. Both show the new challenges posed by the complex and realistic layouts. More importantly, InternScenes paves the way for scaling up the model training for both tasks, making the generation and navigation in such complex scenes possible. We commit to open-sourcing the data, models, and benchmarks to benefit the whole community.

27 Aug 2025
NEMORI, a self-organizing agent memory system, was developed by researchers from Tongji University, Shanghai University of Finance and Economics, Beihang University, and Tanka AI, drawing inspiration from cognitive science to address the 'amnesia' of large language models. The system established new state-of-the-art performance on the LoCoMo dataset with an LLM score of 0.744 using gpt-4o-mini, while simultaneously reducing token usage by 88% compared to full context baselines.

10 Oct 2025

Researchers at HKUST and HKUST(GZ) developed PhysToolBench, the first benchmark for evaluating physical tool understanding in Multimodal Large Language Models (MLLMs), revealing that current models possess a superficial grasp of tool use, significantly underperforming humans across various task complexities. The benchmark exposes critical weaknesses, particularly in discerning non-functional tools and the limited capabilities of MLLM backbones within Vision-Language-Action frameworks.

08 Oct 2025
TrackVLA++ advances embodied visual tracking by integrating an efficient spatial reasoning mechanism and a robust, confidence-gated long-term memory into Vision-Language-Action models. It achieves state-of-the-art performance on multiple simulation benchmarks and demonstrates improved real-world tracking robustness against occlusions and distractors.

03 Oct 2025

Researchers from Tsinghua University developed SP-VLA, a unified framework to accelerate Vision-Language-Action (VLA) models by jointly optimizing model scheduling and token pruning based on temporal and spatial redundancies. The approach achieves up to 2.4x speedup and an average performance gain of 6% in simulation environments, enabling VLA models for real-time applications.

21 Oct 2025
Image editing has achieved remarkable progress recently. Modern editing models could already follow complex instructions to manipulate the original content. However, beyond completing the editing instructions, the accompanying physical effects are the key to the generation realism. For example, removing an object should also remove its shadow, reflections, and interactions with nearby objects. Unfortunately, existing models and benchmarks mainly focus on instruction completion but overlook these physical effects. So, at this moment, how far are we from physically realistic image editing? To answer this, we introduce PICABench, which systematically evaluates physical realism across eight sub-dimension (spanning optics, mechanics, and state transitions) for most of the common editing operations (add, remove, attribute change, etc.). We further propose the PICAEval, a reliable evaluation protocol that uses VLM-as-a-judge with per-case, region-level human annotations and questions. Beyond benchmarking, we also explore effective solutions by learning physics from videos and construct a training dataset PICA-100K. After evaluating most of the mainstream models, we observe that physical realism remains a challenging problem with large rooms to explore. We hope that our benchmark and proposed solutions can serve as a foundation for future work moving from naive content editing toward physically consistent realism.
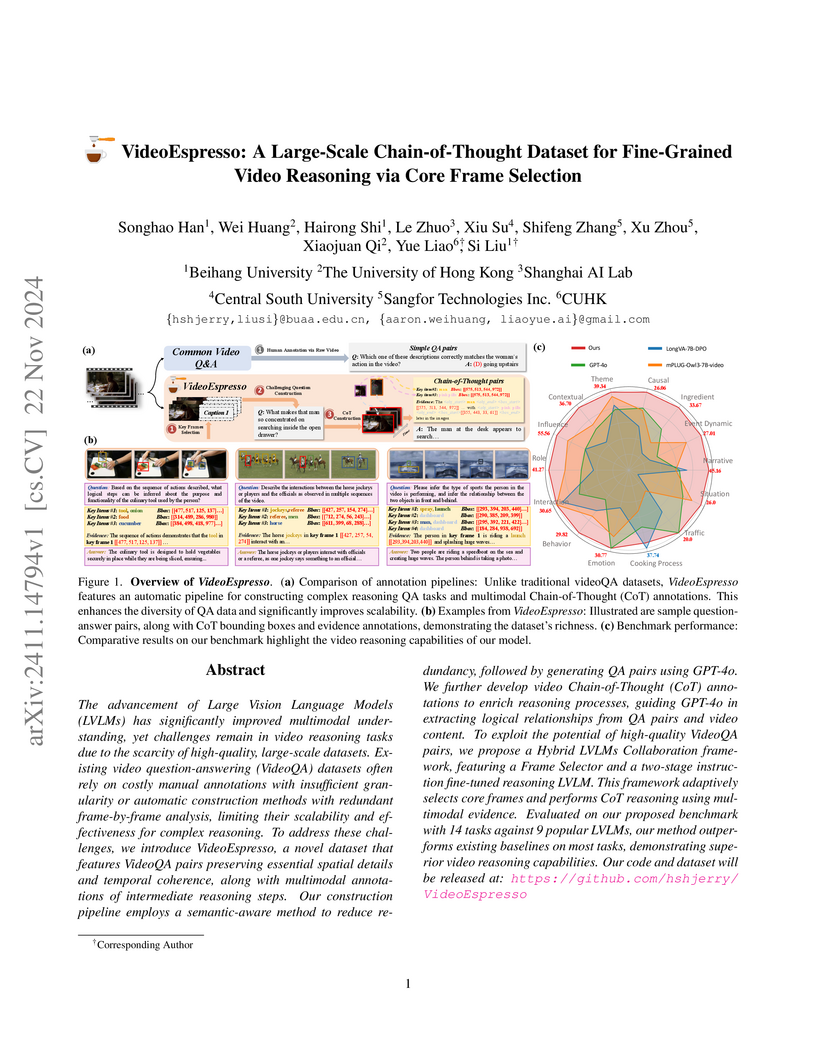
22 Nov 2024
VideoEspresso is a large-scale dataset featuring over 200,000 question-answer pairs with detailed Chain-of-Thought annotations for fine-grained video reasoning. It enables Large Vision Language Models to better understand temporal dynamics and specific spatial-temporal relationships through a novel core frame selection strategy, outperforming existing methods in various video reasoning tasks.

16 Oct 2025

This work from Shanghai Artificial Intelligence Laboratory and Sun Yat-Sen University introduces FakeVLM, a specialized large multimodal model, and FakeClue, a comprehensive dataset, to accurately detect synthetic images and provide natural language explanations for identified artifacts. FakeVLM achieved 98.6% accuracy on FakeClue and 84.3% accuracy on the LOKI benchmark, surpassing human performance in identifying general synthetic content while offering detailed, interpretable explanations.
There are no more papers matching your filters at the moment.
