
07 Oct 2025
Explainable AI (XAI) has become increasingly important with the rise of large transformer models, yet many explanation methods designed for CNNs transfer poorly to Vision Transformers (ViTs). Existing ViT explanations often rely on attention weights, which tend to yield noisy maps as they capture token-to-token interactions within each this http URL attribution methods incorporating MLP blocks have been proposed, we argue that attention remains a valuable and interpretable signal when properly filtered. We propose a method that combines attention maps with a statistical filtering, initially proposed for CNNs, to remove noisy or uninformative patterns and produce more faithful explanations. We further extend our approach with a class-specific variant that yields discriminative explanations. Evaluation against popular state-of-the-art methods demonstrates that our approach produces sharper and more interpretable maps. In addition to perturbation-based faithfulness metrics, we incorporate human gaze data to assess alignment with human perception, arguing that human interpretability remains essential for XAI. Across multiple datasets, our approach consistently outperforms or is comparable to the SOTA methods while remaining efficient and human plausible.

02 Apr 2025
Researchers from Smartesting and Université de Bordeaux explored the efficacy of autonomous web agents for executing natural language test cases, introducing a dedicated benchmark and two open-source agent implementations. Their advanced agent, PinATA, achieved a 50% higher True Accuracy compared to a baseline, though a qualitative analysis revealed five categories of persistent limitations.

30 Aug 2024
Dynamic networks are a complex subject. Not only do they inherit the
complexity of static networks (as a particular case); they are also sensitive
to definitional subtleties that are a frequent source of confusion and
incomparability of results in the literature.
In this paper, we take a step back and examine three such aspects in more
details, exploring their impact in a systematic way; namely, whether the
temporal paths are required to be \emph{strict} (i.e., the times along a path
must increasing, not just be non-decreasing), whether the time labeling is
\emph{proper} (two adjacent edges cannot be present at the same time) and
whether the time labeling is \emph{simple} (an edge can have only one presence
time). In particular, we investigate how different combinations of these
features impact the expressivity of the graph in terms of reachability.
Our results imply a hierarchy of expressivity for the resulting settings,
shedding light on the loss of generality that one is making when considering
either combination. Some settings are more general than expected; in
particular, proper temporal graphs turn out to be as expressive as general
temporal graphs where non-strict paths are allowed. Also, we show that the
simplest setting, that of \emph{happy} temporal graphs (i.e., both proper and
simple) remains expressive enough to emulate the reachability of general
temporal graphs in a certain (restricted but useful) sense. Furthermore, this
setting is advocated as a target of choice for proving negative results. We
illustrates this by strengthening two known results to happy graphs (namely,
the inexistence of sparse spanners, and the hardness of computing temporal
components). Overall, we hope that this article can be seen as a guide for
choosing between different settings of temporal graphs, while being aware of
the way these choices affect generality.

02 Aug 2025
 CNRSJapan Advanced Institute of Science and TechnologySapienza University of RomeUniversity of GalwayVietnam National UniversityHo Chi Minh City University of TechnologyUniversity of BordeauxLaBRIBordeaux INPUniversity of South-Eastern NorwayUniversity of Naples "Parthenope"VNU Information Technology InstituteHo Chi Minh City International University
CNRSJapan Advanced Institute of Science and TechnologySapienza University of RomeUniversity of GalwayVietnam National UniversityHo Chi Minh City University of TechnologyUniversity of BordeauxLaBRIBordeaux INPUniversity of South-Eastern NorwayUniversity of Naples "Parthenope"VNU Information Technology InstituteHo Chi Minh City International UniversityThe growing integration of Artificial Intelligence (AI) into education has intensified the need for transparency and interpretability. While hackathons have long served as agile environments for rapid AI prototyping, few have directly addressed eXplainable AI (XAI) in real-world educational contexts. This paper presents a comprehensive analysis of the XAI Challenge 2025, a hackathon-style competition jointly organized by Ho Chi Minh City University of Technology (HCMUT) and the International Workshop on Trustworthiness and Reliability in Neurosymbolic AI (TRNS-AI), held as part of the International Joint Conference on Neural Networks (IJCNN 2025). The challenge tasked participants with building Question-Answering (QA) systems capable of answering student queries about university policies while generating clear, logic-based natural language explanations. To promote transparency and trustworthiness, solutions were required to use lightweight Large Language Models (LLMs) or hybrid LLM-symbolic systems. A high-quality dataset was provided, constructed via logic-based templates with Z3 validation and refined through expert student review to ensure alignment with real-world academic scenarios. We describe the challenge's motivation, structure, dataset construction, and evaluation protocol. Situating the competition within the broader evolution of AI hackathons, we argue that it represents a novel effort to bridge LLMs and symbolic reasoning in service of explainability. Our findings offer actionable insights for future XAI-centered educational systems and competitive research initiatives.

05 Jul 2025
We propose a physics-informed machine learning framework called P-DivGNN to reconstruct local stress fields at the micro-scale, in the context of multi-scale simulation given a periodic micro-structure mesh and mean, macro-scale, stress values. This method is based in representing a periodic micro-structure as a graph, combined with a message passing graph neural network. We are able to retrieve local stress field distributions, providing average stress values produced by a mean field reduced order model (ROM) or Finite Element (FE) simulation at the macro-scale. The prediction of local stress fields are of utmost importance considering fracture analysis or the definition of local fatigue criteria. Our model incorporates physical constraints during training to constraint local stress field equilibrium state and employs a periodic graph representation to enforce periodic boundary conditions. The benefits of the proposed physics-informed GNN are evaluated considering linear and non linear hyperelastic responses applied to varying geometries. In the non-linear hyperelastic case, the proposed method achieves significant computational speed-ups compared to FE simulation, making it particularly attractive for large-scale applications.
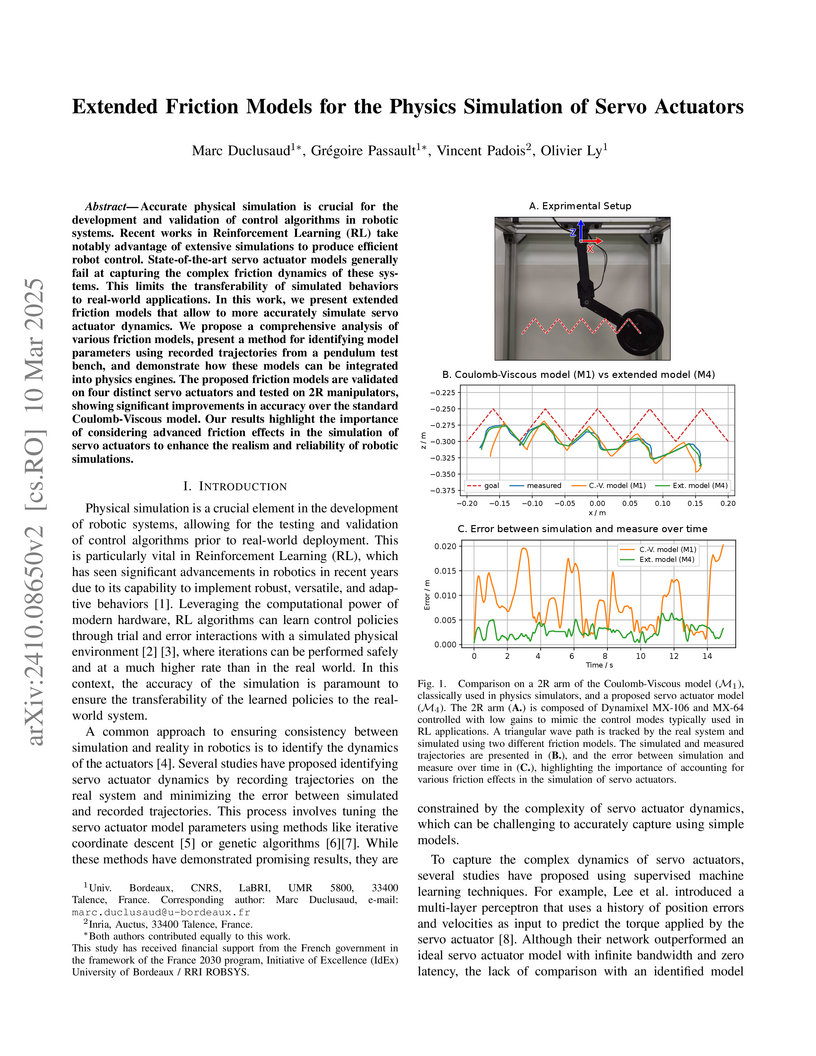
10 Mar 2025

Accurate physical simulation is crucial for the development and validation of
control algorithms in robotic systems. Recent works in Reinforcement Learning
(RL) take notably advantage of extensive simulations to produce efficient robot
control. State-of-the-art servo actuator models generally fail at capturing the
complex friction dynamics of these systems. This limits the transferability of
simulated behaviors to real-world applications. In this work, we present
extended friction models that allow to more accurately simulate servo actuator
dynamics. We propose a comprehensive analysis of various friction models,
present a method for identifying model parameters using recorded trajectories
from a pendulum test bench, and demonstrate how these models can be integrated
into physics engines.
The proposed friction models are validated on four distinct servo actuators
and tested on 2R manipulators, showing significant improvements in accuracy
over the standard Coulomb-Viscous model. Our results highlight the importance
of considering advanced friction effects in the simulation of servo actuators
to enhance the realism and reliability of robotic simulations.

01 Feb 2024
In 2023, Rhoban Football Club reached the first place of the KidSize soccer competition for the fifth time, and received the best humanoid award. This paper presents and reviews important points in robots architecture and workflow, with hindsights from the competition.

04 Nov 2025
Humanoid robotics faces significant challenges in achieving stable locomotion and recovering from falls in dynamic environments. Traditional methods, such as Model Predictive Control (MPC) and Key Frame Based (KFB) routines, either require extensive fine-tuning or lack real-time adaptability. This paper introduces FRASA, a Deep Reinforcement Learning (DRL) agent that integrates fall recovery and stand up strategies into a unified framework. Leveraging the Cross-Q algorithm, FRASA significantly reduces training time and offers a versatile recovery strategy that adapts to unpredictable disturbances. Comparative tests on Sigmaban humanoid robots demonstrate FRASA superior performance against the KFB method deployed in the RoboCup 2023 by the Rhoban Team, world champion of the KidSize League.

17 Dec 2024
Designing a humanoid locomotion controller is challenging and classically
split up in sub-problems. Footstep planning is one of those, where the sequence
of footsteps is defined. Even in simpler environments, finding a minimal
sequence, or even a feasible sequence, yields a complex optimization problem.
In the literature, this problem is usually addressed by search-based algorithms
(e.g. variants of A*). However, such approaches are either computationally
expensive or rely on hand-crafted tuning of several parameters. In this work,
at first, we propose an efficient footstep planning method to navigate in local
environments with obstacles, based on state-of-the art Deep Reinforcement
Learning (DRL) techniques, with very low computational requirements for on-line
inference. Our approach is heuristic-free and relies on a continuous set of
actions to generate feasible footsteps. In contrast, other methods necessitate
the selection of a relevant discrete set of actions. Second, we propose a
forecasting method, allowing to quickly estimate the number of footsteps
required to reach different candidates of local targets. This approach relies
on inherent computations made by the actor-critic DRL architecture. We
demonstrate the validity of our approach with simulation results, and by a
deployment on a kid-size humanoid robot during the RoboCup 2023 competition.

17 Mar 2019
Superpixel decomposition methods are generally used as a pre-processing step
to speed up image processing tasks. They group the pixels of an image into
homogeneous regions while trying to respect existing contours. For all
state-of-the-art superpixel decomposition methods, a trade-off is made between
1) computational time, 2) adherence to image contours and 3) regularity and
compactness of the decomposition. In this paper, we propose a fast method to
compute Superpixels with Contour Adherence using Linear Path (SCALP) in an
iterative clustering framework. The distance computed when trying to associate
a pixel to a superpixel during the clustering is enhanced by considering the
linear path to the superpixel barycenter. The proposed framework produces
regular and compact superpixels that adhere to the image contours. We provide a
detailed evaluation of SCALP on the standard Berkeley Segmentation Dataset. The
obtained results outperform state-of-the-art methods in terms of standard
superpixel and contour detection metrics.

25 Sep 2025
Superpixels have become very popular in many computer vision applications. Nevertheless, they remain underexploited since the superpixel decomposition may produce irregular and non stable segmentation results due to the dependency to the image content. In this paper, we first introduce a novel structure, a superpixel-based patch, called SuperPatch. The proposed structure, based on superpixel neighborhood, leads to a robust descriptor since spatial information is naturally included. The generalization of the PatchMatch method to SuperPatches, named SuperPatchMatch, is introduced. Finally, we propose a framework to perform fast segmentation and labeling from an image database, and demonstrate the potential of our approach since we outperform, in terms of computational cost and accuracy, the results of state-of-the-art methods on both face labeling and medical image segmentation.

13 Nov 2025
In property testing, a tester makes queries to (an oracle for) a graph and, on a graph having or being far from having a property P, it decides with high probability whether the graph satisfies P or not. Often, testers are restricted to a constant number of queries. While the graph properties for which there exists such a tester are somewhat well characterized in the dense graph model, it is not the case for sparse graphs. In this area, Czumaj and Sohler (FOCS'19) proved that H-freeness (i.e. the property of excluding the graph H as a subgraph) can be tested with constant queries on planar graphs as well as on graph classes excluding a minor.
Using results from the sparsity toolkit, we propose a simpler alternative to the proof of Czumaj and Sohler, for a statement generalized to the broader notion of bounded expansion. That is, we prove that for any class C with bounded expansion and any graph H, testing H-freeness can be done with constant query complexity on any graph G in C, where the constant depends on H and C, but is independent of G.
While classes excluding a minor are prime examples of classes with bounded expansion, so are, for example, cubic graphs, graph classes with bounded maximum degree, graphs of bounded book thickness, or random graphs of bounded average degree.

22 Jul 2025
Generative artificial intelligence raises concerns related to energy consumption, copyright infringement and creative atrophy. We show that randomly initialized recurrent neural networks can produce arpeggios and low-frequency oscillations that are rich and configurable. In contrast to end-to-end music generation that aims to replace musicians, our approach expands their creativity while requiring no data and much less computational power. More information can be found at: this https URL

26 May 2025
The differential diagnosis of neurodegenerative dementias is a challenging
clinical task, mainly because of the overlap in symptom presentation and the
similarity of patterns observed in structural neuroimaging. To improve
diagnostic efficiency and accuracy, deep learning-based methods such as
Convolutional Neural Networks and Vision Transformers have been proposed for
the automatic classification of brain MRIs. However, despite their strong
predictive performance, these models find limited clinical utility due to their
opaque decision making. In this work, we propose a framework that integrates
two core components to enhance diagnostic transparency. First, we introduce a
modular pipeline for converting 3D T1-weighted brain MRIs into textual
radiology reports. Second, we explore the potential of modern Large Language
Models (LLMs) to assist clinicians in the differential diagnosis between
Frontotemporal dementia subtypes, Alzheimer's disease, and normal aging based
on the generated reports. To bridge the gap between predictive accuracy and
explainability, we employ reinforcement learning to incentivize diagnostic
reasoning in LLMs. Without requiring supervised reasoning traces or
distillation from larger models, our approach enables the emergence of
structured diagnostic rationales grounded in neuroimaging findings. Unlike
post-hoc explainability methods that retrospectively justify model decisions,
our framework generates diagnostic rationales as part of the inference
process-producing causally grounded explanations that inform and guide the
model's decision-making process. In doing so, our framework matches the
diagnostic performance of existing deep learning methods while offering
rationales that support its diagnostic conclusions.

14 Mar 2023
A Boolean network (BN) is a discrete dynamical system defined by a Boolean function that maps to the domain itself. A trap space of a BN is a generalization of a fixed point, which is defined as the sub-hypercubes closed by the function of the BN. A trap space is minimal if it does not contain any smaller trap space. Minimal trap spaces have applications for the analysis of attractors of BNs with various update modes. This paper establishes the computational complexity results of three decision problems related to minimal trap spaces: the decision of the trap space property of a sub-hypercube, the decision of its minimality, and the decision of the membership of a given configuration to a minimal trap space. Under several cases on Boolean function representations, we investigate the computational complexity of each problem. In the general case, we demonstrate that the trap space property is coNP-complete, and the minimality and the membership properties are -complete. The complexities drop by one level in the polynomial hierarchy whenever the local functions of the BN are either unate, or are represented using truth-tables, binary decision diagrams, or double DNFs (Petri net encoding): the trap space property can be decided in a polynomial time, whereas deciding the minimality and the membership are coNP- complete. When the BN is given as its functional graph, all these problems are in P.

12 Aug 2025
Quantum query complexity is a fundamental model for analyzing the computational power of quantum algorithms. It has played a key role in characterizing quantum speedups, from early breakthroughs such as Grover's and Simon's algorithms to more recent developments in quantum cryptography and complexity theory. This document provides a structured introduction to quantum query lower bounds, focusing on four major techniques: the hybrid method, the polynomial method, the recording method, and the adversary method. Each method is developed from first principles and illustrated through canonical problems. Additionally, the document discusses how the adversary method can be used to derive upper bounds, highlighting its dual role in quantum query complexity. The goal is to offer a self-contained exposition accessible to readers with a basic background in quantum computing, while also serving as an entry point for researchers interested in the study of quantum lower bounds.

13 Jul 2023
This paper deals with the trade-off between time, workload, and versatility
in self-stabilization, a general and lightweight fault-tolerant concept in
distributed computing.In this context, we propose a transformer that provides
an asynchronous silent self-stabilizing version Trans(AlgI) of any terminating
synchronous algorithm AlgI. The transformed algorithm Trans(AlgI) works under
the distributed unfair daemon and is efficient both in moves and rounds.Our
transformer allows to easily obtain fully-polynomial silent self-stabilizing
solutions that are also asymptotically optimal in rounds.We illustrate the
efficiency and versatility of our transformer with several efficient (i.e.,
fully-polynomial) silent self-stabilizing instances solving major distributed
computing problems, namely vertex coloring, Breadth-First Search (BFS) spanning
tree construction, k-clustering, and leader election.

02 Oct 2024
Byte-Pair Encoding (BPE) is an algorithm commonly used in Natural Language Processing to build a vocabulary of subwords, which has been recently applied to symbolic music. Given that symbolic music can differ significantly from text, particularly with polyphony, we investigate how BPE behaves with different types of musical content. This study provides a qualitative analysis of BPE's behavior across various instrumentations and evaluates its impact on a musical phrase segmentation task for both monophonic and polyphonic music. Our findings show that the BPE training process is highly dependent on the instrumentation and that BPE "supertokens" succeed in capturing abstract musical content. In a musical phrase segmentation task, BPE notably improves performance in a polyphonic setting, but enhances performance in monophonic tunes only within a specific range of BPE merges.

17 Sep 2014
Detection of community structures in social networks has attracted lots of attention in the domain of sociology and behavioral sciences. Social networks also exhibit dynamic nature as these networks change continuously with the passage of time. Social networks might also present a hierarchical structure led by individuals that play important roles in a society such as Managers and Decision Makers. Detection and Visualization of these networks changing over time is a challenging problem where communities change as a function of events taking place in the society and the role people play in it.
In this paper we address these issues by presenting a system to analyze dynamic social networks. The proposed system is based on dynamic graph discretization and graph clustering. The system allows detection of major structural changes taking place in social communities over time and reveals hierarchies by identifying influential people in a social networks. We use two different data sets for the empirical evaluation and observe that our system helps to discover interesting facts about the social and hierarchical structures present in these social networks.

23 Jul 2025
Understanding API evolution and the introduction of breaking changes (BCs) in software libraries is essential for library maintainers to manage backward compatibility and for researchers to conduct empirical studies on software library evolution. In Java, tools such as JApiCmp and Revapi are commonly used to detect BCs between library releases, but their reliance on binary JARs limits their applicability. This restriction hinders large-scale longitudinal studies of API evolution and fine-grained analyses such as commit-level BC detection. In this paper, we introduce Roseau, a novel static analysis tool that constructs technology-agnostic API models from library code equipped with rich semantic analyses. API models can be analyzed to study API evolution and compared to identify BCs between any two versions of a library (releases, commits, branches, etc.). Unlike traditional approaches, Roseau can build API models from source code or bytecode, and is optimized for large-scale longitudinal analyses of library histories. We assess the accuracy, performance, and suitability of Roseau for longitudinal studies of API evolution, using JApiCmp and Revapi as baselines. We extend and refine an established benchmark of BCs and show that Roseau achieves higher accuracy (F1 = 0.99) than JApiCmp (F1 = 0.86) and Revapi (F1 = 0.91). We analyze 60 popular libraries from Maven Central and find that Roseau delivers excellent performance, detecting BCs between versions in under two seconds, including in libraries with hundreds of thousands of lines of code. We further illustrate the limitations of JApiCmp and Revapi for longitudinal studies and the novel analysis capabilities offered by Roseau by tracking the evolution of Google's Guava API and the introduction of BCs over 14 years and 6,839 commits, reducing analysis times from a few days to a few minutes.
There are no more papers matching your filters at the moment.
