
13 Apr 2022
Latent Diffusion Models (LDMs) enhance the computational efficiency of Diffusion Models by operating in a lower-dimensional latent space, enabling high-resolution image synthesis while significantly reducing training and inference costs. The approach achieves state-of-the-art or competitive performance on tasks like class-conditional ImageNet generation (FID 3.60), text-to-image synthesis, and inpainting, outperforming pixel-based DMs.

08 Oct 2025




The Memory-R1 framework equips large language model agents with adaptive memory management and utilization capabilities through reinforcement learning, achieving state-of-the-art performance on long-term conversational memory benchmarks with remarkably high data efficiency. It demonstrates relative improvements of up to 69% in BLEU-1 and 48% in F1 over existing baselines on the LoCoMo benchmark, requiring only 152 training question-answer pairs.

21 Nov 2025

Researchers from TUM and LMU developed OpenDriveVLA, an end-to-end Vision-Language Action (VLA) model that generates spatially-grounded driving actions directly from multimodal inputs. The model achieved state-of-the-art results on the nuScenes open-loop planning benchmark, with the 3B and 7B versions reaching an average L2 error of 0.33m, and also demonstrated strong performance in driving-related question answering tasks.

20 Oct 2025

StreamingThinker introduces a paradigm for Large Language Model (LLM) reasoning that enables concurrent input processing and thinking, inspired by human cognition. This approach reduces token-to-first-token (TTFT) latency by approximately 80% and overall time-level latency by over 60% while maintaining reasoning accuracy across various tasks.

18 Jul 2025


The Agentic Neural Network (ANN) framework introduces a method for Large Language Model (LLM)-based multi-agent systems to dynamically self-evolve their roles and coordination through a neural network-inspired architecture and textual backpropagation. This framework achieved 93.9% accuracy on HumanEval with GPT-4o mini, outperforming a GPT-4 baseline by 8.1 percentage points, and demonstrated performance improvements across diverse tasks while maintaining cost-effectiveness.

29 Sep 2025


Reinforcement Mid-Training (RMT) formalizes a critical third stage in large language model development, applying reinforcement learning on unlabeled pre-training data to systematically enhance complex reasoning capabilities. The method achieves up to +64.91% higher language modeling accuracy compared to prior RL-based mid-training approaches while reducing reasoning response length by up to 79%.
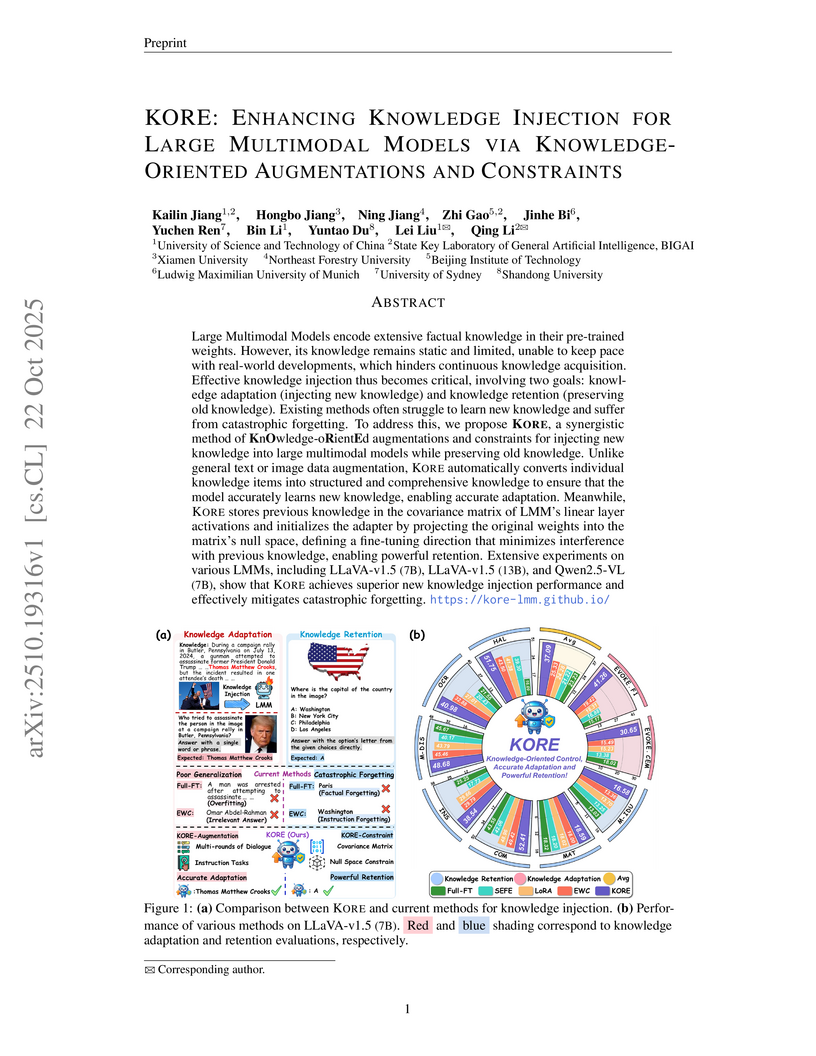
22 Oct 2025



KORE introduces a method for continually updating Large Multimodal Models (LMMs) by balancing the acquisition of new knowledge with the retention of existing information. It combines a knowledge-oriented data augmentation strategy with a novel constraint mechanism, resulting in improved knowledge adaptation (e.g., 12.63 point CEM and 21.27 point F1-Score increase on EVOKE) and robust retention across various LMMs and benchmarks.

12 Nov 2024
PERFT proposes a unified framework and a family of parameter-efficient fine-tuning strategies specifically for Mixture-of-Experts (MoE) models. The approach, particularly the PERFT-R variant, consistently outperforms MoE-agnostic PEFT baselines, achieving up to a 17.2% improvement on commonsense reasoning tasks with OLMoE-1B-7B by integrating dedicated routing mechanisms for PEFT experts.
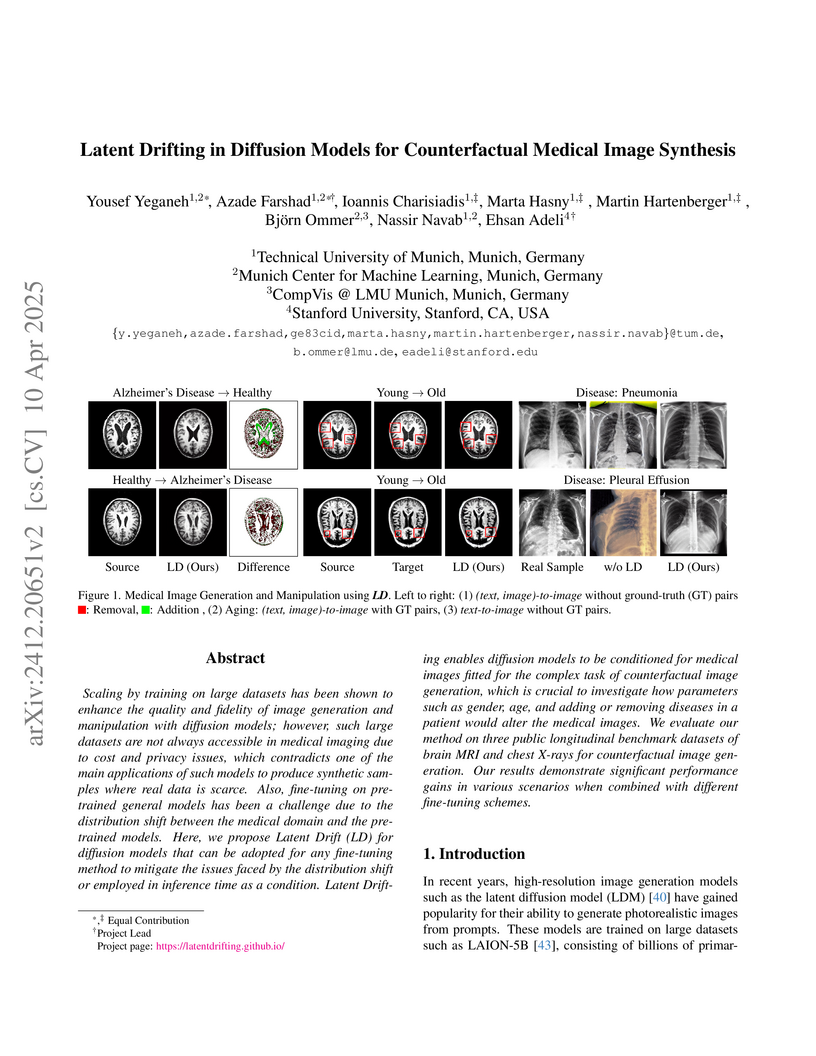
10 Apr 2025


Researchers from TUM, MCML, CompVis @ LMU Munich, and Stanford University developed Latent Drifting (LD), a method to adapt pre-trained diffusion models for high-fidelity counterfactual medical image synthesis. LD significantly improves image realism, reducing FID scores for brain MRIs from 92.13 to 49.68, and enhances the performance of downstream diagnostic classifiers when used for data augmentation.

16 Sep 2024
A comprehensive dataset of simulated pathloss and Time of Arrival (ToA) radio maps is made publicly available for 701 distinct urban environments, generated at 1-meter resolution using ray-tracing. This resource enables advanced deep learning research in radio map prediction and wireless localization, demonstrating that AI models can achieve superior localization accuracy in urban settings compared to traditional ToA methods.

24 Dec 2024
Understanding the benefits of quantum computing for solving combinatorial optimization problems (COPs) remains an open research question. In this work, we extend and analyze algorithms that solve COPs by recursively shrinking them. The algorithms leverage correlations between variables extracted from quantum or classical subroutines to recursively simplify the problem. We compare the performance of the algorithms equipped with correlations from the quantum approximate optimization algorithm (QAOA) as well as the classical linear programming (LP) and semi-definite programming (SDP) relaxations. This allows us to benchmark the utility of QAOA correlations against established classical relaxation algorithms. We apply the recursive algorithm to MaxCut problem instances with up to a hundred vertices at different graph densities. Our results indicate that LP outperforms all other approaches for low-density instances, while SDP excels for high-density problems. Moreover, the shrinking algorithm proves to be a viable alternative to established methods of rounding LP and SDP relaxations. In addition, the recursive shrinking algorithm outperforms its bare counterparts for all three types of correlations, i.e., LP with spanning tree rounding, the Goemans-Williamson algorithm, and conventional QAOA. While the lowest depth QAOA consistently yields worse results than the SDP, our tensor network experiments show that the performance increases significantly for deeper QAOA circuits.

24 Jul 2023



A systematic survey provides a comprehensive overview of prompt engineering techniques for Vision-Language Foundation Models, categorizing prompting methods, analyzing their application across multimodal-to-text, image-text matching, and text-to-image generation models, and outlining future research challenges.

12 Oct 2025


Retrieval-augmented generation (RAG) systems trained using reinforcement learning (RL) with reasoning are hampered by inefficient context management, where long, noisy retrieved documents increase costs and degrade performance. We introduce RECON (REasoning with CONdensation), a framework that integrates an explicit summarization module to compress evidence within the reasoning loop. Our summarizer is trained via a two-stage process: relevance pretraining on QA datasets, followed by multi-aspect distillation from proprietary LLMs to ensure factuality and clarity. Integrated into the Search-R1 pipeline, RECON reduces total context length by 35\%, leading to improved training speed and inference latency, while simultaneously improving RAG performance on downstream QA benchmarks. Notably, it boosts the average EM score of the 3B model by 14.5\% and the 7B model by 3.0\%, showing particular strength in multi-hop QA. RECON demonstrates that learned context compression is essential for building practical, scalable, and performant RAG systems. Our code implementation is made available at this https URL.

19 May 2025
Researchers from LMU Munich and collaborators introduce CoT-Kinetics, a theoretical framework that evaluates reasoning quality in Large Reasoning Models by modeling the reasoning process as particle motion through a force field, achieving superior performance across 7 open-source LRMs and 6 diverse benchmarks while enabling fine-grained assessment of reasoning trajectories beyond final answer correctness.

27 Jun 2025
RoboEnvision introduces a hierarchical video generation model that creates consistent, long-horizon robot manipulation videos from high-level instructions by bypassing autoregressive generation. A lightweight policy model trained on these generated videos achieves a 67.4% success rate on multi-task scenarios, outperforming existing methods and demonstrating the utility of the approach for robust robot policy learning.

03 Sep 2025
 Imperial College London
Imperial College London University of MarylandKyung Hee UniversityTechnische Universität MünchenMunich Center for Quantum Science and TechnologyUniversity of New MexicoUniversity of LeedsJoint Center for Quantum Information and Computer ScienceLudwig Maximilian University of MunichMax Planck Institute of Quantum OpticsThe NSF Institute for Robust Quantum Simulation
University of MarylandKyung Hee UniversityTechnische Universität MünchenMunich Center for Quantum Science and TechnologyUniversity of New MexicoUniversity of LeedsJoint Center for Quantum Information and Computer ScienceLudwig Maximilian University of MunichMax Planck Institute of Quantum OpticsThe NSF Institute for Robust Quantum SimulationRecent advances in quantum technologies have enabled quantum simulation of gauge theories -- some of the most fundamental frameworks of nature -- in regimes far from equilibrium, where classical computation is severely limited. These simulators, primarily based on neutral atoms, trapped ions, and superconducting circuits, hold the potential to address long-standing questions in nuclear, high-energy, and condensed-matter physics, and may ultimately allow first-principles studies of matter evolution in settings ranging from the early universe to high-energy collisions. Research in this rapidly growing field is also driving the convergence of concepts across disciplines and uncovering new phenomena. In this Review, we highlight recent experimental and theoretical developments, focusing on phenomena accessible in current and near-term quantum simulators, including particle production and string breaking, collision dynamics, thermalization, ergodicity breaking, and dynamical quantum phase transitions. We conclude by outlining promising directions for future research and opportunities enabled by available quantum hardware.

23 Jun 2025



We present a quantum simulation framework universally applicable to a wide class of quantum systems, including quantum field theories such as quantum chromodynamics (QCD). Specifically, we generalize an efficient quantum simulation protocol developed for bosonic theories in [Halimeh et al., arXiv:2411.13161] which, when applied to Yang-Mills theory, demonstrated an exponential resource advantage with respect to the truncation level of the bosonic modes, to systems with both bosons and fermions using the Jordan-Wigner transform and also the Verstraete-Cirac transform. We apply this framework to QCD using the orbifold lattice formulation and achieve an exponential speedup compared to previous proposals. As a by-product, exponential speedup is achieved in the quantum simulation of the Kogut-Susskind Hamiltonian, the latter being a special limit of the orbifold lattice Hamiltonian. In the case of Hamiltonian time evolution of a theory on an spatial lattice via Trotterization, one Trotter step can be realized using numbers of CNOT gates, Hadamard gates, phase gates, and one-qubit rotations. We show this analytically for any matter content and gauge group with any . Even when we use the Jordan-Wigner transform, we can utilize the cancellation of quantum gates to significantly simplify the quantum circuit. We also discuss a block encoding of the Hamiltonian as a linear combination of unitaries using the Verstraete-Cirac transform. Our protocols do not assume oracles, but rather present explicit constructions with rigorous resource estimations without a hidden cost, and are thus readily implementable on a quantum computer.

15 Oct 2025
Visual instruction tuning adapts pre-trained Multimodal Large Language Models (MLLMs) to follow human instructions for real-world applications. However, the rapid growth of these datasets introduces significant redundancy, leading to increased computational costs. Existing methods for selecting instruction data aim to prune this redundancy, but predominantly rely on computationally demanding techniques such as proxy-based inference or training-based metrics. Consequently, the substantial computational costs incurred by these selection processes often exacerbate the very efficiency bottlenecks they are intended to resolve, posing a significant challenge to the scalable and effective tuning of MLLMs. To address this challenge, we first identify a critical, yet previously overlooked, factor: the anisotropy inherent in visual feature distributions. We find that this anisotropy induces a \textit{Global Semantic Drift}, and overlooking this phenomenon is a key factor limiting the efficiency of current data selection methods. Motivated by this insight, we devise \textbf{PRISM}, the first training-free framework for efficient visual instruction selection. PRISM surgically removes the corrupting influence of global background features by modeling the intrinsic visual semantics via implicit re-centering. Empirically, PRISM reduces the end-to-end time for data selection and model tuning to just 30\% of conventional pipelines. More remarkably, it achieves this efficiency while simultaneously enhancing performance, surpassing models fine-tuned on the full dataset across eight multimodal and three language understanding benchmarks, culminating in a 101.7\% relative improvement over the baseline. The code is available for access via \href{this https URL}{this repository}.

02 Mar 2025

FedBiP integrates bi-level personalization of pretrained latent diffusion models within a one-shot federated learning framework, enabling the generation of high-quality, client-specific synthetic data. This approach effectively addresses data heterogeneity and scarcity while enhancing privacy and communication efficiency in decentralized settings.

22 Sep 2024
Research from TUM, LMU Munich, Oxford, and Huawei systematically investigated the adversarial robustness of Multimodal Large Language Models (MLLMs) leveraging Chain-of-Thought (CoT) reasoning. The study found that CoT provides only marginal robustness against existing image attacks and introduced a novel "Stop-Reasoning Attack" that effectively forces MLLMs to skip reasoning, leading to significantly higher attack success rates, while CoT's rationale still offered explainability into model misbehavior.
There are no more papers matching your filters at the moment.
