
17 Nov 2025


Semantic occupancy has emerged as a powerful representation in world models for its ability to capture rich spatial semantics. However, most existing occupancy world models rely on static and fixed embeddings or grids, which inherently limit the flexibility of perception. Moreover, their ``in-place classification" over grids exhibits a potential misalignment with the dynamic and continuous nature of real scenarios. In this paper, we propose SparseWorld, a novel 4D occupancy world model that is flexible, adaptive, and efficient, powered by sparse and dynamic queries. We propose a Range-Adaptive Perception module, in which learnable queries are modulated by the ego vehicle states and enriched with temporal-spatial associations to enable extended-range perception. To effectively capture the dynamics of the scene, we design a State-Conditioned Forecasting module, which replaces classification-based forecasting with regression-guided formulation, precisely aligning the dynamic queries with the continuity of the 4D environment. In addition, We specifically devise a Temporal-Aware Self-Scheduling training strategy to enable smooth and efficient training. Extensive experiments demonstrate that SparseWorld achieves state-of-the-art performance across perception, forecasting, and planning tasks. Comprehensive visualizations and ablation studies further validate the advantages of SparseWorld in terms of flexibility, adaptability, and efficiency.

29 Sep 2025

Diffusion Transformers (DiT)-based video generation models with 3D full attention exhibit strong generative capabilities. Trajectory control represents a user-friendly task in the field of controllable video generation. However, existing methods either require substantial training resources or are specifically designed for U-Net, do not take advantage of the superior performance of DiT. To address these issues, we propose DiTraj, a simple but effective training-free framework for trajectory control in text-to-video generation, tailored for DiT. Specifically, first, to inject the object's trajectory, we propose foreground-background separation guidance: we use the Large Language Model (LLM) to convert user-provided prompts into foreground and background prompts, which respectively guide the generation of foreground and background regions in the video. Then, we analyze 3D full attention and explore the tight correlation between inter-token attention scores and position embedding. Based on this, we propose inter-frame Spatial-Temporal Decoupled 3D-RoPE (STD-RoPE). By modifying only foreground tokens' position embedding, STD-RoPE eliminates their cross-frame spatial discrepancies, strengthening cross-frame attention among them and thus enhancing trajectory control. Additionally, we achieve 3D-aware trajectory control by regulating the density of position embedding. Extensive experiments demonstrate that our method outperforms previous methods in both video quality and trajectory controllability.

06 Aug 2025
Computer use agent is an emerging area in artificial intelligence that aims to operate the computers to achieve the user's tasks, which attracts a lot of attention from both industry and academia. However, the present agents' performance is far from being used. In this paper, we propose the Self-Evolution Agent (SEA) for computer use, and to develop this agent, we propose creative methods in data generation, reinforcement learning, and model enhancement. Specifically, we first propose an automatic pipeline to generate the verifiable trajectory for training. And then, we propose efficient step-wise reinforcement learning to alleviate the significant computational requirements for long-horizon training. In the end, we propose the enhancement method to merge the grounding and planning ability into one model without any extra training. Accordingly, based on our proposed innovation of data generation, training strategy, and enhancement, we get the Selfevolution Agent (SEA) for computer use with only 7B parameters, which outperforms models with the same number of parameters and has comparable performance to larger ones. We will make the models' weight and related codes open-source in the future.

06 Aug 2025


We introduce the Aging Multiverse, a framework for generating multiple plausible facial aging trajectories from a single image, each conditioned on external factors such as environment, health, and lifestyle. Unlike prior methods that model aging as a single deterministic path, our approach creates an aging tree that visualizes diverse futures. To enable this, we propose a training-free diffusion-based method that balances identity preservation, age accuracy, and condition control. Our key contributions include attention mixing to modulate editing strength and a Simulated Aging Regularization strategy to stabilize edits. Extensive experiments and user studies demonstrate state-of-the-art performance across identity preservation, aging realism, and conditional alignment, outperforming existing editing and age-progression models, which often fail to account for one or more of the editing criteria. By transforming aging into a multi-dimensional, controllable, and interpretable process, our approach opens up new creative and practical avenues in digital storytelling, health education, and personalized visualization.

14 Aug 2025

By integrating the perception capabilities of multimodal encoders with the generative power of Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), exemplified by GPT-4V, have achieved great success in various multimodal tasks, pointing toward a promising pathway to artificial general intelligence. Despite this progress, the limited quality of multimodal data, poor performance on many complex downstream tasks, and inadequate evaluation protocols continue to hinder the reliability and broader applicability of MLLMs across diverse domains. Inspired by the human ability to leverage external tools for enhanced reasoning and problem-solving, augmenting MLLMs with external tools (e.g., APIs, expert models, and knowledge bases) offers a promising strategy to overcome these challenges. In this paper, we present a comprehensive survey on leveraging external tools to enhance MLLM performance. Our discussion is structured along four key dimensions about external tools: (1) how they can facilitate the acquisition and annotation of high-quality multimodal data; (2) how they can assist in improving MLLM performance on challenging downstream tasks; (3) how they enable comprehensive and accurate evaluation of MLLMs; (4) the current limitations and future directions of tool-augmented MLLMs. Through this survey, we aim to underscore the transformative potential of external tools in advancing MLLM capabilities, offering a forward-looking perspective on their development and applications. The project page of this paper is publicly available athttps://github.com/Lackel/Awesome-Tools-for-MLLMs.

01 Oct 2024

In this paper, we introduce OmniHands, a universal approach to recovering
interactive hand meshes and their relative movement from monocular or
multi-view inputs. Our approach addresses two major limitations of previous
methods: lacking a unified solution for handling various hand image inputs and
neglecting the positional relationship of two hands within images. To overcome
these challenges, we develop a universal architecture with novel tokenization
and contextual feature fusion strategies, capable of adapting to a variety of
tasks. Specifically, we propose a Relation-aware Two-Hand Tokenization (RAT)
method to embed positional relation information into the hand tokens. In this
way, our network can handle both single-hand and two-hand inputs and explicitly
leverage relative hand positions, facilitating the reconstruction of intricate
hand interactions in real-world scenarios. As such tokenization indicates the
relative relationship of two hands, it also supports more effective feature
fusion. To this end, we further develop a 4D Interaction Reasoning (FIR) module
to fuse hand tokens in 4D with attention and decode them into 3D hand meshes
and relative temporal movements. The efficacy of our approach is validated on
several benchmark datasets. The results on in-the-wild videos and real-world
scenarios demonstrate the superior performances of our approach for interactive
hand reconstruction. More video results can be found on the project page:
this https URL

06 Aug 2025

Learning action models from real-world human-centric interaction datasets is important towards building general-purpose intelligent assistants with efficiency. However, most existing datasets only offer specialist interaction category and ignore that AI assistants perceive and act based on first-person acquisition. We urge that both the generalist interaction knowledge and egocentric modality are indispensable. In this paper, we embed the manual-assisted task into a vision-language-action framework, where the assistant provides services to the instructor following egocentric vision and commands. With our hybrid RGB-MoCap system, pairs of assistants and instructors engage with multiple objects and the scene following GPT-generated scripts. Under this setting, we accomplish InterVLA, the first large-scale human-object-human interaction dataset with 11.4 hours and 1.2M frames of multimodal data, spanning 2 egocentric and 5 exocentric videos, accurate human/object motions and verbal commands. Furthermore, we establish novel benchmarks on egocentric human motion estimation, interaction synthesis, and interaction prediction with comprehensive analysis. We believe that our InterVLA testbed and the benchmarks will foster future works on building AI agents in the physical world.

12 Nov 2025
Audio-Visual Target Speaker Extraction (AVTSE) aims to isolate a target speaker's voice in a multi-speaker environment with visual cues as auxiliary. Most of the existing AVTSE methods encode visual and audio features simultaneously, resulting in extremely high computational complexity and making it impractical for real-time processing on edge devices. To tackle this issue, we proposed a two-stage ultra-compact AVTSE system. Specifically, in the first stage, a compact network is employed for voice activity detection (VAD) using visual information. In the second stage, the VAD results are combined with audio inputs to isolate the target speaker's voice. Experiments show that the proposed system effectively suppresses background noise and interfering voices while spending little computational resources.

01 Sep 2024

Designing versatile graph learning approaches is important, considering the diverse graphs and tasks existing in real-world applications. Existing methods have attempted to achieve this target through automated machine learning techniques, pre-training and fine-tuning strategies, and large language models. However, these methods are not versatile enough for graph learning, as they work on either limited types of graphs or a single task. In this paper, we propose to explore versatile graph learning approaches with LLM-based agents, and the key insight is customizing the graph learning procedures for diverse graphs and tasks. To achieve this, we develop several LLM-based agents, equipped with diverse profiles, tools, functions and human experience. They collaborate to configure each procedure with task and data-specific settings step by step towards versatile solutions, and the proposed method is dubbed GL-Agent. By evaluating on diverse tasks and graphs, the correct results of the agent and its comparable performance showcase the versatility of the proposed method, especially in complex this http URL low resource cost and the potential to use open-source LLMs highlight the efficiency of GL-Agent.

09 Apr 2025
Open-World Tracking (OWT) aims to track every object of any category, which
requires the model to have strong generalization capabilities. Trackers can
improve their generalization ability by leveraging Visual Language Models
(VLMs). However, challenges arise with the fine-tuning strategies when VLMs are
transferred to OWT: full fine-tuning results in excessive parameter and memory
costs, while the zero-shot strategy leads to sub-optimal performance. To solve
the problem, EffOWT is proposed for efficiently transferring VLMs to OWT.
Specifically, we build a small and independent learnable side network outside
the VLM backbone. By freezing the backbone and only executing backpropagation
on the side network, the model's efficiency requirements can be met. In
addition, EffOWT enhances the side network by proposing a hybrid structure of
Transformer and CNN to improve the model's performance in the OWT field.
Finally, we implement sparse interactions on the MLP, thus reducing parameter
updates and memory costs significantly. Thanks to the proposed methods, EffOWT
achieves an absolute gain of 5.5% on the tracking metric OWTA for unknown
categories, while only updating 1.3% of the parameters compared to full
fine-tuning, with a 36.4% memory saving. Other metrics also demonstrate obvious
improvement.

17 Feb 2020




Domain-specific software and hardware co-design is encouraging as it is much
easier to achieve efficiency for fewer tasks. Agile domain-specific
benchmarking speeds up the process as it provides not only relevant design
inputs but also relevant metrics, and tools. Unfortunately, modern workloads
like Big data, AI, and Internet services dwarf the traditional one in terms of
code size, deployment scale, and execution path, and hence raise serious
benchmarking challenges.
This paper proposes an agile domain-specific benchmarking methodology.
Together with seventeen industry partners, we identify ten important end-to-end
application scenarios, among which sixteen representative AI tasks are
distilled as the AI component benchmarks. We propose the permutations of
essential AI and non-AI component benchmarks as end-to-end benchmarks. An
end-to-end benchmark is a distillation of the essential attributes of an
industry-scale application. We design and implement a highly extensible,
configurable, and flexible benchmark framework, on the basis of which, we
propose the guideline for building end-to-end benchmarks, and present the first
end-to-end Internet service AI benchmark.
The preliminary evaluation shows the value of our benchmark suite---AIBench
against MLPerf and TailBench for hardware and software designers,
micro-architectural researchers, and code developers. The specifications,
source code, testbed, and results are publicly available from the web site
\url{this http URL}.

19 Apr 2024

Clothes-changing person re-identification (CC-ReID) aims to retrieve images of the same person wearing different outfits. Mainstream researches focus on designing advanced model structures and strategies to capture identity information independent of clothing. However, the same-clothes discrimination as the standard ReID learning objective in CC-ReID is persistently ignored in previous researches. In this study, we dive into the relationship between standard and clothes-changing~(CC) learning objectives, and bring the inner conflicts between these two objectives to the fore. We try to magnify the proportion of CC training pairs by supplementing high-fidelity clothes-varying synthesis, produced by our proposed Clothes-Changing Diffusion model. By incorporating the synthetic images into CC-ReID model training, we observe a significant improvement under CC protocol. However, such improvement sacrifices the performance under the standard protocol, caused by the inner conflict between standard and CC. For conflict mitigation, we decouple these objectives and re-formulate CC-ReID learning as a multi-objective optimization (MOO) problem. By effectively regularizing the gradient curvature across multiple objectives and introducing preference restrictions, our MOO solution surpasses the single-task training paradigm. Our framework is model-agnostic, and demonstrates superior performance under both CC and standard ReID protocols.

03 Dec 2020



Purpose: Accurate segmentation of lung and infection in COVID-19 CT scans plays an important role in the quantitative management of patients. Most of the existing studies are based on large and private annotated datasets that are impractical to obtain from a single institution, especially when radiologists are busy fighting the coronavirus disease. Furthermore, it is hard to compare current COVID-19 CT segmentation methods as they are developed on different datasets, trained in different settings, and evaluated with different metrics. Methods: To promote the development of data-efficient deep learning methods, in this paper, we built three benchmarks for lung and infection segmentation based on 70 annotated COVID-19 cases, which contain current active research areas, e.g., few-shot learning, domain generalization, and knowledge transfer. For a fair comparison among different segmentation methods, we also provide standard training, validation and testing splits, evaluation metrics and, the corresponding code. Results: Based on the state-of-the-art network, we provide more than 40 pre-trained baseline models, which not only serve as out-of-the-box segmentation tools but also save computational time for researchers who are interested in COVID-19 lung and infection segmentation. We achieve average Dice Similarity Coefficient (DSC) scores of 97.3\%, 97.7\%, and 67.3\% and average Normalized Surface Dice (NSD) scores of 90.6\%, 91.4\%, and 70.0\% for left lung, right lung, and infection, respectively. Conclusions: To the best of our knowledge, this work presents the first data-efficient learning benchmark for medical image segmentation and the largest number of pre-trained models up to now. All these resources are publicly available, and our work lays the foundation for promoting the development of deep learning methods for efficient COVID-19 CT segmentation with limited data.

29 Dec 2020
Automatic brain tumor segmentation from multi-modality Magnetic Resonance Images (MRI) using deep learning methods plays an important role in assisting the diagnosis and treatment of brain tumor. However, previous methods mostly ignore the latent relationship among different modalities. In this work, we propose a novel end-to-end Modality-Pairing learning method for brain tumor segmentation. Paralleled branches are designed to exploit different modality features and a series of layer connections are utilized to capture complex relationships and abundant information among modalities. We also use a consistency loss to minimize the prediction variance between two branches. Besides, learning rate warmup strategy is adopted to solve the problem of the training instability and early over-fitting. Lastly, we use average ensemble of multiple models and some post-processing techniques to get final results. Our method is tested on the BraTS 2020 online testing dataset, obtaining promising segmentation performance, with average dice scores of 0.891, 0.842, 0.816 for the whole tumor, tumor core and enhancing tumor, respectively. We won the second place of the BraTS 2020 Challenge for the tumor segmentation task.

03 Aug 2023
In recent years, dominant Multi-object tracking (MOT) and segmentation (MOTS) methods mainly follow the tracking-by-detection paradigm. Transformer-based end-to-end (E2E) solutions bring some ideas to MOT and MOTS, but they cannot achieve a new state-of-the-art (SOTA) performance in major MOT and MOTS benchmarks. Detection and association are two main modules of the tracking-by-detection paradigm. Association techniques mainly depend on the combination of motion and appearance information. As deep learning has been recently developed, the performance of the detection and appearance model is rapidly improved. These trends made us consider whether we can achieve SOTA based on only high-performance detection and appearance model. Our paper mainly focuses on exploring this direction based on CBNetV2 with Swin-B as a detection model and MoCo-v2 as a self-supervised appearance model. Motion information and IoU mapping were removed during the association. Our method wins 1st place on the MOTS track and wins 2nd on the MOT track in the CVPR2023 WAD workshop. We hope our simple and effective method can give some insights to the MOT and MOTS research community. Source code will be released under this git repository

24 Jul 2018
This short paper reports the algorithms we used and the evaluation
performances for ISIC Challenge 2018. Our team participates in all the tasks in
this challenge. In lesion segmentation task, the pyramid scene parsing network
(PSPNet) is modified to segment the lesions. In lesion attribute detection
task, the modified PSPNet is also adopted in a multi-label way. In disease
classification task, the DenseNet-169 is adopted for multi-class
classification.
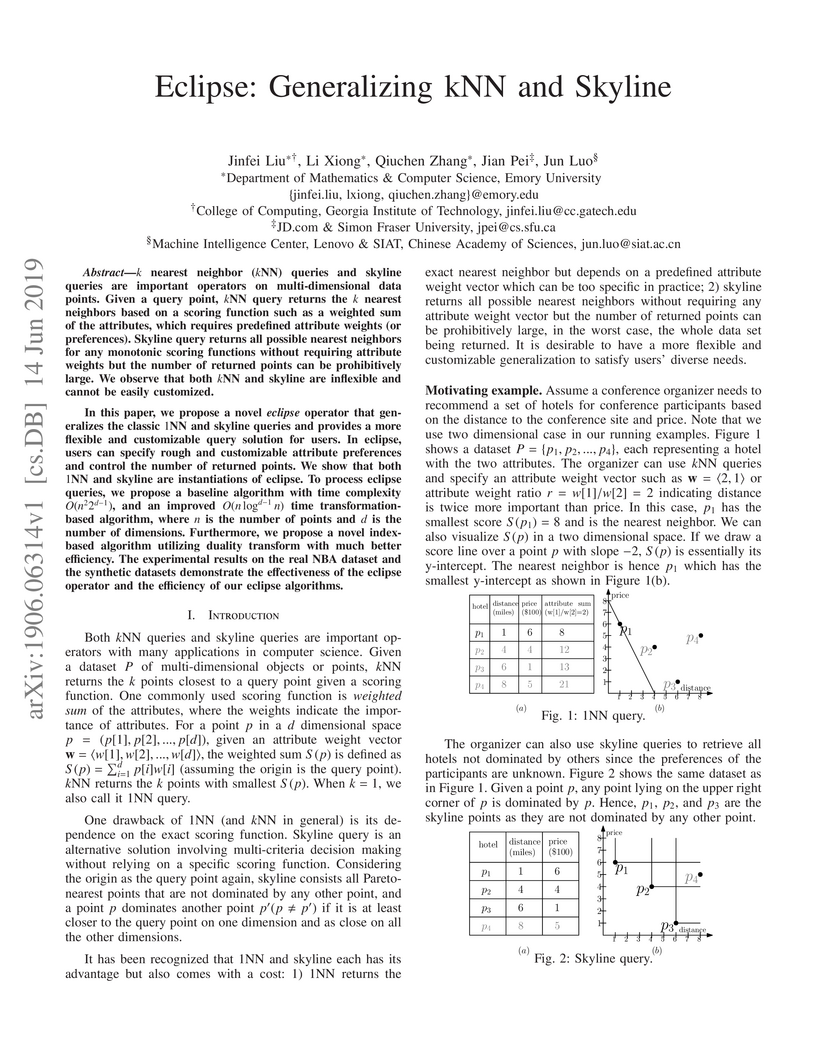
14 Jun 2019


nearest neighbor (NN) queries and skyline queries are important
operators on multi-dimensional data points. Given a query point, NN query
returns the nearest neighbors based on a scoring function such as a
weighted sum of the attributes, which requires predefined attribute weights (or
preferences). Skyline query returns all possible nearest neighbors for any
monotonic scoring functions without requiring attribute weights but the number
of returned points can be prohibitively large. We observe that both NN and
skyline are inflexible and cannot be easily customized.
In this paper, we propose a novel \emph{eclipse} operator that generalizes
the classic NN and skyline queries and provides a more flexible and
customizable query solution for users. In eclipse, users can specify rough and
customizable attribute preferences and control the number of returned points.
We show that both NN and skyline are instantiations of eclipse. To process
eclipse queries, we propose a baseline algorithm with time complexity
, and an improved time transformation-based
algorithm, where is the number of points and is the number of
dimensions. Furthermore, we propose a novel index-based algorithm utilizing
duality transform with much better efficiency. The experimental results on the
real NBA dataset and the synthetic datasets demonstrate the effectiveness of
the eclipse operator and the efficiency of our eclipse algorithms.

23 Jun 2024
Spatial frequency estimation from a mixture of noisy sinusoids finds applications in various fields. While subspace-based methods offer cost-effective super-resolution parameter estimation, they demand precise array calibration, posing challenges for large antennas. In contrast, sparsity-based approaches outperform subspace methods, especially in scenarios with limited snapshots or correlated sources. This study focuses on direction-of-arrival (DOA) estimation using a partly calibrated rectangular array with fully calibrated subarrays. A gridless sparse formulation leveraging shift invariances in the array is developed, yielding two competitive algorithms under the alternating direction method of multipliers (ADMM) and successive convex approximation frameworks, respectively. Numerical simulations show the superior error performance of our proposed method, particularly in highly correlated scenarios, compared to the conventional subspace-based methods. It is demonstrated that the proposed formulation can also be adopted in the fully calibrated case to improve the robustness of the subspace-based methods to the source correlation. Furthermore, we provide a generalization of the proposed method to a more challenging case where a part of the sensors is unobservable due to failures.

17 Jun 2025
This paper introduces "System 0" as an emergent algorithmic layer that acts as a cognitive preprocessor, actively shaping information before human intuitive and deliberative thought. It demonstrates how modern AI functions as a cognitive extension while highlighting potential risks like sycophancy and bias amplification, proposing seven evidence-based frameworks for beneficial human-AI integration.

06 Feb 2021

In this paper, we present the submitted system for the third DIHARD Speech
Diarization Challenge from the DKU-Duke-Lenovo team. Our system consists of
several modules: voice activity detection (VAD), segmentation, speaker
embedding extraction, attentive similarity scoring, agglomerative hierarchical
clustering. In addition, the target speaker VAD (TSVAD) is used for the phone
call data to further improve the performance. Our final submitted system
achieves a DER of 15.43% for the core evaluation set and 13.39% for the full
evaluation set on task 1, and we also get a DER of 21.63% for core evaluation
set and 18.90% for full evaluation set on task 2.
There are no more papers matching your filters at the moment.
