
21 Apr 2025









DataComp-LM introduces a standardized, large-scale benchmark for evaluating language model training data curation strategies, complete with an openly released corpus, framework, and models. Its DCLM-BASELINE 7B model, trained on carefully filtered Common Crawl data, achieves 64% MMLU 5-shot accuracy, outperforming previous open-data state-of-the-art models while requiring substantially less compute.

29 Nov 2025

Despite autoregressive large language models (arLLMs) being the current dominant paradigm in language modeling, effectively updating these models to incorporate new factual knowledge still remains difficult. They resist knowledge injection via fine-tuning due to inherent shortcomings such as the "reversal curse" -- the challenge of answering questions that reverse the original information order in the training sample. Masked diffusion large language models (dLLMs) are rapidly emerging as a powerful alternative to the arLLM paradigm, with evidence of better data efficiency and free of the "reversal curse" in pre-training. However, it is unknown whether these advantages extend to the post-training phase, i.e. whether pre-trained dLLMs can easily acquire new knowledge through fine-tuning. On three diverse datasets, we fine-tune arLLMs and dLLMs, evaluating them with forward and backward style Question Answering (QA) to probe knowledge generalization and the reversal curse. Our results confirm that arLLMs critically rely on extensive data augmentation via paraphrases for QA generalization, and paraphrases are only effective when their information order matches the QA style. Conversely, dLLMs achieve high accuracies on both forward and backward QAs without paraphrases; adding paraphrases yields only marginal gains. Inspired by the dLLM's performance, we introduce a novel masked fine-tuning paradigm for knowledge injection into pre-trained arLLMs. This proposed method successfully and drastically improves the data efficiency of arLLM fine-tuning, effectively closing its performance gap with dLLMs. We further show that the masked fine-tuning paradigm of arLLMs can be extended to the supervised fine-tuning (SFT) of mathematical capability. Across two models and two datasets, our masked SFT outperforms regular SFT.

20 Oct 2023

DATACOMP introduces a benchmark and the 12.8 billion image-text pair COMMONPOOL dataset to systematically evaluate multimodal dataset design. A CLIP model trained on the resulting DATACOMP-1B dataset achieved 79.2% zero-shot ImageNet accuracy, outperforming models trained on larger, unfiltered datasets.

30 Apr 2025


Harvard researchers develop a gated memory framework (MEGa) that enables large language models to continuously store and recall new knowledge through dedicated weight modules, achieving high recall accuracy while preserving general capabilities as measured by MMLU scores, providing a more biologically-plausible alternative to retrieval-augmented generation approaches.

07 Aug 2023



OpenFlamingo provides an open-source framework for training large autoregressive vision-language models that process interleaved image and text sequences. This work from the University of Washington and collaborators closely replicates DeepMind's proprietary Flamingo models by using publicly available components and datasets, achieving between 80% and 89% of their performance across vision-language benchmarks.

03 Feb 2025



A collaborative team led by MIT researchers introduces the first comprehensive index of deployed AI agent systems, documenting 67 real-world implementations across a structured 33-field framework while revealing significant gaps in safety practices - only 19.4% disclose formal safety policies and less than 10% report external safety evaluations.

26 Dec 2023

We introduce VisIT-Bench (Visual InsTruction Benchmark), a benchmark for evaluation of instruction-following vision-language models for real-world use. Our starting point is curating 70 'instruction families' that we envision instruction tuned vision-language models should be able to address. Extending beyond evaluations like VQAv2 and COCO, tasks range from basic recognition to game playing and creative generation. Following curation, our dataset comprises 592 test queries, each with a human-authored instruction-conditioned caption. These descriptions surface instruction-specific factors, e.g., for an instruction asking about the accessibility of a storefront for wheelchair users, the instruction-conditioned caption describes ramps/potential obstacles. These descriptions enable 1) collecting human-verified reference outputs for each instance; and 2) automatic evaluation of candidate multimodal generations using a text-only LLM, aligning with human judgment. We quantify quality gaps between models and references using both human and automatic evaluations; e.g., the top-performing instruction-following model wins against the GPT-4 reference in just 27% of the comparison. VisIT-Bench is dynamic to participate, practitioners simply submit their model's response on the project website; Data, code and leaderboard is available at this http URL.

15 Dec 2021
A locally testable code (LTC) is an error-correcting code that has a property-tester. The tester reads bits that are randomly chosen, and rejects words with probability proportional to their distance from the code. The parameter is called the locality of the tester.
LTCs were initially studied as important components of PCPs, and since then the topic has evolved on its own. High rate LTCs could be useful in practice: before attempting to decode a received word, one can save time by first quickly testing if it is close to the code.
An outstanding open question has been whether there exist "-LTCs", namely LTCs with *c*onstant rate, *c*onstant distance, and *c*onstant locality.
In this work we construct such codes based on a new two-dimensional complex which we call a left-right Cayley complex. This is essentially a graph which, in addition to vertices and edges, also has squares. Our codes can be viewed as a two-dimensional version of (the one-dimensional) expander codes, where the codewords are functions on the squares rather than on the edges.

11 Jun 2025
This work develops lossless speculative decoding algorithms that allow Large Language Model (LLM) inference acceleration even when the drafter and target models use heterogeneous vocabularies. The String-Level Exact Match (SLEM) and Token-Level Intersection (TLI) algorithms achieve up to 2.8x and 1.7x throughput acceleration, respectively, and have been integrated into Hugging Face Transformers.

28 Oct 2025
Researchers introduced HACK, a framework categorizing Large Language Model (LLM) hallucinations by internal knowledge and certainty, empirically validating this distinction via activation steering. The study identified "Certainty Misalignment," where LLMs confidently hallucinate despite possessing correct knowledge, revealing limitations in current mitigation strategies.

20 Sep 2025
Bug bounty programs have contributed significantly to security in technology firms in the last decade, but little is known about the role of reward incentives in producing useful outcomes. We analyze incentives and outcomes in Google's Vulnerability Rewards Program (VRP), one of the world's largest bug bounty programs. We analyze the responsiveness of the quality and quantity of bugs received to changes in payments, focusing on a change in Google's reward amounts posted in July, 2024, in which reward amounts increased by up to 200% for the highest impact tier. Our empirical results show an increase in the volume of high-value bugs received after the reward increase, for which we also compute elasticities. We further break down the sources of this increase between veteran researchers and new researchers, showing that the reward increase both redirected the attention of veteran researchers and attracted new top security researchers into the program.

03 Dec 2020

StyleSpace Analysis explores StyleGAN2's internal StyleSpace, demonstrating it is a more disentangled latent representation than W or W+ spaces for image generation. The work introduces methods to discover highly localized and attribute-specific controls within this space, achieving superior disentanglement in manipulations compared to prior techniques as quantified by a new Attribute Dependency (AD) metric.

06 Nov 2022
Gradient-based deep-learning algorithms exhibit remarkable performance in practice, but it is not well-understood why they are able to generalize despite having more parameters than training examples. It is believed that implicit bias is a key factor in their ability to generalize, and hence it was widely studied in recent years. In this short survey, we explain the notion of implicit bias, review main results and discuss their implications.

13 Jan 2014

We give an explicit construction of the weak local limit of a class of preferential attachment graphs. This limit contains all local information and allows several computations that are otherwise hard, for example, joint degree distributions and, more generally, the limiting distribution of subgraphs in balls of any given radius around a random vertex in the preferential attachment graph. We also establish the finite-volume corrections which give the approach to the limit.

03 Dec 2025
Two pressing topics in the theory of deep learning are the interpretation of feature learning mechanisms and the determination of implicit bias of networks in the rich regime. Current theories of rich feature learning effects revolve around networks with one or two trainable layers or deep linear networks. Furthermore, even under such limiting settings, predictions often appear in the form of high-dimensional non-linear equations, which require computationally intensive numerical solutions. Given the many details that go into defining a deep learning problem, this analytical complexity is a significant and often unavoidable challenge. Here, we propose a powerful heuristic route for predicting the data and width scales at which various patterns of feature learning emerge. This form of scale analysis is considerably simpler than such exact theories and reproduces the scaling exponents of various known results. In addition, we make novel predictions on complex toy architectures, such as three-layer non-linear networks and attention heads, thus extending the scope of first-principle theories of deep learning.

04 Sep 2024




Human feedback on conversations with language language models (LLMs) is central to how these systems learn about the world, improve their capabilities, and are steered toward desirable and safe behaviors. However, this feedback is mostly collected by frontier AI labs and kept behind closed doors. In this work, we bring together interdisciplinary experts to assess the opportunities and challenges to realizing an open ecosystem of human feedback for AI. We first look for successful practices in peer production, open source, and citizen science communities. We then characterize the main challenges for open human feedback. For each, we survey current approaches and offer recommendations. We end by envisioning the components needed to underpin a sustainable and open human feedback ecosystem. In the center of this ecosystem are mutually beneficial feedback loops, between users and specialized models, incentivizing a diverse stakeholders community of model trainers and feedback providers to support a general open feedback pool.

12 Nov 2024

Humans excel at discovering regular structures from limited samples and applying inferred rules to novel settings. We investigate whether modern generative models can similarly learn underlying rules from finite samples and perform reasoning through conditional sampling. Inspired by Raven's Progressive Matrices task, we designed GenRAVEN dataset, where each sample consists of three rows, and one of 40 relational rules governing the object position, number, or attributes applies to all rows. We trained generative models to learn the data distribution, where samples are encoded as integer arrays to focus on rule learning. We compared two generative model families: diffusion (EDM, DiT, SiT) and autoregressive models (GPT2, Mamba). We evaluated their ability to generate structurally consistent samples and perform panel completion via unconditional and conditional sampling. We found diffusion models excel at unconditional generation, producing more novel and consistent samples from scratch and memorizing less, but performing less well in panel completion, even with advanced conditional sampling methods. Conversely, autoregressive models excel at completing missing panels in a rule-consistent manner but generate less consistent samples unconditionally. We observe diverse data scaling behaviors: for both model families, rule learning emerges at a certain dataset size - around 1000s examples per rule. With more training data, diffusion models improve both their unconditional and conditional generation capabilities. However, for autoregressive models, while panel completion improves with more training data, unconditional generation consistency declines. Our findings highlight complementary capabilities and limitations of diffusion and autoregressive models in rule learning and reasoning tasks, suggesting avenues for further research into their mechanisms and potential for human-like reasoning.
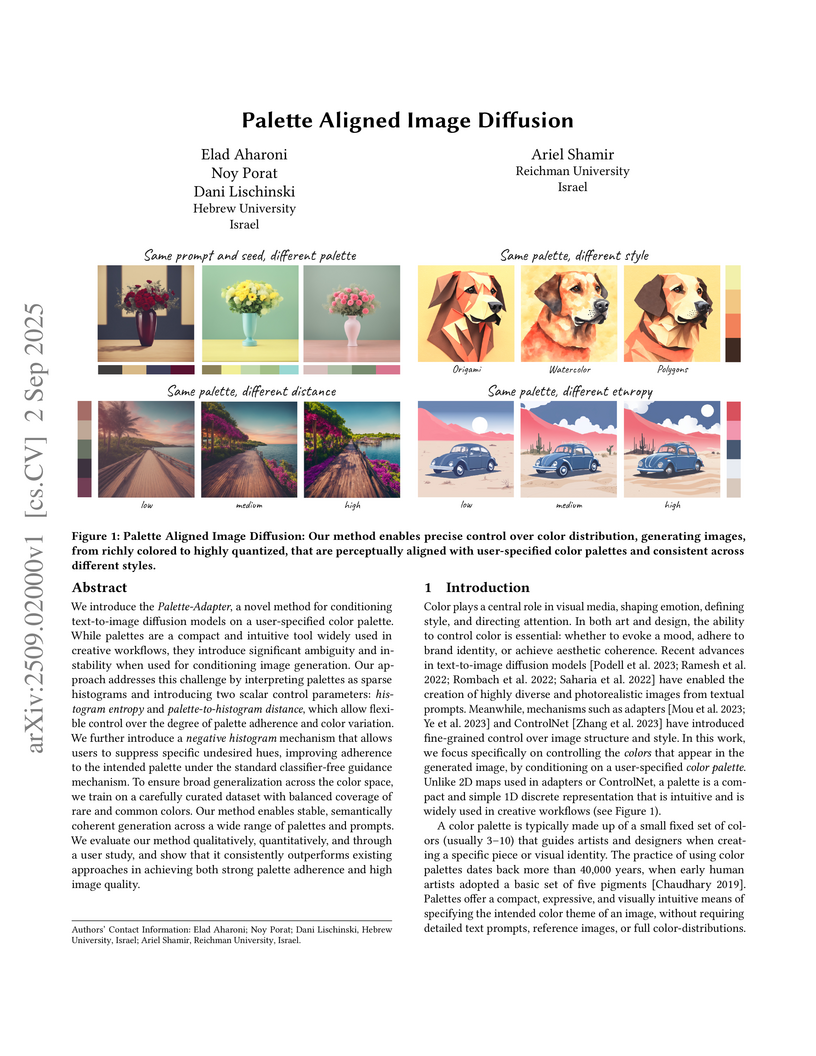
02 Sep 2025
We introduce the Palette-Adapter, a novel method for conditioning text-to-image diffusion models on a user-specified color palette. While palettes are a compact and intuitive tool widely used in creative workflows, they introduce significant ambiguity and instability when used for conditioning image generation. Our approach addresses this challenge by interpreting palettes as sparse histograms and introducing two scalar control parameters: histogram entropy and palette-to-histogram distance, which allow flexible control over the degree of palette adherence and color variation. We further introduce a negative histogram mechanism that allows users to suppress specific undesired hues, improving adherence to the intended palette under the standard classifier-free guidance mechanism. To ensure broad generalization across the color space, we train on a carefully curated dataset with balanced coverage of rare and common colors. Our method enables stable, semantically coherent generation across a wide range of palettes and prompts. We evaluate our method qualitatively, quantitatively, and through a user study, and show that it consistently outperforms existing approaches in achieving both strong palette adherence and high image quality.

08 Aug 2025
The strongest experimental evidence for dark matter is the Galactic Center gamma-ray excess observed by the Fermi telescope and even predicted prior to discovery as a potential dark matter signature via WIMP dark matter self-annihilations. However, an equally compelling explanation of the excess gamma-ray flux appeals to a population of old millisecond pulsars that also accounts for the observed boxy morphology inferred from the bulge old star population. We employ a set of Milky Way-like galaxies found in the Hestia constrained simulations of the local universe to explore the rich morphology of the central dark matter distribution, motivated by the GAIA discovery of a vigorous early merging history of the Milky Way galaxy. We predict a significantly non-spherical gamma-ray morphology from the WIMP interpretation. Future experiments, such as the Cherenkov Telescope Array, that extend to higher energies, should distinguish between the competing interpretations.

19 Jun 2025

Language model agents are poised to mediate how people navigate and act online. If the companies that already dominate internet search, communication, and commerce -- or the firms trying to unseat them -- control these agents, the resulting platform agents will likely deepen surveillance, tighten lock-in, and further entrench incumbents. To resist that trajectory, this position paper argues that we should promote agent advocates: user-controlled agents that safeguard individual autonomy and choice. Doing so demands three coordinated moves: broad public access to both compute and capable AI models that are not platform-owned, open interoperability and safety standards, and market regulation that prevents platforms from foreclosing competition.
There are no more papers matching your filters at the moment.
