
16 Nov 2025



Advances in AI generative models facilitate super-realistic video synthesis, amplifying misinformation risks via social media and eroding trust in digital content. Several research works have explored new deepfake detection methods on AI-generated images to alleviate these risks. However, with the fast development of video generation models, such as Sora and WanX, there is currently a lack of large-scale, high-quality AI-generated video datasets for forgery detection. In addition, existing detection approaches predominantly treat the task as binary classification, lacking explainability in model decision-making and failing to provide actionable insights or guidance for the public. To address these challenges, we propose \textbf{GenBuster-200K}, a large-scale AI-generated video dataset featuring 200K high-resolution video clips, diverse latest generative techniques, emphasis on fairness, and focus on real-world scenes. We further introduce \textbf{BusterX}, a novel AI-generated video detection and explanation framework leveraging multimodal large language model (MLLM) and reinforcement learning (RL) to provide authenticity determination and explainable rationales. To our knowledge, BusterX is the first framework to integrate MLLM with RL for explainable AI-generated video detection. Extensive experiments with state-of-the-art methods and ablation studies demonstrate the effectiveness and generalizability of BusterX.

27 Nov 2025


In recent years, Large-Language-Model-driven AI agents have exhibited unprecedented intelligence and adaptability. Nowadays, agents are undergoing a new round of evolution. They no longer act as an isolated island like LLMs. Instead, they start to communicate with diverse external entities, such as other agents and tools, to perform complex tasks. Under this trend, agent communication is regarded as a foundational pillar of the next communication era, and many organizations have intensively begun to design related communication protocols (e.g., Anthropic's MCP and Google's A2A) within the past year. However, this new field exposes significant security hazards, which can cause severe damage to real-world scenarios. To help researchers quickly figure out this promising topic and benefit the future agent communication development, this paper presents a comprehensive survey of agent communication security. More precisely, we present the first clear definition of agent communication. Besides, we propose a framework that categorizes agent communication into three classes and uses a three-layered communication architecture to illustrate how each class works. Next, for each communication class, we dissect related communication protocols and analyze the security risks, illustrating which communication layer the risks arise from. Then, we provide an outlook on the possible defense countermeasures for each risk. In addition, we conduct experiments using MCP and A2A to help readers better understand the novel vulnerabilities brought by agent communication. Finally, we discuss open issues and future directions in this promising research field. We also publish a repository that maintains a list of related papers on this https URL.
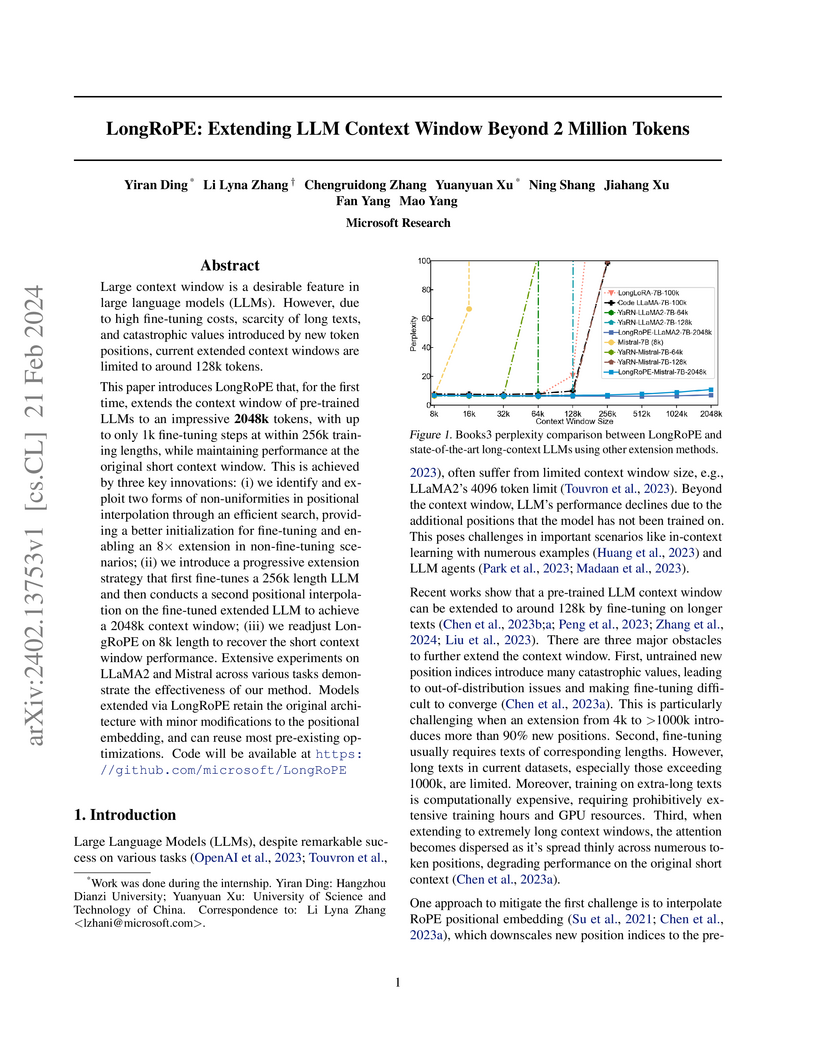
21 Feb 2024

LongRoPE extends Large Language Model context windows to over 2 million tokens by applying non-uniform, dimension-specific scaling to Rotary Position Embeddings (RoPE) and using a progressive extension strategy. The method maintains high performance across extremely long contexts, including successful information retrieval beyond 1 million tokens, while requiring minimal fine-tuning.
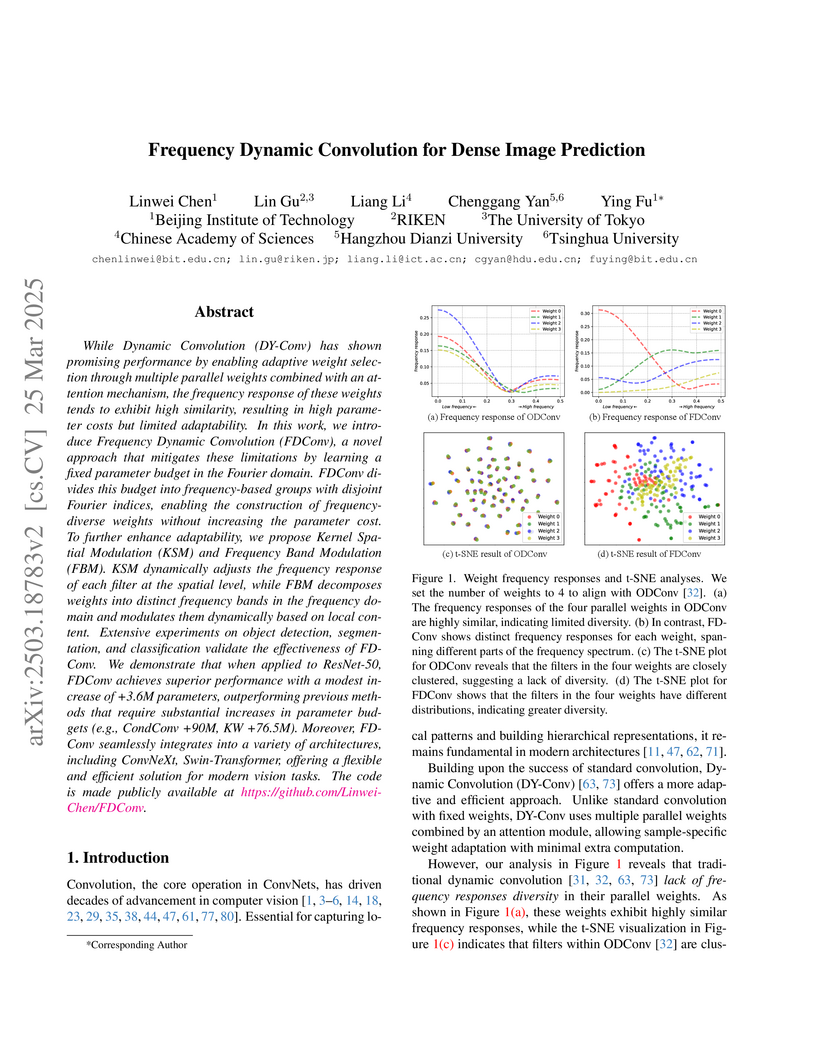
25 Mar 2025




Researchers at the Beijing Institute of Technology and collaborators developed Frequency Dynamic Convolution (FDConv), a method for adaptive deep learning models that constructs diverse convolution kernel weights directly in the Fourier domain. FDConv achieves competitive or superior performance across object detection, instance segmentation, and semantic segmentation benchmarks while significantly reducing the parameter overhead compared to prior dynamic convolution techniques.

26 Feb 2024

A comprehensive survey from Zhejiang University researchers systematically analyzes over 300 articles at the intersection of Knowledge Graphs (KGs) and Multi-modal (MM) Learning, categorizing research into KG-driven MM (KG4MM) and MM Knowledge Graphs (MM4KG) to map the evolving landscape and the role of Large Language Models.

18 Mar 2025
In this paper, we propose RFUAV as a new benchmark dataset for
radio-frequency based (RF-based) unmanned aerial vehicle (UAV) identification
and address the following challenges: Firstly, many existing datasets feature a
restricted variety of drone types and insufficient volumes of raw data, which
fail to meet the demands of practical applications. Secondly, existing datasets
often lack raw data covering a broad range of signal-to-noise ratios (SNR), or
do not provide tools for transforming raw data to different SNR levels. This
limitation undermines the validity of model training and evaluation. Lastly,
many existing datasets do not offer open-access evaluation tools, leading to a
lack of unified evaluation standards in current research within this field.
RFUAV comprises approximately 1.3 TB of raw frequency data collected from 37
distinct UAVs using the Universal Software Radio Peripheral (USRP) device in
real-world environments. Through in-depth analysis of the RF data in RFUAV, we
define a drone feature sequence called RF drone fingerprint, which aids in
distinguishing drone signals. In addition to the dataset, RFUAV provides a
baseline preprocessing method and model evaluation tools. Rigorous experiments
demonstrate that these preprocessing methods achieve state-of-the-art (SOTA)
performance using the provided evaluation tools. The RFUAV dataset and baseline
implementation are publicly available at this https URL

10 Nov 2024
Large Language Models (LLM) based agents have shown promise in autonomously
completing tasks across various domains, e.g., robotics, games, and web
navigation. However, these agents typically require elaborate design and expert
prompts to solve tasks in specific domains, which limits their adaptability. We
introduce AutoManual, a framework enabling LLM agents to autonomously build
their understanding through interaction and adapt to new environments.
AutoManual categorizes environmental knowledge into diverse rules and optimizes
them in an online fashion by two agents: 1) The Planner codes actionable plans
based on current rules for interacting with the environment. 2) The Builder
updates the rules through a well-structured rule system that facilitates online
rule management and essential detail retention. To mitigate hallucinations in
managing rules, we introduce a *case-conditioned prompting* strategy for the
Builder. Finally, the Formulator agent compiles these rules into a
comprehensive manual. The self-generated manual can not only improve the
adaptability but also guide the planning of smaller LLMs while being
human-readable. Given only one simple demonstration, AutoManual significantly
improves task success rates, achieving 97.4\% with GPT-4-turbo and 86.2\% with
GPT-3.5-turbo on ALFWorld benchmark tasks. The code is available at
this https URL

11 Sep 2025
Computer-Aided Design (CAD) generative modeling is driving significant innovations across industrial applications. Recent works have shown remarkable progress in creating solid models from various inputs such as point clouds, meshes, and text descriptions. However, these methods fundamentally diverge from traditional industrial workflows that begin with 2D engineering drawings. The automatic generation of parametric CAD models from these 2D vector drawings remains underexplored despite being a critical step in engineering design. To address this gap, our key insight is to reframe CAD generation as a sequence-to-sequence learning problem where vector drawing primitives directly inform the generation of parametric CAD operations, preserving geometric precision and design intent throughout the transformation process. We propose Drawing2CAD, a framework with three key technical components: a network-friendly vector primitive representation that preserves precise geometric information, a dual-decoder transformer architecture that decouples command type and parameter generation while maintaining precise correspondence, and a soft target distribution loss function accommodating inherent flexibility in CAD parameters. To train and evaluate Drawing2CAD, we create CAD-VGDrawing, a dataset of paired engineering drawings and parametric CAD models, and conduct thorough experiments to demonstrate the effectiveness of our method. Code and dataset are available at this https URL.

19 Jul 2025
Large vision-language models (VLMs) have demonstrated remarkable capabilities in open-world multimodal understanding, yet their high computational overheads pose great challenges for practical deployment. Some recent works have proposed methods to accelerate VLMs by pruning redundant visual tokens guided by the attention maps of VLM's early layers. Despite the success of these token pruning methods, they still suffer from two major shortcomings: (i) considerable accuracy drop due to insensitive attention signals in early layers, and (ii) limited speedup when generating long responses (e.g., 30 tokens). To address the limitations above, we present TwigVLM -- a simple and general architecture by growing a lightweight twig upon an early layer of the base VLM. Compared with most existing VLM acceleration methods purely based on visual token pruning, our TwigVLM not only achieves better accuracy retention by employing a twig-guided token pruning (TTP) strategy, but also yields higher generation speed by utilizing a self-speculative decoding (SSD) strategy. Taking LLaVA-1.5-7B as the base VLM, experimental results show that TwigVLM preserves 96% of the original performance after pruning 88.9% of visual tokens and achieves 154% speedup in generating long responses, delivering significantly better performance in terms of both accuracy and speed over the state-of-the-art VLM acceleration methods.

12 Oct 2024
Long-term Video Question Answering (VideoQA) is a challenging vision-and-language bridging task focusing on semantic understanding of untrimmed long-term videos and diverse free-form questions, simultaneously emphasizing comprehensive cross-modal reasoning to yield precise answers. The canonical approaches often rely on off-the-shelf feature extractors to detour the expensive computation overhead, but often result in domain-independent modality-unrelated representations. Furthermore, the inherent gradient blocking between unimodal comprehension and cross-modal interaction hinders reliable answer generation. In contrast, recent emerging successful video-language pre-training models enable cost-effective end-to-end modeling but fall short in domain-specific ratiocination and exhibit disparities in task formulation. Toward this end, we present an entirely end-to-end solution for long-term VideoQA: Multi-granularity Contrastive cross-modal collaborative Generation (MCG) model. To derive discriminative representations possessing high visual concepts, we introduce Joint Unimodal Modeling (JUM) on a clip-bone architecture and leverage Multi-granularity Contrastive Learning (MCL) to harness the intrinsically or explicitly exhibited semantic correspondences. To alleviate the task formulation discrepancy problem, we propose a Cross-modal Collaborative Generation (CCG) module to reformulate VideoQA as a generative task instead of the conventional classification scheme, empowering the model with the capability for cross-modal high-semantic fusion and generation so as to rationalize and answer. Extensive experiments conducted on six publicly available VideoQA datasets underscore the superiority of our proposed method.

05 Sep 2023
High dynamic range (HDR) images capture much more intensity levels than standard ones. Current methods predominantly generate HDR images from 8-bit low dynamic range (LDR) sRGB images that have been degraded by the camera processing pipeline. However, it becomes a formidable task to retrieve extremely high dynamic range scenes from such limited bit-depth data. Unlike existing methods, the core idea of this work is to incorporate more informative Raw sensor data to generate HDR images, aiming to recover scene information in hard regions (the darkest and brightest areas of an HDR scene). To this end, we propose a model tailor-made for Raw images, harnessing the unique features of Raw data to facilitate the Raw-to-HDR mapping. Specifically, we learn exposure masks to separate the hard and easy regions of a high dynamic scene. Then, we introduce two important guidances, dual intensity guidance, which guides less informative channels with more informative ones, and global spatial guidance, which extrapolates scene specifics over an extended spatial domain. To verify our Raw-to-HDR approach, we collect a large Raw/HDR paired dataset for both training and testing. Our empirical evaluations validate the superiority of the proposed Raw-to-HDR reconstruction model, as well as our newly captured dataset in the experiments.

29 Oct 2025
Large language models (LLMs) tend to follow maliciously crafted instructions to generate deceptive responses, posing safety challenges. How deceptive instructions alter the internal representations of LLM compared to truthful ones remains poorly understood beyond output analysis. To bridge this gap, we investigate when and how these representations ``flip'', such as from truthful to deceptive, under deceptive versus truthful/neutral instructions. Analyzing the internal representations of Llama-3.1-8B-Instruct and Gemma-2-9B-Instruct on a factual verification task, we find the model's instructed True/False output is predictable via linear probes across all conditions based on the internal representation. Further, we use Sparse Autoencoders (SAEs) to show that the Deceptive instructions induce significant representational shifts compared to Truthful/Neutral representations (which are similar), concentrated in early-to-mid layers and detectable even on complex datasets. We also identify specific SAE features highly sensitive to deceptive instruction and use targeted visualizations to confirm distinct truthful/deceptive representational subspaces. % Our analysis pinpoints layer-wise and feature-level correlates of instructed dishonesty, offering insights for LLM detection and control. Our findings expose feature- and layer-level signatures of deception, offering new insights for detecting and mitigating instructed dishonesty in LLMs.

06 Jun 2019

Recent developments in modeling language and vision have been successfully applied to image question answering. It is both crucial and natural to extend this research direction to the video domain for video question answering (VideoQA). Compared to the image domain where large scale and fully annotated benchmark datasets exists, VideoQA datasets are limited to small scale and are automatically generated, etc. These limitations restrict their applicability in practice. Here we introduce ActivityNet-QA, a fully annotated and large scale VideoQA dataset. The dataset consists of 58,000 QA pairs on 5,800 complex web videos derived from the popular ActivityNet dataset. We present a statistical analysis of our ActivityNet-QA dataset and conduct extensive experiments on it by comparing existing VideoQA baselines. Moreover, we explore various video representation strategies to improve VideoQA performance, especially for long videos. The dataset is available at this https URL

07 Jul 2025


HOI-Diff presents a modular diffusion-based framework for generating 3D human-object interactions (HOIs) from text prompts and object geometry, producing realistic human and dynamic object motions with physically plausible contacts. The framework achieves superior performance on human motion and interaction quality metrics, including a lower FID of 1.62 and Contact Distance of 0.347 on the BEHAVE dataset, and releases a new text-annotated version of the BEHAVE dataset to address data scarcity.

13 Oct 2025
The FRANCK framework enables Source-Free Object Detection (SFOD) for Detection Transformer (DETR) models by introducing a query-centric adaptation approach, achieving state-of-the-art performance across various domain shift scenarios. It integrates novel modules for sample reweighting, contrastive learning, and feature distillation to enhance detection accuracy when source data is unavailable.

12 Oct 2025

The COSINE framework unifies open-vocabulary segmentation and in-context segmentation by leveraging multi-modal prompts, processing both text and image cues within a single model. This approach achieves competitive or state-of-the-art performance across a diverse range of segmentation tasks, demonstrating synergistic collaboration between visual and textual modalities for enhanced generalization.

29 Apr 2025

Knowledge-based visual question answering (VQA) requires external knowledge
beyond the image to answer the question. Early studies retrieve required
knowledge from explicit knowledge bases (KBs), which often introduces
irrelevant information to the question, hence restricting the performance of
their models. Recent works have resorted to using a powerful large language
model (LLM) as an implicit knowledge engine to acquire the necessary knowledge
for answering. Despite the encouraging results achieved by these methods, we
argue that they have not fully activated the capacity of the \emph{blind} LLM
as the provided textual input is insufficient to depict the required visual
information to answer the question. In this paper, we present Prophet -- a
conceptually simple, flexible, and general framework designed to prompt LLM
with answer heuristics for knowledge-based VQA. Specifically, we first train a
vanilla VQA model on a specific knowledge-based VQA dataset without external
knowledge. After that, we extract two types of complementary answer heuristics
from the VQA model: answer candidates and answer-aware examples. The two types
of answer heuristics are jointly encoded into a formatted prompt to facilitate
the LLM's understanding of both the image and question, thus generating a more
accurate answer. By incorporating the state-of-the-art LLM GPT-3, Prophet
significantly outperforms existing state-of-the-art methods on four challenging
knowledge-based VQA datasets. Prophet is general that can be instantiated with
the combinations of different VQA models (i.e., both discriminative and
generative ones) and different LLMs (i.e., both commercial and open-source
ones). Moreover, Prophet can also be integrated with modern large multimodal
models in different stages, which is named Prophet++, to further improve the
capabilities on knowledge-based VQA tasks.

29 Jul 2025
Audio-visual multi-task incremental learning aims to continuously learn from multiple audio-visual tasks without the need for joint training on all tasks. The challenge of the problem is how to preserve the old task knowledge while facilitating the learning of new task with previous experiences. To address these challenges, we introduce a three-stage Progressive Homeostatic and Plastic audio-visual prompt (PHP) method. In the shallow phase, we design the task-shared modality aggregating adapter to foster cross-task and cross-modal audio-visual representation learning to enhance shared understanding between tasks. In the middle phase, we propose the task-specific modality-shared dynamic generating adapter, which constructs prompts that are tailored to individual tasks while remaining general across modalities, which balances the models ability to retain knowledge against forgetting with its potential for versatile multi-task transferability. In the deep phase, we introduce the task-specific modality-independent prompts to further refine the understand ability by targeting individual information for each task and modality. By incorporating these three phases, PHP retains task-specific prompts while adapting shared parameters for new tasks to effectively balance knowledge sharing and specificity. Our method achieves SOTA performance in different orders of four tasks (AVE, AVVP, AVS and AVQA). Our code can be available at this https URL.

07 Oct 2025
Survival analysis plays a vital role in making clinical decisions. However, the models currently in use are often difficult to interpret, which reduces their usefulness in clinical settings. Prototype learning presents a potential solution, yet traditional methods focus on local similarities and static matching, neglecting the broader tumor context and lacking strong semantic alignment with genomic data. To overcome these issues, we introduce an innovative prototype-based multimodal framework, FeatProto, aimed at enhancing cancer survival prediction by addressing significant limitations in current prototype learning methodologies within pathology. Our framework establishes a unified feature prototype space that integrates both global and local features of whole slide images (WSI) with genomic profiles. This integration facilitates traceable and interpretable decision-making processes. Our approach includes three main innovations: (1) A robust phenotype representation that merges critical patches with global context, harmonized with genomic data to minimize local bias. (2) An Exponential Prototype Update Strategy (EMA ProtoUp) that sustains stable cross-modal associations and employs a wandering mechanism to adapt prototypes flexibly to tumor heterogeneity. (3) A hierarchical prototype matching scheme designed to capture global centrality, local typicality, and cohort-level trends, thereby refining prototype inference. Comprehensive evaluations on four publicly available cancer datasets indicate that our method surpasses current leading unimodal and multimodal survival prediction techniques in both accuracy and interoperability, providing a new perspective on prototype learning for critical medical applications. Our source code is available at this https URL.

20 Mar 2025

Researchers from TUM and partner institutions develop a SLAM system that reconstructs dynamic scenes by combining 4D Gaussian representations with optical flow supervision, enabling simultaneous camera tracking and scene modeling while maintaining accurate reconstruction of both static and moving objects in real-world environments.
There are no more papers matching your filters at the moment.
