28 Oct 2025

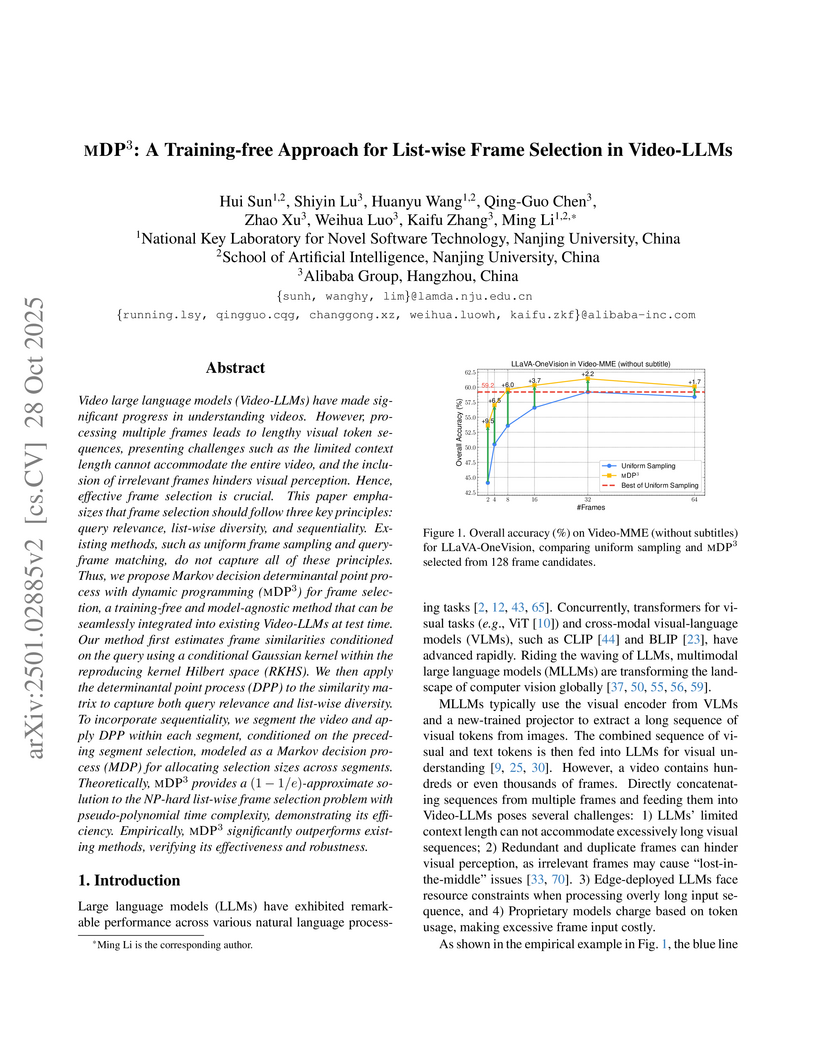
Video large language models (Video-LLMs) have made significant progress in understanding videos. However, processing multiple frames leads to lengthy visual token sequences, presenting challenges such as the limited context length cannot accommodate the entire video, and the inclusion of irrelevant frames hinders visual perception. Hence, effective frame selection is crucial. This paper emphasizes that frame selection should follow three key principles: query relevance, list-wise diversity, and sequentiality. Existing methods, such as uniform frame sampling and query-frame matching, do not capture all of these principles. Thus, we propose Markov decision determinantal point process with dynamic programming (MDP3) for frame selection, a training-free and model-agnostic method that can be seamlessly integrated into existing Video-LLMs. Our method first estimates frame similarities conditioned on the query using a conditional Gaussian kernel within the reproducing kernel Hilbert space~(RKHS). We then apply the determinantal point process~(DPP) to the similarity matrix to capture both query relevance and list-wise diversity. To incorporate sequentiality, we segment the video and apply DPP within each segment, conditioned on the preceding segment selection, modeled as a Markov decision process~(MDP) for allocating selection sizes across segments. Theoretically, MDP3 provides a -approximate solution to the NP-hard list-wise frame selection problem with pseudo-polynomial time complexity, demonstrating its efficiency. Empirically, MDP3 significantly outperforms existing methods, verifying its effectiveness and robustness.

06 Sep 2025


ChinaTravel introduces the first open-ended benchmark for language agents in authentic Chinese travel planning, revealing that pure large language models struggle with complex constraints, while a neuro-symbolic approach significantly improves performance but highlights persistent challenges in natural language to domain-specific language translation.

18 Jun 2025
A systematic and comprehensive review of reward models in deep reinforcement learning is presented, introducing a novel tripartite categorization framework based on source, mechanism, and learning paradigm. The survey unifies fragmented knowledge in the field and highlights the emerging role of foundation models in defining reward signals.

11 Aug 2025
Class-Incremental Learning (CIL) requires a learning system to continually learn new classes without forgetting. Existing pre-trained model-based CIL methods often freeze the pre-trained network and adapt to incremental tasks using additional lightweight modules such as adapters. However, incorrect module selection during inference hurts performance, and task-specific modules often overlook shared general knowledge, leading to errors on distinguishing between similar classes across tasks. To address the aforementioned challenges, we propose integrating Task-Specific and Universal Adapters (TUNA) in this paper. Specifically, we train task-specific adapters to capture the most crucial features relevant to their respective tasks and introduce an entropy-based selection mechanism to choose the most suitable adapter. Furthermore, we leverage an adapter fusion strategy to construct a universal adapter, which encodes the most discriminative features shared across tasks. We combine task-specific and universal adapter predictions to harness both specialized and general knowledge during inference. Extensive experiments on various benchmark datasets demonstrate the state-of-the-art performance of our approach. Code is available at: this https URL

06 Feb 2025
Nanjing University researchers introduce a groundbreaking self-backtracking framework that enables language models to autonomously learn and apply backtracking strategies during reasoning, achieving over 40% accuracy improvements while eliminating the need for external reward models and successfully transforming slow-thinking capabilities into fast-thinking processes.

19 Dec 2024
Network traffic includes data transmitted across a network, such as web browsing and file transfers, and is organized into packets (small units of data) and flows (sequences of packets exchanged between two endpoints). Classifying encrypted traffic is essential for detecting security threats and optimizing network management. Recent advancements have highlighted the superiority of foundation models in this task, particularly for their ability to leverage large amounts of unlabeled data and demonstrate strong generalization to unseen data. However, existing methods that focus on token-level relationships fail to capture broader flow patterns, as tokens, defined as sequences of hexadecimal digits, typically carry limited semantic information in encrypted traffic. These flow patterns, which are crucial for traffic classification, arise from the interactions between packets within a flow, not just their internal structure. To address this limitation, we propose a Multi-Instance Encrypted Traffic Transformer (MIETT), which adopts a multi-instance approach where each packet is treated as a distinct instance within a larger bag representing the entire flow. This enables the model to capture both token-level and packet-level relationships more effectively through Two-Level Attention (TLA) layers, improving the model's ability to learn complex packet dynamics and flow patterns. We further enhance the model's understanding of temporal and flow-specific dynamics by introducing two novel pre-training tasks: Packet Relative Position Prediction (PRPP) and Flow Contrastive Learning (FCL). After fine-tuning, MIETT achieves state-of-the-art (SOTA) results across five datasets, demonstrating its effectiveness in classifying encrypted traffic and understanding complex network behaviors. Code is available at \url{this https URL}.

06 Feb 2024
This work introduces LaMAI (Language Model with Active Inquiry), a framework that empowers large language models to actively seek clarification from users to resolve ambiguous queries. It integrates active learning for intelligent question selection, resulting in significantly improved accuracy and relevance of responses across various natural language processing tasks.

27 Feb 2025

Deep tabular models have demonstrated remarkable success on i.i.d. data,
excelling in a variety of structured data tasks. However, their performance
often deteriorates under temporal distribution shifts, where trends and
periodic patterns are present in the evolving data distribution over time. In
this paper, we explore the underlying reasons for this failure in capturing
temporal dependencies. We begin by investigating the training protocol,
revealing a key issue in how model selection perform. While existing approaches
use temporal ordering for splitting validation set, we show that even a random
split can significantly improve model performance. By minimizing the time lag
between training data and test time, while reducing the bias in validation, our
proposed training protocol significantly improves generalization across various
methods. Furthermore, we analyze how temporal data affects deep tabular
representations, uncovering that these models often fail to capture crucial
periodic and trend information. To address this gap, we introduce a
plug-and-play temporal embedding method based on Fourier series expansion to
learn and incorporate temporal patterns, offering an adaptive approach to
handle temporal shifts. Our experiments demonstrate that this temporal
embedding, combined with the improved training protocol, provides a more
effective and robust framework for learning from temporal tabular data.

26 Sep 2025
Reward design remains a critical bottleneck in visual reinforcement learning (RL) for robotic manipulation. In simulated environments, rewards are conventionally designed based on the distance to a target position. However, such precise positional information is often unavailable in real-world visual settings due to sensory and perceptual limitations. In this study, we propose a method that implicitly infers spatial distances through keypoints extracted from images. Building on this, we introduce Reward Learning with Anticipation Model (ReLAM), a novel framework that automatically generates dense, structured rewards from action-free video demonstrations. ReLAM first learns an anticipation model that serves as a planner and proposes intermediate keypoint-based subgoals on the optimal path to the final goal, creating a structured learning curriculum directly aligned with the task's geometric objectives. Based on the anticipated subgoals, a continuous reward signal is provided to train a low-level, goal-conditioned policy under the hierarchical reinforcement learning (HRL) framework with provable sub-optimality bound. Extensive experiments on complex, long-horizon manipulation tasks show that ReLAM significantly accelerates learning and achieves superior performance compared to state-of-the-art methods.

07 Jun 2024
Large language models (LLMs), including both proprietary and open-source models, have showcased remarkable capabilities in addressing a wide range of downstream tasks. Nonetheless, when it comes to practical Chinese legal tasks, these models fail to meet the actual requirements. Proprietary models do not ensure data privacy for sensitive legal cases, while open-source models demonstrate unsatisfactory performance due to their lack of legal knowledge. To address this problem, we introduce LawGPT, the first open-source model specifically designed for Chinese legal applications. LawGPT comprises two key components: legal-oriented pre-training and legal supervised fine-tuning. Specifically, we employ large-scale Chinese legal documents for legal-oriented pre-training to incorporate legal domain knowledge. To further improve the model's performance on downstream legal tasks, we create a knowledge-driven instruction dataset for legal supervised fine-tuning. Our experimental results demonstrate that LawGPT outperforms the open-source LLaMA 7B model. Our code and resources are publicly available at this https URL and have received 5.7K stars on GitHub.

25 Oct 2025
Reinforcement Learning from Human Feedback (RLHF) has shown remarkable success in aligning Large Language Models (LLMs) with human preferences. Traditional RLHF methods rely on a fixed dataset, which often suffers from limited coverage. To this end, online RLHF has emerged as a promising direction, enabling iterative data collection and refinement. Despite its potential, this paradigm faces a key bottleneck: the requirement to continuously integrate new data into the dataset and re-optimize the model from scratch at each iteration, resulting in computational and storage costs that grow linearly with the number of iterations. In this work, we address this challenge by proposing a one-pass reward modeling method that eliminates the need to store historical data and achieves constant-time updates per iteration. Specifically, we first formalize RLHF as a contextual preference bandit and develop a new algorithm based on online mirror descent with a tailored local norm, replacing the standard maximum likelihood estimation for reward modeling. We then apply it to various online RLHF settings, including passive data collection, active data collection, and deployment-time adaptation. We provide theoretical guarantees showing that our method enhances both statistical and computational efficiency. Finally, we design practical algorithms for LLMs and conduct experiments with the Llama-3-8B-Instruct and Qwen2.5-7B-Instruct models on Ultrafeedback and Mixture2 datasets, validating the effectiveness of our approach.

11 Aug 2024
Code generation has been greatly enhanced by the profound advancements in
Large Language Models (LLMs) recently. Nevertheless, such LLM-based code
generation approaches still struggle to generate error-free code in a few tries
when faced with complex problems. To address this, the prevailing strategy is
to sample a huge number of candidate programs, with the hope of any one in them
could work. However, users of code generation systems usually expect to find a
correct program by reviewing or testing only a small number of code candidates.
Otherwise, the system would be unhelpful. In this paper, we propose Top Pass, a
code ranking approach that identifies potential correct solutions from a large
number of candidates. Top Pass directly optimizes the pass@k loss function,
enhancing the quality at the top of the candidate list. This enables the user
to find the correct solution within as few tries as possible. Experimental
results on four benchmarks indicate that our Top Pass method enhances the
usability of code generation models by producing better ranking results,
particularly achieving a 32.9\% relative improvement in pass@1 on CodeContests
when compared to the state-of-the-art ranking method.

27 May 2025
Network quantization is arguably one of the most practical network
compression approaches for reducing the enormous resource consumption of modern
deep neural networks. They usually require diverse and subtle design choices
for specific architecture and tasks. Instead, the QwT method is a simple and
general approach which introduces lightweight additional structures to improve
quantization. But QwT incurs extra parameters and latency. More importantly,
QwT is not compatible with many hardware platforms. In this paper, we propose
QwT-v2, which not only enjoys all advantages of but also resolves major defects
of QwT. By adopting a very lightweight channel-wise affine compensation (CWAC)
module, QwT-v2 introduces significantly less extra parameters and computations
compared to QwT, and at the same time matches or even outperforms QwT in
accuracy. The compensation module of QwT-v2 can be integrated into quantization
inference engines with little effort, which not only effectively removes the
extra costs but also makes it compatible with most existing hardware platforms.

07 Apr 2024
We investigate online convex optimization in non-stationary environments and choose dynamic regret as the performance measure, defined as the difference between cumulative loss incurred by the online algorithm and that of any feasible comparator sequence. Let be the time horizon and be the path length that essentially reflects the non-stationarity of environments, the state-of-the-art dynamic regret is . Although this bound is proved to be minimax optimal for convex functions, in this paper, we demonstrate that it is possible to further enhance the guarantee for some easy problem instances, particularly when online functions are smooth. Specifically, we introduce novel online algorithms that can exploit smoothness and replace the dependence on in dynamic regret with problem-dependent quantities: the variation in gradients of loss functions, the cumulative loss of the comparator sequence, and the minimum of these two terms. These quantities are at most while could be much smaller in benign environments. Therefore, our results are adaptive to the intrinsic difficulty of the problem, since the bounds are tighter than existing results for easy problems and meanwhile safeguard the same rate in the worst case. Notably, our proposed algorithms can achieve favorable dynamic regret with only one gradient per iteration, sharing the same gradient query complexity as the static regret minimization methods. To accomplish this, we introduce the collaborative online ensemble framework. The proposed framework employs a two-layer online ensemble to handle non-stationarity, and uses optimistic online learning and further introduces crucial correction terms to enable effective collaboration within the meta-base two layers, thereby attaining adaptivity. We believe the framework can be useful for broader problems.

29 Mar 2024
Nanjing University researchers introduce Emotion-Anchored Contrastive Learning (EACL), a framework that employs learnable "emotion anchors" to explicitly incorporate emotion label semantics, enabling models to better distinguish between semantically similar emotions in conversations. EACL achieved state-of-the-art weighted F1 scores of 72.34% on IEMOCAP, 70.31% on MELD, and 41.23% on EmoryNLP, reducing misclassification between nuanced emotion pairs.

10 Feb 2025
Large language models~(LLMs) have recently demonstrated promising performance
in many tasks. However, the high storage and computational cost of LLMs has
become a challenge for deploying LLMs. Weight quantization has been widely used
for model compression, which can reduce both storage and computational cost.
Most existing weight quantization methods for LLMs use a rank-one codebook for
quantization, which results in substantial accuracy loss when the compression
ratio is high. In this paper, we propose a novel weight quantization method,
called low-rank codebook based quantization~(LCQ), for LLMs. LCQ adopts a
low-rank codebook, the rank of which can be larger than one, for quantization.
Experiments show that LCQ can achieve better accuracy than existing methods
with a negligibly extra storage cost.

09 Mar 2023
Federated learning (FL) has recently become a hot research topic, in which
Byzantine robustness, communication efficiency and privacy preservation are
three important aspects. However, the tension among these three aspects makes
it hard to simultaneously take all of them into account. In view of this
challenge, we theoretically analyze the conditions that a communication
compression method should satisfy to be compatible with existing
Byzantine-robust methods and privacy-preserving methods. Motivated by the
analysis results, we propose a novel communication compression method called
consensus sparsification (ConSpar). To the best of our knowledge, ConSpar is
the first communication compression method that is designed to be compatible
with both Byzantine-robust methods and privacy-preserving methods. Based on
ConSpar, we further propose a novel FL framework called FedREP, which is
Byzantine-robust, communication-efficient and privacy-preserving. We
theoretically prove the Byzantine robustness and the convergence of FedREP.
Empirical results show that FedREP can significantly outperform
communication-efficient privacy-preserving baselines. Furthermore, compared
with Byzantine-robust communication-efficient baselines, FedREP can achieve
comparable accuracy with the extra advantage of privacy preservation.

16 Jul 2025
In this paper, we present enhanced analysis for sign-based optimization algorithms with momentum updates. Traditional sign-based methods, under the separable smoothness assumption, guarantee a convergence rate of , but they either require large batch sizes or assume unimodal symmetric stochastic noise. To address these limitations, we demonstrate that signSGD with momentum can achieve the same convergence rate using constant batch sizes without additional assumptions. Our analysis, under the standard -smoothness condition, improves upon the result of the prior momentum-based signSGD method by a factor of , where is the problem dimension. Furthermore, we explore sign-based methods with majority vote in distributed settings and show that the proposed momentum-based method yields convergence rates of and , which outperform the previous results of and , respectively. Numerical experiments further validate the effectiveness of the proposed methods.

30 Oct 2023
There are complaints about current machine learning techniques such as the
requirement of a huge amount of training data and proficient training skills,
the difficulty of continual learning, the risk of catastrophic forgetting, the
leaking of data privacy/proprietary, etc. Most research efforts have been
focusing on one of those concerned issues separately, paying less attention to
the fact that most issues are entangled in practice. The prevailing big model
paradigm, which has achieved impressive results in natural language processing
and computer vision applications, has not yet addressed those issues, whereas
becoming a serious source of carbon emissions. This article offers an overview
of the learnware paradigm, which attempts to enable users not need to build
machine learning models from scratch, with the hope of reusing small models to
do things even beyond their original purposes, where the key ingredient is the
specification which enables a trained model to be adequately identified to
reuse according to the requirement of future users who know nothing about the
model in advance.

21 Apr 2016
Deep Pairwise-Supervised Hashing (DPSH) introduces an end-to-end deep learning framework for image retrieval, which jointly learns feature representations and hash codes from raw image pixels using pairwise similarity labels. Experiments demonstrate DPSH consistently outperforms existing state-of-the-art hashing methods across various hash code lengths on benchmark datasets like CIFAR-10 and NUS-WIDE.
There are no more papers matching your filters at the moment.
