
29 Oct 2025


SciReasoner, a scientific reasoning large language model, integrates diverse scientific data representations with natural language across multiple disciplines. The model achieved state-of-the-art performance on 54 scientific tasks and ranked among the top-2 on 101 tasks by employing a three-stage training framework that incorporates multi-representation scientific data.

03 Jun 2025


SparseVLM introduces a text-guided, training-free framework that enhances the inference efficiency of Vision-Language Models by intelligently pruning redundant visual tokens. The method reduces CUDA inference time by 43.1% and FLOPs by 62.8% on LLaVA-1.5, while maintaining 96.7% of the original model's accuracy.

21 Oct 2024





This survey systematically reviews Knowledge Distillation (KD) techniques for Large Language Models (LLMs), outlining methods for transferring capabilities from large proprietary models to smaller, more accessible open-source ones. It categorizes KD approaches by algorithms, skill distillation, and verticalization, highlighting the central role of data augmentation and iterative self-improvement for democratizing advanced LLM capabilities.

15 Nov 2025
The MIRROR framework introduces a multi-modal self-supervised learning approach for computational pathology, integrating histopathology and transcriptomics by balancing modality alignment with modality-specific information retention and mitigating redundancy through a novel style clustering module. It demonstrates superior performance in cancer subtyping and survival prediction on TCGA cohorts, outperforming existing baselines in various diagnostic tasks.

12 Sep 2025
Arbitrary resolution image generation provides a consistent visual experience across devices, having extensive applications for producers and consumers. Current diffusion models increase computational demand quadratically with resolution, causing 4K image generation delays over 100 seconds. To solve this, we explore the second generation upon the latent diffusion models, where the fixed latent generated by diffusion models is regarded as the content representation and we propose to decode arbitrary resolution images with a compact generated latent using a one-step generator. Thus, we present the \textbf{InfGen}, replacing the VAE decoder with the new generator, for generating images at any resolution from a fixed-size latent without retraining the diffusion models, which simplifies the process, reducing computational complexity and can be applied to any model using the same latent space. Experiments show InfGen is capable of improving many models into the arbitrary high-resolution era while cutting 4K image generation time to under 10 seconds.

23 Mar 2025



OASIS presents an open agent social interaction simulator capable of scaling to one million LLM-based agents, designed to mimic real-world social media platforms. The platform successfully replicates and investigates complex social phenomena like information propagation, group polarization, and herd effects, providing a testbed for understanding emergent behaviors at unprecedented scales.
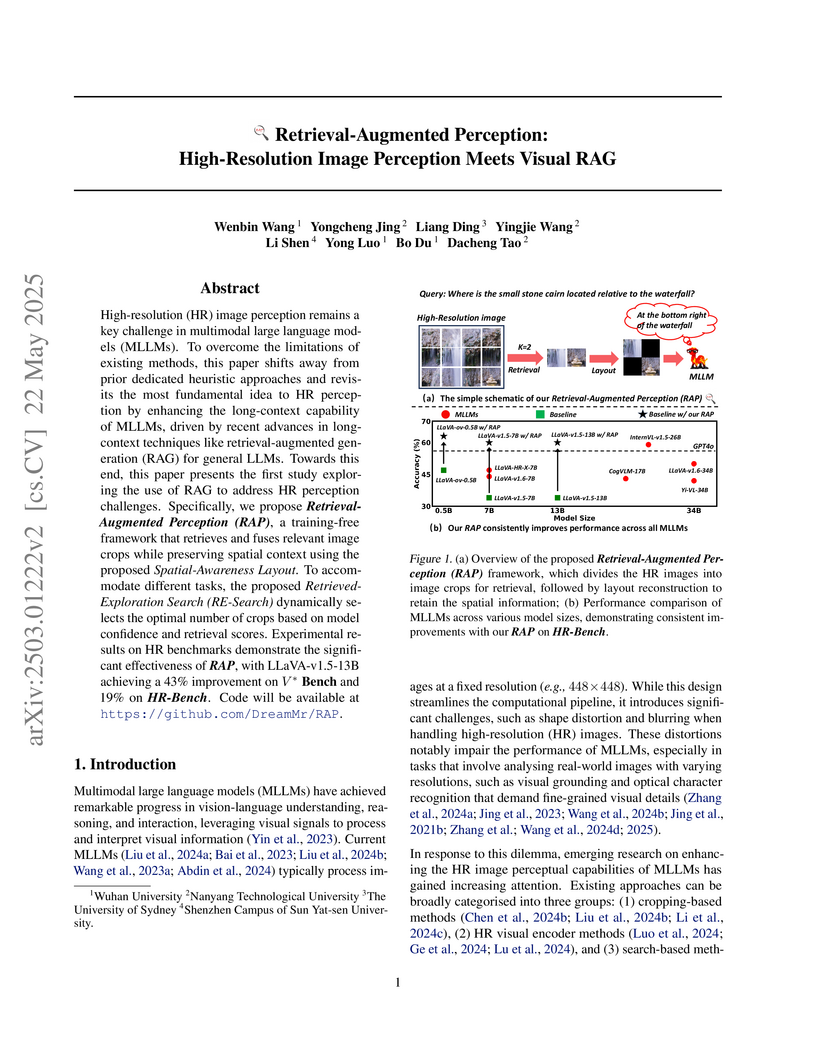
22 May 2025
This work introduces Retrieval-Augmented Perception (RAP), a training-free framework that applies Retrieval-Augmented Generation (RAG) principles to enhance Multimodal Large Language Models' (MLLMs) understanding of high-resolution images. RAP significantly improves MLLM performance on fine-grained perception tasks by intelligently retrieving, spatially arranging, and adaptively selecting relevant visual information, leading to an average accuracy increase of 24% on high-resolution image benchmarks while also improving inference efficiency.

19 Nov 2025
Universal multimodal embedding models are foundational to various tasks. Existing approaches typically employ in-batch negative mining by measuring the similarity of query-candidate pairs. However, these methods often struggle to capture subtle semantic differences among candidates and lack diversity in negative samples. Moreover, the embeddings exhibit limited discriminative ability in distinguishing false and hard negatives. In this paper, we leverage the advanced understanding capabilities of MLLMs to enhance representation learning and present a novel Universal Multimodal Embedding (UniME-V2) model. Our approach first constructs a potential hard negative set through global retrieval. We then introduce the MLLM-as-a-Judge mechanism, which utilizes MLLMs to assess the semantic alignment of query-candidate pairs and generate soft semantic matching scores. These scores serve as a foundation for hard negative mining, mitigating the impact of false negatives and enabling the identification of diverse, high-quality hard negatives. Furthermore, the semantic matching scores are used as soft labels to mitigate the rigid one-to-one mapping constraint. By aligning the similarity matrix with the soft semantic matching score matrix, the model learns semantic distinctions among candidates, significantly enhancing its discriminative capacity. To further improve performance, we propose UniME-V2-Reranker, a reranking model trained on our mined hard negatives through a joint pairwise and listwise optimization approach. We conduct comprehensive experiments on the MMEB benchmark and multiple retrieval tasks, demonstrating that our method achieves state-of-the-art performance on average across all tasks.

13 Oct 2025

Revealing hidden causal variables alongside the underlying causal mechanisms is essential to the development of science. Despite the progress in the past decades, existing practice in causal discovery (CD) heavily relies on high-quality measured variables, which are usually given by human experts. In fact, the lack of well-defined high-level variables behind unstructured data has been a longstanding roadblock to a broader real-world application of CD. This procedure can naturally benefit from an automated process that can suggest potential hidden variables in the system. Interestingly, Large language models (LLMs) are trained on massive observations of the world and have demonstrated great capability in processing unstructured data. To leverage the power of LLMs, we develop a new framework termed Causal representatiOn AssistanT (COAT) that incorporates the rich world knowledge of LLMs to propose useful measured variables for CD with respect to high-value target variables on their paired unstructured data. Instead of directly inferring causality with LLMs, COAT constructs feedback from intermediate CD results to LLMs to refine the proposed variables. Given the target variable and the paired unstructured data, we first develop COAT-MB that leverages the predictivity of the proposed variables to iteratively uncover the Markov Blanket of the target variable. Built upon COAT-MB, COAT-PAG further extends to uncover a more complete causal graph, i.e., Partial Ancestral Graph, by iterating over the target variables and actively seeking new high-level variables. Moreover, the reliable CD capabilities of COAT also extend the debiased causal inference to unstructured data by discovering an adjustment set. We establish theoretical guarantees for the CD results and verify their efficiency and reliability across realistic benchmarks and real-world case studies.

05 Mar 2025

Shanghai Jiao Tong University and Shanghai AI Laboratory researchers introduce MAS-GPT, a framework that enables automatic generation of task-specific Multi-Agent Systems through a single LLM inference, demonstrating superior performance across 9 benchmarks while reducing computational costs compared to existing approaches that require multiple LLM calls or manual design.

24 Mar 2025
AgentDropout introduces a dynamic optimization method for LLM-based multi-agent systems, selectively eliminating less critical agents and communication links. This approach achieves substantial reductions in token consumption, such as a 21.4% decrease in prompt tokens with Llama3, while also improving task performance by an average of 2.19 over AgentPrune on reasoning and code generation benchmarks.

22 May 2025
Researchers from Nanyang Technological University, ByteDance, and collaborating institutions develop Share-GRPO, a reinforcement learning framework for multimodal large language models that addresses sparse reward and advantage vanishing problems by expanding question spaces through semantic transformations and sharing reward information across question variants during training, with their R1-ShareVL model achieving substantial improvements on mathematical reasoning benchmarks including 4.2-point gains on MathVista and 3.8-point gains on MathVerse compared to baseline GRPO when applied to Qwen2.5-VL models.

02 Aug 2025
 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of Oxford
University of Oxford Fudan University
Fudan University Shanghai Jiao Tong University
Shanghai Jiao Tong University the University of Tokyo
the University of Tokyo Tsinghua University
Tsinghua University City University of Hong KongThe University of Melbourne
City University of Hong KongThe University of Melbourne ByteDance
ByteDance RIKENGriffith University
RIKENGriffith University Nanyang Technological University
Nanyang Technological University University of Wisconsin-Madison
University of Wisconsin-Madison Purdue UniversityThe University of SydneyUniversity of Massachusetts Amherst
Purdue UniversityThe University of SydneyUniversity of Massachusetts Amherst Duke University
Duke University Virginia TechSingapore Management UniversitySea AI LabUniversity of Auckland
Virginia TechSingapore Management UniversitySea AI LabUniversity of Auckland HKUSTCISPA – Helmholtz Center for Information SecurityChinese University of Hong Kong, Shenzhen
HKUSTCISPA – Helmholtz Center for Information SecurityChinese University of Hong Kong, Shenzhen University of California, Santa Cruz
University of California, Santa CruzThis comprehensive survey systematically reviews current safety research across six major large AI model paradigms and autonomous agents, presenting a detailed taxonomy of 10 attack types and corresponding defense strategies. The review identifies a predominant focus on attack methodologies (60% of papers) over defenses and outlines key open challenges for advancing AI safety.

27 Mar 2025

Shanghai AI Laboratory researchers introduce Lumina-Image 2.0, a unified text-to-image generation framework that combines a novel diffusion transformer architecture with a specialized captioning system, achieving competitive performance on benchmarks while reducing computational costs through efficient training and inference optimizations.
17 Oct 2024
 The Chinese University of Hong KongThe University of MelbourneUniversity of Technology SydneyThe University of Sydney
The Chinese University of Hong KongThe University of MelbourneUniversity of Technology SydneyThe University of Sydney Australian National UniversityKing Fahd University of Petroleum and MineralsUniversity of Engineering and TechnologyThe University of Western AustraliaCommonwealth Scientific and Industrial Research OrganisationSDAIA-KFUPM Joint Research Center for Artificial Intelligence
Australian National UniversityKing Fahd University of Petroleum and MineralsUniversity of Engineering and TechnologyThe University of Western AustraliaCommonwealth Scientific and Industrial Research OrganisationSDAIA-KFUPM Joint Research Center for Artificial IntelligenceThis paper synthesizes the extensive and rapidly evolving literature on Large Language Models (LLMs), offering a structured resource on their architectures, training strategies, and applications. It provides a comprehensive overview of existing works, highlighting key design aspects, model capabilities, augmentation strategies, and efficiency techniques, while also discussing challenges and future research directions.

19 Apr 2025
This survey systematically reviews and categorizes generative models in computer vision that produce physically plausible outputs, establishing a taxonomy of explicit and implicit physics-aware generation methods. It details six paradigms for integrating physical simulation, revealing a trend towards functional realism, and identifies current challenges in evaluation metrics.

13 Oct 2022
ViTPose introduces a straightforward approach to human pose estimation by leveraging plain vision transformers as the exclusive backbone, paired with a minimal decoder. The method demonstrates robust performance, achieving 80.9 AP on the MS COCO test-dev set with a single model and showcasing the strong feature representation capabilities of simple ViT architectures.

20 May 2021
This survey from the UBTECH Sydney AI Centre systematically reviews Knowledge Distillation (KD), a method for transferring knowledge from large teacher models to smaller student models to enable efficient deployment on resource-constrained devices. It categorizes KD methods by knowledge type, distillation scheme, and algorithms, demonstrating its consistent effectiveness in model compression and broad applicability across diverse AI domains like computer vision, NLP, and speech recognition.

12 Apr 2025
VisuoThink introduces a framework that enhances Large Vision-Language Model reasoning by dynamically interleaving visual and textual information within a multimodal tree search, achieving up to a 21.8% accuracy improvement on geometry problem-solving benchmarks without requiring model fine-tuning.

02 Jul 2025


Researchers introduce OpticalRS-13M, a 13-million-image visible light remote sensing dataset, and SelectiveMAE, an efficient masked image modeling method. This pipeline achieves over a 2x speedup in pre-training and substantial memory reduction while maintaining or improving performance across various downstream remote sensing tasks compared to existing methods.
There are no more papers matching your filters at the moment.
