
08 Dec 2025

Utilizing multi-band JWST observations, this research reveals that high-redshift submillimeter galaxies primarily form through secular evolution and internal processes rather than major mergers, uncovering a significant population of central stellar structures that do not conform to established local galaxy classifications.

20 Mar 2023


T2I-Adapter enhances the controllability of large text-to-image diffusion models, such as Stable Diffusion, by introducing lightweight, trainable adapter networks that inject external control signals like sketches, depth maps, or color palettes. This method achieves superior image fidelity and alignment with control conditions while preserving the original model's generation quality and requiring minimal computational resources.

16 Oct 2025

Researchers at the Chinese Academy of Sciences developed QDepth-VLA, a framework that enhances Vision-Language-Action (VLA) models with robust 3D geometric understanding through quantized depth prediction as auxiliary supervision. This approach improves performance on fine-grained robotic manipulation tasks, achieving up to 29.7% higher success rates on complex simulated tasks and 20.0% gains in real-world pick-and-place scenarios compared to existing baselines.
05 Mar 2025


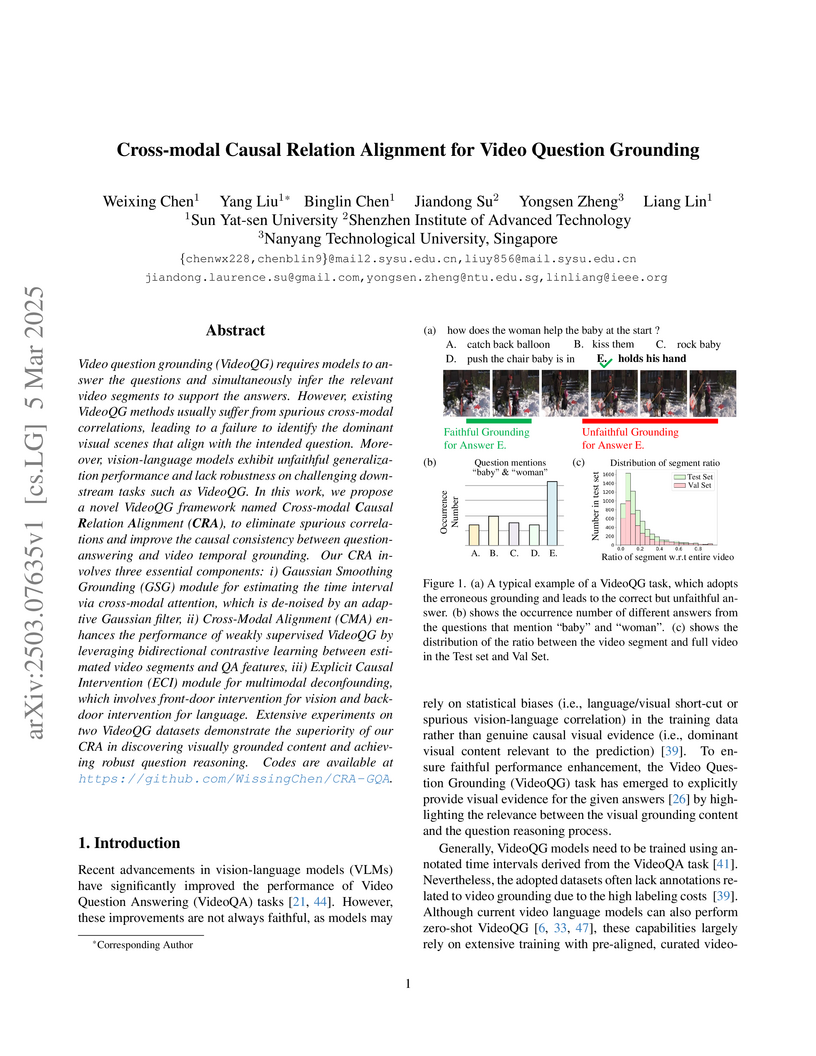
Video question grounding (VideoQG) requires models to answer the questions
and simultaneously infer the relevant video segments to support the answers.
However, existing VideoQG methods usually suffer from spurious cross-modal
correlations, leading to a failure to identify the dominant visual scenes that
align with the intended question. Moreover, vision-language models exhibit
unfaithful generalization performance and lack robustness on challenging
downstream tasks such as VideoQG. In this work, we propose a novel VideoQG
framework named Cross-modal Causal Relation Alignment (CRA), to eliminate
spurious correlations and improve the causal consistency between
question-answering and video temporal grounding. Our CRA involves three
essential components: i) Gaussian Smoothing Grounding (GSG) module for
estimating the time interval via cross-modal attention, which is de-noised by
an adaptive Gaussian filter, ii) Cross-Modal Alignment (CMA) enhances the
performance of weakly supervised VideoQG by leveraging bidirectional
contrastive learning between estimated video segments and QA features, iii)
Explicit Causal Intervention (ECI) module for multimodal deconfounding, which
involves front-door intervention for vision and back-door intervention for
language. Extensive experiments on two VideoQG datasets demonstrate the
superiority of our CRA in discovering visually grounded content and achieving
robust question reasoning. Codes are available at
this https URL

29 Sep 2025

While emotional text-to-speech (TTS) has made significant progress, most existing research remains limited to utterance-level emotional expression and fails to support word-level control. Achieving word-level expressive control poses fundamental challenges, primarily due to the complexity of modeling multi-emotion transitions and the scarcity of annotated datasets that capture intra-sentence emotional and prosodic variation. In this paper, we propose WeSCon, the first self-training framework that enables word-level control of both emotion and speaking rate in a pretrained zero-shot TTS model, without relying on datasets containing intra-sentence emotion or speed transitions. Our method introduces a transition-smoothing strategy and a dynamic speed control mechanism to guide the pretrained TTS model in performing word-level expressive synthesis through a multi-round inference process. To further simplify the inference, we incorporate a dynamic emotional attention bias mechanism and fine-tune the model via self-training, thereby activating its ability for word-level expressive control in an end-to-end manner. Experimental results show that WeSCon effectively overcomes data scarcity, achieving state-of-the-art performance in word-level emotional expression control while preserving the strong zero-shot synthesis capabilities of the original TTS model.

18 Sep 2025




MEDFACT-R1 introduces a two-stage framework that combines pseudo-label generation with Group Relative Policy Optimization (GRPO) and tailored reward signals to enhance factual medical reasoning in Vision-Language Models. The system achieved up to 22.5% absolute improvement in factual accuracy over previous state-of-the-art methods across multiple medical QA benchmarks.

11 Dec 2023

SmartEdit introduces an instruction-based image editing framework that incorporates Multimodal Large Language Models (MLLMs) to better interpret and execute complex natural language instructions. The approach utilizes a Bidirectional Interaction Module for two-way information exchange and demonstrates improved performance on tasks requiring spatial reasoning and attribute understanding on a newly created Reason-Edit dataset.

11 Jun 2024

Developed by Huawei Co., Ltd., CODER introduces a multi-agent framework guided by pre-defined task graphs to automate GitHub issue resolution. The system achieved a 28.33% resolved rate on SWE-bench lite, establishing a new state-of-the-art for the benchmark.

02 Jun 2024

Automatic report generation has arisen as a significant research area in computer-aided diagnosis, aiming to alleviate the burden on clinicians by generating reports automatically based on medical images. In this work, we propose a novel framework for automatic ultrasound report generation, leveraging a combination of unsupervised and supervised learning methods to aid the report generation process. Our framework incorporates unsupervised learning methods to extract potential knowledge from ultrasound text reports, serving as the prior information to guide the model in aligning visual and textual features, thereby addressing the challenge of feature discrepancy. Additionally, we design a global semantic comparison mechanism to enhance the performance of generating more comprehensive and accurate medical reports. To enable the implementation of ultrasound report generation, we constructed three large-scale ultrasound image-text datasets from different organs for training and validation purposes. Extensive evaluations with other state-of-the-art approaches exhibit its superior performance across all three datasets. Code and dataset are valuable at this link.

15 Oct 2025
Recent Large Language Models (LLMs) have demonstrated remarkable profi- ciency in code generation. However, their ability to create complex visualiza- tions for scaled and structured data remains largely unevaluated and underdevel- oped. To address this gap, we introduce PlotCraft, a new benchmark featuring 1k challenging visualization tasks that cover a wide range of topics, such as fi- nance, scientific research, and sociology. The benchmark is structured around seven high-level visualization tasks and encompasses 48 distinct chart types. Cru- cially, it is the first to systematically evaluate both single-turn generation and multi-turn refinement across a diverse spectrum of task complexities. Our com- prehensive evaluation of 23 leading LLMs on PlotCraft reveals obvious per- formance deficiencies in handling sophisticated visualization tasks. To bridge this performance gap, we develope SynthVis-30K, a large-scale, high-quality dataset of complex visualization code synthesized via a collaborative agent frame- work. Building upon this dataset, we develope PlotCraftor, a novel code gener- ation model that achieves strong capabilities in complex data visualization with a remarkably small size. Across VisEval, PandasPlotBench, and our proposed PlotCraft, PlotCraftor shows performance comparable to that of leading propri- etary approaches. Especially, on hard task, Our model achieves over 50% per- formance improvement. We will release the benchmark, dataset, and code at this https URL.

01 Oct 2025


While Large Language Models (LLMs) have become the predominant paradigm for automated code generation, current single-model approaches fundamentally ignore the heterogeneous computational strengths that different models exhibit across programming languages, algorithmic domains, and development stages. This paper challenges the single-model convention by introducing a multi-stage, performance-guided orchestration framework that dynamically routes coding tasks to the most suitable LLMs within a structured generate-fix-refine workflow. Our approach is grounded in a comprehensive empirical study of 17 state-of-the-art LLMs across five programming languages (Python, Java, C++, Go, and Rust) using HumanEval-X benchmark. The study, which evaluates both functional correctness and runtime performance metrics (execution time, mean/max memory utilization, and CPU efficiency), reveals pronounced performance heterogeneity by language, development stage, and problem category. Guided by these empirical insights, we present PerfOrch, an LLM agent that orchestrates top-performing LLMs for each task context through stage-wise validation and rollback mechanisms. Without requiring model fine-tuning, PerfOrch achieves substantial improvements over strong single-model baselines: average correctness rates of 96.22% and 91.37% on HumanEval-X and EffiBench-X respectively, surpassing GPT-4o's 78.66% and 49.11%. Beyond correctness gains, the framework delivers consistent performance optimizations, improving execution time for 58.76% of problems with median speedups ranging from 17.67% to 27.66% across languages on two benchmarks. The framework's plug-and-play architecture ensures practical scalability, allowing new LLMs to be profiled and integrated seamlessly, thereby offering a paradigm for production-grade automated software engineering that adapts to the rapidly evolving generative AI landscape.

01 Apr 2025

Researchers developed LARF (Let AI Read First), an AI-powered system leveraging GPT-4 to annotate important information in texts with visual cues, improving reading performance and subjective experience for individuals with dyslexia, particularly those with more severe conditions. The system enhanced objective detail retrieval and comprehension while preserving original content.

25 Mar 2025

Creating a high-fidelity, animatable 3D full-body avatar from a single image
is a challenging task due to the diverse appearance and poses of humans and the
limited availability of high-quality training data. To achieve fast and
high-quality human reconstruction, this work rethinks the task from the
perspectives of dataset, model, and representation. First, we introduce a
large-scale HUman-centric GEnerated dataset, HuGe100K, consisting of 100K
diverse, photorealistic sets of human images. Each set contains 24-view frames
in specific human poses, generated using a pose-controllable
image-to-multi-view model. Next, leveraging the diversity in views, poses, and
appearances within HuGe100K, we develop a scalable feed-forward transformer
model to predict a 3D human Gaussian representation in a uniform space from a
given human image. This model is trained to disentangle human pose, body shape,
clothing geometry, and texture. The estimated Gaussians can be animated without
post-processing. We conduct comprehensive experiments to validate the
effectiveness of the proposed dataset and method. Our model demonstrates the
ability to efficiently reconstruct photorealistic humans at 1K resolution from
a single input image using a single GPU instantly. Additionally, it seamlessly
supports various applications, as well as shape and texture editing tasks.
Project page: this https URL

15 Sep 2025

While generative world models have advanced video and occupancy-based data synthesis, LiDAR generation remains underexplored despite its importance for accurate 3D perception. Extending generation to 4D LiDAR data introduces challenges in controllability, temporal stability, and evaluation. We present LiDARCrafter, a unified framework that converts free-form language into editable LiDAR sequences. Instructions are parsed into ego-centric scene graphs, which a tri-branch diffusion model transforms into object layouts, trajectories, and shapes. A range-image diffusion model generates the initial scan, and an autoregressive module extends it into a temporally coherent sequence. The explicit layout design further supports object-level editing, such as insertion or relocation. To enable fair assessment, we provide EvalSuite, a benchmark spanning scene-, object-, and sequence-level metrics. On nuScenes, LiDARCrafter achieves state-of-the-art fidelity, controllability, and temporal consistency, offering a foundation for LiDAR-based simulation and data augmentation.

14 Jul 2025

Code large language models (LLMs) enhance programming by understanding and generating code across languages, offering intelligent feedback, bug detection, and code updates through reflection, improving development efficiency and accessibility. While benchmarks (e.g. HumanEval/LiveCodeBench) evaluate code generation and real-world relevance, previous works ignore the scenario of modifying code in repositories. Considering challenges remaining in improving reflection capabilities and avoiding data contamination in dynamic benchmarks, we introduce LiveRepoReflection, a challenging benchmark for evaluating code understanding and generation in multi-file repository contexts, featuring 1,888 rigorously filtered test cases across programming languages to ensure diversity, correctness, and high difficulty. Further, we create RepoReflection-Instruct, a large-scale, quality-filtered instruction-tuning dataset derived from diverse sources, used to train RepoReflectionCoder through a two-turn dialogue process involving code generation and error-driven repair. The leaderboard evaluates over 40 LLMs to reflect the model performance of repository-based code reflection.

30 Oct 2024

This work focuses on generating high-quality images with specific style of reference images and content of provided textual descriptions. Current leading algorithms, i.e., DreamBooth and LoRA, require fine-tuning for each style, leading to time-consuming and computationally expensive processes. In this work, we propose StyleAdapter, a unified stylized image generation model capable of producing a variety of stylized images that match both the content of a given prompt and the style of reference images, without the need for per-style fine-tuning. It introduces a two-path cross-attention (TPCA) module to separately process style information and textual prompt, which cooperate with a semantic suppressing vision model (SSVM) to suppress the semantic content of style images. In this way, it can ensure that the prompt maintains control over the content of the generated images, while also mitigating the negative impact of semantic information in style references. This results in the content of the generated image adhering to the prompt, and its style aligning with the style references. Besides, our StyleAdapter can be integrated with existing controllable synthesis methods, such as T2I-adapter and ControlNet, to attain a more controllable and stable generation process. Extensive experiments demonstrate the superiority of our method over previous works.

23 Dec 2024

Large Language Models (LLMs) have advanced rapidly in recent years, with their applications in software engineering expanding to more complex repository-level tasks. GitHub issue resolving is a key challenge among these tasks. While recent approaches have made progress on this task, they focus on textual data within issues, neglecting visual data. However, this visual data is crucial for resolving issues as it conveys additional knowledge that text alone cannot. We propose CodeV, the first approach to leveraging visual data to enhance the issue-resolving capabilities of LLMs. CodeV resolves each issue by following a two-phase process: data processing and patch generation. To evaluate CodeV, we construct a benchmark for visual issue resolving, namely Visual SWE-bench. Through extensive experiments, we demonstrate the effectiveness of CodeV, as well as provide valuable insights into leveraging visual data to resolve GitHub issues.

28 Feb 2025
EdgeLLM, a CPU-FPGA heterogeneous accelerator, demonstrates efficient deployment of Large Language Models on edge devices by achieving 1.91x higher throughput and 7.55x higher energy efficiency than an NVIDIA A100-SXM4-80G GPU for single-batch inference, while also outperforming the state-of-the-art FPGA accelerator FlightLLM by 10-24% in key metrics.

15 Oct 2025
Integrated photonic circuits are foundational for versatile applications, where high-performance traveling-wave optical resonators are critical. Conventional whispering-gallery mode microresonators (WGMRs) confine light in closed-loop waveguide paths, thus inevitably occupy large footprints. Here, we report an ultracompact high loaded Q silicon photonic WGMR in an open curved path instead. By leveraging spatial mode multiplexing, low-loss mode converter-based photonic routers enable reentrant photon recycling in a single non-closed waveguide. The fabricated device achieves a measured loaded Q-factor of 1.78*10^5 at 1554.3 nm with a 1.05 nm free spectral range in a ultracompact footprint of 0.00137 mm^2-6*smaller than standard WGMRs while delivering 100*higher Q-factor than photonic crystal counterparts. This work pioneers dense integration of high-performance WGMR arrays through open-path mode recirculation.

08 Sep 2025


ToxicSQL introduces a framework for investigating and exploiting SQL injection vulnerabilities in LLM-based Text-to-SQL models through backdoor attacks. The work demonstrates that these models can be trained with low poisoning rates to generate malicious, executable SQL queries while retaining normal performance on benign inputs, thereby exposing critical security flaws in database interaction systems.
There are no more papers matching your filters at the moment.
