
20 Sep 2024

ControlMath introduces a framework for generating diverse mathematical reasoning data by starting with controlled equations and employing an adaptive selection mechanism to identify challenging problems. This approach significantly enhances the generalization capabilities of large language models across various mathematical domains and improves training efficiency.

08 Oct 2024
This research from Wuhan University and the National University of Singapore provides the first explicit constructions of purely quantum Parameterized Quantum Circuits (PQCs) for multivariate polynomials and smooth functions. The work establishes non-asymptotic approximation error bounds, demonstrating that PQCs can achieve exponentially smaller model sizes and parameter counts compared to deep ReLU neural networks for certain high-dimensional smooth functions.

01 Dec 2024
Preserving Privacy in Software Composition Analysis: A Study of Technical Solutions and Enhancements
Preserving Privacy in Software Composition Analysis: A Study of Technical Solutions and Enhancements
Researchers from HKUST and Tencent's Keen Security Lab developed SAFESCA, an optimized Multi-Party Computation (MPC)-based framework for Software Composition Analysis (SCA) that cryptographically protects both client and vendor data. This framework achieves high accuracy and reduces the computational overhead of MPC-based SCA by 87% compared to naive implementations, making privacy-preserving SCA practical for real-world deployment.

06 Dec 2025
 Monash UniversityCSIRO
Monash UniversityCSIRO Chinese Academy of SciencesSichuan University
Chinese Academy of SciencesSichuan University University of Manchester
University of Manchester Beihang University
Beihang University Nanjing University
Nanjing University Zhejiang University
Zhejiang University ByteDanceShanghai AI LabHarbin Institute of Technology
ByteDanceShanghai AI LabHarbin Institute of Technology Beijing Jiaotong University
Beijing Jiaotong University Huawei
Huawei Nanyang Technological UniversityNTUBeijing University of Posts and TelecommunicationsUniversity of Sheffield
Nanyang Technological UniversityNTUBeijing University of Posts and TelecommunicationsUniversity of Sheffield TencentAlibabaHuawei CloudStepFunTeleAIOPPOHong Kong University of Science and Technology (Guangzhou)KuaiShouM-A-PChinese Academy of Sciences, Institute of AutomationUOM
TencentAlibabaHuawei CloudStepFunTeleAIOPPOHong Kong University of Science and Technology (Guangzhou)KuaiShouM-A-PChinese Academy of Sciences, Institute of AutomationUOMA comprehensive synthesis of Large Language Models for automated software development covers the entire model lifecycle, from data curation to autonomous agents, and offers practical guidance derived from empirical experiments on pre-training, fine-tuning, and reinforcement learning, alongside a detailed analysis of challenges and future directions.

13 Oct 2025


This survey synthesizes the extensive and fragmented field of robot manipulation, providing a comprehensive overview that unifies diverse methodologies and challenges under novel classification systems. It structures the landscape by introducing new taxonomies for high-level planning, low-level learning-based control, and key bottlenecks, while outlining future research directions.

02 Sep 2025


A comprehensive survey organizes research on implicit reasoning in Large Language Models (LLMs) by proposing a new execution-centric taxonomy and consolidating evidence for how multi-step reasoning unfolds internally without generating explicit text. The work highlights critical challenges and future directions to foster more efficient and robust LLM reasoning systems.

25 Jun 2025



This survey provides a comprehensive analysis of 'reasoning Large Language Models,' detailing their transition from intuitive 'System 1' to deliberate 'System 2' thinking. It maps the foundational technologies, core construction methods, and evaluation benchmarks, highlighting their enhanced performance in complex tasks like mathematics and coding while also identifying current limitations and future research directions.

09 Jun 2025
 University of WashingtonWuhan University
University of WashingtonWuhan University University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign UCLAChinese Academy of SciencesShanghai AI Laboratory
UCLAChinese Academy of SciencesShanghai AI Laboratory New York University
New York University National University of Singapore
National University of Singapore Fudan University
Fudan University Georgia Institute of Technology
Georgia Institute of Technology University of Science and Technology of ChinaZhejiang UniversityUniversity of Electronic Science and Technology of China
University of Science and Technology of ChinaZhejiang UniversityUniversity of Electronic Science and Technology of China Renmin University of China
Renmin University of China The Hong Kong Polytechnic University
The Hong Kong Polytechnic University Peking UniversityGriffith UniversityNanyang Technological University
Peking UniversityGriffith UniversityNanyang Technological University Johns Hopkins University
Johns Hopkins University The University of Hong Kong
The University of Hong Kong The Pennsylvania State UniversityA*STARShanghai UniversityUniversity of Illinois at ChicagoSingapore Management University
The Pennsylvania State UniversityA*STARShanghai UniversityUniversity of Illinois at ChicagoSingapore Management University Southern University of Science and Technology
Southern University of Science and Technology HKUSTTencentTeleAISquirrel Ai LearningHong Kong University of Science and Technology (Guangzhou)The University of North Carolina at Chapel HillBen Gurion UniversityCenter for Applied Scientific Computing
HKUSTTencentTeleAISquirrel Ai LearningHong Kong University of Science and Technology (Guangzhou)The University of North Carolina at Chapel HillBen Gurion UniversityCenter for Applied Scientific Computing

This survey paper defines and applies a 'full-stack' safety concept for Large Language Models (LLMs), systematically analyzing safety concerns across their entire lifecycle from data to deployment and commercialization. The collaboration synthesizes findings from over 900 papers, providing a unified taxonomy of attacks and defenses while identifying key insights and future research directions for LLM and LLM-agent safety.

01 Dec 2025
Researchers introduce Prompt-R1, an end-to-end reinforcement learning framework where a small language model agent learns to generate optimal prompts for a large language model environment. This approach yields consistent performance improvements, strong generalization to unseen data, and robust transferability across diverse large language models for complex tasks.

24 Nov 2025

VR-Bench, a new benchmark, is introduced to evaluate the spatial reasoning capabilities of video generation models through diverse maze-solving tasks. The paper demonstrates that fine-tuned video models can perform robust spatial reasoning, often outperforming Vision-Language Models, and exhibit strong generalization and a notable test-time scaling effect.

15 Nov 2025
DexGraspVLA, a vision-language-action framework from Peking University, achieves an unprecedented 90.8% aggregated success rate for dexterous grasping in cluttered scenes across 1,287 unseen object, lighting, and background combinations. The framework leverages foundation models to iteratively transform diverse language and visual inputs into domain-invariant representations, enabling robust closed-loop control and strong zero-shot generalization for language-guided manipulation.

14 Mar 2025

This paper systematically reviews state-of-the-art research on Large Language Model (LLM) agents in education, providing a task-centric taxonomy and examining their technological foundations, applications, and challenges. It details how these agents offer personalized and adaptive support for learning by categorizing them into pedagogical and domain-specific types.

26 Sep 2025
Think-on-Graph 3.0 (ToG-3) introduces a Retrieval-Augmented Generation (RAG) framework that leverages a heterogeneous graph and a Multi-Agent Context Evolution and Retrieval (MACER) mechanism. This approach enables efficient and adaptive LLM reasoning, achieving state-of-the-art performance on complex tasks even with lightweight language models by dynamically refining the knowledge context.

18 Jun 2024
Researchers from USTC, BOSS Zhipin, and HKUST present a comprehensive survey of Large Language Models (LLMs) in recommendation systems, introducing a new taxonomy that differentiates between discriminative and generative LLM paradigms, particularly focusing on the emerging field of Generative LLMs for Recommendation (GLLM4Rec), while outlining key challenges and future research directions.
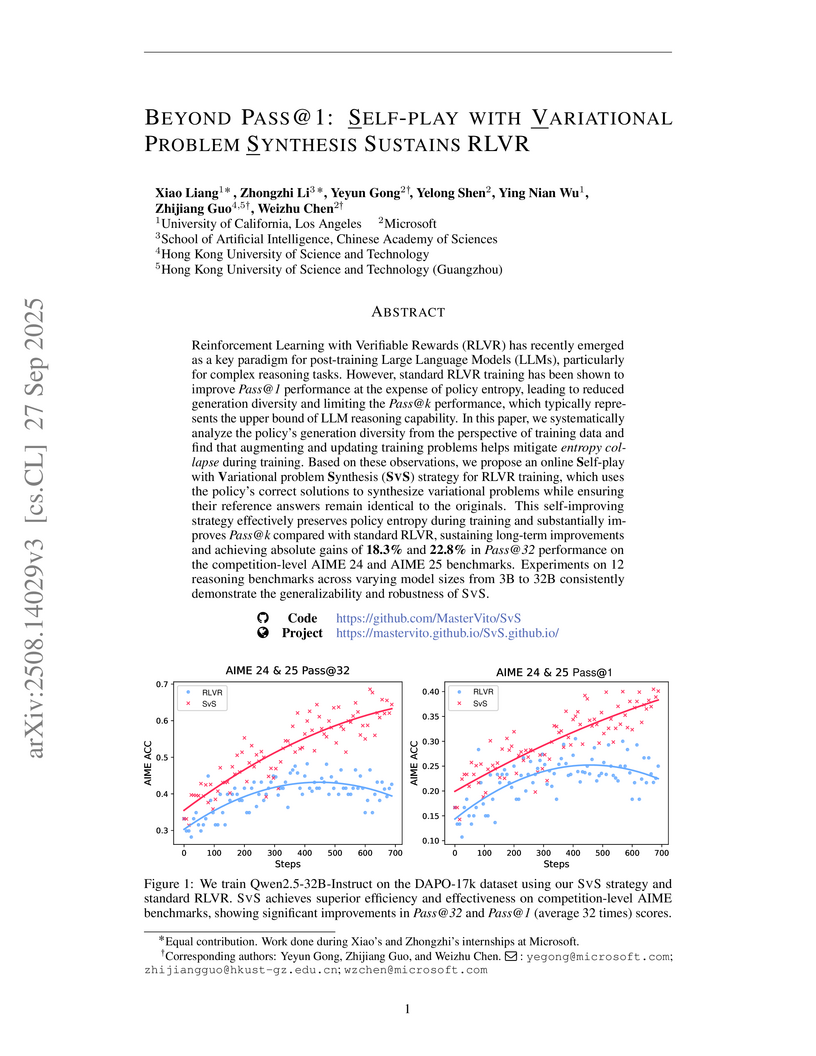
27 Sep 2025
Self-play with Variational problem Synthesis (SVS), an online strategy for Reinforcement Learning with Verifiable Rewards (RLVR), enables Large Language Models to continuously generate and solve diverse, new problems, addressing policy entropy collapse. This method achieved absolute gains of 18.3% and 22.8% in Pass@32 on AIME 24 and AIME 25 benchmarks, and consistently improved Pass@k performance and generalization across various models and tasks.

20 Nov 2024

A comprehensive benchmark for video generation models, VBench++ from S-Lab at Nanyang Technological University and Shanghai Artificial Intelligence Laboratory evaluates performance across 16 distinct dimensions, encompassing text-to-video, image-to-video, and trustworthiness aspects. It provides granular insights into model capabilities and limitations, such as the trade-off between temporal consistency and motion, and challenges in compositional understanding.

25 Aug 2025
Researchers from HKUST (Guangzhou) and University of Surrey conducted a systematic survey on controllable speech synthesis (TTS) methods, focusing on the impact of Large Language Models (LLMs) and diffusion models. The survey provides a comprehensive taxonomy of architectures and control strategies, identifies current challenges like fine-grained control, and proposes future research directions.

20 Oct 2025
ConsistEdit introduces the first training-free attention control method specifically for Multi-Modal Diffusion Transformers (MM-DiT), enabling highly consistent and precise text-guided visual editing across both images and videos. The method achieves state-of-the-art performance by allowing strong, prompt-aligned edits while preserving structural integrity and content fidelity in unedited regions, alongside fine-grained control over consistency.

23 Sep 2025
Tianjin UniversityHuawei Noah’s Ark LabChinese Academy of Sciences Imperial College London
Imperial College London Sun Yat-Sen UniversityUniversity of Manchester
Sun Yat-Sen UniversityUniversity of Manchester University College LondonTongji University
University College LondonTongji University Shanghai Jiao Tong UniversityNanjing University
Shanghai Jiao Tong UniversityNanjing University Tsinghua UniversityPeking University
Tsinghua UniversityPeking University King’s College LondonTU DarmstadtPengcheng LaboratoryHong Kong University of Science and Technology (Guangzhou)
King’s College LondonTU DarmstadtPengcheng LaboratoryHong Kong University of Science and Technology (Guangzhou)
Chinese Academy of SciencesImperial College LondonSun Yat-Sen UniversityUniversity of ManchesterUniversity College LondonTongji UniversityShanghai Jiao Tong UniversityNanjing UniversityTsinghua UniversityPeking UniversityKing’s College LondonTU DarmstadtPengcheng LaboratoryHong Kong University of Science and Technology (Guangzhou)
Researchers from a global consortium, including Tianjin University and Huawei Noah’s Ark Lab, developed Embodied Arena, a comprehensive platform for evaluating Embodied AI agents, featuring a systematic capability taxonomy and an automated, LLM-driven data generation pipeline. This platform integrates over 22 benchmarks and 30 models, revealing that specialized embodied models often outperform general models on targeted tasks and identifying object and spatial perception as key performance bottlenecks.

01 May 2025

BrowseComp-ZH introduces the first comprehensive benchmark for evaluating large language models' web browsing and reasoning capabilities in the Chinese information environment. The benchmark reveals consistently low performance across models and underscores the unique challenges of effectively integrating and reconciling retrieved information from the complex Chinese web.
There are no more papers matching your filters at the moment.
