
01 Aug 2024
Researchers developed Y Social, a digital twin of social media platforms powered by Large Language Models, enabling the simulation and experimental investigation of platform dynamics, algorithmic effects, and user interactions in a controlled environment. The platform generates realistic user behaviors and content, mirroring patterns observed in real-world social media.

06 Oct 2025
Zero-shot captioners are recently proposed models that utilize common-space vision-language representations to caption images without relying on paired image-text data. To caption an image, they proceed by textually decoding a text-aligned image feature, but they limit their scope to global representations and whole-image captions. We present Patch-ioner, a unified framework for zero-shot captioning that shifts from an image-centric to a patch-centric paradigm, enabling the captioning of arbitrary regions without the need of region-level supervision. Instead of relying on global image representations, we treat individual patches as atomic captioning units and aggregate them to describe arbitrary regions, from single patches to non-contiguous areas and entire images. We analyze the key ingredients that enable current latent captioners to work in our novel proposed framework. Experiments demonstrate that backbones producing meaningful, dense visual features, such as DINO, are key to achieving state-of-the-art performance in multiple region-based captioning tasks. Compared to other baselines and state-of-the-art competitors, our models achieve better performance on zero-shot dense, region-set, and a newly introduced trace captioning task, highlighting the effectiveness of patch-wise semantic representations for scalable caption generation. Project page at this https URL .

24 Jun 2019

We present a new fully automatic block-decomposition hexahedral meshing algorithm capable of producing high quality meshes that strictly preserve feature curve networks on the input surface and align with an input surface cross-field. We produce all-hex meshes on the vast majority of inputs, and introduce localized non-hex elements only when the surface feature network necessitates those. The input to our framework is a closed surface with a collection of geometric or user-demarcated feature curves and a feature-aligned surface cross-field. Its output is a compact set of blocks whose edges interpolate these features and are loosely aligned with this cross-field. We obtain this block decomposition by cutting the input model using a collection of simple cutting surfaces bounded by closed surface loops. The set of cutting loops spans the input feature curves, ensuring feature preservation, and is obtained using a field-space sampling process. The computed loops are uniformly distributed across the surface, cross orthogonally, and are loosely aligned with the cross-field directions, inducing the desired block decomposition. We validate our method by applying it to a large range of complex inputs and comparing our results to those produced by state-of-the-art alternatives. Contrary to prior approaches, our framework consistently produces high-quality field aligned meshes while strictly preserving geometric or user-specified surface features.

04 Apr 2024
Researchers investigated the limitations of CLIP in fine-grained open-vocabulary object detection, determining that fine-grained information exists within CLIP's latent space but is not effectively utilized by standard matching functions. The study showed that simple linear projections applied to CLIP embeddings can notably improve fine-grained recognition performance.

11 Nov 2025
Class-agnostic counting (CAC) aims to estimate the number of objects in images without being restricted to predefined categories. However, while current exemplar-based CAC methods offer flexibility at inference time, they still rely heavily on labeled data for training, which limits scalability and generalization to many downstream use cases. In this paper, we introduce CountingDINO, the first training-free exemplar-based CAC framework that exploits a fully unsupervised feature extractor. Specifically, our approach employs self-supervised vision-only backbones to extract object-aware features, and it eliminates the need for annotated data throughout the entire proposed pipeline. At inference time, we extract latent object prototypes via ROI-Align from DINO features and use them as convolutional kernels to generate similarity maps. These are then transformed into density maps through a simple yet effective normalization scheme. We evaluate our approach on the FSC-147 benchmark, where we consistently outperform a baseline based on an SOTA unsupervised object detector under the same label- and training-free setting. Additionally, we achieve competitive results -- and in some cases surpass -- training-free methods that rely on supervised backbones, non-training-free unsupervised methods, as well as several fully supervised SOTA approaches. This demonstrates that label- and training-free CAC can be both scalable and effective. Code: this https URL.

11 Jun 2025

Knowledge Organization Systems (KOSs), such as term lists, thesauri, taxonomies, and ontologies, play a fundamental role in categorising, managing, and retrieving information. In the academic domain, KOSs are often adopted for representing research areas and their relationships, primarily aiming to classify research articles, academic courses, patents, books, scientific venues, domain experts, grants, software, experiment materials, and several other relevant products and agents. These structured representations of research areas, widely embraced by many academic fields, have proven effective in empowering AI-based systems to i) enhance retrievability of relevant documents, ii) enable advanced analytic solutions to quantify the impact of academic research, and iii) analyse and forecast research dynamics. This paper aims to present a comprehensive survey of the current KOS for academic disciplines. We analysed and compared 45 KOSs according to five main dimensions: scope, structure, curation, usage, and links to other KOSs. Our results reveal a very heterogeneous scenario in terms of scope, scale, quality, and usage, highlighting the need for more integrated solutions for representing research knowledge across academic fields. We conclude by discussing the main challenges and the most promising future directions.

23 Apr 2025
Multi-label requirements classification is a challenging task, especially
when dealing with numerous classes at varying levels of abstraction. The
difficulties increases when a limited number of requirements is available to
train a supervised classifier. Zero-shot learning (ZSL) does not require
training data and can potentially address this problem. This paper investigates
the performance of zero-shot classifiers (ZSCs) on a multi-label industrial
dataset. We focuse on classifying requirements according to a taxonomy designed
to support requirements tracing. We compare multiple variants of ZSCs using
different embeddings, including 9 language models (LMs) with a reduced number
of parameters (up to 3B), e.g., BERT, and 5 large LMs (LLMs) with a large
number of parameters (up to 70B), e.g., Llama. Our ground truth includes 377
requirements and 1968 labels from 6 output spaces. For the evaluation, we adopt
traditional metrics, i.e., precision, recall, F1, and , as well as a
novel label distance metric Dn. This aims to better capture the
classification's hierarchical nature and provides a more nuanced evaluation of
how far the results are from the ground truth. 1) The top-performing model on 5
out of 6 output spaces is T5-xl, with maximum = 0.78 and Dn = 0.04,
while BERT base outperformed the other models in one case, with maximum
= 0.83 and Dn = 0.04. 2) LMs with smaller parameter size produce the
best classification results compared to LLMs. Thus, addressing the problem in
practice is feasible as limited computing power is needed. 3) The model
architecture (autoencoding, autoregression, and sentence-to-sentence)
significantly affects the classifier's performance. We conclude that using ZSL
for multi-label requirements classification offers promising results. We also
present a novel metric that can be used to select the top-performing model for
this problem

08 Apr 2024
The recent events affecting global society continuously highlight the need to change the development lifecycle of complex systems by promoting human-centered solutions that increase awareness and ensure critical properties such as security, safety, trust, transparency, and privacy. This fast abstract introduces the Holistic Human-Centered Development Lifecycle (2HCDL) methodology focused on: (i) the enforcement of human values and properties and (ii) the mitigation and prevention of critical issues for more secure, safe, trustworthy, transparent, and private development processes.

28 Apr 2025

Visual object counting has recently shifted towards class-agnostic counting
(CAC), which addresses the challenge of counting objects across arbitrary
categories -- a crucial capability for flexible and generalizable counting
systems. Unlike humans, who effortlessly identify and count objects from
diverse categories without prior knowledge, most existing counting methods are
restricted to enumerating instances of known classes, requiring extensive
labeled datasets for training and struggling in open-vocabulary settings. In
contrast, CAC aims to count objects belonging to classes never seen during
training, operating in a few-shot setting. In this paper, we present the first
comprehensive review of CAC methodologies. We propose a taxonomy to categorize
CAC approaches into three paradigms based on how target object classes can be
specified: reference-based, reference-less, and open-world text-guided.
Reference-based approaches achieve state-of-the-art performance by relying on
exemplar-guided mechanisms. Reference-less methods eliminate exemplar
dependency by leveraging inherent image patterns. Finally, open-world
text-guided methods use vision-language models, enabling object class
descriptions via textual prompts, offering a flexible and promising solution.
Based on this taxonomy, we provide an overview of the architectures of 29 CAC
approaches and report their results on gold-standard benchmarks. We compare
their performance and discuss their strengths and limitations. Specifically, we
present results on the FSC-147 dataset, setting a leaderboard using
gold-standard metrics, and on the CARPK dataset to assess generalization
capabilities. Finally, we offer a critical discussion of persistent challenges,
such as annotation dependency and generalization, alongside future directions.
We believe this survey will be a valuable resource, showcasing CAC advancements
and guiding future research.

08 Jan 2025

Large language models (LLMs) are increasingly used to generate software artifacts, such as source code, tests, and trace links. Requirements play a central role in shaping the input prompts that guide LLMs, as they are often used as part of the prompts to synthesize the artifacts. However, the impact of requirements formulation on LLM performance remains unclear. In this paper, we investigate the role of requirements smells-indicators of potential issues like ambiguity and inconsistency-when used in prompts for LLMs. We conducted experiments using two LLMs focusing on automated trace link generation between requirements and code. Our results show mixed outcomes: while requirements smells had a small but significant effect when predicting whether a requirement was implemented in a piece of code (i.e., a trace link exists), no significant effect was observed when tracing the requirements with the associated lines of code. These findings suggest that requirements smells can affect LLM performance in certain SE tasks but may not uniformly impact all tasks. We highlight the need for further research to understand these nuances and propose future work toward developing guidelines for mitigating the negative effects of requirements smells in AI-driven SE processes.

18 Mar 2025

We propose a novel bio-inspired semi-supervised learning approach for training downsampling-upsampling semantic segmentation architectures. The first stage does not use backpropagation. Rather, it exploits the Hebbian principle ``fire together, wire together'' as a local learning rule for updating the weights of both convolutional and transpose-convolutional layers, allowing unsupervised discovery of data features. In the second stage, the model is fine-tuned with standard backpropagation on a small subset of labeled data. We evaluate our methodology through experiments conducted on several widely used biomedical datasets, deeming that this domain is paramount in computer vision and is notably impacted by data scarcity. Results show that our proposed method outperforms SOTA approaches across different levels of label availability. Furthermore, we show that using our unsupervised stage to initialize the SOTA approaches leads to performance improvements. The code to replicate our experiments can be found at this https URL

28 Jun 2024
 CNRSUniversitat Pompeu FabraRMIT UniversityIstituto Nazionale di Fisica NucleareUniversity of PadovaCNR-ISTISciences PoLearning Planet InstituteCity, University of LondonCREFIIIA-CSICUniversità degli Studi di Bari Aldo MoroSony Computer Science Laboratories - RomeComplex Systems Institute of Paris Île-de-France (ISC-PIF) CNRSPredict S.r.l.
CNRSUniversitat Pompeu FabraRMIT UniversityIstituto Nazionale di Fisica NucleareUniversity of PadovaCNR-ISTISciences PoLearning Planet InstituteCity, University of LondonCREFIIIA-CSICUniversità degli Studi di Bari Aldo MoroSony Computer Science Laboratories - RomeComplex Systems Institute of Paris Île-de-France (ISC-PIF) CNRSPredict S.r.l.Following recent policy changes by X (Twitter) and other social media
platforms, user interaction data has become increasingly difficult to access.
These restrictions are impeding robust research pertaining to social and
political phenomena online, which is critical due to the profound impact social
media platforms may have on our societies. Here, we investigate the reliability
of polarization measures obtained from different samples of social media data
by studying the structural polarization of the Polish political debate on
Twitter over a 24-hour period. First, we show that the political discussion on
Twitter is only a small subset of the wider Twitter discussion. Second, we find
that large samples can be representative of the whole political discussion on a
platform, but small samples consistently fail to accurately reflect the true
structure of polarization online. Finally, we demonstrate that keyword-based
samples can be representative if keywords are selected with great care, but
that poorly selected keywords can result in substantial political bias in the
sampled data. Our findings demonstrate that it is not possible to measure
polarization in a reliable way with small, sampled datasets, highlighting why
the current lack of research data is so problematic, and providing insight into
the practical implementation of the European Union's Digital Service Act which
aims to improve researchers' access to social media data.

18 Dec 2024
Query suggestion, a technique widely adopted in information retrieval,
enhances system interactivity and the browsing experience of document
collections. In cross-modal retrieval, many works have focused on retrieving
relevant items from natural language queries, while few have explored query
suggestion solutions. In this work, we address query suggestion in cross-modal
retrieval, introducing a novel task that focuses on suggesting minimal textual
modifications needed to explore visually consistent subsets of the collection,
following the premise of ''Maybe you are looking for''. To facilitate the
evaluation and development of methods, we present a tailored benchmark named
CroQS. This dataset comprises initial queries, grouped result sets, and
human-defined suggested queries for each group. We establish dedicated metrics
to rigorously evaluate the performance of various methods on this task,
measuring representativeness, cluster specificity, and similarity of the
suggested queries to the original ones. Baseline methods from related fields,
such as image captioning and content summarization, are adapted for this task
to provide reference performance scores. Although relatively far from human
performance, our experiments reveal that both LLM-based and captioning-based
methods achieve competitive results on CroQS, improving the recall on cluster
specificity by more than 115% and representativeness mAP by more than 52% with
respect to the initial query. The dataset, the implementation of the baseline
methods and the notebooks containing our experiments are available here:
this https URL
29 Nov 2024
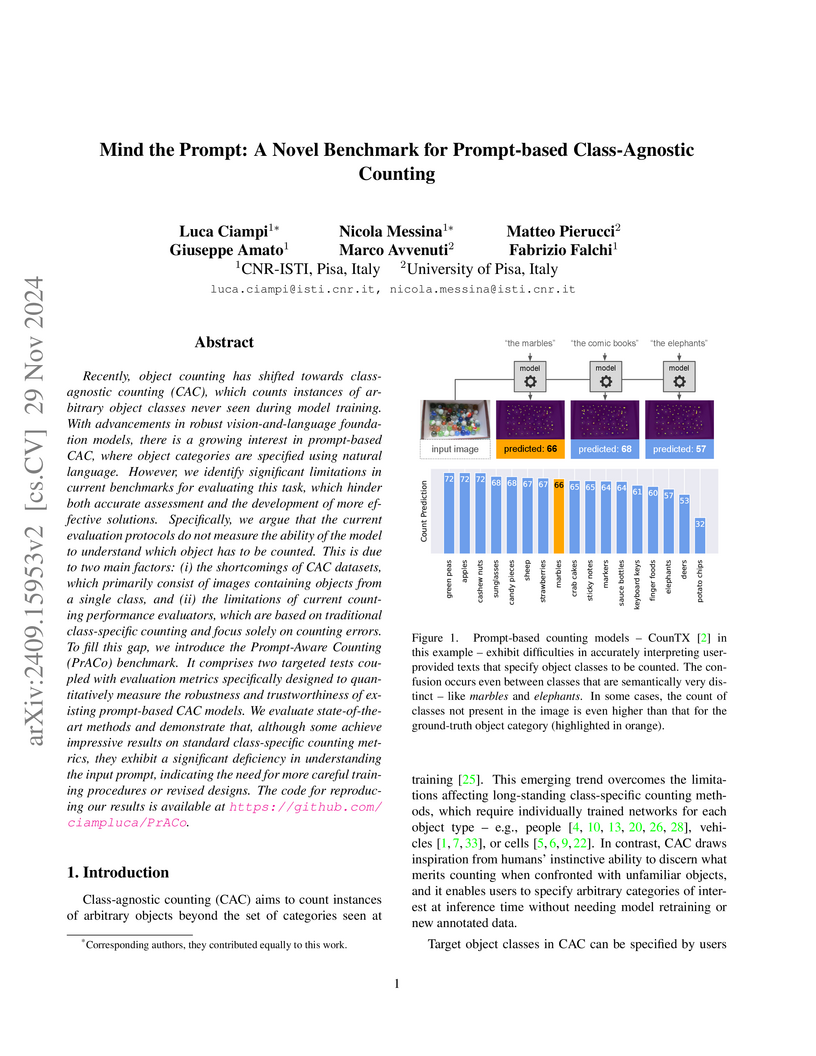
Recently, object counting has shifted towards class-agnostic counting (CAC), which counts instances of arbitrary object classes never seen during model training. With advancements in robust vision-and-language foundation models, there is a growing interest in prompt-based CAC, where object categories are specified using natural language. However, we identify significant limitations in current benchmarks for evaluating this task, which hinder both accurate assessment and the development of more effective solutions. Specifically, we argue that the current evaluation protocols do not measure the ability of the model to understand which object has to be counted. This is due to two main factors: (i) the shortcomings of CAC datasets, which primarily consist of images containing objects from a single class, and (ii) the limitations of current counting performance evaluators, which are based on traditional class-specific counting and focus solely on counting errors. To fill this gap, we introduce the Prompt-Aware Counting (PrACo) benchmark. It comprises two targeted tests coupled with evaluation metrics specifically designed to quantitatively measure the robustness and trustworthiness of existing prompt-based CAC models. We evaluate state-of-the-art methods and demonstrate that, although some achieve impressive results on standard class-specific counting metrics, they exhibit a significant deficiency in understanding the input prompt, indicating the need for more careful training procedures or revised designs. The code for reproducing our results is available at this https URL.

13 May 2025
Accurate affiliation matching, which links affiliation strings to
standardized organization identifiers, is critical for improving research
metadata quality, facilitating comprehensive bibliometric analyses, and
supporting data interoperability across scholarly knowledge bases. Existing
approaches fail to handle the complexity of affiliation strings that often
include mentions of multiple organizations or extraneous information. In this
paper, we present AffRo, a novel approach designed to address these challenges,
leveraging advanced parsing and disambiguation techniques. We also introduce
AffRoDB, an expert-curated dataset to systematically evaluate affiliation
matching algorithms, ensuring robust benchmarking. Results demonstrate the
effectiveness of AffRp in accurately identifying organizations from complex
affiliation strings.

26 May 2025
In this paper, we introduce a deep learning solution for video activity
recognition that leverages an innovative combination of convolutional layers
with a linear-complexity attention mechanism. Moreover, we introduce a novel
quantization mechanism to further improve the efficiency of our model during
both training and inference. Our model maintains a reduced computational cost,
while preserving robust learning and generalization capabilities. Our approach
addresses the issues related to the high computing requirements of current
models, with the goal of achieving competitive accuracy on consumer and edge
devices, enabling smart home and smart healthcare applications where efficiency
and privacy issues are of concern. We experimentally validate our model on
different established and publicly available video activity recognition
benchmarks, improving accuracy over alternative models at a competitive
computing cost.

01 Mar 2023
OWL ontologies are a quite popular way to describe structured knowledge in terms of classes, relations among classes and class instances. In this paper, given a target class T of an OWL ontology, with a focus on ontologies with real- and boolean-valued data properties, we address the problem of learning graded fuzzy concept inclusion axioms with the aim of describing enough conditions for being an individual classified as instance of the class T. To do so, we present PN-OWL that is a two-stage learning algorithm made of a P-stage and an N-stage. Roughly, in the P-stage the algorithm tries to cover as many positive examples as possible (increase recall), without compromising too much precision, while in the N-stage, the algorithm tries to rule out as many false positives, covered by the P-stage, as possible. PN-OWL then aggregates the fuzzy inclusion axioms learnt at the P-stage and the N-stage by combining them via aggregation functions to allow for a final decision whether an individual is instance of T or not. We also illustrate its effectiveness by means of an experimentation. An interesting feature is that fuzzy datatypes are built automatically, the learnt fuzzy concept inclusions can be represented directly into Fuzzy OWL 2 and, thus, any Fuzzy OWL 2 reasoner can then be used to automatically determine/classify (and to which degree) whether an individual belongs to the target class T or not.

14 Nov 2018
Recent research on spatial and spatio-temporal model checking provides novel
image analysis methodologies, rooted in logical methods for topological spaces.
Medical Imaging (MI) is a field where such methods show potential for
ground-breaking innovation. Our starting point is SLCS, the Spatial Logic for
Closure Spaces -- Closure Spaces being a generalisation of topological spaces,
covering also discrete space structures -- and topochecker, a model-checker for
SLCS (and extensions thereof). We introduce the logical language ImgQL ("Image
Query Language"). ImgQL extends SLCS with logical operators describing distance
and region similarity. The spatio-temporal model checker topochecker is
correspondingly enhanced with state-of-the-art algorithms, borrowed from
computational image processing, for efficient implementation of distancebased
operators, namely distance transforms. Similarity between regions is defined by
means of a statistical similarity operator, based on notions from statistical
texture analysis. We illustrate our approach by means of two examples of
analysis of Magnetic Resonance images: segmentation of glioblastoma and its
oedema, and segmentation of rectal carcinoma.

13 Jun 2025
This study investigates the emotional dynamics of Italian soccer fandoms through computational analysis of user-generated content from official Instagram accounts of 83 teams across Serie A, Serie B, and Lega Pro during the 2023-24 season. By applying sentiment analysis to fan comments, we extract temporal emotional patterns and identify distinct clusters of fan bases with similar preseason expectations. Drawing from complex systems theory, we characterize joy as displaying anti-bursty temporal distributions, while anger is marked by pronounced bursty patterns. Our analysis reveals significant correlations between these emotional signals, preseason expectations, socioeconomic factors, and final league rankings. In particular, the burstiness metric emerges as a meaningful correlate of team performance; statistical models excluding this parameter show a decrease in the coefficient of determination of 32%. These findings offer novel insights into the relationship between fan emotional expression and team outcomes, suggesting potential avenues for research in sports analytics, social media dynamics, and fan engagement studies.

01 Jul 2025
Positional bias in binary question answering occurs when a model systematically favors one choice over another based solely on the ordering of presented options. In this study, we quantify and analyze positional bias across five large language models under varying degrees of answer uncertainty. We re-adapted the SQuAD-it dataset by adding an extra incorrect answer option and then created multiple versions with progressively less context and more out-of-context answers, yielding datasets that range from low to high uncertainty. Additionally, we evaluate two naturally higher-uncertainty benchmarks: (1) WebGPT - question pairs with unequal human-assigned quality scores, and (2) Winning Arguments - where models predict the more persuasive argument in Reddit's r/ChangeMyView exchanges. Across each dataset, the order of the "correct" (or higher-quality/persuasive) option is systematically flipped (first placed in position 1, then in position 2) to compute both Preference Fairness and Position Consistency. We observe that positional bias is nearly absent under low-uncertainty conditions, but grows exponentially when it becomes doubtful to decide which option is correct.
There are no more papers matching your filters at the moment.
