
02 Dec 2024
Researchers from Xi’an Jiaotong University provide a comprehensive review of mathematical optimization techniques in Federated Learning (FL), focusing on problem formulations, underlying assumptions, optimization methods, and theoretical results. The work synthesizes existing literature and identifies future research directions, offering a mathematically rigorous perspective on FL's core challenges.

14 Oct 2024
SpeGCL introduces a self-supervised graph contrastive learning framework that efficiently utilizes high-frequency spectral information through Fourier transforms and achieves state-of-the-art performance by relying solely on negative samples, challenging the necessity of positive pairs. This method demonstrates improved classification accuracy across diverse datasets and enhanced computational efficiency compared to existing approaches.

02 Dec 2024
FedAH enhances personalized federated learning by introducing an Aggregated Head mechanism that adaptively integrates global knowledge into client-specific prediction heads. This approach consistently outperforms ten state-of-the-art FL methods, showing up to 2.87% higher test accuracy on complex datasets like Cifar100.

26 May 2025
DeepEyes enables Vision-Language Models (VLMs) to perform 'thinking with images' by dynamically integrating visual re-perception into their reasoning process through end-to-end reinforcement learning. This approach, developed by researchers from Xiaohongshu Inc. and Xi'an Jiaotong University, achieves notable performance improvements, including an 18.9% accuracy gain on V* Bench and a 1.8% reduction in hallucinations on POPE compared to baselines.

20 Feb 2024

The multi-agent perception system collects visual data from sensors located
on various agents and leverages their relative poses determined by GPS signals
to effectively fuse information, mitigating the limitations of single-agent
sensing, such as occlusion. However, the precision of GPS signals can be
influenced by a range of factors, including wireless transmission and
obstructions like buildings. Given the pivotal role of GPS signals in
perception fusion and the potential for various interference, it becomes
imperative to investigate whether specific GPS signals can easily mislead the
multi-agent perception system. To address this concern, we frame the task as an
adversarial attack challenge and introduce \textsc{AdvGPS}, a method capable of
generating adversarial GPS signals which are also stealthy for individual
agents within the system, significantly reducing object detection accuracy. To
enhance the success rates of these attacks in a black-box scenario, we
introduce three types of statistically sensitive natural discrepancies:
appearance-based discrepancy, distribution-based discrepancy, and task-aware
discrepancy. Our extensive experiments on the OPV2V dataset demonstrate that
these attacks substantially undermine the performance of state-of-the-art
methods, showcasing remarkable transferability across different point cloud
based 3D detection systems. This alarming revelation underscores the pressing
need to address security implications within multi-agent perception systems,
thereby underscoring a critical area of research.

11 Nov 2025

FutureSightDrive (FSDrive) introduces a framework for Vision-Language-Action (VLA) models in autonomous driving that generates a visual spatio-temporal Chain-of-Thought (CoT) as a unified future image. This approach, which incorporates physically plausible future scenarios, improves trajectory planning accuracy and significantly reduces collision rates.

13 Oct 2025





This survey synthesizes the extensive and fragmented field of robot manipulation, providing a comprehensive overview that unifies diverse methodologies and challenges under novel classification systems. It structures the landscape by introducing new taxonomies for high-level planning, low-level learning-based control, and key bottlenecks, while outlining future research directions.

18 Sep 2025




ForceVLA enhances Vision-Language-Action models for contact-rich robotic manipulation by integrating 6-axis force feedback through a Force-aware Mixture-of-Experts (FVLMoE) module. This approach improves average task success rates by 23.2% and demonstrates superior generalization across diverse physical interaction scenarios, including under visual occlusion.

26 Sep 2025
JANUSVLN introduces a framework for Vision-Language Navigation (VLN) using a dual implicit neural memory that decouples and integrates visual semantics with 3D spatial geometry. The system leverages a 3D visual geometry foundation model to extract spatial priors solely from RGB video input, achieving state-of-the-art performance on R2R-CE and RxR-CE benchmarks while reducing inference overhead by 69-90%.
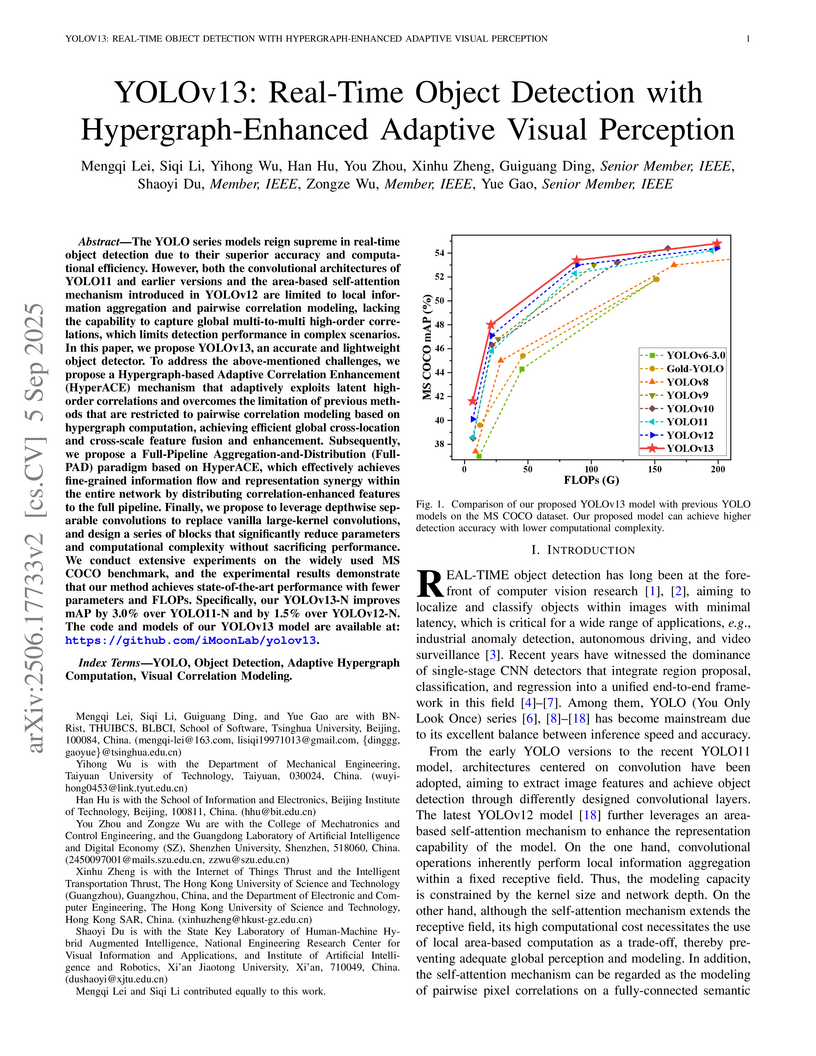
05 Sep 2025


YOLOv13 enhances real-time object detection by integrating an adaptive hypergraph computation mechanism for high-order visual correlation modeling and a full-pipeline feature distribution paradigm. The approach yields improved detection accuracy on the MS COCO benchmark, with the Nano variant achieving a 1.5% mAP@50:95 increase over YOLOv12-N, while maintaining or reducing computational cost.

24 Sep 2025
A new benchmark, OmniSpatial, offers a comprehensive evaluation of Vision-Language Models' spatial reasoning by integrating principles from cognitive psychology into 50 fine-grained subtasks. The benchmark reveals that state-of-the-art VLMs perform over 30 percentage points below human accuracy, particularly struggling with complex spatial logic and perspective-taking.

21 Sep 2025
Speculative decoding is a powerful way to accelerate autoregressive large language models (LLMs), but directly porting it to vision-language models (VLMs) faces unique systems constraints: the prefill stage is dominated by visual tokens whose count scales with image resolution and video length, inflating both compute and memory, especially the key-value (KV) cache. We study speculative decoding for VLMs and introduce SpecVLM, a practical system that (1) establishes a strong EAGLE-2-style baseline, EagleVLM, delivering 1.5--2.3x end-to-end speedups over full autoregressive inference, and (2) further accelerates VLM inference with an elastic visual compressor that adaptively selects among pruning, pooling, convolution, and resampler primitives to balance FLOPs/parameters and accuracy per input. To avoid costly offline distillation corpora, we propose an online-logit distillation protocol that trains the draft model with on-the-fly teacher logits and penultimate features using a combined cross-entropy and Smooth L1 objective, eliminating storage and preprocessing while remaining compute-efficient. This protocol reveals a training-time scaling effect: longer online training monotonically increases the draft model's average accepted length, improving speculative efficiency. Empirically, SpecVLM achieves additional acceleration, culminating in 2.5--2.9x end-to-end speedups within 5 epochs across LLaVA and MMMU, consistently over resolutions and task difficulties, while preserving the target model's output distribution (lossless decoding). Our code is available at this https URL.

03 Nov 2025

A framework called Multi-Agent Reinforcement Fine-Tuning (MARFT) is introduced to optimize Large Language Model-based Multi-Agent Systems (LaMAS) using reinforcement learning techniques. It leverages a Flexible Markov Game formulation and achieves performance improvements on agentic tasks like mathematical problem-solving and coding, with MARFT-A increasing episodic return by approximately 18.45% on the MATH dataset and 14.75% in coding benchmarks.

16 Jul 2025

SWE-Perf introduces the first benchmark for evaluating Large Language Models (LLMs) on real-world, repository-level code performance optimization, drawing from 140 human-authored performance-improving pull requests. Evaluations using SWE-Perf reveal a substantial gap between current LLM capabilities (e.g., OpenHands with 2.26% average gain) and expert performance (10.85% gain), indicating LLMs struggle with complex, multi-function optimization and identifying opportunities in computationally intensive code.

28 Aug 2025
Long-VLA enhances Vision-Language-Action (VLA) models for long-horizon robot manipulation by introducing a phase-aware input masking strategy and unified training. This approach mitigates the skill chaining problem, achieving up to 81% relative performance improvement in simulations and demonstrating enhanced robustness in real-world tasks like sorting and cleaning, even under visual distractions.

23 Mar 2025



OASIS presents an open agent social interaction simulator capable of scaling to one million LLM-based agents, designed to mimic real-world social media platforms. The platform successfully replicates and investigates complex social phenomena like information propagation, group polarization, and herd effects, providing a testbed for understanding emergent behaviors at unprecedented scales.

11 Jun 2025
EfficientVLA presents a training-free framework that accelerates and compresses diffusion-based Vision-Language-Action (VLA) models by systematically addressing redundancies in the language module, visual processing, and iterative action head. The approach achieved a 1.93x inference speedup and over 70% FLOPs reduction with only a 0.6% drop in success rate, enabling more practical deployment on robotic platforms.
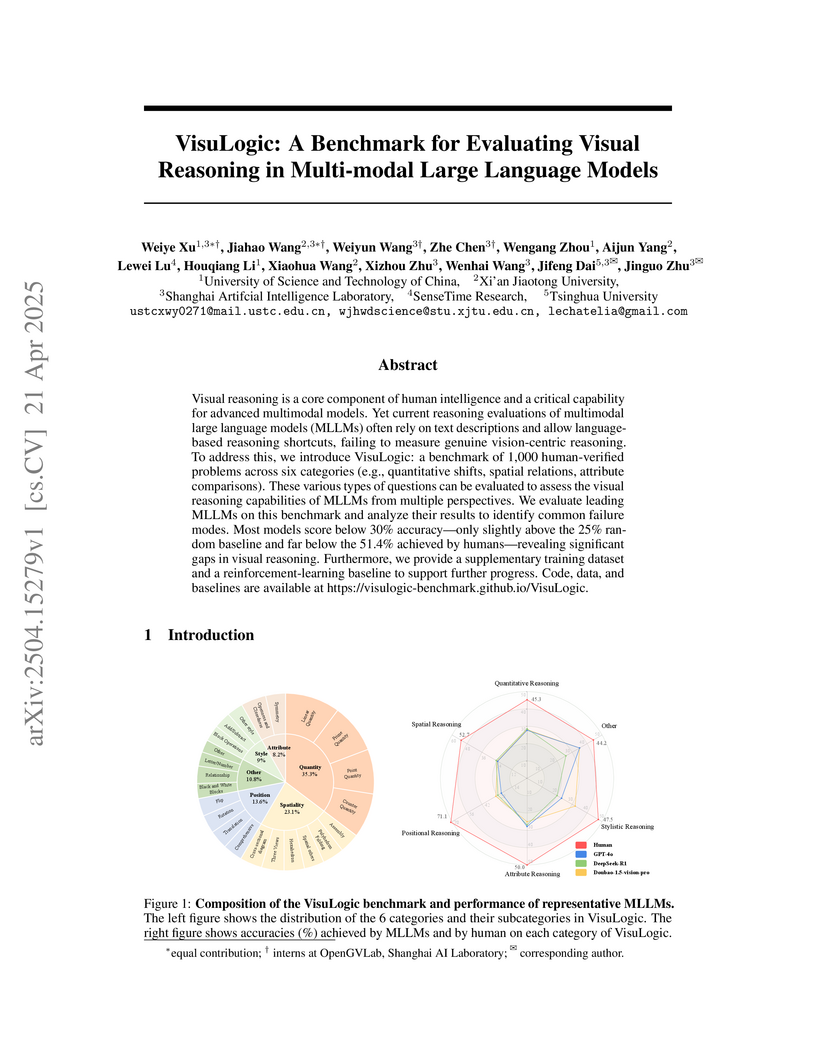
21 Apr 2025

A new benchmark called VisuLogic evaluates true visual reasoning capabilities in multimodal language models through carefully designed tasks that prevent language-based shortcuts, revealing that current MLLMs achieve only 30% accuracy compared to 51.4% human performance while demonstrating how reinforcement learning can help bridge this gap.
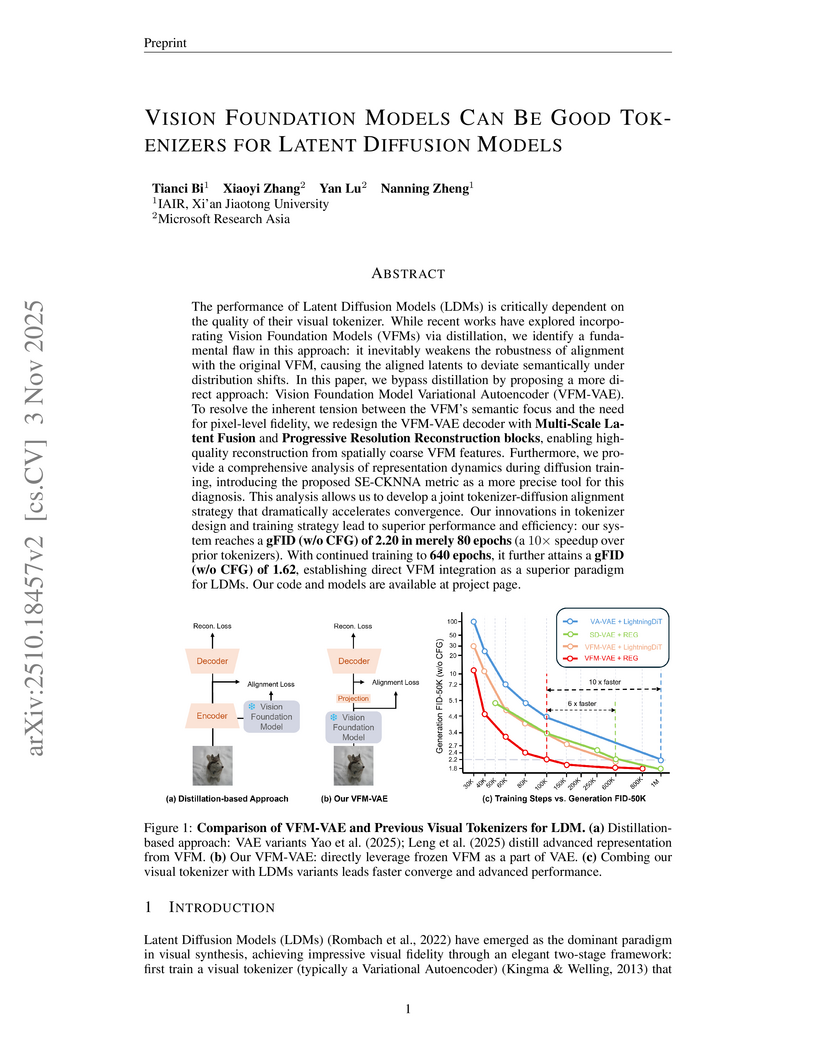
03 Nov 2025

Researchers from Xi’an Jiaotong University and Microsoft Research Asia developed VFM-VAE, a deep learning framework that directly integrates frozen Vision Foundation Models into Latent Diffusion Models' tokenizers. This approach achieves a 10x speedup in LDM training convergence and sets new benchmarks for image generation quality on ImageNet 256x256 with a gFID of 1.31.

13 Oct 2025


Researchers at Microsoft and collaborating universities developed DOCREWARD, a Document Reward Model designed to evaluate the visual structure and style professionalism of multi-page documents, independently of their textual content. The model achieved 89.22% human preference accuracy, a 19.45 percentage point improvement over GPT-5, and increased the win rate of AI-generated documents in human comparisons to 60.8% when used as a reward signal.
There are no more papers matching your filters at the moment.
