
17 Jun 2025

This paper presents the Autoregressive U-Net (AU-Net), an architecture that processes language directly from raw bytes, learning hierarchical representations without a predefined vocabulary. AU-Net matches or surpasses the performance of BPE-based Transformer baselines on various NLP tasks, while demonstrating improved multilingual generalization and superior character-level manipulation capabilities.

10 May 2024
 University of Washington
University of Washington CNRS
CNRS Monash University
Monash University Carnegie Mellon UniversityAllen Institute for Artificial Intelligence
Carnegie Mellon UniversityAllen Institute for Artificial Intelligence Georgia Institute of TechnologyIT University of Copenhagen
Georgia Institute of TechnologyIT University of Copenhagen University of British ColumbiaIndian Institute of Science
University of British ColumbiaIndian Institute of Science Université Paris-Saclay
Université Paris-Saclay Mohamed bin Zayed University of Artificial IntelligenceIndian Institute of Technology
Mohamed bin Zayed University of Artificial IntelligenceIndian Institute of Technology University of SydneyThe Hebrew University of JerusalemTechnical University of DarmstadtUniversität HamburgBocconi UniversityRadboud University NijmegenLISNUniversity of Applied Sciences DarmstadtQueens
’ University
University of SydneyThe Hebrew University of JerusalemTechnical University of DarmstadtUniversität HamburgBocconi UniversityRadboud University NijmegenLISNUniversity of Applied Sciences DarmstadtQueens
’ UniversityA white paper resulting from a Dagstuhl seminar systematically maps the scientific peer review process, identifying specific challenges and opportunities for Natural Language Processing (NLP) solutions across all stages. It outlines how NLP can assist from submission preparation to post-review analysis, while also highlighting critical overarching challenges related to data, measurement, and ethics.
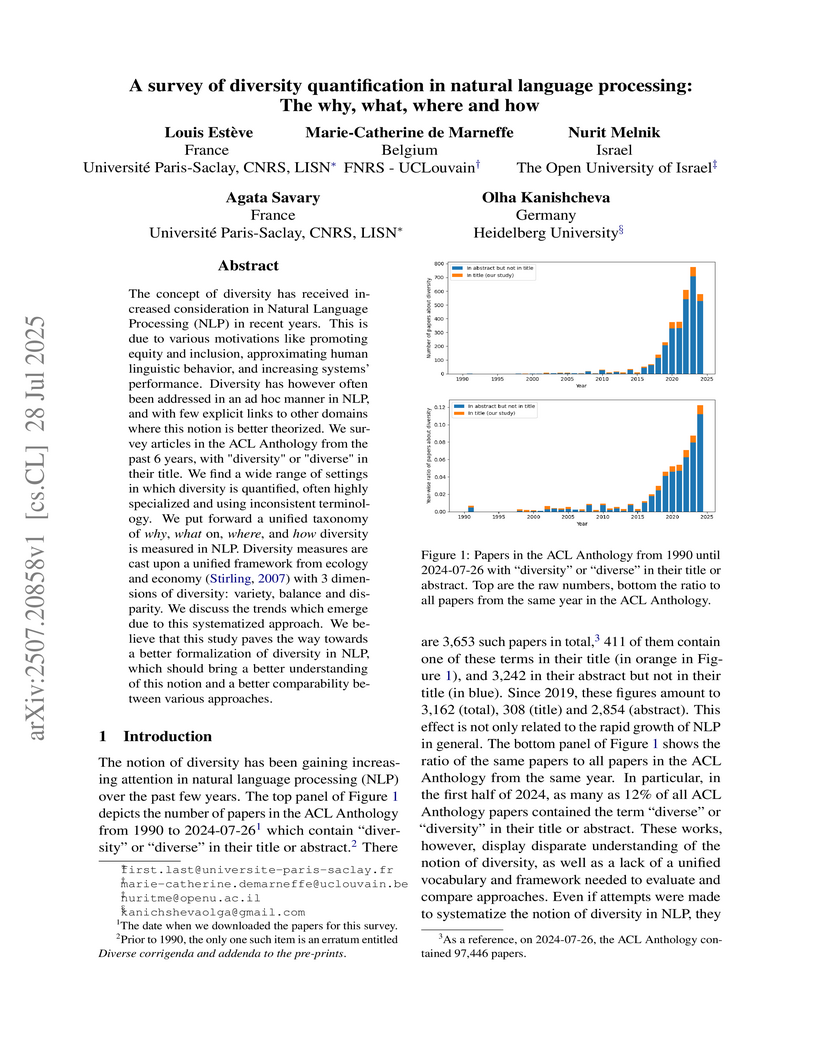
28 Jul 2025
The concept of diversity has received increased consideration in Natural Language Processing (NLP) in recent years. This is due to various motivations like promoting and inclusion, approximating human linguistic behavior, and increasing systems' performance. Diversity has however often been addressed in an ad hoc manner in NLP, and with few explicit links to other domains where this notion is better theorized. We survey articles in the ACL Anthology from the past 6 years, with "diversity" or "diverse" in their title. We find a wide range of settings in which diversity is quantified, often highly specialized and using inconsistent terminology. We put forward a unified taxonomy of why, what on, where, and how diversity is measured in NLP. Diversity measures are cast upon a unified framework from ecology and economy (Stirling, 2007) with 3 dimensions of diversity: variety, balance and disparity. We discuss the trends which emerge due to this systematized approach. We believe that this study paves the way towards a better formalization of diversity in NLP, which should bring a better understanding of this notion and a better comparability between various approaches.

03 Nov 2022

Progress in machine learning (ML) comes with a cost to the environment, given that training ML models requires significant computational resources, energy and materials. In the present article, we aim to quantify the carbon footprint of BLOOM, a 176-billion parameter language model, across its life cycle. We estimate that BLOOM's final training emitted approximately 24.7 tonnes of~\carboneq~if we consider only the dynamic power consumption, and 50.5 tonnes if we account for all processes ranging from equipment manufacturing to energy-based operational consumption. We also study the energy requirements and carbon emissions of its deployment for inference via an API endpoint receiving user queries in real-time. We conclude with a discussion regarding the difficulty of precisely estimating the carbon footprint of ML models and future research directions that can contribute towards improving carbon emissions reporting.

04 Jul 2024

CoSPLADE offers an efficient neural retrieval model, contextualizing sparse lexical representations for conversational search. It attains strong performance on TREC CAsT benchmarks, showing high recall and overall effectiveness with a lightweight training approach.

08 May 2024
A systematic review and classification of Deep Structural Causal Models (DSCMs) categorizes existing methods based on their underlying causal assumptions and deep generative model architectures. This work clarifies their capabilities and limitations in answering counterfactual queries from observational data, while highlighting open challenges and future research directions.

12 Dec 2024
Machine learning tasks are generally formulated as optimization problems, where one searches for an optimal function within a certain functional space. In practice, parameterized functional spaces are considered, in order to be able to perform gradient descent. Typically, a neural network architecture is chosen and fixed, and its parameters (connection weights) are optimized, yielding an architecture-dependent result. This way of proceeding however forces the evolution of the function during training to lie within the realm of what is expressible with the chosen architecture, and prevents any optimization across architectures. Costly architectural hyper-parameter optimization is often performed to compensate for this. Instead, we propose to adapt the architecture on the fly during training. We show that the information about desirable architectural changes, due to expressivity bottlenecks when attempting to follow the functional gradient, can be extracted from backpropagation. To do this, we propose a mathematical definition of expressivity bottlenecks, which enables us to detect, quantify and solve them while training, by adding suitable neurons. Thus, while the standard approach requires large networks, in terms of number of neurons per layer, for expressivity and optimization reasons, we provide tools and properties to develop an architecture starting with a very small number of neurons. As a proof of concept, we show results~on the CIFAR dataset, matching large neural network accuracy, with competitive training time, while removing the need for standard architectural hyper-parameter search.

25 Feb 2022
Obtaining standardized crowdsourced benchmark of computational methods is a major issue in data science communities. Dedicated frameworks enabling fair benchmarking in a unified environment are yet to be developed. Here we introduce Codabench, an open-source, community-driven platform for benchmarking algorithms or software agents versus datasets or tasks. A public instance of Codabench (this https URL) is open to everyone, free of charge, and allows benchmark organizers to compare fairly submissions, under the same setting (software, hardware, data, algorithms), with custom protocols and data formats. Codabench has unique features facilitating the organization of benchmarks flexibly, easily and reproducibly, such as the possibility of re-using templates of benchmarks, and supplying compute resources on-demand. Codabench has been used internally and externally on various applications, receiving more than 130 users and 2500 submissions. As illustrative use cases, we introduce 4 diverse benchmarks covering Graph Machine Learning, Cancer Heterogeneity, Clinical Diagnosis and Reinforcement Learning.

10 Oct 2025

Gradient-based optimization is the workhorse of deep learning, offering efficient and scalable training via backpropagation. However, exposing gradients during training can leak sensitive information about the underlying data, raising privacy and security concerns such as susceptibility to data poisoning attacks. In contrast, black box optimization methods, which treat the model as an opaque function, relying solely on function evaluations to guide optimization, offer a promising alternative in scenarios where data access is restricted, adversarial risks are high, or overfitting is a concern. This paper introduces BBoxER, an evolutionary black-box method for LLM post-training that induces an information bottleneck via implicit compression of the training data. Leveraging the tractability of information flow, we provide non-vacuous generalization bounds and strong theoretical guarantees for differential privacy, robustness to data poisoning attacks, and extraction attacks. In experiments with LLMs, we demonstrate empirically that black-box optimization methods-despite the scalability and computational challenges inherent to black-box approaches-are able to learn, showing how a few iterations of BBoxER improve performance, generalize well on a benchmark of reasoning datasets, and are robust to membership inference attacks. This positions BBoxER as an attractive add-on on top of gradient-based optimization, offering suitability for deployment in restricted or privacy-sensitive environments while also providing non-vacuous generalization guarantees.

05 Oct 2025
Reporting quality is an important topic in clinical trial research articles, as it can impact clinical decisions. In this article, we test the ability of large language models to assess the reporting quality of this type of article using the Consolidated Standards of Reporting Trials (CONSORT). We create CONSORT-QA, an evaluation corpus from two studies on abstract reporting quality with CONSORT-abstract standards. We then evaluate the ability of different large generative language models (from the general domain or adapted to the biomedical domain) to correctly assess CONSORT criteria with different known prompting methods, including Chain-of-thought. Our best combination of model and prompting method achieves 85% accuracy. Using Chain-of-thought adds valuable information on the model's reasoning for completing the task.

23 Oct 2023
Metal forging is used to manufacture dies. We require the best set of input
parameters for the process to be efficient. Currently, we predict the best
parameters using the finite element method by generating simulations for the
different initial conditions, which is a time-consuming process. In this paper,
introduce a hybrid approach that helps in processing and generating new data
simulations using a surrogate graph neural network model based on graph
convolutions, having a cheaper time cost. We also introduce a hybrid approach
that helps in processing and generating new data simulations using the model.
Given a dataset representing meshes, our focus is on the conversion of the
available information into a graph or point cloud structure. This new
representation enables deep learning. The predicted result is similar, with a
low error when compared to that produced using the finite element method. The
new models have outperformed existing PointNet and simple graph neural network
models when applied to produce the simulations.

10 Oct 2024
Training a large set of machine learning algorithms to convergence in order to select the best-performing algorithm for a dataset is computationally wasteful. Moreover, in a budget-limited scenario, it is crucial to carefully select an algorithm candidate and allocate a budget for training it, ensuring that the limited budget is optimally distributed to favor the most promising candidates. Casting this problem as a Markov Decision Process, we propose a novel framework in which an agent must select in the process of learning the most promising algorithm without waiting until it is fully trained. At each time step, given an observation of partial learning curves of algorithms, the agent must decide whether to allocate resources to further train the most promising algorithm (exploitation), to wake up another algorithm previously put to sleep, or to start training a new algorithm (exploration). In addition, our framework allows the agent to meta-learn from learning curves on past datasets along with dataset meta-features and algorithm hyperparameters. By incorporating meta-learning, we aim to avoid myopic decisions based solely on premature learning curves on the dataset at hand. We introduce two benchmarks of learning curves that served in international competitions at WCCI'22 and AutoML-conf'22, of which we analyze the results. Our findings show that both meta-learning and the progression of learning curves enhance the algorithm selection process, as evidenced by methods of winning teams and our DDQN baseline, compared to heuristic baselines or a random search. Interestingly, our cost-effective baseline, which selects the best-performing algorithm w.r.t. a small budget, can perform decently when learning curves do not intersect frequently.

23 Dec 2024
The compute requirements associated with training Artificial Intelligence (AI) models have increased exponentially over time. Optimisation strategies aim to reduce the energy consumption and environmental impacts associated with AI, possibly shifting impacts from the use phase to the manufacturing phase in the life-cycle of hardware. This paper investigates the evolution of individual graphics cards production impacts and of the environmental impacts associated with training Machine Learning (ML) models over time. We collect information on graphics cards used to train ML models and released between 2013 and 2023. We assess the environmental impacts associated with the production of each card to visualize the trends on the same period. Then, using information on notable AI systems from the Epoch AI dataset we assess the environmental impacts associated with training each system. The environmental impacts of graphics cards production have increased continuously. The energy consumption and environmental impacts associated with training models have increased exponentially, even when considering reduction strategies such as location shifting to places with less carbon intensive electricity mixes. These results suggest that current impact reduction strategies cannot curb the growth in the environmental impacts of AI. This is consistent with rebound effect, where the efficiency increases fuel the creation of even larger models thereby cancelling the potential impact reduction. Furthermore, these results highlight the importance of considering the impacts of hardware over the entire life-cycle rather than the sole usage phase in order to avoid impact shifting. The environmental impact of AI cannot be reduced without reducing AI activities as well as increasing efficiency.

26 May 2023
Span-based nested named-entity recognition (NER) has a cubic-time complexity using a variant of the CYK algorithm. We show that by adding a supplementary structural constraint on the search space, nested NER has a quadratic-time complexity, that is the same asymptotic complexity than the non-nested case. The proposed algorithm covers a large part of three standard English benchmarks and delivers comparable experimental results.

14 Jan 2025
Diversity is an important property of datasets and sampling data for diversity is useful in dataset creation. Finding the optimally diverse sample is expensive, we therefore present a heuristic significantly increasing diversity relative to random sampling. We also explore whether different kinds of diversity -- lexical and syntactic -- correlate, with the purpose of sampling for expensive syntactic diversity through inexpensive lexical diversity. We find that correlations fluctuate with different datasets and versions of diversity measures. This shows that an arbitrarily chosen measure may fall short of capturing diversity-related properties of datasets.

28 Mar 2024
Intent classification and slot-filling are essential tasks of Spoken Language Understanding (SLU). In most SLUsystems, those tasks are realized by independent modules. For about fifteen years, models achieving both of themjointly and exploiting their mutual enhancement have been proposed. A multilingual module using a joint modelwas envisioned to create a touristic dialogue system for a European project, HumanE-AI-Net. A combination ofmultiple datasets, including the MEDIA dataset, was suggested for training this joint model. The MEDIA SLU datasetis a French dataset distributed since 2005 by ELRA, mainly used by the French research community and free foracademic research since 2020. Unfortunately, it is annotated only in slots but not intents. An enhanced version ofMEDIA annotated with intents has been built to extend its use to more tasks and use cases. This paper presents thesemi-automatic methodology used to obtain this enhanced version. In addition, we present the first results of SLUexperiments on this enhanced dataset using joint models for intent classification and slot-filling.

09 Jul 2025
This position paper looks at differences between the current understandings of human-centered explainability and explainability AI. We discuss current ideas in both fields, as well as the differences and opportunities we discovered. As an example of combining both, we will present preliminary work on a new algebraic machine learning approach. We are excited to continue discussing design opportunities for human-centered explainability (HCx) and xAI with the broader HCxAI community.

10 Nov 2025
The emergence of large-scale spatial modulations of turbulent channel flow, as the Reynolds number is decreased, is addressed numerically using the framework of linear stability analysis. Such modulations are known as the precursors of laminar-turbulent patterns found near the onset of relaminarisation. A synthetic two-dimensional base flow is constructed by adding finite-amplitude streaks to the turbulent mean flow. The streak mode is chosen as the leading resolvent mode from linear response theory. Besides, turbulent fluctuations can be taken into account or not by using a simple Cess eddy viscosity model. The linear stability of the base flow is considered by searching for unstable eigenmodes with wavelengths larger than the base flow streaks. As the streak amplitude is increased in the presence of the turbulent closure, the base flow loses its stability to a large-scale modulation below a critical Reynolds number value. The structure of the corresponding eigenmode, its critical Reynolds number, its critical angle and wavelengths are all fully consistent with the onset of turbulent modulations from the literature. The existence of a threshold value of the Reynolds number is directly related to the presence of an eddy viscosity, and is justified using an energy budget. The values of the critical streak amplitudes are discussed in relation with those relevant to turbulent flows.

02 Apr 2025
We study the cutwidth measure on graphs and ways to bound the cutwidth of a
graph by partitioning its vertices. We consider bounds expressed as a function
of two quantities: on the one hand, the maximal cutwidth x of the subgraphs
induced by the classes of the partition, and on the other hand, the cutwidth y
of the quotient multigraph obtained by merging each class to a single vertex.
We consider in particular decomposition of directed graphs into strongly
connected components (SCCs): in this case, x is the maximal cutwidth of an SCC,
and y is the cutwidth of the directed acyclic condensation multigraph.
We show that the cutwidth of a graph is always in O(x + y), specifically it
can be upper bounded by 1.5x + y. We also show a lower bound justifying that
the constant 1.5 cannot be improved in general

12 Feb 2025
CNRSConsiglio Nazionale delle Ricerche The University of Texas at Austin
The University of Texas at Austin INFNUniversité Paris-Saclay
INFNUniversité Paris-Saclay InriaUniversidad de ZaragozaUniversidad de ExtremaduraUniversità degli Studi di SienaCNR-NANOTECUniversidad ComplutenseLISNAmes LaboratoryChan Zuckerberg BiohubTexas Materials InstituteFundación ARAIDI3AEAWAGInstituto de Biocomputación y Física de Sistemas ComplejosDiputación General de AragónBIFIInstituto de Computación Científica AvanzadaUniversit
di FerraraSapienza Universit
di RomaICCAEx
InriaUniversidad de ZaragozaUniversidad de ExtremaduraUniversità degli Studi di SienaCNR-NANOTECUniversidad ComplutenseLISNAmes LaboratoryChan Zuckerberg BiohubTexas Materials InstituteFundación ARAIDI3AEAWAGInstituto de Biocomputación y Física de Sistemas ComplejosDiputación General de AragónBIFIInstituto de Computación Científica AvanzadaUniversit
di FerraraSapienza Universit
di RomaICCAExRejuvenation and memory, long considered the distinguishing features of spin
glasses, have recently been proven to result from the growth of multiple length
scales. This insight, enabled by simulations on the Janus~II supercomputer, has
opened the door to a quantitative analysis. We combine numerical simulations
with comparable experiments to introduce two coefficients that quantify memory.
A third coefficient has been recently presented by Freedberg et al. We show
that these coefficients are physically equivalent by studying their temperature
and waiting-time dependence.
There are no more papers matching your filters at the moment.
