 University of Florida
University of Florida
05 Dec 2024
A multiscale intrinsically motivated reinforcement learning framework, ELEMENT, combines episodic and lifelong maximum entropy to enhance exploration in reward-sparse environments. This approach generates superior data for offline reinforcement learning and improves unsupervised pre-training, consistently surpassing existing intrinsic reward methods in state coverage and sample efficiency across various environments.

19 Nov 2024
Head and neck (H&N) cancers are among the most prevalent types of cancer worldwide, and [18F]F-FDG PET/CT is widely used for H&N cancer management. Recently, the diffusion model has demonstrated remarkable performance in various image-generation tasks. In this work, we proposed a 3D diffusion model to accurately perform H&N tumor segmentation from 3D PET and CT volumes. The 3D diffusion model was developed considering the 3D nature of PET and CT images acquired. During the reverse process, the model utilized a 3D UNet structure and took the concatenation of PET, CT, and Gaussian noise volumes as the network input to generate the tumor mask. Experiments based on the HECKTOR challenge dataset were conducted to evaluate the effectiveness of the proposed diffusion model. Several state-of-the-art techniques based on U-Net and Transformer structures were adopted as the reference methods. Benefits of employing both PET and CT as the network input as well as further extending the diffusion model from 2D to 3D were investigated based on various quantitative metrics and the uncertainty maps generated. Results showed that the proposed 3D diffusion model could generate more accurate segmentation results compared with other methods. Compared to the diffusion model in 2D format, the proposed 3D model yielded superior results. Our experiments also highlighted the advantage of utilizing dual-modality PET and CT data over only single-modality data for H&N tumor segmentation.

23 Oct 2023

The Reasoning via Planning (RAP) framework from UC San Diego and University of Florida integrates Large Language Models (LLMs) with an internal world model and Monte Carlo Tree Search to enable deliberate, multi-step reasoning. This approach allows LLaMA-33B to outperform GPT-4 on plan generation and achieves higher accuracy on math and logical reasoning tasks compared to existing LLM reasoning methods.

07 Dec 2025
The computational role of imagination remains debated. While classical accounts emphasize reward maximization, emerging evidence suggests imagination serves a broader function: accessing internal world models (IWMs). Here, we employ psychological network analysis to compare IWMs in humans and large language models (LLMs) through imagination vividness ratings. Using the Vividness of Visual Imagery Questionnaire (VVIQ-2) and Plymouth Sensory Imagery Questionnaire (PSIQ), we construct imagination networks from three human populations (Florida, Poland, London; N=2,743) and six LLM variants in two conversation conditions. Human imagination networks demonstrate robust correlations across centrality measures (expected influence, strength, closeness) and consistent clustering patterns, indicating shared structural organization of IWMs across populations. In contrast, LLM-derived networks show minimal clustering and weak centrality correlations, even when manipulating conversational memory. These systematic differences persist across environmental scenes (VVIQ-2) and sensory modalities (PSIQ), revealing fundamental disparities between human and artificial world models. Our network-based approach provides a quantitative framework for comparing internally-generated representations across cognitive agents, with implications for developing human-like imagination in artificial intelligence systems.

20 Nov 2025
 University of Toronto
University of Toronto California Institute of Technology
California Institute of Technology University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of Waterloo
University of Waterloo Harvard University
Harvard University Northeastern University
Northeastern University UCLA
UCLA Carnegie Mellon University
Carnegie Mellon University University of Chicago
University of Chicago UC Berkeley
UC Berkeley The Chinese University of Hong Kong
The Chinese University of Hong Kong University of Maryland, College Park
University of Maryland, College Park ETH Zürich
ETH Zürich University of California, San DiegoOhio State University
University of California, San DiegoOhio State University Columbia UniversityUniversity of FloridaVector Institute
Columbia UniversityUniversity of FloridaVector Institute Argonne National LaboratoryUniversity of Cologne
Argonne National LaboratoryUniversity of Cologne Perimeter Institute for Theoretical Physics
Perimeter Institute for Theoretical Physics Virginia Tech
Virginia Tech Princeton University
Princeton University HKUSTUtrecht UniversityUniversity of ConnecticutUniversity of Colorado BoulderPaul Scherrer InstituteHofstra UniversityUniversity of Tennessee, KnoxvilleChi 3 OpticsNational Institute of Theory and Mathematics in BiologyUniversity of Washington-Seattle
HKUSTUtrecht UniversityUniversity of ConnecticutUniversity of Colorado BoulderPaul Scherrer InstituteHofstra UniversityUniversity of Tennessee, KnoxvilleChi 3 OpticsNational Institute of Theory and Mathematics in BiologyUniversity of Washington-SeattleResearchers from Argonne National Laboratory and the University of Illinois Urbana-Champaign, with over 50 collaborators, introduce CritPt, a benchmark to evaluate Large Language Models (LLMs) on unpublished, research-level physics problems. The study found that current LLMs achieve very low accuracy on end-to-end scientific challenges (best base model at 5.7%) but show limited potential on modular sub-tasks, revealing a significant gap in their ability for genuine scientific reasoning and consistent reliability.

06 Oct 2025

Researchers at MIT CSAIL, Stanford, and the University of Florida demonstrated that training large language models on a dataset of 3.8 million real student programming traces leads to a richer understanding of both code and the underlying human reasoning processes. This approach yields models that can more accurately predict student programming behavior, adapt efficiently for personalized learning, and improve error recovery compared to models trained on final programs or synthetically generated traces.

03 Sep 2025
In the fast-paced financial domain, accurate and up-to-date information is critical to addressing ever-evolving market conditions. Retrieving this information correctly is essential in financial Question-Answering (QA), since many language models struggle with factual accuracy in this domain. We present FinDER, an expert-generated dataset tailored for Retrieval-Augmented Generation (RAG) in finance. Unlike existing QA datasets that provide predefined contexts and rely on relatively clear and straightforward queries, FinDER focuses on annotating search-relevant evidence by domain experts, offering 5,703 query-evidence-answer triplets derived from real-world financial inquiries. These queries frequently include abbreviations, acronyms, and concise expressions, capturing the brevity and ambiguity common in the realistic search behavior of professionals. By challenging models to retrieve relevant information from large corpora rather than relying on readily determined contexts, FinDER offers a more realistic benchmark for evaluating RAG systems. We further present a comprehensive evaluation of multiple state-of-the-art retrieval models and Large Language Models, showcasing challenges derived from a realistic benchmark to drive future research on truthful and precise RAG in the financial domain.

21 Aug 2024

Researchers from MIT and the University of Florida developed NeuralSVD, a novel optimization framework for training neural networks to approximate the top-L orthogonal singular functions of linear operators. This method utilizes an unconstrained low-rank approximation objective and nesting techniques, outperforming prior neural network-based approaches by an order of magnitude in quantum physics simulations and achieving state-of-the-art results in cross-domain retrieval for non-self-adjoint operators.

13 May 2025
University of Utah University of Notre DameUC Berkeley
University of Notre DameUC Berkeley Stanford University
Stanford University University of Michigan
University of Michigan Texas A&M University
Texas A&M University NVIDIA
NVIDIA University of Texas at AustinColumbia UniversityLehigh UniversityUniversity of Florida
University of Texas at AustinColumbia UniversityLehigh UniversityUniversity of Florida Johns Hopkins University
Johns Hopkins University Arizona State University
Arizona State University University of Wisconsin-Madison
University of Wisconsin-Madison Purdue UniversityUniversity of California, MercedTechnische Universität MünchenBosch Research North AmericaBosch Center for Artificial Intelligence (BCAI)University of California Riverside
Purdue UniversityUniversity of California, MercedTechnische Universität MünchenBosch Research North AmericaBosch Center for Artificial Intelligence (BCAI)University of California Riverside AdobeCleveland State UniversityTexas A&M Transportation Institute
AdobeCleveland State UniversityTexas A&M Transportation Institute
University of Notre DameUC BerkeleyStanford UniversityUniversity of MichiganTexas A&M UniversityNVIDIAUniversity of Texas at AustinColumbia UniversityLehigh UniversityUniversity of FloridaJohns Hopkins UniversityArizona State UniversityUniversity of Wisconsin-MadisonPurdue UniversityUniversity of California, MercedTechnische Universität MünchenBosch Research North AmericaBosch Center for Artificial Intelligence (BCAI)University of California RiversideAdobeCleveland State UniversityTexas A&M Transportation Institute

A comprehensive survey examines how generative AI technologies (GANs, VAEs, Diffusion Models, LLMs) are being applied across the autonomous driving stack, mapping current applications while analyzing challenges in safety, evaluation, and deployment through a collaborative effort spanning 20+ institutions including Texas A&M, Stanford, and NVIDIA.

19 Jun 2024
Wuhan UniversitySichuan UniversityThe Chinese University of Hong Kong, ShenzhenColumbia UniversityJiangxi Normal UniversityUniversity of Florida Stony Brook UniversityThe University of ManchesterYunnan UniversitySouthwest Jiaotong UniversityStevens Institute of TechnologyThe Fin AINanjing Audit University
Stony Brook UniversityThe University of ManchesterYunnan UniversitySouthwest Jiaotong UniversityStevens Institute of TechnologyThe Fin AINanjing Audit University
Columbia UniversityJiangxi Normal UniversityUniversity of FloridaStony Brook UniversityThe University of ManchesterYunnan UniversitySouthwest Jiaotong UniversityStevens Institute of TechnologyThe Fin AINanjing Audit UniversityFinBen introduces the first comprehensive open-source evaluation benchmark for large language models in finance, integrating 36 datasets across 24 tasks and seven critical financial aspects. Its extensive evaluation of 15 LLMs reveals strong performance in basic NLP but significant deficiencies in complex reasoning, quantitative forecasting, and robust decision-making, while showcasing advanced models' capabilities in areas like stock trading.

07 Jun 2025
Rensselaer Polytechnic InstituteWuhan UniversitySichuan University New York University
New York University Nanjing UniversityThe Chinese University of Hong Kong, Shenzhen
Nanjing UniversityThe Chinese University of Hong Kong, Shenzhen Yale UniversityNVIDIAColumbia UniversityUniversity of FloridaStony Brook UniversityThe University of ManchesterStevens Institute of TechnologyUniversity of Montreal
Yale UniversityNVIDIAColumbia UniversityUniversity of FloridaStony Brook UniversityThe University of ManchesterStevens Institute of TechnologyUniversity of Montreal
New York UniversityNanjing UniversityThe Chinese University of Hong Kong, ShenzhenYale UniversityNVIDIAColumbia UniversityUniversity of FloridaStony Brook UniversityThe University of ManchesterStevens Institute of TechnologyUniversity of Montreal

Financial LLMs hold promise for advancing financial tasks and domain-specific
applications. However, they are limited by scarce corpora, weak multimodal
capabilities, and narrow evaluations, making them less suited for real-world
application. To address this, we introduce \textit{Open-FinLLMs}, the first
open-source multimodal financial LLMs designed to handle diverse tasks across
text, tabular, time-series, and chart data, excelling in zero-shot, few-shot,
and fine-tuning settings. The suite includes FinLLaMA, pre-trained on a
comprehensive 52-billion-token corpus; FinLLaMA-Instruct, fine-tuned with 573K
financial instructions; and FinLLaVA, enhanced with 1.43M multimodal tuning
pairs for strong cross-modal reasoning. We comprehensively evaluate
Open-FinLLMs across 14 financial tasks, 30 datasets, and 4 multimodal tasks in
zero-shot, few-shot, and supervised fine-tuning settings, introducing two new
multimodal evaluation datasets. Our results show that Open-FinLLMs outperforms
afvanced financial and general LLMs such as GPT-4, across financial NLP,
decision-making, and multi-modal tasks, highlighting their potential to tackle
real-world challenges. To foster innovation and collaboration across academia
and industry, we release all codes
(this https URL) and models under
OSI-approved licenses.
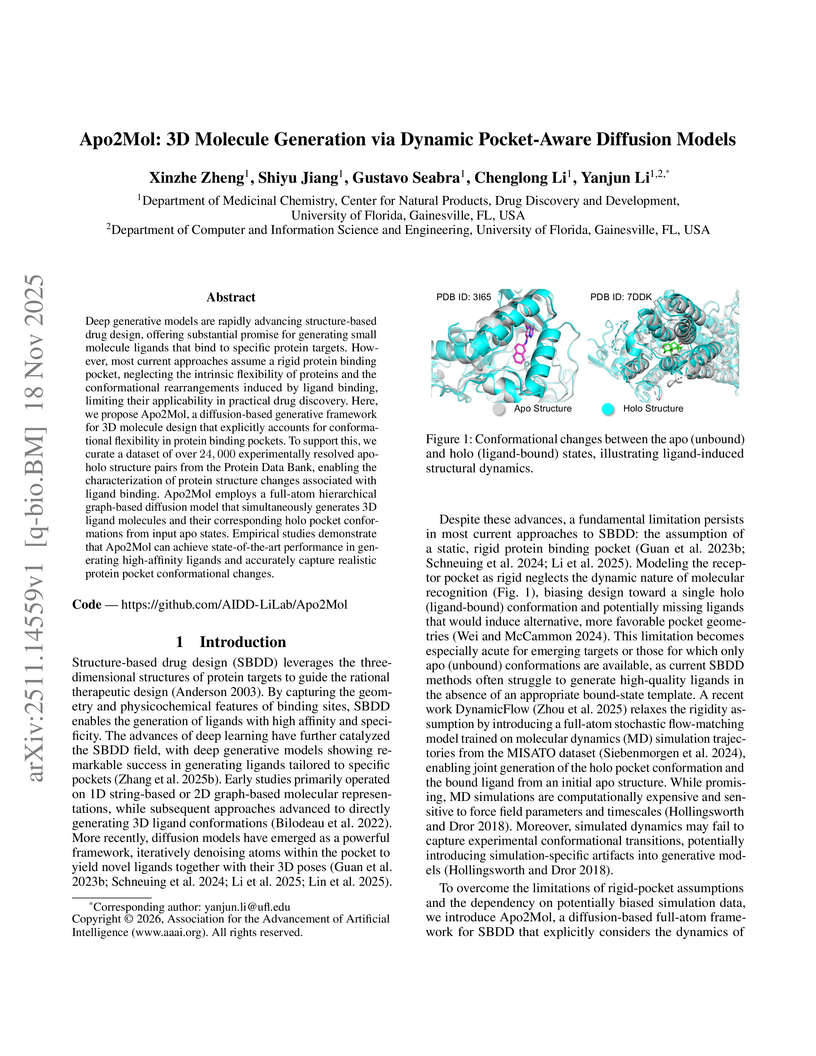
18 Nov 2025
Apo2Mol introduces a full-atom, SE(3)-equivariant diffusion model for jointly generating 3D small molecules and refining protein binding pocket conformations from unbound (apo) protein structures. The model leverages a large, curated dataset of experimentally resolved apo-holo protein pairs, achieving improved predicted binding affinities and more chemically realistic generated molecules compared to rigid-pocket baselines.

30 Oct 2025


Although Large Language Model (LLM)-based agents are increasingly used in financial trading, it remains unclear whether they can reason and adapt in live markets, as most studies test models instead of agents, cover limited periods and assets, and rely on unverified data. To address these gaps, we introduce Agent Market Arena (AMA), the first lifelong, real-time benchmark for evaluating LLM-based trading agents across multiple markets. AMA integrates verified trading data, expert-checked news, and diverse agent architectures within a unified trading framework, enabling fair and continuous comparison under real conditions. It implements four agents, including InvestorAgent as a single-agent baseline, TradeAgent and HedgeFundAgent with different risk styles, and DeepFundAgent with memory-based reasoning, and evaluates them across GPT-4o, GPT-4.1, Claude-3.5-haiku, Claude-sonnet-4, and Gemini-2.0-flash. Live experiments on both cryptocurrency and stock markets demonstrate that agent frameworks display markedly distinct behavioral patterns, spanning from aggressive risk-taking to conservative decision-making, whereas model backbones contribute less to outcome variation. AMA thus establishes a foundation for rigorous, reproducible, and continuously evolving evaluation of financial reasoning and trading intelligence in LLM-based agents.

03 Oct 2025
FinAgentBench introduces the first large-scale benchmark for evaluating agentic retrieval capabilities of large language models in financial question answering. It assesses LLMs in a two-stage process for identifying relevant document types and specific content chunks, demonstrating that fine-tuning significantly improves performance across both stages.

11 Jun 2024

Researchers from the University of Alabama, Delft University of Technology, Mathworks, and the University of Florida developed SR-SPECNet, a deep learning approach that transforms 2D radar heatmap enhancement into a 1D angular spectra estimation problem. This method improves radar image quality, achieving an inference time of 3.12 ms and using 1 million parameters, outperforming 2D and 3D U-Nets.

11 Aug 2024

Researchers from UC San Diego introduce AutoRace, a fully automated and task-adaptive method for evaluating LLM reasoning chains, and LLM Reasoners, a unified library for implementing diverse reasoning algorithms. These tools enable more systematic analysis of LLM reasoning, revealing that search-based methods reduce false positives and explicit world models are crucial for embodied planning tasks.

02 Nov 2024
Me-LLaMA, a new family of medical foundation large language models developed by researchers from Yale, University of Florida, and UTHealth Houston, integrates a 129 billion token medical dataset and a dual-phase training strategy to achieve leading performance across diverse medical text analysis tasks. The models demonstrate strong capabilities in complex clinical diagnosis, even outperforming GPT-4 in human clinician evaluations.

15 Aug 2025
Vision-language models (VLMs) have shown promise in 2D medical image analysis, but extending them to 3D remains challenging due to the high computational demands of volumetric data and the difficulty of aligning 3D spatial features with clinical text. We present Med3DVLM, a 3D VLM designed to address these challenges through three key innovations: (1) DCFormer, an efficient encoder that uses decomposed 3D convolutions to capture fine-grained spatial features at scale; (2) SigLIP, a contrastive learning strategy with pairwise sigmoid loss that improves image-text alignment without relying on large negative batches; and (3) a dual-stream MLP-Mixer projector that fuses low- and high-level image features with text embeddings for richer multi-modal representations. We evaluate our model on the M3D dataset, which includes radiology reports and VQA data for 120,084 3D medical images. Results show that Med3DVLM achieves superior performance across multiple benchmarks. For image-text retrieval, it reaches 61.00% R@1 on 2,000 samples, significantly outperforming the current state-of-the-art M3D model (19.10%). For report generation, it achieves a METEOR score of 36.42% (vs. 14.38%). In open-ended visual question answering (VQA), it scores 36.76% METEOR (vs. 33.58%), and in closed-ended VQA, it achieves 79.95% accuracy (vs. 75.78%). These results highlight Med3DVLM's ability to bridge the gap between 3D imaging and language, enabling scalable, multi-task reasoning across clinical applications. Our code is publicly available at this https URL.

28 Oct 2025
We document the capability of large language models (LLMs) like ChatGPT to predict stock market reactions from news headlines without direct financial training. Using post-knowledge-cutoff headlines, GPT-4 captures initial market responses, achieving approximately 90% portfolio-day hit rates for the non-tradable initial reaction. GPT-4 scores also significantly predict the subsequent drift, especially for small stocks and negative news. Forecasting ability generally increases with model size, suggesting that financial reasoning is an emerging capacity of complex LLMs. Strategy returns decline as LLM adoption rises, consistent with improved price efficiency. To rationalize these findings, we develop a theoretical model that incorporates LLM technology, information-processing capacity constraints, underreaction, and limits to arbitrage.

06 Feb 2025
The paper identifies and validates a "Patchification Scaling Law," demonstrating that reducing patch sizes consistently improves performance across image classification, semantic segmentation, and object detection. By utilizing Mamba-based architectures, the work processes pixel-level tokenization (1x1 patches, 50,176 tokens) for the first time on standard image resolutions, achieving 84.6% accuracy on ImageNet-1k and reducing the need for complex decoders in dense prediction tasks.
There are no more papers matching your filters at the moment.
