
19 Sep 2025

Randomized smoothing (RS) is one of the prominent techniques to ensure the correctness of machine learning models, where point-wise robustness certificates can be derived analytically. While RS is well understood for classification, its application to generative models is unclear, since their outputs are sequences rather than labels. We resolve this by connecting generative outputs to an oracle classification task and showing that RS can still be enabled: the final response can be classified as a discrete action (e.g., service-robot commands in VLAs), as harmful vs. harmless (content moderation or toxicity detection in VLMs), or even applying oracles to cluster answers into semantically equivalent ones. Provided that the error rate for the oracle classifier comparison is bounded, we develop the theory that associates the number of samples with the corresponding robustness radius. We further derive improved scaling laws analytically relating the certified radius and accuracy to the number of samples, showing that the earlier result of 2 to 3 orders of magnitude fewer samples sufficing with minimal loss remains valid even under weaker assumptions. Together, these advances make robustness certification both well-defined and computationally feasible for state-of-the-art VLMs, as validated against recent jailbreak-style adversarial attacks.

05 Mar 2025
Human-in-the-loop Reasoning For Traffic Sign Detection: Collaborative Approach Yolo With Video-llava
Human-in-the-loop Reasoning For Traffic Sign Detection: Collaborative Approach Yolo With Video-llava
Traffic Sign Recognition (TSR) detection is a crucial component of autonomous
vehicles. While You Only Look Once (YOLO) is a popular real-time object
detection algorithm, factors like training data quality and adverse weather
conditions (e.g., heavy rain) can lead to detection failures. These failures
can be particularly dangerous when visual similarities between objects exist,
such as mistaking a 30 km/h sign for a higher speed limit sign. This paper
proposes a method that combines video analysis and reasoning, prompting with a
human-in-the-loop guide large vision model to improve YOLOs accuracy in
detecting road speed limit signs, especially in semi-real-world conditions. It
is hypothesized that the guided prompting and reasoning abilities of
Video-LLava can enhance YOLOs traffic sign detection capabilities. This
hypothesis is supported by an evaluation based on human-annotated accuracy
metrics within a dataset of recorded videos from the CARLA car simulator. The
results demonstrate that a collaborative approach combining YOLO with
Video-LLava and reasoning can effectively address challenging situations such
as heavy rain and overcast conditions that hinder YOLOs detection capabilities.

13 Oct 2025
Ambisonics is a method for capturing and rendering a sound field accurately, assuming that the acoustics of the playback room does not significantly influence the sound field. However, in practice, the acoustics of the playback room may lead to a noticeable degradation in sound quality. We propose a recording and rendering method based on Ambisonics that utilizes a perceptually-motivated approach to compensate for the reverberation of the playback room. The recorded direct and reverberant sound field components in the spherical harmonics (SHs) domain are spectrally and spatially compensated to preserve the relevant auditory cues including the direction of arrival of the direct sound, the spectral energy of the direct and reverberant sound components, and the Interaural Coherence (IC) across each auditory band. In contrast to the conventional Ambisonics, a flexible number of Ambisonics channels can be used for audio rendering. Listening test results show that the proposed method provides a perceptually accurate rendering of the originally recorded sound field, outperforming both conventional Ambisonics without compensation and even ideal Ambisonics rendering in a simulated anechoic room. Additionally, subjective evaluations of listeners seated at the center of the loudspeaker array demonstrate that the method remains robust to head rotation and minor displacements.

30 Aug 2025



Personalized binaural audio reproduction is the basis of realistic spatial localization, sound externalization, and immersive listening, directly shaping user experience and listening effort. This survey reviews recent advances in deep learning for this task and organizes them by generation mechanism into two paradigms: explicit personalized filtering and end-to-end rendering. Explicit methods predict personalized head-related transfer functions (HRTFs) from sparse measurements, morphological features, or environmental cues, and then use them in the conventional rendering pipeline. End-to-end methods map source signals directly to binaural signals, aided by other inputs such as visual, textual, or parametric guidance, and they learn personalization within the model. We also summarize the field's main datasets and evaluation metrics to support fair and repeatable comparison. Finally, we conclude with a discussion of key applications enabled by these technologies, current technical limitations, and potential research directions for deep learning-based spatial audio systems.

16 May 2024
Large Language Models (LLMs) exhibit world knowledge and inference capabilities, making them powerful tools for various applications. This paper proposes a feedback loop mechanism that leverages these capabilities to tune Evolution Strategies (ES) parameters effectively. The mechanism involves a structured process of providing programming instructions, executing the corresponding code, and conducting thorough analysis. This process is specifically designed for the optimization of ES parameters. The method operates through an iterative cycle, ensuring continuous refinement of the ES parameters. First, LLMs process the instructions to generate or modify the code. The code is then executed, and the results are meticulously logged. Subsequent analysis of these results provides insights that drive further improvements. An experiment on tuning the learning rates of ES using the LLaMA3 model demonstrate the feasibility of this approach. This research illustrates how LLMs can be harnessed to improve ES algorithms' performance and suggests broader applications for similar feedback loop mechanisms in various domains.

19 Aug 2024
This research explores using Large Language Models for hybrid reasoning in autonomous driving, demonstrating their capacity to generate precise vehicle control commands. The study shows that combining common-sense and arithmetic reasoning enables LLMs to make more accurate and actionable decisions compared to either method alone, particularly in challenging weather conditions, improving decision-making for autonomous vehicles.

27 Oct 2025

The interaction of a quantum two-level system with a resonant driving field results in the emergence of Rabi oscillations, which are the hallmark of a controlled manipulation of a quantum state on the Bloch sphere. This all-optical coherent control of solid-state two-level systems is crucial for quantum applications. In this work we study Rabi oscillations emerging in a WSe2 monolayer-based quantum dot. The emitter is driven coherently using picosecond laser pulses to a higher-energy state, while photoluminescence is probed from the ground state. The theoretical treatment based on a three-level exciton model reveals the population transfer between the exciton ground and excited states coupled by Coulomb interaction. Our calculations demonstrate that the resulting exciton ground state population can be controlled by varying driving pulse area and detuning which is evidenced by the experimental data. Our results pave the way towards the coherent control of quantum emitters in atomically thin semiconductors, a crucial ingredient for monolayer-based high-performance, on-demand single photon sources.

16 Sep 2025
Evaluating object detection models in deployment is challenging because ground-truth annotations are rarely available. We introduce the Cumulative Consensus Score (CCS), a label-free metric that enables continuous monitoring and comparison of detectors in real-world settings. CCS applies test-time data augmentation to each image, collects predicted bounding boxes across augmented views, and computes overlaps using Intersection over Union. Maximum overlaps are normalized and averaged across augmentation pairs, yielding a measure of spatial consistency that serves as a proxy for reliability without annotations. In controlled experiments on Open Images and KITTI, CCS achieved over 90% congruence with F1-score, Probabilistic Detection Quality, and Optimal Correction Cost. The method is model-agnostic, working across single-stage and two-stage detectors, and operates at the case level to highlight under-performing scenarios. Altogether, CCS provides a robust foundation for DevOps-style monitoring of object detectors.

02 Mar 2023


We consider the problem of explaining the temporal behavior of black-box systems using human-interpretable models. To this end, based on recent research trends, we rely on the fundamental yet interpretable models of deterministic finite automata (DFAs) and linear temporal logic (LTL) formulas. In contrast to most existing works for learning DFAs and LTL formulas, we rely on only positive examples. Our motivation is that negative examples are generally difficult to observe, in particular, from black-box systems. To learn meaningful models from positive examples only, we design algorithms that rely on conciseness and language minimality of models as regularizers. To this end, our algorithms adopt two approaches: a symbolic and a counterexample-guided one. While the symbolic approach exploits an efficient encoding of language minimality as a constraint satisfaction problem, the counterexample-guided one relies on generating suitable negative examples to prune the search. Both the approaches provide us with effective algorithms with theoretical guarantees on the learned models. To assess the effectiveness of our algorithms, we evaluate all of them on synthetic data.

27 Oct 2025
Fully homomorphic encryption allows the evaluation of arbitrary functions on encrypted data. It can be leveraged to secure outsourced and multiparty computation. TFHE is a fast torus-based fully homomorphic encryption scheme that allows both linear operations, as well as the evaluation of arbitrary non-linear functions. It currently provides the fastest bootstrapping operation performance of any other FHE scheme. Despite its fast performance, TFHE suffers from a considerably higher computational overhead for the evaluation of homomorphic circuits. Computations in the encrypted domain are orders of magnitude slower than their unencrypted equivalents. This bottleneck hinders the widespread adoption of (T)FHE for the protection of sensitive data. While state-of-the-art implementations focused on accelerating and outsourcing single operations, their scalability and practicality are constrained by high memory bandwidth costs. In order to overcome this, we propose an FPGA-based hardware accelerator for the evaluation of homomorphic circuits. Specifically, we design a functionally complete TFHE processor for FPGA hardware capable of processing instructions on the data completely on the FPGA. In order to achieve a higher throughput from our TFHE processor, we implement an improved programmable bootstrapping module which outperforms the current state-of-the-art by 240\% to 480\% more bootstrappings per second. Our efficient, compact, and scalable design lays the foundation for implementing complete FPGA-based TFHE processor architectures.

25 Oct 2015
This paper presents a direct method to obtain the deterministic and stochastic contribution of the sum of two independent sets of stochastic processes, one of which is composed by Ornstein-Uhlenbeck processes and the other being a general (non-linear) Langevin process. The method is able to distinguish between all stochastic process, retrieving their corresponding stochastic evolution equations. This framework is based on a recent approach for the analysis of multidimensional Langevin-type stochastic processes in the presence of strong measurement (or observational) noise, which is here extended to impose neither constraints nor parameters and extract all coefficients directly from the empirical data sets. Using synthetic data, it is shown that the method yields satisfactory results.

18 Jun 2023
The reuse of research software is central to research efficiency and academic exchange. The application of software enables researchers with varied backgrounds to reproduce, validate, and expand upon study findings. Furthermore, the analysis of open source code aids in the comprehension, comparison, and integration of approaches. Often, however, no further use occurs because relevant software cannot be found or is incompatible with existing research processes. This results in repetitive software development, which impedes the advancement of individual researchers and entire research communities. In this article, the DataDesc ecosystem is presented, an approach to describing data models of software interfaces with detailed and machine-actionable metadata. In addition to a specialized metadata schema, an exchange format and support tools for easy collection and the automated publishing of software documentation are introduced. This approach practically increases the FAIRness, i.e., findability, accessibility, interoperability, and so the reusability of research software, as well as effectively promotes its impact on research.
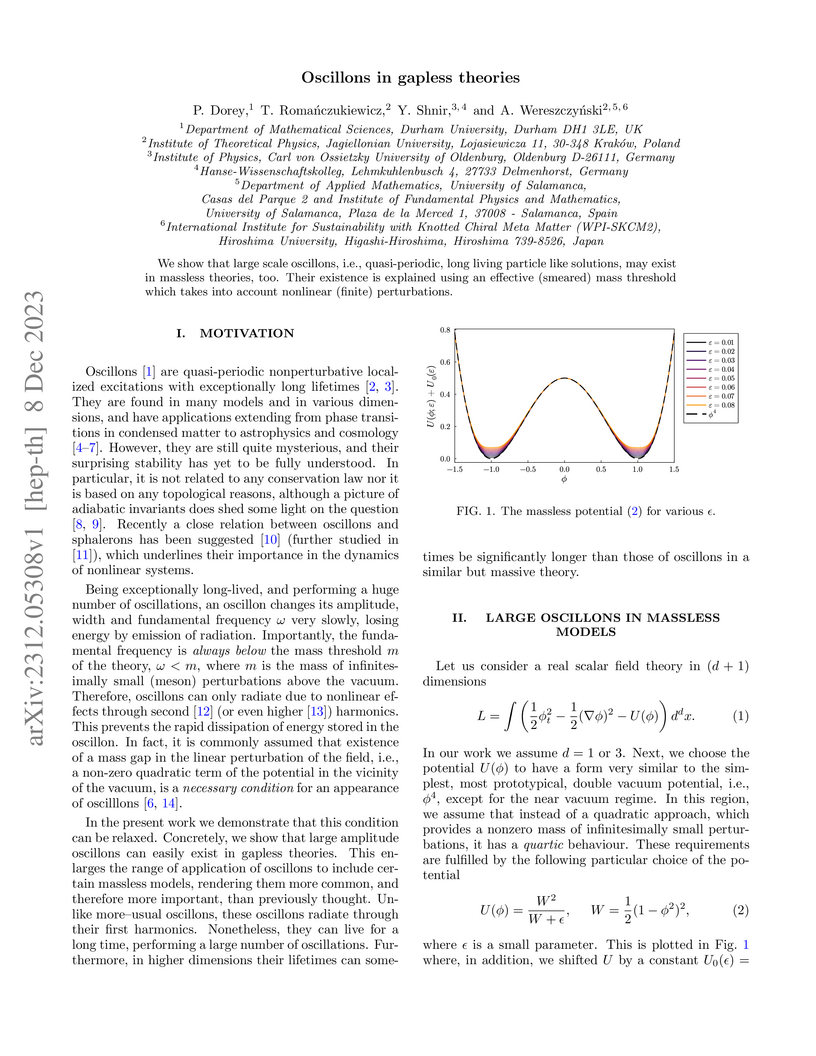
08 Dec 2023

We show that large scale oscillons, i.e., quasi-periodic, long living
particle like solutions, may exist in massless theories, too. Their existence
is explained using an effective (smeared) mass threshold which takes into
account nonlinear (finite) perturbations.

11 Jul 2013
We apply recent methods in stochastic data analysis for discovering a set of
few stochastic variables that represent the relevant information on a
multivariate stochastic system, used as input for artificial neural networks
models for air quality forecast. We show that using these derived variables as
input variables for training the neural networks it is possible to
significantly reduce the amount of input variables necessary for the neural
network model, without considerably changing the predictive power of the model.
The reduced set of variables including these derived variables is therefore
proposed as optimal variable set for training neural networks models in
forecasting geophysical and weather properties. Finally, we briefly discuss
other possible applications of such optimized neural network models.

03 Feb 2025




Asteroid discoveries are essential for planetary-defense efforts aiming to prevent impacts with Earth, including the more frequent megaton explosions from decameter impactors. While large asteroids (100 km) have remained in the main belt since their formation, small asteroids are commonly transported to the near-Earth object (NEO) population. However, due to the lack of direct observational constraints, their size-frequency distribution--which informs our understanding of the NEOs and the delivery of meteorite samples to Earth--varies significantly among models. Here, we report 138 detections of the smallest asteroids (10 m) ever observed in the main belt, which were enabled by JWST's infrared capabilities covering the asteroids' emission peaks and synthetic tracking techniques. Despite small orbital arcs, we constrain the objects' distances and phase angles using known asteroids as proxies, allowing us to derive sizes via radiometric techniques. Their size-frequency distribution exhibits a break at m (debiased cumulative slopes of and for diameters smaller and larger than 100 m, respectively), suggestive of a population driven by collisional cascade. These asteroids were sampled from multiple asteroid families--most likely Nysa, Polana and Massalia--according to the geometry of pointings considered here. Through additional long-stare infrared observations, JWST is poised to serendipitously detect thousands of decameter-scale asteroids across the sky, probing individual asteroid families and the source regions of meteorites "in-situ".

31 May 2024
In an era of rapidly advancing data-driven applications, there is a growing
demand for data in both research and practice. Synthetic data have emerged as
an alternative when no real data is available (e.g., due to privacy
regulations). Synthesizing tabular data presents unique and complex challenges,
especially handling (i) missing values, (ii) dataset imbalance, (iii) diverse
column types, and (iv) complex data distributions, as well as preserving (i)
column correlations, (ii) temporal dependencies, and (iii) integrity
constraints (e.g., functional dependencies) present in the original dataset.
While substantial progress has been made recently in the context of
generational models, there is no one-size-fits-all solution for tabular data
today, and choosing the right tool for a given task is therefore no trivial
task. In this paper, we survey the state of the art in Tabular Data Synthesis
(TDS), examine the needs of users by defining a set of functional and
non-functional requirements, and compile the challenges associated with meeting
those needs. In addition, we evaluate the reported performance of 36 popular
research TDS tools about these requirements and develop a decision guide to
help users find suitable TDS tools for their applications. The resulting
decision guide also identifies significant research gaps.

26 Aug 2024
The phase-resolved imaging of confined light fields by homodyne detection is
a cornerstone of metrology in nano-optics and photonics, but its application in
electron microscopy has been limited so far. Here, we report the mapping of
optical modes in a waveguide structure by illumination with femtosecond light
pulses in a continuous-beam transmission electron microscope. Multi-photon
photoemission results in a remanent charging pattern which we image by Lorentz
microscopy. The resulting image contrast is linked to the intensity
distribution of the standing light wave and quantitatively described within an
analytical model. The robustness of the approach is showcased in a wider
parameter range and more complex sample geometries including micro- and
nanostructures. We discuss further applications of light-interference-based
charging for electron microscopy with in-situ optical excitation, laying the
foundation for advanced measurement schemes for the phase-resolved imaging of
propagating light fields.

30 Apr 2019
With the usage of two transparent electrodes, organic solar cells are
semitransparent and may be combined to parallel-connected multi-junction
devices or used for innovative applications like power-generating windows. A
challenging issue is the optimization of the electrodes, in order to combine
high transparency with adequate electric properties. In the present work, we
study the potential of sputter-deposited aluminum-doped zinc oxide (AZO) as an
alternative to the widely used but relatively expensive indium tin oxide (ITO)
as cathode material in semitransparent polymer-fullerene solar cells.
Concerning the anode, we utilized an insulator/metal/insulator structure based
on ultra-thin Au films embedded between two evaporated MoO layers, with the
outer MoO film (capping layer) serving as a light coupling layer. The
performance of the ITO-free semitransparent solar cells is systematically
studied as dependent on the thickness of the capping layer and the active
layer, as well as the illumination direction. These variations are found to
have strong impact on the obtained photocurrent. We performed optical
simulations of the electric field distribution within the devices to analyze
the origin of the current variations and provide deep insight in the device
physics. With the conventional absorber materials studied herein, optimized
ITO-free and semitransparent devices reached 2.0% power conversion efficiency
and a maximum optical transmission of 60%, with the device concept being
potentially transferable to other absorber materials.

20 Oct 2017
The observing campaign on the deep-space debris WT1190F as a test case for short-warning NEO impacts
The observing campaign on the deep-space debris WT1190F as a test case for short-warning NEO impacts
 Purdue University
Purdue University Technical University of MunichEuropean Space Agency
Technical University of MunichEuropean Space Agency European Southern ObservatoryINAF – Osservatorio Astronomico di RomaCarl von Ossietzky University of OldenburgAgenzia Spaziale ItalianaINAF-Osservatorio Astronomico di BolognaDeimos Space S.L.U.ESA Space Debris OfficeOsservatorio Astronomico “Serafino Zani”Deimos Space RomaniaESA SSA-NEO Coordination Centre
European Southern ObservatoryINAF – Osservatorio Astronomico di RomaCarl von Ossietzky University of OldenburgAgenzia Spaziale ItalianaINAF-Osservatorio Astronomico di BolognaDeimos Space S.L.U.ESA Space Debris OfficeOsservatorio Astronomico “Serafino Zani”Deimos Space RomaniaESA SSA-NEO Coordination CentreOn 2015 November 13, the small artificial object designated WT1190F entered
the Earth atmosphere above the Indian Ocean offshore Sri Lanka after being
discovered as a possible new asteroid only a few weeks earlier. At ESA's
SSA-NEO Coordination Centre we took advantage of this opportunity to organize a
ground-based observational campaign, using WT1190F as a test case for a
possible similar future event involving a natural asteroidal body.

29 Nov 2023
Agent-based simulations, especially those including communication, are complex to model and execute. To help researchers deal with this complexity and to encourage modular and maintainable research software, the Python-based framework mango (modular python agent framework) has been developed. The framework enables users to quickly implement software agents with different communication protocols (e.g., TCP) and message codecs (e.g., JSON). Furthermore, mango provides various options for developing an integrated agent simulation. This includes a scheduler module, which can control the agents' tasks, a (distributed) clock mechanism for time synchronization, and a specific simulation component, which can be coupled with other (co-)simulation software. These features are complemented by modular implementation patterns and a well-evaluated performance with the ability to simulate across multiple processes to ensure scalability.
There are no more papers matching your filters at the moment.
