
24 Apr 2025

LLMs are an integral component of retrieval-augmented generation (RAG)
systems. While many studies focus on evaluating the overall quality of
end-to-end RAG systems, there is a gap in understanding the appropriateness of
LLMs for the RAG task. To address this, we introduce Trust-Score, a holistic
metric that evaluates the trustworthiness of LLMs within the RAG framework. Our
results show that various prompting methods, such as in-context learning, fail
to effectively adapt LLMs to the RAG task as measured by Trust-Score.
Consequently, we propose Trust-Align, a method to align LLMs for improved
Trust-Score performance. 26 out of 27 models aligned using Trust-Align
substantially outperform competitive baselines on ASQA, QAMPARI, and ELI5.
Specifically, in LLaMA-3-8b, Trust-Align outperforms FRONT on ASQA (up 12.56),
QAMPARI (up 36.04), and ELI5 (up 17.69). Trust-Align also significantly
enhances models' ability to correctly refuse and provide quality citations. We
also demonstrate the effectiveness of Trust-Align across different open-weight
models, including the LLaMA series (1b to 8b), Qwen-2.5 series (0.5b to 7b),
and Phi3.5 (3.8b). We release our code at
this https URL

04 Aug 2023

Deception detection in conversations is a challenging yet important task, having pivotal applications in many fields such as credibility assessment in business, multimedia anti-frauds, and custom security. Despite this, deception detection research is hindered by the lack of high-quality deception datasets, as well as the difficulties of learning multimodal features effectively. To address this issue, we introduce DOLOS\footnote {The name ``DOLOS" comes from Greek mythology.}, the largest gameshow deception detection dataset with rich deceptive conversations. DOLOS includes 1,675 video clips featuring 213 subjects, and it has been labeled with audio-visual feature annotations. We provide train-test, duration, and gender protocols to investigate the impact of different factors. We benchmark our dataset on previously proposed deception detection approaches. To further improve the performance by fine-tuning fewer parameters, we propose Parameter-Efficient Crossmodal Learning (PECL), where a Uniform Temporal Adapter (UT-Adapter) explores temporal attention in transformer-based architectures, and a crossmodal fusion module, Plug-in Audio-Visual Fusion (PAVF), combines crossmodal information from audio-visual features. Based on the rich fine-grained audio-visual annotations on DOLOS, we also exploit multi-task learning to enhance performance by concurrently predicting deception and audio-visual features. Experimental results demonstrate the desired quality of the DOLOS dataset and the effectiveness of the PECL. The DOLOS dataset and the source codes are available at this https URL.

30 Oct 2025
Multimodal contrastive learning models (e.g., CLIP) can learn high-quality representations from large-scale image-text datasets, while they exhibit significant vulnerabilities to backdoor attacks, raising serious safety concerns. In this paper, we reveal that CLIP's vulnerabilities primarily stem from its tendency to encode features beyond in-dataset predictive patterns, compromising its visual feature resistivity to input perturbations. This makes its encoded features highly susceptible to being reshaped by backdoor triggers. To address this challenge, we propose Repulsive Visual Prompt Tuning (RVPT), a novel defense approach that employs deep visual prompt tuning with a specially designed feature-repelling loss. Specifically, RVPT adversarially repels the encoded features from deeper layers while optimizing the standard cross-entropy loss, ensuring that only predictive features in downstream tasks are encoded, thereby enhancing CLIP's visual feature resistivity against input perturbations and mitigating its susceptibility to backdoor attacks. Unlike existing multimodal backdoor defense methods that typically require the availability of poisoned data or involve fine-tuning the entire model, RVPT leverages few-shot downstream clean samples and only tunes a small number of parameters. Empirical results demonstrate that RVPT tunes only 0.27\% of the parameters in CLIP, yet it significantly outperforms state-of-the-art defense methods, reducing the attack success rate from 89.70\% to 2.76\% against the most advanced multimodal attacks on ImageNet and effectively generalizes its defensive capabilities across multiple datasets.

24 Aug 2024
Concept Bottleneck Models (CBM) map images to human-interpretable concepts
before making class predictions. Recent approaches automate CBM construction by
prompting Large Language Models (LLMs) to generate text concepts and employing
Vision Language Models (VLMs) to score these concepts for CBM training.
However, it is desired to build CBMs with concepts defined by human experts
rather than LLM-generated ones to make them more trustworthy. In this work, we
closely examine the faithfulness of VLM concept scores for such expert-defined
concepts in domains like fine-grained bird species and animal classification.
Our investigations reveal that VLMs like CLIP often struggle to correctly
associate a concept with the corresponding visual input, despite achieving a
high classification performance. This misalignment renders the resulting models
difficult to interpret and less reliable. To address this issue, we propose a
novel Contrastive Semi-Supervised (CSS) learning method that leverages a few
labeled concept samples to activate truthful visual concepts and improve
concept alignment in the CLIP model. Extensive experiments on three benchmark
datasets demonstrate that our method significantly enhances both concept
(+29.95) and classification (+3.84) accuracies yet requires only a fraction of
human-annotated concept labels. To further improve the classification
performance, we introduce a class-level intervention procedure for fine-grained
classification problems that identifies the confounding classes and intervenes
in their concept space to reduce errors.

18 Jun 2025
Researchers from SUTD, DSO National Laboratories, and Lambda Labs developed Ground-GRPO, a two-stage reinforcement learning framework that significantly enhances the groundedness of large language models in RAG settings. The approach improves answer correctness, citation quality, and appropriate refusal behavior by leveraging verifiable outcome-based rewards, showing particular synergy with models possessing strong reasoning capabilities.

04 Oct 2025

We propose a framework for active mapping and exploration that leverages Gaussian splatting for constructing dense maps. Further, we develop a GPU-accelerated motion planning algorithm that can exploit the Gaussian map for real-time navigation. The Gaussian map constructed onboard the robot is optimized for both photometric and geometric quality while enabling real-time situational awareness for autonomy. We show through viewpoint selection experiments that our method yields comparable Peak Signal-to-Noise Ratio (PSNR) and similar reconstruction error to state-of-the-art approaches, while being orders of magnitude faster to compute. In closed-loop physics-based simulation and real-world experiments, our algorithm achieves better map quality (at least 0.8dB higher PSNR and more than 16% higher geometric reconstruction accuracy) than maps constructed by a state-of-the-art method, enabling semantic segmentation using off-the-shelf open-set models. Experiment videos and more details can be found on our project page: this https URL GuIDE/

24 Jul 2025
Automated deception detection is crucial for assisting humans in accurately assessing truthfulness and identifying deceptive behavior. Conventional contact-based techniques, like polygraph devices, rely on physiological signals to determine the authenticity of an individual's statements. Nevertheless, recent developments in automated deception detection have demonstrated that multimodal features derived from both audio and video modalities may outperform human observers on publicly available datasets. Despite these positive findings, the generalizability of existing audio-visual deception detection approaches across different scenarios remains largely unexplored. To close this gap, we present the first cross-domain audio-visual deception detection benchmark, that enables us to assess how well these methods generalize for use in real-world scenarios. We used widely adopted audio and visual features and different architectures for benchmarking, comparing single-to-single and multi-to-single domain generalization performance. To further exploit the impacts using data from multiple source domains for training, we investigate three types of domain sampling strategies, including domain-simultaneous, domain-alternating, and domain-by-domain for multi-to-single domain generalization evaluation. We also propose an algorithm to enhance the generalization performance by maximizing the gradient inner products between modality encoders, named ``MM-IDGM". Furthermore, we proposed the Attention-Mixer fusion method to improve performance, and we believe that this new cross-domain benchmark will facilitate future research in audio-visual deception detection.

19 Aug 2025


Scale variation is a fundamental challenge in computer vision. Objects of the same class can have different sizes, and their perceived size is further affected by the distance from the camera. These variations are local to the objects, i.e., different object sizes may change differently within the same image. To effectively handle scale variations, we present a deep equilibrium canonicalizer (DEC) to improve the local scale equivariance of a model. DEC can be easily incorporated into existing network architectures and can be adapted to a pre-trained model. Notably, we show that on the competitive ImageNet benchmark, DEC improves both model performance and local scale consistency across four popular pre-trained deep-nets, e.g., ViT, DeiT, Swin, and BEiT. Our code is available at this https URL.

03 Nov 2025
A common approach to the de novo molecular generation problem from mass spectra involves a two-stage pipeline: (1) encoding mass spectra into molecular fingerprints, followed by (2) decoding these fingerprints into molecular structures. In our work, we adopt MIST (Goldman et. al., 2023) as the encoder and MolForge (Ucak et. al., 2023) as the decoder, leveraging additional training data to enhance performance. We also threshold the probabilities of each fingerprint bit to focus on the presence of substructures. This results in a tenfold improvement over previous state-of-the-art methods, generating top-1 31% / top-10 40% of molecular structures correctly from mass spectra in MassSpecGym (Bushuiev et. al., 2024). We position this as a strong baseline for future research in de novo molecule elucidation from mass spectra.

16 May 2025
PhiNet v2 introduces a mask-free, brain-inspired vision foundation model for video, utilizing a Transformer architecture and a probabilistically derived objective based on temporal prediction. This model learns robust visual representations from sequential data without relying on strong data augmentation or pixel-level reconstruction, achieving competitive performance on video understanding benchmarks like DAVIS with a J&Fm score of 60.1.

12 Sep 2024



Narrative videos, such as movies, pose significant challenges in video
understanding due to their rich contexts (characters, dialogues, storylines)
and diverse demands (identify who, relationship, and reason). In this paper, we
introduce MovieSeq, a multimodal language model developed to address the wide
range of challenges in understanding video contexts. Our core idea is to
represent videos as interleaved multimodal sequences (including images, plots,
videos, and subtitles), either by linking external knowledge databases or using
offline models (such as whisper for subtitles). Through instruction-tuning,
this approach empowers the language model to interact with videos using
interleaved multimodal instructions. For example, instead of solely relying on
video as input, we jointly provide character photos alongside their names and
dialogues, allowing the model to associate these elements and generate more
comprehensive responses. To demonstrate its effectiveness, we validate
MovieSeq's performance on six datasets (LVU, MAD, Movienet, CMD, TVC, MovieQA)
across five settings (video classification, audio description, video-text
retrieval, video captioning, and video question-answering). The code will be
public at this https URL

29 Oct 2025
We propose an extension of Thompson sampling to optimization problems over function spaces where the objective is a known functional of an unknown operator's output. We assume that queries to the operator (such as running a high-fidelity simulator or physical experiment) are costly, while functional evaluations on the operator's output are inexpensive. Our algorithm employs a sample-then-optimize approach using neural operator surrogates. This strategy avoids explicit uncertainty quantification by treating trained neural operators as approximate samples from a Gaussian process (GP) posterior. We derive regret bounds and theoretical results connecting neural operators with GPs in infinite-dimensional settings. Experiments benchmark our method against other Bayesian optimization baselines on functional optimization tasks involving partial differential equations of physical systems, demonstrating better sample efficiency and significant performance gains.

13 May 2025

The significant progress of quantum sensing technologies offer numerous
radical solutions for measuring a multitude of physical quantities at an
unprecedented precision. Among them, Rydberg atomic quantum receivers (RAQRs)
emerge as an eminent solution for detecting the electric field of radio
frequency (RF) signals, exhibiting great potential in assisting classical
wireless communications and sensing. So far, most experimental studies have
aimed for the proof of physical concepts to reveal its promise, while the
practical signal model of RAQR-aided wireless communications and sensing
remained under-explored. Furthermore, the performance of RAQR-based wireless
receivers and their advantages over classical RF receivers have not been fully
characterized. To fill these gaps, we introduce the RAQR to the wireless
community by presenting an end-to-end reception scheme. We then develop a
corresponding equivalent baseband signal model relying on a realistic reception
flow. Our scheme and model provide explicit design guidance to RAQR-aided
wireless systems. We next study the performance of RAQR-aided wireless systems
based on our model, and compare them to classical RF receivers. The results
show that the RAQR is capable of achieving a substantial received
signal-to-noise ratio (SNR) gain of over decibel (dB) and dB in the
photon shot limit regime and the standard quantum limit regime, respectively.
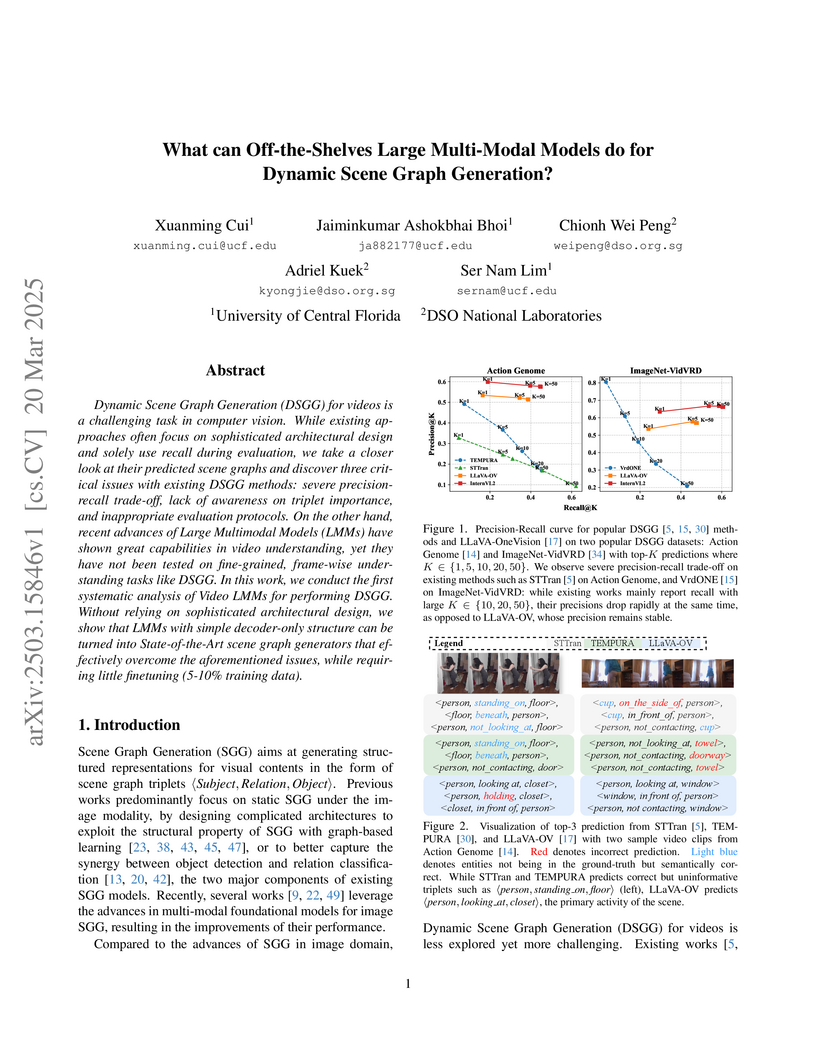
20 Mar 2025

Dynamic Scene Graph Generation (DSGG) for videos is a challenging task in
computer vision. While existing approaches often focus on sophisticated
architectural design and solely use recall during evaluation, we take a closer
look at their predicted scene graphs and discover three critical issues with
existing DSGG methods: severe precision-recall trade-off, lack of awareness on
triplet importance, and inappropriate evaluation protocols. On the other hand,
recent advances of Large Multimodal Models (LMMs) have shown great capabilities
in video understanding, yet they have not been tested on fine-grained,
frame-wise understanding tasks like DSGG. In this work, we conduct the first
systematic analysis of Video LMMs for performing DSGG. Without relying on
sophisticated architectural design, we show that LMMs with simple decoder-only
structure can be turned into State-of-the-Art scene graph generators that
effectively overcome the aforementioned issues, while requiring little
finetuning (5-10% training data).

08 Sep 2025
Currently, Automatic Speech Recognition (ASR) models are deployed in an extensive range of applications. However, recent studies have demonstrated the possibility of adversarial attack on these models which could potentially suppress or disrupt model output. We investigate and verify the robustness of these attacks and explore if it is possible to increase their imperceptibility. We additionally find that by relaxing the optimisation objective from complete suppression to partial suppression, we can further decrease the imperceptibility of the attack. We also explore possible defences against these attacks and show a low-pass filter defence could potentially serve as an effective defence.

16 Aug 2023
Pro-Cap enhances hateful meme detection by leveraging a frozen vision-language model (BLIP-2) in a zero-shot Visual Question Answering manner to generate hate-content-centric image captions. This approach achieves state-of-the-art results across three benchmarks, including FHM, MAMI, and HarM, while reducing computational costs and eliminating reliance on expensive external APIs compared to prior methods.

08 Jan 2024
In a landscape characterized by heightened connectivity and mobility, coupled
with a surge in cardiovascular ailments, the imperative to curtail healthcare
expenses through remote monitoring of cardiovascular health has become more
pronounced. The accurate detection and classification of cardiac arrhythmias
are pivotal for diagnosing individuals with heart irregularities. This study
underscores the feasibility of employing electrocardiograms (ECG) measurements
in the home environment for real-time arrhythmia detection. Presenting a fresh
application for arrhythmia detection, this paper leverages the cutting-edge
You-Only-Look-Once (YOLO)v8 algorithm to categorize single-lead ECG signals. We
introduce a novel loss-modified YOLOv8 model, fine-tuned on the MIT-BIH
arrhythmia dataset, enabling real-time continuous monitoring. The obtained
results substantiate the efficacy of our approach, with the model attaining an
average accuracy of 99.5% and 0.992 mAP@50, and a rapid detection time of 0.002
seconds on an NVIDIA Tesla V100. Our investigation exemplifies the potential of
real-time arrhythmia detection, enabling users to visually interpret the model
output within the comfort of their homes. Furthermore, this study lays the
groundwork for an extension into a real-time explainable AI (XAI) model capable
of deployment in the healthcare sector, thereby significantly advancing the
realm of healthcare solutions.

18 Jan 2025
The Rydberg atomic quantum receivers (RAQR) are emerging quantum precision
sensing platforms designed for receiving radio frequency (RF) signals. It
relies on creation of Rydberg atoms from normal atoms by exciting one or more
electrons to a very high energy level, thereby making the atom sensitive to RF
signals. RAQRs realize RF-to-optical conversions based on light-atom
interactions relying on the so called electromagnetically induced transparency
(EIT) and Aulter-Townes splitting (ATS), so that the desired RF signal can be
read out optically. The large dipole moments of Rydberg atoms associated with
rich choices of Rydberg states and various modulation schemes facilitate an
ultra-high sensitivity ( nV/cm/) and an ultra-broadband
tunability (direct-current to Terahertz). RAQRs also exhibit compelling
scalability and lend themselves to the construction of innovative, compact
receivers. Initial experimental studies have demonstrated their capabilities in
classical wireless communications and sensing. To fully harness their potential
in a wide variety of applications, we commence by outlining the underlying
fundamentals of Rydberg atoms, followed by the principles and schemes of RAQRs.
Then, we overview the state-of-the-art studies from both physics and
communication societies. Furthermore, we conceive Rydberg atomic quantum
single-input single-output (RAQ-SISO) and multiple-input multiple-output
(RAQ-MIMO) schemes for facilitating the integration of RAQRs with classical
wireless systems. Finally, we conclude with a set of potent research
directions.

02 Jun 2025
Rydberg atomic quantum receivers (RAQRs) have emerged as a promising solution
for evolving wireless receivers from the classical to the quantum domain. To
further unleash their great potential in wireless communications, we propose a
flexible architecture for Rydberg atomic quantum multiple-input multiple-output
(RAQ-MIMO) receivers in the multi-user uplink. Then the corresponding signal
model of the RAQ-MIMO system is constructed by paving the way from quantum
physics to classical wireless communications. Explicitly, we outline the
associated operating principles and transmission flow. We also validate the
linearity of our model and its feasible region. Based on our model, we derive
closed-form asymptotic formulas for the ergodic achievable rate (EAR) of both
the maximum-ratio combining (MRC) and zero-forcing (ZF) receivers operating in
uncorrelated fading channels (UFC) and the correlated fading channels (CFC),
respectively. Furthermore, we theoretically characterize the EAR difference
both between the UFC and CFC scenarios, as well as MRC and ZF schemes. More
particularly, we quantify the superiority of RAQ-MIMO receivers over the
classical massive MIMO (M-MIMO) receivers, specifying an increase of $\log_{2}
\Pi\Pi$-fold reduction of the users' transmit power,
and -fold increase of the transmission distance, respectively,
where of the
single-sensor receivers and is the path-loss exponent. Our simulation
results reveal that, compared to classical M-MIMO receivers, our RAQ-MIMO
scheme can either realize bits/s/Hz/user ( bits/s/Hz/user)
higher EAR, or -fold (-fold) lower transmit power, or
alternatively, -fold (-fold) longer distance in free-space
transmissions, in the standard quantum limit (photon shot limit).

11 Feb 2023
Detecting deception by human behaviors is vital in many fields such as custom
security and multimedia anti-fraud. Recently, audio-visual deception detection
attracts more attention due to its better performance than using only a single
modality. However, in real-world multi-modal settings, the integrity of data
can be an issue (e.g., sometimes only partial modalities are available). The
missing modality might lead to a decrease in performance, but the model still
learns the features of the missed modality. In this paper, to further improve
the performance and overcome the missing modality problem, we propose a novel
Transformer-based framework with an Audio-Visual Adapter (AVA) to fuse temporal
features across two modalities efficiently. Extensive experiments conducted on
two benchmark datasets demonstrate that the proposed method can achieve
superior performance compared with other multi-modal fusion methods under
flexible-modal (multiple and missing modalities) settings.
There are no more papers matching your filters at the moment.
