
11 Jun 2025
Creating recipe images is a key challenge in food computing, with applications in culinary education and multimodal recipe assistants. However, existing datasets lack fine-grained alignment between recipe goals, step-wise instructions, and visual content. We present RecipeGen, the first large-scale, real-world benchmark for recipe-based Text-to-Image (T2I), Image-to-Video (I2V), and Text-to-Video (T2V) generation. RecipeGen contains 26,453 recipes, 196,724 images, and 4,491 videos, covering diverse ingredients, cooking procedures, styles, and dish types. We further propose domain-specific evaluation metrics to assess ingredient fidelity and interaction modeling, benchmark representative T2I, I2V, and T2V models, and provide insights for future recipe generation models. Project page is available now.

21 Sep 2023
This work addresses continuous space-time video super-resolution (C-STVSR)
that aims to up-scale an input video both spatially and temporally by any
scaling factors. One key challenge of C-STVSR is to propagate information
temporally among the input video frames. To this end, we introduce a space-time
local implicit neural function. It has the striking feature of learning forward
motion for a continuum of pixels. We motivate the use of forward motion from
the perspective of learning individual motion trajectories, as opposed to
learning a mixture of motion trajectories with backward motion. To ease motion
interpolation, we encode sparsely sampled forward motion extracted from the
input video as the contextual input. Along with a reliability-aware splatting
and decoding scheme, our framework, termed MoTIF, achieves the state-of-the-art
performance on C-STVSR. The source code of MoTIF is available at
this https URL

09 Dec 2020

Chern insulator ferromagnets are characterized by a quantized anomalous Hall effect, and have so far been identified experimentally in magnetically-doped topological insulator (MTI) thin films and in bilayer graphene moir{é} superlattices. We classify Chern insulator ferromagnets as either spin or orbital, depending on whether the orbital magnetization results from spontaneous spin-polarization combined with spin-orbit interactions, as in the MTI case, or directly from spontaneous orbital currents, as in the moir{é} superlattice case. We argue that in a given magnetic state, characterized for example by the sign of the anomalous Hall effect, the magnetization of an orbital Chern insulator will often have opposite signs for weak and weak electrostatic or chemical doping. This property enables pure electrical switching of a magnetic state in the presence of a fixed magnetic field.

19 Nov 2024
A search for an eV-scale sterile neutrino using improved high-energy event reconstruction in IceCube
A search for an eV-scale sterile neutrino using improved high-energy event reconstruction in IceCube
University of CanterburyNational Central University UC Berkeley
UC Berkeley Georgia Institute of TechnologySungkyunkwan UniversityNational Taiwan University
Georgia Institute of TechnologySungkyunkwan UniversityNational Taiwan University University of California, Irvine
University of California, Irvine University of Maryland, College Park
University of Maryland, College Park University of California, San DiegoOhio State UniversityPennsylvania State UniversityLouisiana State University
University of California, San DiegoOhio State UniversityPennsylvania State UniversityLouisiana State University University of Pennsylvania
University of Pennsylvania University of Tokyo
University of Tokyo Lawrence Berkeley National Laboratory
Lawrence Berkeley National Laboratory University of AlbertaUppsala University
University of AlbertaUppsala University University of California, Davis
University of California, Davis Technical University of MunichDeutsches Elektronen-Synchrotron DESY
Technical University of MunichDeutsches Elektronen-Synchrotron DESY MITUniversity of SheffieldChiba UniversityUniversity of GenevaHumboldt-Universität zu BerlinUniversity of DelawareHelmholtz-Zentrum Dresden-Rossendorf (HZDR)University of New MexicoUniversity of AlabamaUniversität HamburgUniversity of Erlangen-NurembergTechnical University of DortmundRuhr-Universität BochumUniversity of AdelaideKarlsruhe Institute of Technology (KIT)University of Texas at ArlingtonUniversité de MonsAlbert-Ludwigs-Universität FreiburgUniversity of Kansas
MITUniversity of SheffieldChiba UniversityUniversity of GenevaHumboldt-Universität zu BerlinUniversity of DelawareHelmholtz-Zentrum Dresden-Rossendorf (HZDR)University of New MexicoUniversity of AlabamaUniversität HamburgUniversity of Erlangen-NurembergTechnical University of DortmundRuhr-Universität BochumUniversity of AdelaideKarlsruhe Institute of Technology (KIT)University of Texas at ArlingtonUniversité de MonsAlbert-Ludwigs-Universität FreiburgUniversity of Kansas University of California, Santa CruzDrexel UniversityUniversity of Hawai’iUniversity of WuppertalNiels Bohr Institute, University of CopenhagenKochi UniversityUniversity of MainzClark Atlanta UniversityUniversity of KlagenfurtUniversity of GhentNational Chiao Tung UniversityUniversity of StockholmUniversity of Wisconsin-River FallsUniversit
Libre de BruxellesRWTH Aachen UniversityUniversity of Wisconsin
Half-width em dash
–MadisonKavli Institute for the Physics and Mathematics of the Universe (IPMU), University of TokyoUniversity of Wisconsin
Half-width em dash
–MilwaukeeVrije Universiteit Brussel
University of California, Santa CruzDrexel UniversityUniversity of Hawai’iUniversity of WuppertalNiels Bohr Institute, University of CopenhagenKochi UniversityUniversity of MainzClark Atlanta UniversityUniversity of KlagenfurtUniversity of GhentNational Chiao Tung UniversityUniversity of StockholmUniversity of Wisconsin-River FallsUniversit
Libre de BruxellesRWTH Aachen UniversityUniversity of Wisconsin
Half-width em dash
–MadisonKavli Institute for the Physics and Mathematics of the Universe (IPMU), University of TokyoUniversity of Wisconsin
Half-width em dash
–MilwaukeeVrije Universiteit Brussel
UC BerkeleyGeorgia Institute of TechnologySungkyunkwan UniversityNational Taiwan UniversityUniversity of California, IrvineUniversity of Maryland, College ParkUniversity of California, San DiegoOhio State UniversityPennsylvania State UniversityLouisiana State UniversityUniversity of PennsylvaniaUniversity of TokyoLawrence Berkeley National LaboratoryUniversity of AlbertaUppsala UniversityUniversity of California, DavisTechnical University of MunichDeutsches Elektronen-Synchrotron DESYMITUniversity of SheffieldChiba UniversityUniversity of GenevaHumboldt-Universität zu BerlinUniversity of DelawareHelmholtz-Zentrum Dresden-Rossendorf (HZDR)University of New MexicoUniversity of AlabamaUniversität HamburgUniversity of Erlangen-NurembergTechnical University of DortmundRuhr-Universität BochumUniversity of AdelaideKarlsruhe Institute of Technology (KIT)University of Texas at ArlingtonUniversité de MonsAlbert-Ludwigs-Universität FreiburgUniversity of KansasUniversity of California, Santa CruzDrexel UniversityUniversity of Hawai’iUniversity of WuppertalNiels Bohr Institute, University of CopenhagenKochi UniversityUniversity of MainzClark Atlanta UniversityUniversity of KlagenfurtUniversity of GhentNational Chiao Tung UniversityUniversity of StockholmUniversity of Wisconsin-River FallsUniversit
Libre de BruxellesRWTH Aachen UniversityUniversity of Wisconsin
Half-width em dash
–MadisonKavli Institute for the Physics and Mathematics of the Universe (IPMU), University of TokyoUniversity of Wisconsin
Half-width em dash
–MilwaukeeVrije Universiteit BrusselThis Letter presents the result of a 3+1 sterile neutrino search using 10.7 years of IceCube data. We analyze atmospheric muon neutrinos that traverse the Earth with energies ranging from 0.5 to 100 TeV, incorporating significant improvements in modeling neutrino flux and detector response compared to earlier studies. Notably, for the first time, we categorize data into starting and through-going events, distinguishing neutrino interactions with vertices inside or outside the instrumented volume, to improve energy resolution. The best-fit point for a 3+1 model is found to be at and eV, which agrees with previous iterations of this study. The result is consistent with the null hypothesis of no sterile neutrinos with a p-value of 3.1\%.
29 Jul 2024
 University of Washington
University of Washington Michigan State UniversityUniversity of CanterburyDESYGeorgia Institute of TechnologySungkyunkwan UniversityUniversity of California, Irvine
Michigan State UniversityUniversity of CanterburyDESYGeorgia Institute of TechnologySungkyunkwan UniversityUniversity of California, Irvine University of CopenhagenOhio State UniversityPennsylvania State University
University of CopenhagenOhio State UniversityPennsylvania State University Columbia UniversityAarhus UniversityUniversity of Pennsylvania
Columbia UniversityAarhus UniversityUniversity of Pennsylvania University of Maryland
University of Maryland University of Wisconsin-MadisonUniversity of AlbertaUniversity of RochesterMITChiba UniversityUniversity of Geneva
University of Wisconsin-MadisonUniversity of AlbertaUniversity of RochesterMITChiba UniversityUniversity of Geneva Karlsruhe Institute of TechnologyUniversity of DelhiUniversität OldenburgNiels Bohr InstituteUniversity of AlabamaUniversity of South DakotaUniversity of California BerkeleyRuhr-Universität BochumUniversity of AdelaideKobe UniversityTechnische Universität DortmundUniversity of KansasUniversity of California, Santa CruzUniversity of California RiversideUniversity of WürzburgUniversität MünsterErlangen Centre for Astroparticle PhysicsUniversity of MainzUniversity of Alaska AnchorageSouthern University and A&M CollegeBartol Research InstituteNational Chiao Tung UniversityUniversität WuppertalDelaware State UniversityOskar Klein CentreTHOUGHTHere's my plan:THINK:1. Scan the list of authors and their numerical affiliations.2. Look at the numbered list of affiliations at the end of the author list (it's cut off, but I'll process what's available).3. Identify the distinct organization names from these affiliations.4. Ensure these are actual organizations and not departments or general terms.Universit
Libre de BruxellesRWTH Aachen University":Vrije Universiteit Brussel
Karlsruhe Institute of TechnologyUniversity of DelhiUniversität OldenburgNiels Bohr InstituteUniversity of AlabamaUniversity of South DakotaUniversity of California BerkeleyRuhr-Universität BochumUniversity of AdelaideKobe UniversityTechnische Universität DortmundUniversity of KansasUniversity of California, Santa CruzUniversity of California RiversideUniversity of WürzburgUniversität MünsterErlangen Centre for Astroparticle PhysicsUniversity of MainzUniversity of Alaska AnchorageSouthern University and A&M CollegeBartol Research InstituteNational Chiao Tung UniversityUniversität WuppertalDelaware State UniversityOskar Klein CentreTHOUGHTHere's my plan:THINK:1. Scan the list of authors and their numerical affiliations.2. Look at the numbered list of affiliations at the end of the author list (it's cut off, but I'll process what's available).3. Identify the distinct organization names from these affiliations.4. Ensure these are actual organizations and not departments or general terms.Universit
Libre de BruxellesRWTH Aachen University":Vrije Universiteit BrusselThe LIGO/Virgo collaboration published the catalogs GWTC-1, GWTC-2.1 and GWTC-3 containing candidate gravitational-wave (GW) events detected during its runs O1, O2 and O3. These GW events can be possible sites of neutrino emission. In this paper, we present a search for neutrino counterparts of 90 GW candidates using IceCube DeepCore, the low-energy infill array of the IceCube Neutrino Observatory. The search is conducted using an unbinned maximum likelihood method, within a time window of 1000 s and uses the spatial and timing information from the GW events. The neutrinos used for the search have energies ranging from a few GeV to several tens of TeV. We do not find any significant emission of neutrinos, and place upper limits on the flux and the isotropic-equivalent energy emitted in low-energy neutrinos. We also conduct a binomial test to search for source populations potentially contributing to neutrino emission. We report a non-detection of a significant neutrino-source population with this test.

02 May 2022
Semantic outdoor scene understanding based on 3D LiDAR point clouds is a challenging task for autonomous driving due to the sparse and irregular data structure. This paper takes advantages of the uneven range distribution of different LiDAR laser beams to propose a range aware instance segmentation network, RangeSeg. RangeSeg uses a shared encoder backbone with two range dependent decoders. A heavy decoder only computes top of a range image where the far and small objects locate to improve small object detection accuracy, and a light decoder computes whole range image for low computational cost. The results are further clustered by the DBSCAN method with a resolution weighted distance function to get instance-level segmentation results. Experiments on the KITTI dataset show that RangeSeg outperforms the state-of-the-art semantic segmentation methods with enormous speedup and improves the instance-level segmentation performance on small and far objects. The whole RangeSeg pipeline meets the real time requirement on NVIDIA\textsuperscript{\textregistered} JETSON AGX Xavier with 19 frames per second in average.

01 Sep 2022

Generating images from hand-drawings is a crucial and fundamental task in content creation. The translation is difficult as there exist infinite possibilities and the different users usually expect different outcomes. Therefore, we propose a unified framework supporting a three-dimensional control over the image synthesis from sketches and strokes based on diffusion models. Users can not only decide the level of faithfulness to the input strokes and sketches, but also the degree of realism, as the user inputs are usually not consistent with the real images. Qualitative and quantitative experiments demonstrate that our framework achieves state-of-the-art performance while providing flexibility in generating customized images with control over shape, color, and realism. Moreover, our method unleashes applications such as editing on real images, generation with partial sketches and strokes, and multi-domain multi-modal synthesis.

07 Jun 2014
We consider the Einstein-Maxwell-dilaton system with an arbitrary kinetic
gauge function and a dilaton potential. A family of analytic solutions is
obtained by the potential reconstruction method. We then study its holographic
dual QCD model. The kinetic gauge function can be fixed by requesting the
linear Regge spectrum of mesons. We calculate the free energy to obtain the
phase diagram of the holographic QCD model.

24 Nov 2020

The chiral symmetry breaking () is one of the most fundamental problems in QCD. In this paper, we calculate quark condensation analytically in a holographic QCD model dual to the Einstein-Maxwell-Dilaton (EMD) system coupled to a probe scalar field. We find that the black hole phase transition in the EMD system seriously affects . At small chemical potential, behaves as a crossover. For large chemical potential , becomes first order with exactly the same transition temperature as the black hole phase transition by a bypass mechanism. The phase diagram we obtained is qualitatively consistent with the recent results from lattice QCD simulations and NJL models.

03 Apr 2021
Although significant progress has been made in room layout estimation, most methods aim to reduce the loss in the 2D pixel coordinate rather than exploiting the room structure in the 3D space. Towards reconstructing the room layout in 3D, we formulate the task of 360 layout estimation as a problem of predicting depth on the horizon line of a panorama. Specifically, we propose the Differentiable Depth Rendering procedure to make the conversion from layout to depth prediction differentiable, thus making our proposed model end-to-end trainable while leveraging the 3D geometric information, without the need of providing the ground truth depth. Our method achieves state-of-the-art performance on numerous 360 layout benchmark datasets. Moreover, our formulation enables a pre-training step on the depth dataset, which further improves the generalizability of our layout estimation model.

19 Aug 2020

A domain adaptive object detector aims to adapt itself to unseen domains that may contain variations of object appearance, viewpoints or backgrounds. Most existing methods adopt feature alignment either on the image level or instance level. However, image-level alignment on global features may tangle foreground/background pixels at the same time, while instance-level alignment using proposals may suffer from the background noise. Different from existing solutions, we propose a domain adaptation framework that accounts for each pixel via predicting pixel-wise objectness and centerness. Specifically, the proposed method carries out center-aware alignment by paying more attention to foreground pixels, hence achieving better adaptation across domains. We demonstrate our method on numerous adaptation settings with extensive experimental results and show favorable performance against existing state-of-the-art algorithms.
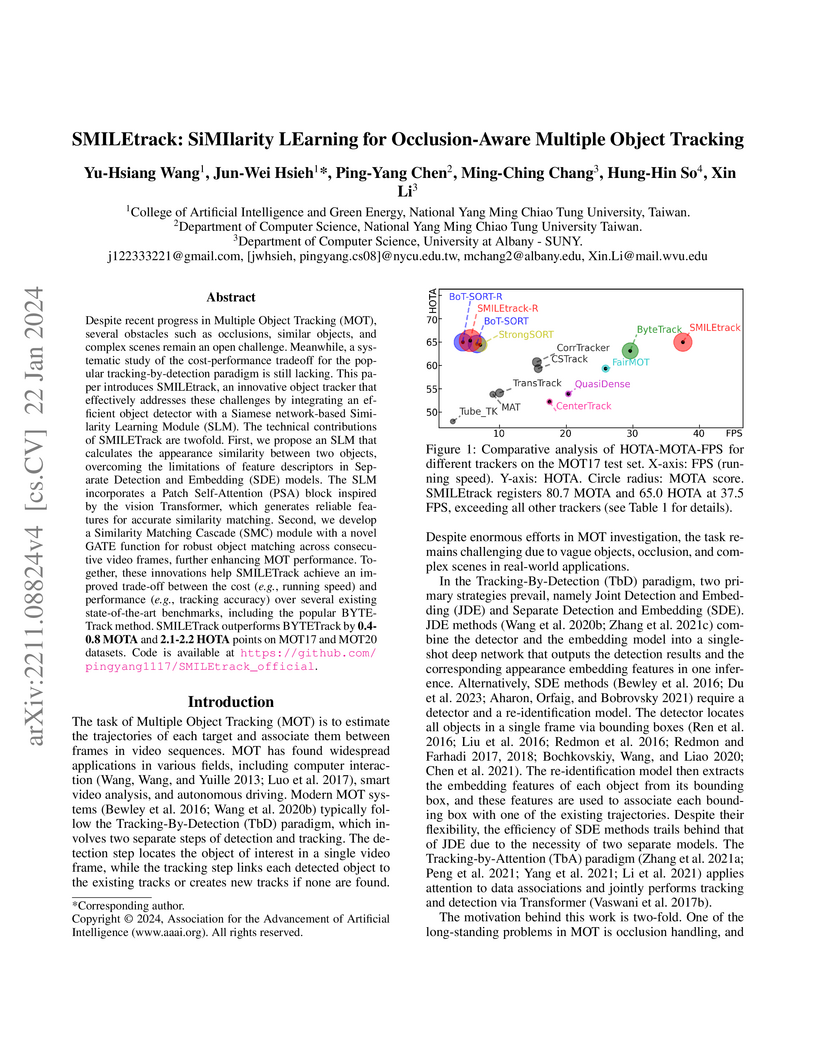
22 Jan 2024
SMILEtrack introduces a Multiple Object Tracking architecture utilizing a novel Similarity Learning Module and a Similarity Matching Cascade with a GATE function for robust occlusion handling and differentiation of similar objects. It achieves 81.1% MOTA and 80.5% IDF1 on MOT17, and 78.2% MOTA and 77.5% IDF1 on MOT20, demonstrating an improved balance between tracking accuracy and inference speed within the Separate Detection and Embedding (SDE) paradigm.

02 Aug 2021
Action-constrained reinforcement learning (RL) is a widely-used approach in
various real-world applications, such as scheduling in networked systems with
resource constraints and control of a robot with kinematic constraints. While
the existing projection-based approaches ensure zero constraint violation, they
could suffer from the zero-gradient problem due to the tight coupling of the
policy gradient and the projection, which results in sample-inefficient
training and slow convergence. To tackle this issue, we propose a learning
algorithm that decouples the action constraints from the policy parameter
update by leveraging state-wise Frank-Wolfe and a regression-based policy
update scheme. Moreover, we show that the proposed algorithm enjoys convergence
and policy improvement properties in the tabular case as well as generalizes
the popular DDPG algorithm for action-constrained RL in the general case.
Through experiments, we demonstrate that the proposed algorithm significantly
outperforms the benchmark methods on a variety of control tasks.

17 Dec 2021
Studying the sensitivity of weight perturbation in neural networks and its
impacts on model performance, including generalization and robustness, is an
active research topic due to its implications on a wide range of machine
learning tasks such as model compression, generalization gap assessment, and
adversarial attacks. In this paper, we provide the first integral study and
analysis for feed-forward neural networks in terms of the robustness in
pairwise class margin and its generalization behavior under weight
perturbation. We further design a new theory-driven loss function for training
generalizable and robust neural networks against weight perturbations.
Empirical experiments are conducted to validate our theoretical analysis. Our
results offer fundamental insights for characterizing the generalization and
robustness of neural networks against weight perturbations.

02 Oct 2020

Estimating the 3D hand pose from a monocular RGB image is important but challenging. A solution is training on large-scale RGB hand images with accurate 3D hand keypoint annotations. However, it is too expensive in practice. Instead, we have developed a learning-based approach to synthesize realistic, diverse, and 3D pose-preserving hand images under the guidance of 3D pose information. We propose a 3D-aware multi-modal guided hand generative network (MM-Hand), together with a novel geometry-based curriculum learning strategy. Our extensive experimental results demonstrate that the 3D-annotated images generated by MM-Hand qualitatively and quantitatively outperform existing options. Moreover, the augmented data can consistently improve the quantitative performance of the state-of-the-art 3D hand pose estimators on two benchmark datasets. The code will be available at this https URL.

05 Jun 2014
We show that each 26D open bosonic Regge string scattering amplitude (RSSA) can be expressed in terms of one single Appell function in the Regge limit. This result enables us to derive infinite number of recurrence relations among RSSA at arbitrary mass levels, which are conjectured to be related to the known SL(5,C) dynamical symmetry of . In addition, we show that these recurrence relations in the Regge limit can be systematically solved so that all RSSA can be expressed in terms of one amplitude. All these results are dual to high energy symmetries of fixed angle string scattering amplitudes discovered previously [4-8].

31 May 2019
Many of the strongest game playing programs use a combination of Monte Carlo
tree search (MCTS) and deep neural networks (DNN), where the DNNs are used as
policy or value evaluators. Given a limited budget, such as online playing or
during the self-play phase of AlphaZero (AZ) training, a balance needs to be
reached between accurate state estimation and more MCTS simulations, both of
which are critical for a strong game playing agent. Typically, larger DNNs are
better at generalization and accurate evaluation, while smaller DNNs are less
costly, and therefore can lead to more MCTS simulations and bigger search trees
with the same budget. This paper introduces a new method called the multiple
policy value MCTS (MPV-MCTS), which combines multiple policy value neural
networks (PV-NNs) of various sizes to retain advantages of each network, where
two PV-NNs f_S and f_L are used in this paper. We show through experiments on
the game NoGo that a combined f_S and f_L MPV-MCTS outperforms single PV-NN
with policy value MCTS, called PV-MCTS. Additionally, MPV-MCTS also outperforms
PV-MCTS for AZ training.

10 Jul 2021
The development of lightweight object detectors is essential due to the
limited computation resources. To reduce the computation cost, how to generate
redundant features plays a significant role. This paper proposes a new
lightweight Convolution method Cross-Stage Lightweight (CSL) Module, to
generate redundant features from cheap operations. In the intermediate
expansion stage, we replaced Pointwise Convolution with Depthwise Convolution
to produce candidate features. The proposed CSL-Module can reduce the
computation cost significantly. Experiments conducted at MS-COCO show that the
proposed CSL-Module can approximate the fitting ability of Convolution-3x3.
Finally, we use the module to construct a lightweight detector CSL-YOLO,
achieving better detection performance with only 43% FLOPs and 52% parameters
than Tiny-YOLOv4.

26 Mar 2019
In this paper we tackle the problem of unsupervised domain adaptation for the task of semantic segmentation, where we attempt to transfer the knowledge learned upon synthetic datasets with ground-truth labels to real-world images without any annotation. With the hypothesis that the structural content of images is the most informative and decisive factor to semantic segmentation and can be readily shared across domains, we propose a Domain Invariant Structure Extraction (DISE) framework to disentangle images into domain-invariant structure and domain-specific texture representations, which can further realize image-translation across domains and enable label transfer to improve segmentation performance. Extensive experiments verify the effectiveness of our proposed DISE model and demonstrate its superiority over several state-of-the-art approaches.

19 Dec 2018
University of CincinnatiNational United UniversityCharles University Beijing Normal UniversityUC Berkeley
Beijing Normal UniversityUC Berkeley University of Science and Technology of ChinaNational Taiwan University
University of Science and Technology of ChinaNational Taiwan University Nanjing University
Nanjing University Tsinghua UniversityNankai UniversityJoint Institute for Nuclear Research
Tsinghua UniversityNankai UniversityJoint Institute for Nuclear Research Yale UniversityEast China University of Science and Technology
Yale UniversityEast China University of Science and Technology The University of Hong Kong
The University of Hong Kong Brookhaven National LaboratoryUniversity of Wisconsin-MadisonLawrence Berkeley National LaboratoryShenzhen University
Brookhaven National LaboratoryUniversity of Wisconsin-MadisonLawrence Berkeley National LaboratoryShenzhen University Virginia TechUniversity of Houston
Virginia TechUniversity of Houston Shandong UniversityTemple UniversityChinese University of Hong KongDongguan University of TechnologyXian Jiaotong UniversityNorth China Electric Power UniversityInstitute of high-energy PhysicsChina Institute of Atomic EnergySiena CollegeNational Chiao Tung UniversitySun Yat-sen (Zhongshan) University
Shandong UniversityTemple UniversityChinese University of Hong KongDongguan University of TechnologyXian Jiaotong UniversityNorth China Electric Power UniversityInstitute of high-energy PhysicsChina Institute of Atomic EnergySiena CollegeNational Chiao Tung UniversitySun Yat-sen (Zhongshan) University
Beijing Normal UniversityUC BerkeleyUniversity of Science and Technology of ChinaNational Taiwan UniversityNanjing UniversityTsinghua UniversityNankai UniversityJoint Institute for Nuclear ResearchYale UniversityEast China University of Science and TechnologyThe University of Hong KongBrookhaven National LaboratoryUniversity of Wisconsin-MadisonLawrence Berkeley National LaboratoryShenzhen UniversityVirginia TechUniversity of HoustonShandong UniversityTemple UniversityChinese University of Hong KongDongguan University of TechnologyXian Jiaotong UniversityNorth China Electric Power UniversityInstitute of high-energy PhysicsChina Institute of Atomic EnergySiena CollegeNational Chiao Tung UniversitySun Yat-sen (Zhongshan) UniversityWe report a measurement of electron antineutrino oscillation from the Daya
Bay Reactor Neutrino Experiment with nearly 4 million reactor
inverse beta decay candidates observed over 1958 days of
data collection. The installation of a Flash-ADC readout system and a special
calibration campaign using different source enclosures reduce uncertainties in
the absolute energy calibration to less than 0.5% for visible energies larger
than 2 MeV. The uncertainty in the cosmogenic Li and He background is
reduced from 45% to 30% in the near detectors. A detailed investigation of the
spent nuclear fuel history improves its uncertainty from 100% to 30%. Analysis
of the relative rates and energy spectra among detectors
yields
and $\Delta
m^2_{32}=(2.471^{+0.068}_{-0.070})\times 10^{-3}~\mathrm{eV}^2$ assuming the
normal hierarchy, and $\Delta m^2_{32}=-(2.575^{+0.068}_{-0.070})\times
10^{-3}~\mathrm{eV}^2$ assuming the inverted hierarchy.
There are no more papers matching your filters at the moment.
