Ask or search anything...
 Monash University
Monash UniversityA comprehensive synthesis of Large Language Models for automated software development covers the entire model lifecycle, from data curation to autonomous agents, and offers practical guidance derived from empirical experiments on pre-training, fine-tuning, and reinforcement learning, alongside a detailed analysis of challenges and future directions.
View blog
Alibaba's HumanAIGC Team developed WAN-ANIMATE, a unified framework for character animation and replacement that delivers high-fidelity results. The open-sourced model outperforms existing open-source alternatives and is preferred over commercial products like Runway's Act-two and Bytedance's DreamActor-M1 in human evaluations across metrics like identity consistency and expression accuracy.
View blog


 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign UC Berkeley
UC BerkeleyOpenHands is an open-source platform facilitating the development, evaluation, and deployment of generalist AI agents that interact with digital environments by writing code, using command lines, and browsing the web. Its CodeAct agent achieved competitive performance across 15 diverse benchmarks, including software engineering, web browsing, and general assistance tasks, without task-specific modifications.
View blog

 ByteDance
ByteDance Tencent
Tencent
 CUHK
CUHKResearchers from CUHK, HKU, Beihang University, and Alibaba introduced FLUX-Reason-6M, a 6-million-image, reasoning-focused text-to-image dataset, and PRISM-Bench, a comprehensive benchmark for evaluating T2I models. This work provides an open-source resource with 20 million bilingual captions, including Generation Chain-of-Thought prompts, aiming to advance T2I reasoning capabilities and offering a robust evaluation of 19 leading models, highlighting persistent challenges in text rendering and long instruction following.
View blog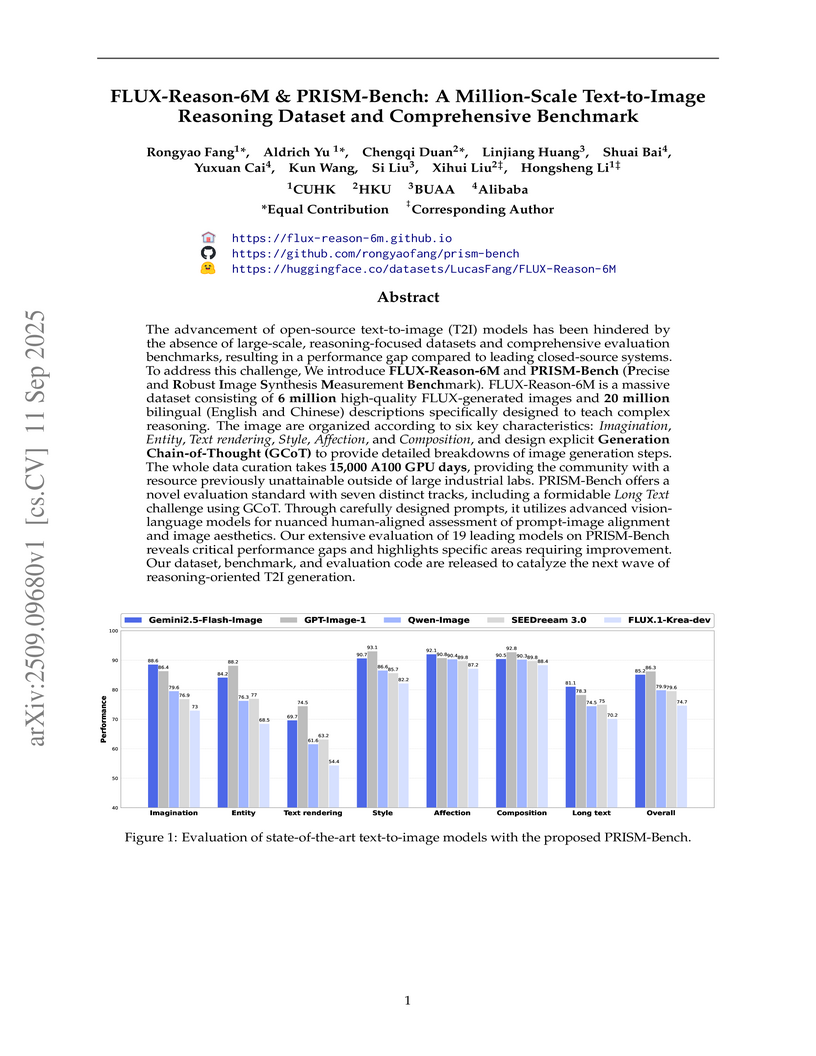
Alibaba Group's ROLL is a comprehensive framework designed for large-scale Reinforcement Learning (RL) training of Large Language Models (LLMs), capable of supporting models over 200 billion parameters. It demonstrated robust scalability by training an MoE model on thousands of GPUs for two weeks uninterrupted and achieved significant performance improvements on RLVR and agentic RL tasks.
View blog
The Qwen Team introduced Qwen3Guard, a suite of multilingual safety guardrail models available in Generative and Stream variants, to enable more flexible, real-time moderation of large language models. The Generative model achieved top performance on 8 out of 14 public English benchmarks, while the Stream variant precisely detected unsafe content at the token level, with an approximate 86% hit rate for the first unsafe token.
View blog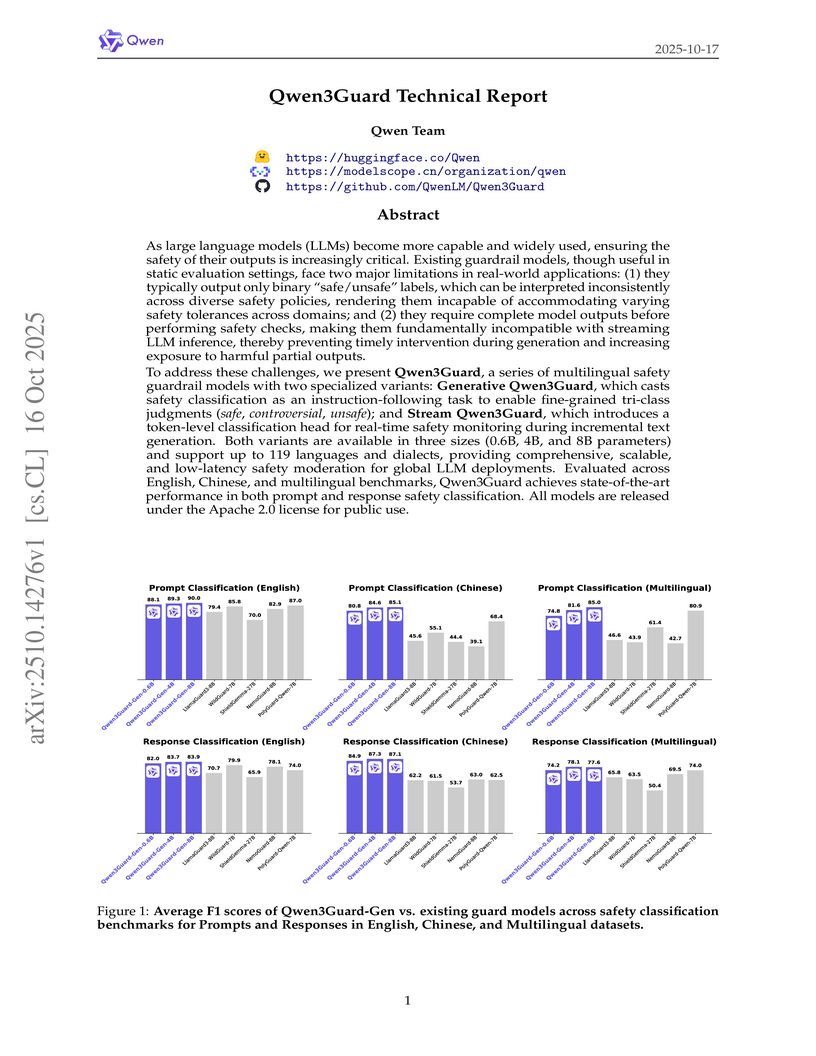
WAN-S2V, from Alibaba's HumanAIGC Team, generates audio-driven human videos that achieve cinematic quality, producing expressive character movements, dynamic camera work, and long-term consistency. The model significantly outperforms existing methods across qualitative and quantitative benchmarks, demonstrating superior visual quality, identity preservation, and motion richness in complex scenarios.
View blog
Researchers at Alibaba developed a Multi-Attribution Learning (MAL) framework that integrates diverse attribution signals to improve Conversion Rate (CVR) prediction. Deployed on Taobao, the system achieved a +2.7% increase in Gross Merchandise Volume (GMV), +1.2% in orders, and +2.6% in Return on Investment (ROI) in online A/B tests.
View blog
 Fudan University
Fudan University Tsinghua University
Tsinghua University
 National University of Singapore
National University of Singapore Zhejiang University
Zhejiang UniversityHealthGPT presents a Medical Large Vision-Language Model that unifies both visual comprehension and generation capabilities by adapting pre-trained large language models with heterogeneous knowledge. The model achieves state-of-the-art results across various medical visual question answering, report generation, super-resolution, and modality conversion tasks.
View blog
RecIS is a PyTorch-native training framework developed by Alibaba that unifies sparse and dense computations for industrial-grade recommendation models. It achieves up to 2x faster training throughput compared to existing solutions and enables the processing of user behavior sequences with up to 1 million interactions.
View blog

 Meta
MetaA new alignment pipeline, MM-RLHF, enhances Multimodal Large Language Models (MLLMs) by improving visual perception, reasoning, dialogue, and trustworthiness. This approach leads to an average 11% gain in conversational abilities and a 57% reduction in unsafe behaviors across various models.
View blog
 Peking University
Peking UniversityResearchers from Peking University and Alibaba developed StreamKV, a training-free framework that enables Video Large Language Models (Video-LLMs) to perform efficient and accurate question-answering in real-time streaming video environments. The framework achieves state-of-the-art accuracy on the StreamingBench benchmark, demonstrating robust performance even with up to 90% KV cache compression while substantially reducing memory consumption and latency.
View blog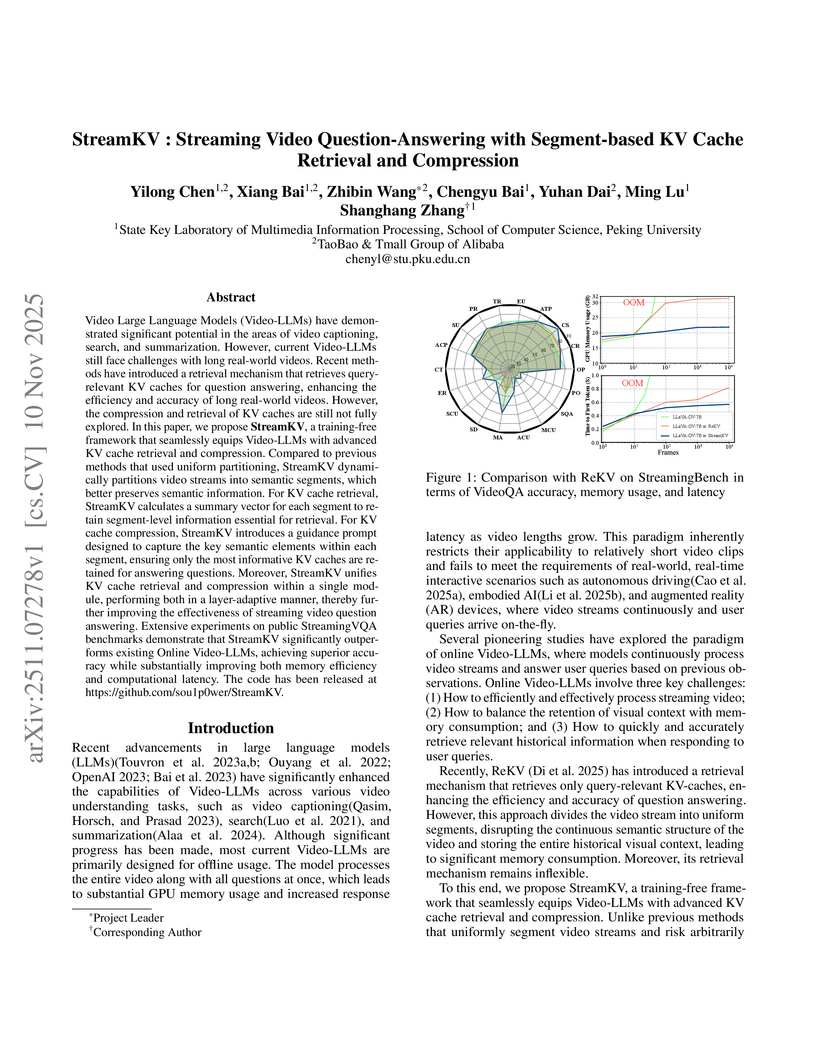
 Shanghai Jiao Tong University
Shanghai Jiao Tong UniversityThe "Global Compression Commander" (GlobalCom²) framework accelerates inference for High-Resolution Large Vision-Language Models (HR-LVLMs) and VideoLLMs by intelligently compressing visual tokens using a global-to-local guidance strategy. It achieves a 90.9% reduction in FLOPs, a 40.0% decrease in peak GPU memory, and a 1.8x inference throughput boost at 10% token retention, while maintaining over 90% of original model performance.
View blog


 Beihang University
Beihang UniversityResearchers from Alibaba, The Chinese University of Hong Kong, and other institutions developed LLaVA-MoD, a framework that leverages Mixture-of-Experts (MoE) architecture and progressive knowledge distillation to create efficient small-scale Multimodal Large Language Models (s-MLLMs). The resulting 2-billion-parameter model achieves state-of-the-art performance among similarly sized models and significantly reduces hallucination, even surpassing larger teacher models and RLHF-based systems, while using only 0.3% of the training data compared to some large MLLMs.
View blog
 University of Toronto
University of Toronto Harvard University
Harvard University
This survey provides a comprehensive and up-to-date review of Graph Neural Networks (GNNs) applied to time series analysis tasks, including forecasting, classification, anomaly detection, and imputation. The paper introduces a unified taxonomy for categorizing GNN-based approaches and highlights key architectural trends, dependency modeling strategies, and critical future research directions in the field.
View blog
 Renmin University of China
Renmin University of ChinaResearchers from the National University of Singapore and collaborators introduced a framework for Multi-Scale Temporal Prediction (MSTP) in dynamic scenes, formalizing the task and creating a new benchmark. Their Incremental Generation and Multi-agent Collaboration (IG-MC) method achieved improved accuracy and consistency in forecasting future states across varying temporal and hierarchical scales, demonstrating robust performance in both general human actions and complex surgical workflows.
View blog