
27 Nov 2025


For autonomous vehicles, safe navigation in complex environments depends on handling a broad range of diverse and rare driving scenarios. Simulation- and scenario-based testing have emerged as key approaches to development and validation of autonomous driving systems. Traditional scenario generation relies on rule-based systems, knowledge-driven models, and data-driven synthesis, often producing limited diversity and unrealistic safety-critical cases. With the emergence of foundation models, which represent a new generation of pre-trained, general-purpose AI models, developers can process heterogeneous inputs (e.g., natural language, sensor data, HD maps, and control actions), enabling the synthesis and interpretation of complex driving scenarios. In this paper, we conduct a survey about the application of foundation models for scenario generation and scenario analysis in autonomous driving (as of May 2025). Our survey presents a unified taxonomy that includes large language models, vision-language models, multimodal large language models, diffusion models, and world models for the generation and analysis of autonomous driving scenarios. In addition, we review the methodologies, open-source datasets, simulation platforms, and benchmark challenges, and we examine the evaluation metrics tailored explicitly to scenario generation and analysis. Finally, the survey concludes by highlighting the open challenges and research questions, and outlining promising future research directions. All reviewed papers are listed in a continuously maintained repository, which contains supplementary materials and is available at this https URL.

22 Sep 2025
This research outlines a multi-phase agenda for treating prompts for Large Language Models as first-class software engineering artifacts, with preliminary survey findings revealing that while LLMs are heavily used in development, prompt management remains largely unsystematic, lacking reuse and consistent guidelines.

26 Sep 2025
Disentangled representations seek to recover latent factors of variation underlying observed data, yet their identifiability is still not fully understood. We introduce a unified framework in which disentanglement is achieved through mechanistic independence, which characterizes latent factors by how they act on observed variables rather than by their latent distribution. This perspective is invariant to changes of the latent density, even when such changes induce statistical dependencies among factors. Within this framework, we propose several related independence criteria -- ranging from support-based and sparsity-based to higher-order conditions -- and show that each yields identifiability of latent subspaces, even under nonlinear, non-invertible mixing. We further establish a hierarchy among these criteria and provide a graph-theoretic characterization of latent subspaces as connected components. Together, these results clarify the conditions under which disentangled representations can be identified without relying on statistical assumptions.

01 Apr 2025
In-car conversational systems bring the promise to improve the in-vehicle
user experience. Modern conversational systems are based on Large Language
Models (LLMs), which makes them prone to errors such as hallucinations, i.e.,
inaccurate, fictitious, and therefore factually incorrect information. In this
paper, we present an LLM-based methodology for the automatic factual
benchmarking of in-car conversational systems. We instantiate our methodology
with five LLM-based methods, leveraging ensembling techniques and diverse
personae to enhance agreement and minimize hallucinations. We use our
methodology to evaluate CarExpert, an in-car retrieval-augmented conversational
question answering system, with respect to the factual correctness to a
vehicle's manual. We produced a novel dataset specifically created for the
in-car domain, and tested our methodology against an expert evaluation. Our
results show that the combination of GPT-4 with the Input Output Prompting
achieves over 90 per cent factual correctness agreement rate with expert
evaluations, other than being the most efficient approach yielding an average
response time of 4.5s. Our findings suggest that LLM-based testing constitutes
a viable approach for the validation of conversational systems regarding their
factual correctness.

12 Aug 2024

Most vulnerability detection studies focus on datasets of vulnerabilities in C/C++ code, offering limited language diversity. Thus, the effectiveness of deep learning methods, including large language models (LLMs), in detecting software vulnerabilities beyond these languages is still largely unexplored. In this paper, we evaluate the effectiveness of LLMs in detecting and classifying Common Weakness Enumerations (CWE) using different prompt and role strategies. Our experimental study targets six state-of-the-art pre-trained LLMs (GPT-3.5- Turbo, GPT-4 Turbo, GPT-4o, CodeLLama-7B, CodeLLama- 13B, and Gemini 1.5 Pro) and five programming languages: Python, C, C++, Java, and JavaScript. We compiled a multi-language vulnerability dataset from different sources, to ensure representativeness. Our results showed that GPT-4o achieves the highest vulnerability detection and CWE classification scores using a few-shot setting. Aside from the quantitative results of our study, we developed a library called CODEGUARDIAN integrated with VSCode which enables developers to perform LLM-assisted real-time vulnerability analysis in real-world security scenarios. We have evaluated CODEGUARDIAN with a user study involving 22 developers from the industry. Our study showed that, by using CODEGUARDIAN, developers are more accurate and faster at detecting vulnerabilities.

02 Apr 2021
In graph neural networks (GNNs), message passing iteratively aggregates
nodes' information from their direct neighbors while neglecting the sequential
nature of multi-hop node connections. Such sequential node connections e.g.,
metapaths, capture critical insights for downstream tasks. Concretely, in
recommender systems (RSs), disregarding these insights leads to inadequate
distillation of collaborative signals. In this paper, we employ collaborative
subgraphs (CSGs) and metapaths to form metapath-aware subgraphs, which
explicitly capture sequential semantics in graph structures. We propose
meta\textbf{P}ath and \textbf{E}ntity-\textbf{A}ware \textbf{G}raph
\textbf{N}eural \textbf{N}etwork (PEAGNN), which trains multilayer GNNs to
perform metapath-aware information aggregation on such subgraphs. This
aggregated information from different metapaths is then fused using attention
mechanism. Finally, PEAGNN gives us the representations for node and subgraph,
which can be used to train MLP for predicting score for target user-item pairs.
To leverage the local structure of CSGs, we present entity-awareness that acts
as a contrastive regularizer on node embedding. Moreover, PEAGNN can be
combined with prominent layers such as GAT, GCN and GraphSage. Our empirical
evaluation shows that our proposed technique outperforms competitive baselines
on several datasets for recommendation tasks. Further analysis demonstrates
that PEAGNN also learns meaningful metapath combinations from a given set of
metapaths.

15 May 2024
Large Language Models (LLMs) are the cornerstone in automating Requirements Engineering (RE) tasks, underpinning recent advancements in the field. Their pre-trained comprehension of natural language is pivotal for effectively tailoring them to specific RE tasks. However, selecting an appropriate LLM from a myriad of existing architectures and fine-tuning it to address the intricacies of a given task poses a significant challenge for researchers and practitioners in the RE domain. Utilizing LLMs effectively for NLP problems in RE necessitates a dual understanding: firstly, of the inner workings of LLMs, and secondly, of a systematic approach to selecting and adapting LLMs for NLP4RE tasks. This chapter aims to furnish readers with essential knowledge about LLMs in its initial segment. Subsequently, it provides a comprehensive guideline tailored for students, researchers, and practitioners on harnessing LLMs to address their specific objectives. By offering insights into the workings of LLMs and furnishing a practical guide, this chapter contributes towards improving future research and applications leveraging LLMs for solving RE challenges.

12 Nov 2020
Learning-based approaches, such as reinforcement and imitation learning are
gaining popularity in decision-making for autonomous driving. However, learned
policies often fail to generalize and cannot handle novel situations well.
Asking and answering questions in the form of "Would a policy perform well if
the other agents had behaved differently?" can shed light on whether a policy
has seen similar situations during training and generalizes well. In this work,
a counterfactual policy evaluation is introduced that makes use of
counterfactual worlds - worlds in which the behaviors of others are non-actual.
If a policy can handle all counterfactual worlds well, it either has seen
similar situations during training or it generalizes well and is deemed to be
fit enough to be executed in the actual world. Additionally, by performing the
counterfactual policy evaluation, causal relations and the influence of
changing vehicle's behaviors on the surrounding vehicles becomes evident. To
validate the proposed method, we learn a policy using reinforcement learning
for a lane merging scenario. In the application-phase, the policy is only
executed after the counterfactual policy evaluation has been performed and if
the policy is found to be safe enough. We show that the proposed approach
significantly decreases the collision-rate whilst maintaining a high
success-rate.
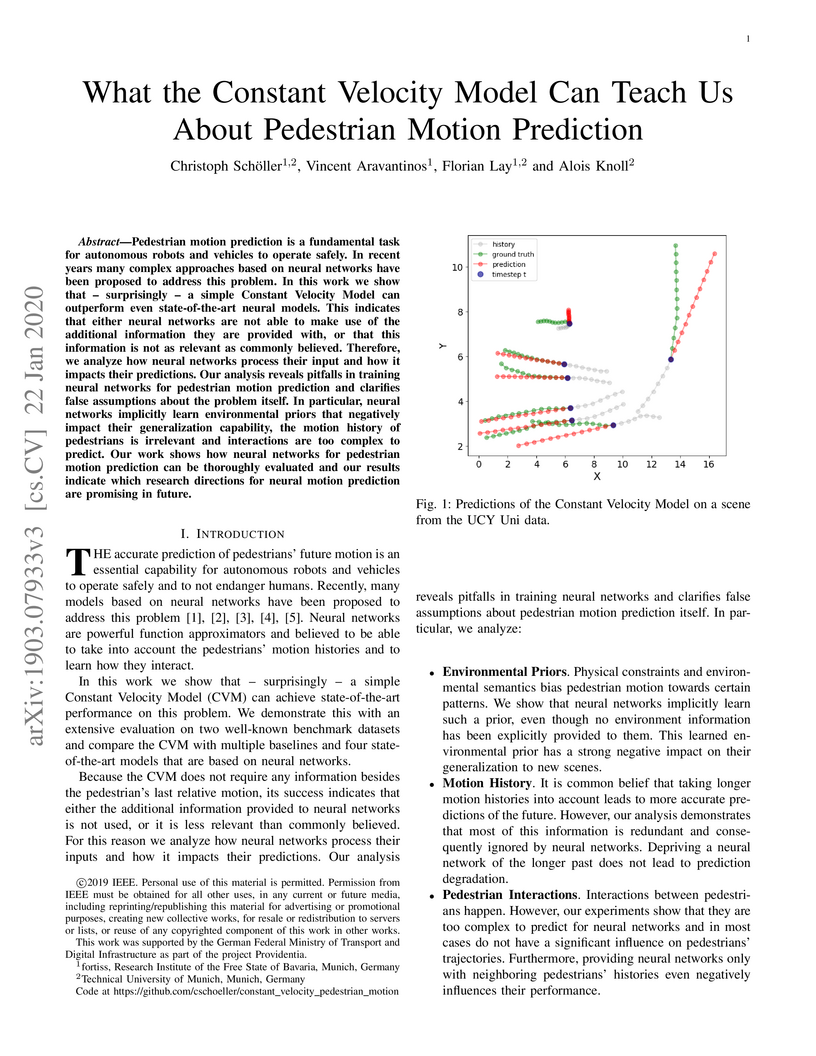
22 Jan 2020
Pedestrian motion prediction is a fundamental task for autonomous robots and
vehicles to operate safely. In recent years many complex approaches based on
neural networks have been proposed to address this problem. In this work we
show that - surprisingly - a simple Constant Velocity Model can outperform even
state-of-the-art neural models. This indicates that either neural networks are
not able to make use of the additional information they are provided with, or
that this information is not as relevant as commonly believed. Therefore, we
analyze how neural networks process their input and how it impacts their
predictions. Our analysis reveals pitfalls in training neural networks for
pedestrian motion prediction and clarifies false assumptions about the problem
itself. In particular, neural networks implicitly learn environmental priors
that negatively impact their generalization capability, the motion history of
pedestrians is irrelevant and interactions are too complex to predict. Our work
shows how neural networks for pedestrian motion prediction can be thoroughly
evaluated and our results indicate which research directions for neural motion
prediction are promising in future.

10 Jul 2025
Recognizing human activities early is crucial for the safety and responsiveness of human-robot and human-machine interfaces. Due to their high temporal resolution and low latency, event-based vision sensors are a perfect match for this early recognition demand. However, most existing processing approaches accumulate events to low-rate frames or space-time voxels which limits the early prediction capabilities. In contrast, spiking neural networks (SNNs) can process the events at a high-rate for early predictions, but most works still fall short on final accuracy. In this work, we introduce a high-rate two-stream SNN which closes this gap by outperforming previous work by 2% in final accuracy on the large-scale THU EACT-50 dataset. We benchmark the SNNs within a novel early event-based recognition framework by reporting Top-1 and Top-5 recognition scores for growing observation time. Finally, we exemplify the impact of these methods on a real-world task of early action triggering for human motion capture in sports.

12 Jul 2023

Optical flow provides information on relative motion that is an important
component in many computer vision pipelines. Neural networks provide high
accuracy optical flow, yet their complexity is often prohibitive for
application at the edge or in robots, where efficiency and latency play crucial
role. To address this challenge, we build on the latest developments in
event-based vision and spiking neural networks. We propose a new network
architecture, inspired by Timelens, that improves the state-of-the-art
self-supervised optical flow accuracy when operated both in spiking and
non-spiking mode. To implement a real-time pipeline with a physical event
camera, we propose a methodology for principled model simplification based on
activity and latency analysis. We demonstrate high speed optical flow
prediction with almost two orders of magnitude reduced complexity while
maintaining the accuracy, opening the path for real-time deployments.

20 Sep 2024
AI is anticipated to enhance human decision-making in high-stakes domains like aviation, but adoption is often hindered by challenges such as inappropriate reliance and poor alignment with users' decision-making. Recent research suggests that a core underlying issue is the recommendation-centric design of many AI systems, i.e., they give end-to-end recommendations and ignore the rest of the decision-making process. Alternative support paradigms are rare, and it remains unclear how the few that do exist compare to recommendation-centric support. In this work, we aimed to empirically compare recommendation-centric support to an alternative paradigm, continuous support, in the context of diversions in aviation. We conducted a mixed-methods study with 32 professional pilots in a realistic setting. To ensure the quality of our study scenarios, we conducted a focus group with four additional pilots prior to the study. We found that continuous support can support pilots' decision-making in a forward direction, allowing them to think more beyond the limits of the system and make faster decisions when combined with recommendations, though the forward support can be disrupted. Participants' statements further suggest a shift in design goal away from providing recommendations, to supporting quick information gathering. Our results show ways to design more helpful and effective AI decision support that goes beyond end-to-end recommendations.

07 May 2025
To ensure the availability and reduce the downtime of complex cyber-physical
systems across different domains, e.g., agriculture and manufacturing, fault
tolerance mechanisms are implemented which are complex in both their
development and operation. In addition, cyber-physical systems are often
confronted with limited hardware resources or are legacy systems, both often
hindering the addition of new functionalities directly on the onboard hardware.
Digital Twins can be adopted to offload expensive computations, as well as
providing support through fault tolerance mechanisms, thus decreasing costs and
operational downtime of cyber-physical systems. In this paper, we show the
feasibility of a Digital Twin used for enhancing cyber-physical system
operations, specifically through functional augmentation and increased fault
tolerance, in an industry-oriented use case.

08 Jan 2025

Large language models (LLMs) are increasingly used to generate software artifacts, such as source code, tests, and trace links. Requirements play a central role in shaping the input prompts that guide LLMs, as they are often used as part of the prompts to synthesize the artifacts. However, the impact of requirements formulation on LLM performance remains unclear. In this paper, we investigate the role of requirements smells-indicators of potential issues like ambiguity and inconsistency-when used in prompts for LLMs. We conducted experiments using two LLMs focusing on automated trace link generation between requirements and code. Our results show mixed outcomes: while requirements smells had a small but significant effect when predicting whether a requirement was implemented in a piece of code (i.e., a trace link exists), no significant effect was observed when tracing the requirements with the associated lines of code. These findings suggest that requirements smells can affect LLM performance in certain SE tasks but may not uniformly impact all tasks. We highlight the need for further research to understand these nuances and propose future work toward developing guidelines for mitigating the negative effects of requirements smells in AI-driven SE processes.

01 Apr 2025
Spiking neural networks (SNNs) present a promising computing paradigm for
neuromorphic processing of event-based sensor data. The resonate-and-fire (RF)
neuron, in particular, appeals through its biological plausibility, complex
dynamics, yet computational simplicity. Despite theoretically predicted
benefits, challenges in parameter initialization and efficient learning
inhibited the implementation of RF networks, constraining their use to a single
layer. In this paper, we address these shortcomings by deriving the RF neuron
as a structured state space model (SSM) from the HiPPO framework. We introduce
S5-RF, a new SSM layer comprised of RF neurons based on the S5 model, that
features a generic initialization scheme and fast training within a deep
architecture. S5-RF scales for the first time a RF network to a deep SNN with
up to four layers and achieves with 78.8% a new state-of-the-art result for
recurrent SNNs on the Spiking Speech Commands dataset in under three hours of
training time. Moreover, compared to the reference SNNs that solve our
benchmarking tasks, it achieves similar performance with much fewer spiking
operations. Our code is publicly available at
this https URL

17 Feb 2025
Researchers from Politecnico di Milano, TUM, fortiss GmbH, and USI developed a method to augment operational design domains in autonomous driving simulators using pre-trained diffusion models and knowledge distillation. The approach identified 20 times more failures in autonomous driving systems than baseline simulations and, with distillation, increased simulation time by only 2%.

28 Feb 2024
Context: Sustainable corporate behavior is increasingly valued by society and impacts corporate reputation and customer trust. Hence, companies regularly publish sustainability reports to shed light on their impact on environmental, social, and governance (ESG) factors. Problem: Sustainability reports are written by companies themselves and are therefore considered a company-controlled source. Contrary, studies reveal that non-corporate channels (e.g., media coverage) represent the main driver for ESG transparency. However, analysing media coverage regarding ESG factors is challenging since (1) the amount of published news articles grows daily, (2) media coverage data does not necessarily deal with an ESG-relevant topic, meaning that it must be carefully filtered, and (3) the majority of media coverage data is unstructured. Research Goal: We aim to extract ESG-relevant information from textual media reactions automatically to calculate an ESG score for a given company. Our goal is to reduce the cost of ESG data collection and make ESG information available to the general public. Contribution: Our contributions are three-fold: First, we publish a corpus of 432,411 news headlines annotated as being environmental-, governance-, social-related, or ESG-irrelevant. Second, we present our tool-supported approach called ESG-Miner capable of analyzing and evaluating headlines on corporate ESG-performance automatically. Third, we demonstrate the feasibility of our approach in an experiment and apply the ESG-Miner on 3000 manually labeled headlines. Our approach processes 96.7 % of the headlines correctly and shows a great performance in detecting environmental-related headlines along with their correct sentiment. We encourage fellow researchers and practitioners to use the ESG-Miner at this https URL.

16 Oct 2024
Search-based software testing (SBST) is a widely adopted technique for testing complex systems with large input spaces, such as Deep Learning-enabled (DL-enabled) systems. Many SBST techniques focus on Pareto-based optimization, where multiple objectives are optimized in parallel to reveal failures. However, it is important to ensure that identified failures are spread throughout the entire failure-inducing area of a search domain and not clustered in a sub-region. This ensures that identified failures are semantically diverse and reveal a wide range of underlying causes. In this paper, we present a theoretical argument explaining why testing based on Pareto optimization is inadequate for covering failure-inducing areas within a search domain. We support our argument with empirical results obtained by applying two widely used types of Pareto-based optimization techniques, namely NSGA-II (an evolutionary algorithm) and OMOPSO (a swarm-based Pareto-optimization algorithm), to two DL-enabled systems: an industrial Automated Valet Parking (AVP) system and a system for classifying handwritten digits. We measure the coverage of failure-revealing test inputs in the input space using a metric that we refer to as the Coverage Inverted Distance quality indicator. Our results show that NSGA-II-based search and OMOPSO are not more effective than a naïve random search baseline in covering test inputs that reveal failures. The replication package for this study is available in a GitHub repository.

29 Apr 2024
Simulation-based testing of automated driving systems (ADS) is the industry
standard, being a controlled, safe, and cost-effective alternative to
real-world testing. Despite these advantages, virtual simulations often fail to
accurately replicate real-world conditions like image fidelity, texture
representation, and environmental accuracy. This can lead to significant
differences in ADS behavior between simulated and real-world domains, a
phenomenon known as the sim2real gap. Researchers have used Image-to-Image
(I2I) neural translation to mitigate the sim2real gap, enhancing the realism of
simulated environments by transforming synthetic data into more authentic
representations of real-world conditions. However, while promising, these
techniques may potentially introduce artifacts, distortions, or inconsistencies
in the generated data that can affect the effectiveness of ADS testing. In our
empirical study, we investigated how the quality of image-to-image (I2I)
techniques influences the mitigation of the sim2real gap, using a set of
established metrics from the literature. We evaluated two popular generative
I2I architectures, pix2pix, and CycleGAN, across two ADS perception tasks at a
model level, namely vehicle detection and end-to-end lane keeping, using paired
simulated and real-world datasets. Our findings reveal that the effectiveness
of I2I architectures varies across different ADS tasks, and existing evaluation
metrics do not consistently align with the ADS behavior. Thus, we conducted
task-specific fine-tuning of perception metrics, which yielded a stronger
correlation. Our findings indicate that a perception metric that incorporates
semantic elements, tailored to each task, can facilitate selecting the most
appropriate I2I technique for a reliable assessment of the sim2real gap
mitigation.

20 Nov 2023
The availability of representative datasets is an essential prerequisite for many successful artificial intelligence and machine learning models. However, in real life applications these models often encounter scenarios that are inadequately represented in the data used for training. There are various reasons for the absence of sufficient data, ranging from time and cost constraints to ethical considerations. As a consequence, the reliable usage of these models, especially in safety-critical applications, is still a tremendous challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches. Knowledge augmented machine learning approaches offer the possibility of compensating for deficiencies, errors, or ambiguities in the data, thus increasing the generalization capability of the applied models. Even more, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-driven models with existing knowledge. The identified approaches are structured according to the categories knowledge integration, extraction and conformity. In particular, we address the application of the presented methods in the field of autonomous driving.
There are no more papers matching your filters at the moment.
