Ask or search anything...
 University of Southampton
University of Southampton HKUST
HKUSTResearchers from Hong Kong University of Science and Technology, University of Southampton, Trine University, and Southwest Jiaotong University developed a breast cancer image classification method that integrates an attention-augmented DenseNet with a multi-level transfer learning strategy. The approach achieved patient-level accuracy of 84.3% and image-level accuracy of 84.0% on the BreakHis dataset, while converging faster than baseline models.
View blog

Plan-and-Solve (PS) Prompting, developed by researchers at Singapore Management University and collaborators, enhances zero-shot Chain-of-Thought reasoning in Large Language Models by guiding them through a two-phase process of planning and execution. This method reduces calculation and missing-step errors, achieving accuracy comparable to few-shot methods on arithmetic reasoning tasks and outperforming Zero-shot CoT across multiple domains.
View blog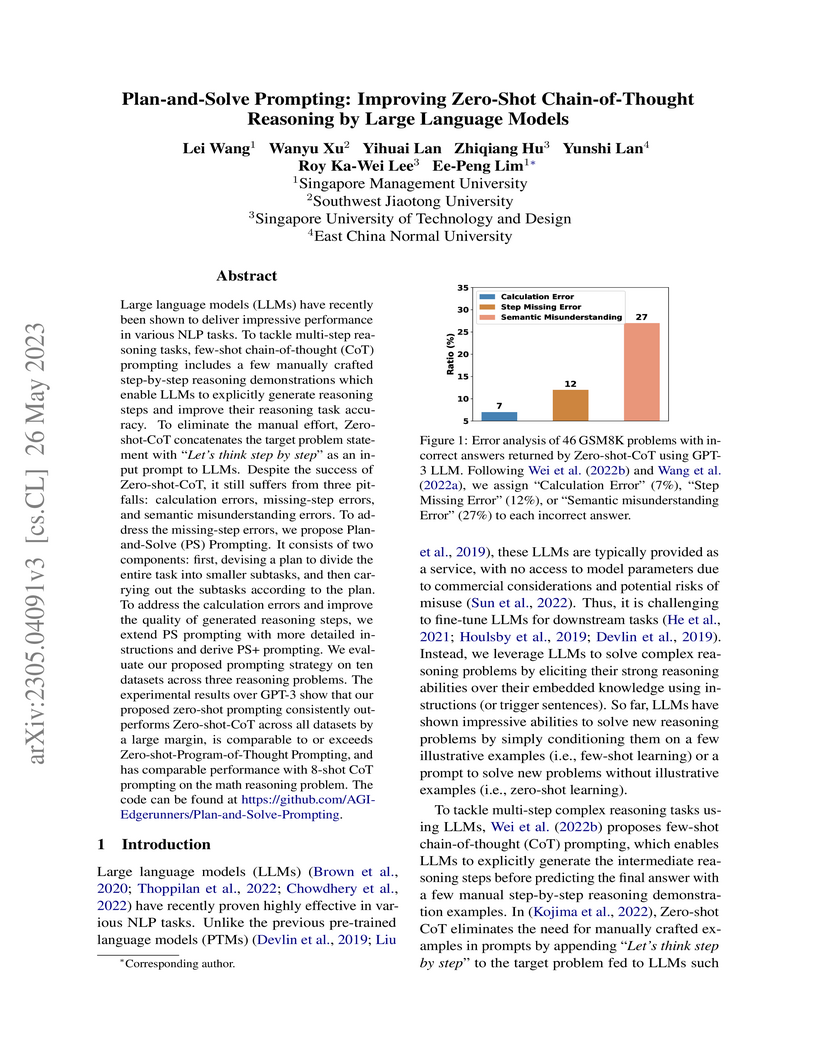
 Nanyang Technological University
Nanyang Technological UniversityThis survey paper provides a comprehensive review of Continual Reinforcement Learning (CRL), introducing a novel taxonomy that categorizes methods based on whether they primarily store and transfer knowledge related to policies, experiences, environment dynamics, or reward signals. It identifies the unique challenges of CRL, such as the stability-plasticity-scalability dilemma, and outlines future research directions and applications across various domains.
View blog
FinBen introduces the first comprehensive open-source evaluation benchmark for large language models in finance, integrating 36 datasets across 24 tasks and seven critical financial aspects. Its extensive evaluation of 15 LLMs reveals strong performance in basic NLP but significant deficiencies in complex reasoning, quantitative forecasting, and robust decision-making, while showcasing advanced models' capabilities in areas like stock trading.
View blog
 Microsoft
MicrosoftCLIP4Clip transfers knowledge from the pre-trained CLIP model to achieve new state-of-the-art results in end-to-end video clip retrieval across five benchmark datasets. The work provides empirical insights into adapting image-language models to video, demonstrating the effectiveness of post-pretraining on video-text data and the importance of temporal modeling.
View blog
Researchers from Ocean University of China and University at Buffalo introduce Forensics Adapter, a lightweight framework adapting CLIP for generalizable face forgery detection by specifically learning blending boundary artifacts. The method achieves an average AUC improvement of approximately 7% over state-of-the-art baselines and a further 1.3% with its multimodal extension, Forensics Adapter++, while being computationally efficient with few trainable parameters.
View blog

 Shanghai Jiao Tong University
Shanghai Jiao Tong University Nanjing University
Nanjing UniversityResearchers from Eastern Institute of Technology, Tencent, and collaborators develop SkipGPT, a dynamic layer pruning framework that introduces token-aware global routing and decoupled pruning policies for MLP versus self-attention modules, achieving over 40% parameter reduction while maintaining or exceeding original model performance through a two-stage training paradigm that first tunes lightweight routers (0.01% parameters) then applies LoRA fine-tuning, with SkipGPT-RT retaining over 90% performance on LLaMA2-7B/13B at 25% pruning and over 95% on LLaMA3.1-8B while outperforming static methods like ShortGPT and dynamic approaches like MoD-D across commonsense reasoning benchmarks, revealing through routing behavior analysis that attention modules exhibit higher redundancy than MLPs and that computational needs shift contextually with later tokens requiring more attention but less MLP processing, challenging the fixed 1:1 attention-MLP architecture design while demonstrating that joint training of routers with pre-trained parameters causes instability compared to their stable disentangled optimization approach.
View blog
 Huazhong University of Science and Technology
Huazhong University of Science and Technology Brown University
Brown University
 Sun Yat-Sen University
Sun Yat-Sen UniversityThe PIXIU framework offers an open-source solution for financial language modeling by releasing a financial instruction tuning dataset (FIT), a fine-tuned financial LLM (FinMA), and a comprehensive evaluation benchmark (FLARE). FinMA, built on LLaMA, generally outperforms other LLMs on financial NLP tasks but shows limitations in quantitative reasoning and financial prediction.
View blog
 Tsinghua University
Tsinghua University
 City University of Hong Kong
City University of Hong Kong Texas A&M University
Texas A&M UniversityResearchers developed a method for controllable 3D outdoor scene generation using scene graphs as intuitive input. The approach leverages a multi-stage diffusion model conditioned by a novel sparse-to-dense architecture, achieving superior control over object quantities and road types (MAE 0.63, Jaccard Index 0.93) while maintaining high scene quality and diversity.
View blog

 Arizona State University
Arizona State UniversitySELF-AUGMENTED VISUAL CONTRASTIVE DECODING (SAVCD) introduces a training-free strategy for Large Vision-Language Models to mitigate hallucinations by employing a query-dependent visual augmentation selection and an entropy-aware adaptive plausibility constraint. The method achieves average performance gains from 6.69% to 18.78% across multiple LVLMs and benchmarks by enhancing factual consistency and relevance.
View blog
A comprehensive review by researchers from TikTok and several universities surveys the advancements and challenges of MultiModal Large Language Models (MM-LLMs) for understanding long videos. The work systematically traces model evolution, highlights the necessity for specialized architectural adaptations and training strategies, and quantitatively compares performance across various video benchmarks.
View blog


Researchers introduced LLM-Adapters, a comprehensive framework and empirical study of parameter-efficient fine-tuning methods for large language models. The work demonstrates that smaller LLMs, when fine-tuned with optimized adapter configurations and high-quality, in-domain data, can achieve performance comparable to or surpassing much larger models on specific downstream tasks like commonsense reasoning.
View blog

 Chinese Academy of Sciences
Chinese Academy of Sciences University of Science and Technology of China
University of Science and Technology of China
 University of Manchester
University of Manchester