 Beijing Jiaotong University
Beijing Jiaotong University
18 Sep 2024
GUNet: A Graph Convolutional Network United Diffusion Model for Stable and Diversity Pose Generation
GUNet: A Graph Convolutional Network United Diffusion Model for Stable and Diversity Pose Generation
PoseDiffusion, featuring the GUNet architecture, utilizes a diffusion model integrated with Graph Convolutional Networks to generate diverse and anatomically correct 2D human pose skeletons directly from text. This method achieves a Mean Squared Error of 262.2 for keypoint prediction and a variance of 244.5, surpassing GAN-based approaches and improving downstream image generation quality when used with models like ControlNet.

27 Oct 2025



Researchers systematically analyzed reinforcement learning techniques for enhancing large language model reasoning, demonstrating that a minimalist combination of two empirically validated methods can consistently outperform more complex, multi-trick algorithms. The work clarifies the conditional effectiveness of various RL components across different model scales, alignment statuses, and data difficulties.

06 Dec 2025
 Monash UniversityCSIRO
Monash UniversityCSIRO Chinese Academy of SciencesSichuan University
Chinese Academy of SciencesSichuan University University of Manchester
University of Manchester Beihang University
Beihang University Nanjing University
Nanjing University Zhejiang University
Zhejiang University ByteDanceShanghai AI LabHarbin Institute of TechnologyBeijing Jiaotong University
ByteDanceShanghai AI LabHarbin Institute of TechnologyBeijing Jiaotong University Huawei
Huawei Nanyang Technological UniversityNTUBeijing University of Posts and TelecommunicationsUniversity of Sheffield
Nanyang Technological UniversityNTUBeijing University of Posts and TelecommunicationsUniversity of Sheffield TencentAlibabaHuawei CloudStepFunTeleAIOPPOHong Kong University of Science and Technology (Guangzhou)KuaiShouM-A-PChinese Academy of Sciences, Institute of AutomationUOM
TencentAlibabaHuawei CloudStepFunTeleAIOPPOHong Kong University of Science and Technology (Guangzhou)KuaiShouM-A-PChinese Academy of Sciences, Institute of AutomationUOMA comprehensive synthesis of Large Language Models for automated software development covers the entire model lifecycle, from data curation to autonomous agents, and offers practical guidance derived from empirical experiments on pre-training, fine-tuning, and reinforcement learning, alongside a detailed analysis of challenges and future directions.

01 Feb 2024


Researchers from ICT, Chinese Academy of Sciences, developed FedCache, a knowledge cache-driven federated learning architecture that facilitates personalized edge intelligence. It achieves performance comparable to state-of-the-art methods while reducing communication overhead by more than two orders of magnitude, notably being the first sample-grained logits interaction method without feature transmission or public datasets.

14 Oct 2025

The MemAct framework enables Large Language Model agents to autonomously manage their working memory by treating context curation as learnable actions, addressing a critical bottleneck in long-horizon tasks. This approach achieves 59.1% accuracy on multi-objective QA while reducing average context tokens to 3,447, outperforming larger baselines and improving training efficiency by up to 40%.

25 Aug 2025
Researchers from multiple international institutions propose a unified methodological taxonomy and formal language for LLM-based agentic reasoning frameworks, systematically surveying their progress, application scenarios, and evaluation strategies across diverse domains like scientific research and healthcare. This work provides a structured view of single-agent, tool-based, and multi-agent approaches, clarifying the rapidly evolving landscape.

26 Oct 2025
The paper surveys a paradigm shift in agentic AI from externally orchestrated, pipeline-based systems to model-native approaches, where core capabilities like planning, tool use, and memory are internalized. This transition is primarily driven by integrating Reinforcement Learning with Large Language Models, leading to more autonomous and adaptable AI systems.

14 Oct 2025



CoIRL-AD presents a competitive dual-policy framework for end-to-end autonomous driving, integrating imitation learning and reinforcement learning within a latent world model. This approach achieves substantial reductions in collision rates and improves generalization on nuScenes and Navsim benchmarks.
22 Oct 2025

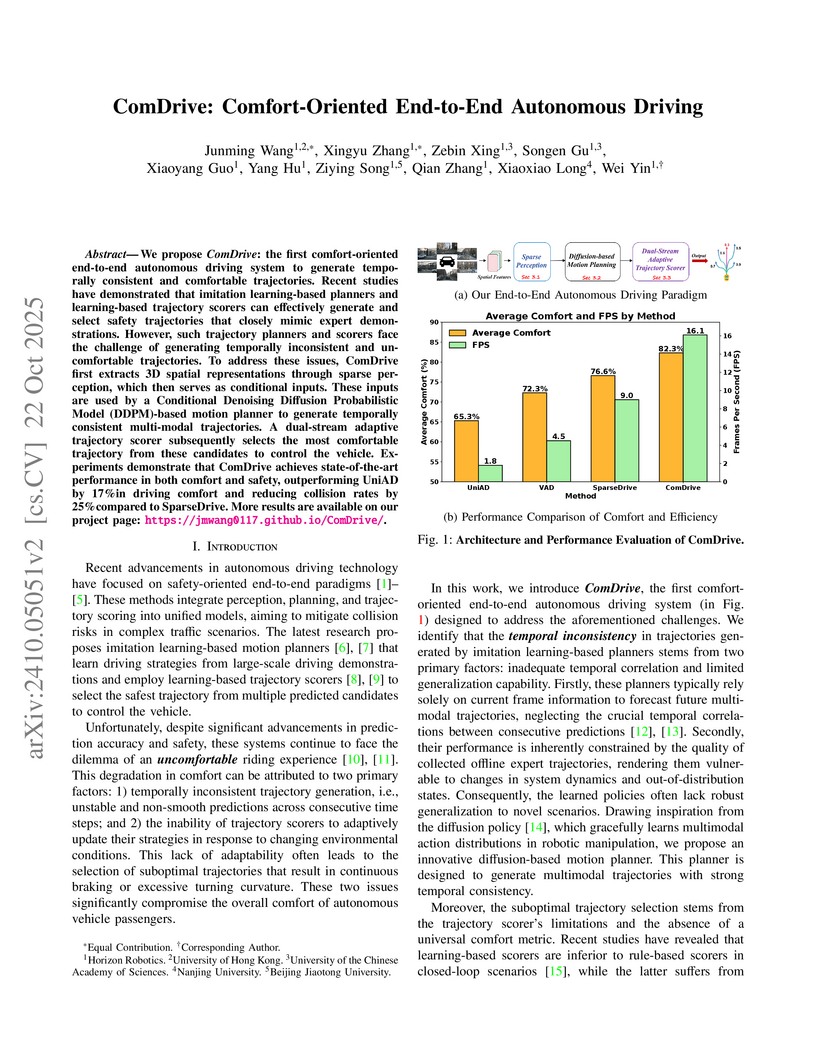
We propose ComDrive: the first comfort-oriented end-to-end autonomous driving system to generate temporally consistent and comfortable trajectories. Recent studies have demonstrated that imitation learning-based planners and learning-based trajectory scorers can effectively generate and select safety trajectories that closely mimic expert demonstrations. However, such trajectory planners and scorers face the challenge of generating temporally inconsistent and uncomfortable trajectories. To address these issues, ComDrive first extracts 3D spatial representations through sparse perception, which then serves as conditional inputs. These inputs are used by a Conditional Denoising Diffusion Probabilistic Model (DDPM)-based motion planner to generate temporally consistent multi-modal trajectories. A dual-stream adaptive trajectory scorer subsequently selects the most comfortable trajectory from these candidates to control the vehicle. Experiments demonstrate that ComDrive achieves state-of-the-art performance in both comfort and safety, outperforming UniAD by 17% in driving comfort and reducing collision rates by 25% compared to SparseDrive. More results are available on our project page: this https URL.

29 Aug 2025
A method enhancing Small Language Models (SLMs) for creative writing leverages AI feedback through two distinct strategies: a multi-agent refined reward model and a principle-guided LLM-as-a-Judge. The LLM-as-a-Judge approach, employing adversarial optimization and reflection, achieved state-of-the-art performance in generating Chinese greetings, outperforming larger models while requiring less data and computational resources.

05 Mar 2025
This research investigates whether deep generative models can learn complex knowledge from unlabeled video data alone, contrasting with text-based models. It introduces VideoWorld, an auto-regressive video generation model from Beijing Jiaotong University and ByteDance Seed, enhanced with a Latent Dynamics Model (LDM) to represent multi-step visual changes. The model achieved a 5-dan professional Go playing ability and demonstrated strong performance in robotic manipulation tasks by learning from visual observation without explicit rewards or labels.

13 Mar 2025
LatentSync introduces an audio-conditioned Latent Diffusion Model for high-resolution lip synchronization, addressing the 'shortcut learning problem' by integrating enhanced SyncNet supervision and a temporal consistency mechanism. The framework achieves state-of-the-art performance across lip-sync accuracy, visual quality, and temporal consistency on HDTF and VoxCeleb2 datasets.

29 Aug 2025
BrainGPT: Unleashing the Potential of EEG Generalist Foundation Model by Autoregressive Pre-training
BrainGPT: Unleashing the Potential of EEG Generalist Foundation Model by Autoregressive Pre-training
BrainGPT introduces the first generalist foundation model for Electroencephalogram (EEG) signals, employing an autoregressive pre-training paradigm and a multi-task transfer learning framework. It unifies heterogeneous EEG data and achieves superior performance across 12 benchmarks in five distinct EEG tasks, with the largest variant (BrainGPT-Giant) demonstrating average accuracy improvements up to 11.20%.

05 Dec 2024
The C2P-CLIP method enhances deepfake detection by injecting category-common prompts into a fine-tuned CLIP model, achieving a mean accuracy of 93.79% and mAP of 98.66% on the UniversalFakeDetect dataset, a substantial 12.41% and 8.52% improvement over baseline UniFd, respectively, without adding inference parameters. This approach leverages an understanding that CLIP detects forgeries by matching similar concepts rather than semantic content.

06 Dec 2025



Diffusion models have been widely used in time series and spatio-temporal data, enhancing generative, inferential, and downstream capabilities. These models are applied across diverse fields such as healthcare, recommendation, climate, energy, audio, and traffic. By separating applications for time series and spatio-temporal data, we offer a structured perspective on model category, task type, data modality, and practical application domain. This study aims to provide a solid foundation for researchers and practitioners, inspiring future innovations that tackle traditional challenges and foster novel solutions in diffusion model-based data mining tasks and applications. For more detailed information, we have open-sourced a repository at this https URL.

15 Jul 2025
Researchers from Fudan University and collaborators developed SVTRv2, a Connectionist Temporal Classification (CTC)-based model for Scene Text Recognition that overcomes traditional limitations to achieve state-of-the-art accuracy. This new architecture matches or surpasses leading encoder-decoder models across various challenging benchmarks while maintaining the inherent efficiency and speed advantage of CTC models, demonstrating up to 8 times faster inference than previous top models like MAERec while also improving accuracy by 0.97% on the U14M benchmark.

28 Nov 2025
AnyTalker presents a framework for scalable multi-person talking video generation, utilizing a two-stage training strategy that leverages approximately 1000 hours of single-person data and only 12 hours of authentic multi-person interaction. This approach achieves state-of-the-art interactivity and visual quality, demonstrating generalization to an arbitrary number of identities and diverse input types while significantly reducing data collection costs.
14 May 2024
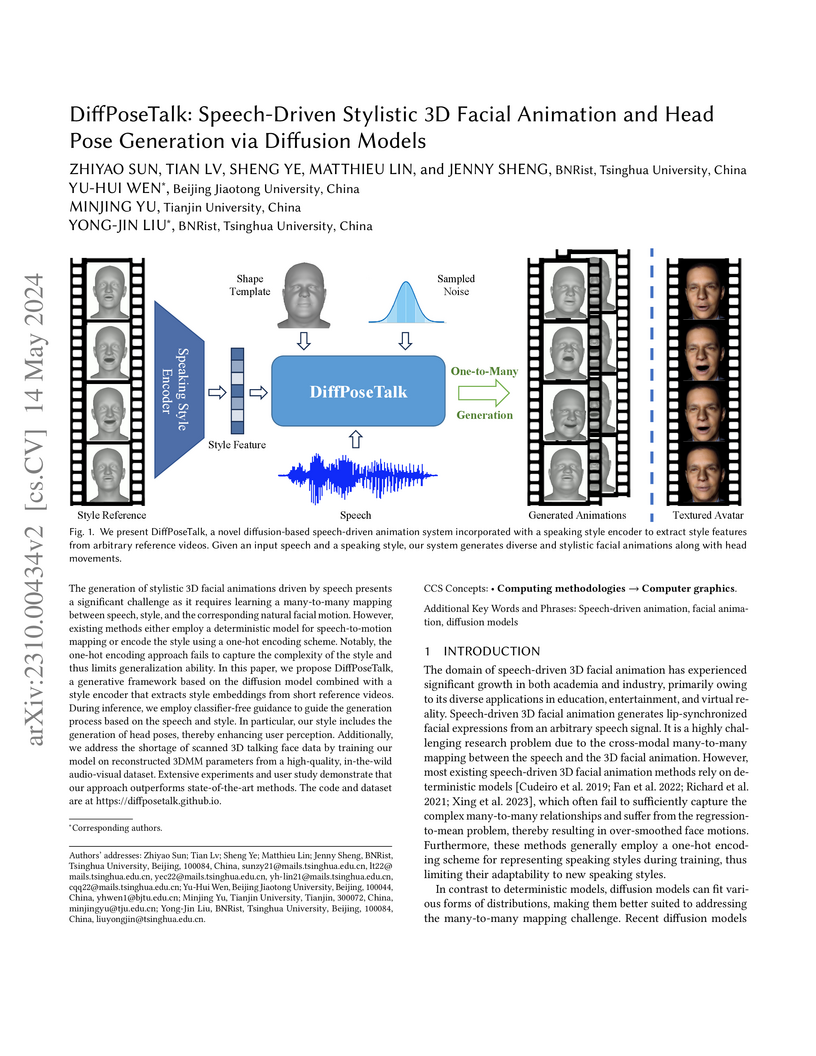
DiffPoseTalk introduces a diffusion-based framework for generating diverse and stylistically controllable 3D facial animations and co-speech head poses from speech input. The approach leverages a novel speaking style encoder and demonstrates improved lip synchronization and naturalness over prior methods, achieving lower Lip Vertex Error and better Beat Alignment.

13 Aug 2025

Researchers from National University of Singapore and collaborators provide the first comprehensive survey on efficient inference for Large Reasoning Models (LRMs), establishing a taxonomy of methods that reduce token consumption and improve inference time while maintaining reasoning quality. The work categorizes approaches into explicit compact Chain-of-Thought and implicit latent Chain-of-Thought, identifying current limitations and future research avenues.

28 May 2025
Researchers from Beijing Jiaotong University and the Chinese Academy of Sciences developed OmniAD, a framework that unifies industrial anomaly detection and understanding through multimodal reasoning. This system provides detailed explanations of defects by combining visual localization with textual analysis, achieving 79.1% accuracy on anomaly understanding tasks on the MMAD benchmark and threshold-free anomaly detection with 92.2% F1-max on image-level detection.
There are no more papers matching your filters at the moment.
