
11 Sep 2024


Researchers from Hong Kong University of Science and Technology, University of Southampton, Trine University, and Southwest Jiaotong University developed a breast cancer image classification method that integrates an attention-augmented DenseNet with a multi-level transfer learning strategy. The approach achieved patient-level accuracy of 84.3% and image-level accuracy of 84.0% on the BreakHis dataset, while converging faster than baseline models.
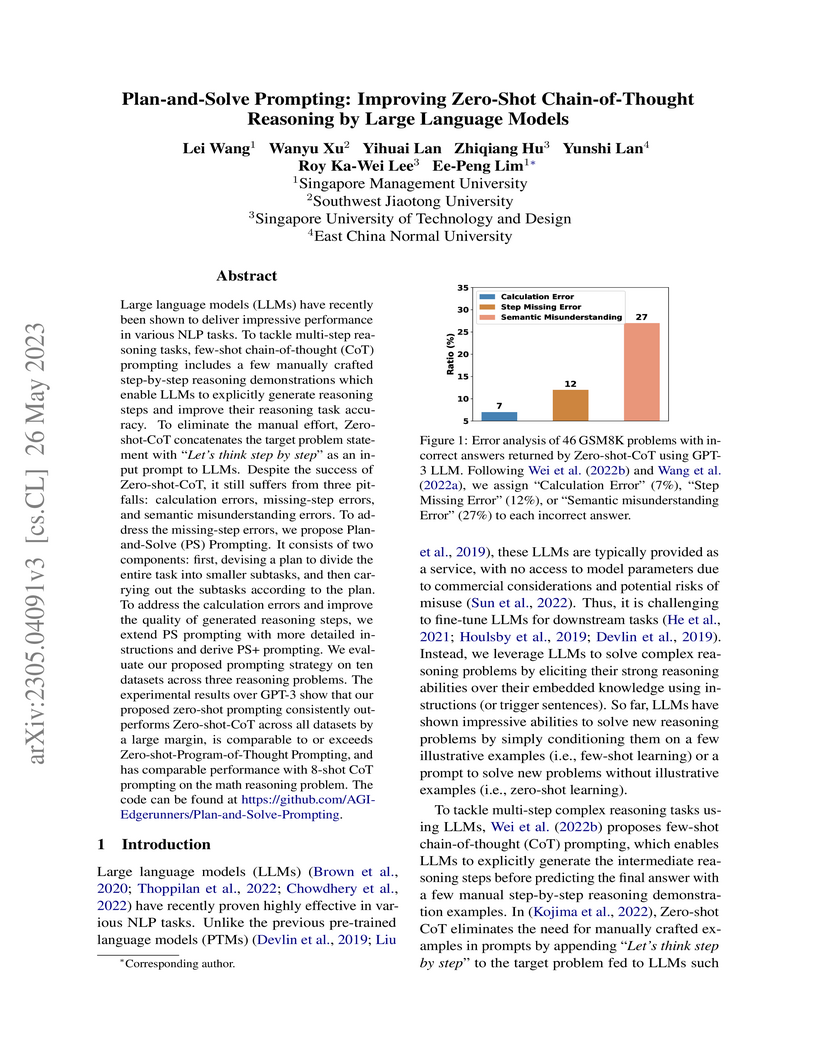
26 May 2023

Plan-and-Solve (PS) Prompting, developed by researchers at Singapore Management University and collaborators, enhances zero-shot Chain-of-Thought reasoning in Large Language Models by guiding them through a two-phase process of planning and execution. This method reduces calculation and missing-step errors, achieving accuracy comparable to few-shot methods on arithmetic reasoning tasks and outperforming Zero-shot CoT across multiple domains.

27 Jun 2025

This survey paper provides a comprehensive review of Continual Reinforcement Learning (CRL), introducing a novel taxonomy that categorizes methods based on whether they primarily store and transfer knowledge related to policies, experiences, environment dynamics, or reward signals. It identifies the unique challenges of CRL, such as the stability-plasticity-scalability dilemma, and outlines future research directions and applications across various domains.

19 Jun 2024
Wuhan UniversitySichuan UniversityThe Chinese University of Hong Kong, Shenzhen Columbia UniversityJiangxi Normal University
Columbia UniversityJiangxi Normal University University of Florida
University of Florida Stony Brook UniversityThe University of ManchesterYunnan UniversitySouthwest Jiaotong UniversityStevens Institute of TechnologyThe Fin AINanjing Audit University
Stony Brook UniversityThe University of ManchesterYunnan UniversitySouthwest Jiaotong UniversityStevens Institute of TechnologyThe Fin AINanjing Audit University
Columbia UniversityJiangxi Normal UniversityUniversity of FloridaStony Brook UniversityThe University of ManchesterYunnan UniversitySouthwest Jiaotong UniversityStevens Institute of TechnologyThe Fin AINanjing Audit UniversityFinBen introduces the first comprehensive open-source evaluation benchmark for large language models in finance, integrating 36 datasets across 24 tasks and seven critical financial aspects. Its extensive evaluation of 15 LLMs reveals strong performance in basic NLP but significant deficiencies in complex reasoning, quantitative forecasting, and robust decision-making, while showcasing advanced models' capabilities in areas like stock trading.

08 May 2021

CLIP4Clip transfers knowledge from the pre-trained CLIP model to achieve new state-of-the-art results in end-to-end video clip retrieval across five benchmark datasets. The work provides empirical insights into adapting image-language models to video, demonstrating the effectiveness of post-pretraining on video-text data and the importance of temporal modeling.

23 May 2025
Researchers from Ocean University of China and University at Buffalo introduce Forensics Adapter, a lightweight framework adapting CLIP for generalizable face forgery detection by specifically learning blending boundary artifacts. The method achieves an average AUC improvement of approximately 7% over state-of-the-art baselines and a further 1.3% with its multimodal extension, Forensics Adapter++, while being computationally efficient with few trainable parameters.

29 Sep 2025
Leveraging pretrained Vision-Language Models (VLMs) to map language instruction and visual observations to raw low-level actions, Vision-Language-Action models (VLAs) hold great promise for achieving general-purpose robotic systems. Despite their advancements, existing VLAs tend to spuriously correlate task-irrelevant visual features with actions, limiting their generalization capacity beyond the training data. To tackle this challenge, we propose Intrinsic Spatial Reasoning (InSpire), a simple yet effective approach that mitigates the adverse effects of spurious correlations by boosting the spatial reasoning ability of VLAs. Specifically, InSpire redirects the VLA's attention to task-relevant factors by prepending the question "In which direction is the [object] relative to the robot?" to the language instruction and aligning the answer "right/left/up/down/front/back/grasped" and predicted actions with ground-truth. Notably, InSpire can be used as a plugin to enhance existing autoregressive VLAs, requiring no extra training data or interaction with other large models. Extensive experimental results in both simulation and real-world environments demonstrate the effectiveness and flexibility of our approach.

04 Jun 2025


Researchers from Eastern Institute of Technology, Tencent, and collaborators develop SkipGPT, a dynamic layer pruning framework that introduces token-aware global routing and decoupled pruning policies for MLP versus self-attention modules, achieving over 40% parameter reduction while maintaining or exceeding original model performance through a two-stage training paradigm that first tunes lightweight routers (0.01% parameters) then applies LoRA fine-tuning, with SkipGPT-RT retaining over 90% performance on LLaMA2-7B/13B at 25% pruning and over 95% on LLaMA3.1-8B while outperforming static methods like ShortGPT and dynamic approaches like MoD-D across commonsense reasoning benchmarks, revealing through routing behavior analysis that attention modules exhibit higher redundancy than MLPs and that computational needs shift contextually with later tokens requiring more attention but less MLP processing, challenging the fixed 1:1 attention-MLP architecture design while demonstrating that joint training of routers with pre-trained parameters causes instability compared to their stable disentangled optimization approach.

13 Oct 2025


Scientific diagrams are vital tools for communicating structured knowledge across disciplines. However, they are often published as static raster images, losing symbolic semantics and limiting reuse. While Multimodal Large Language Models (MLLMs) offer a pathway to bridging vision and structure, existing methods lack semantic control and structural interpretability, especially on complex diagrams. We propose Draw with Thought (DwT), a training-free framework that guides MLLMs to reconstruct diagrams into editable mxGraph XML code through cognitively-grounded Chain-of-Thought reasoning. DwT enables interpretable and controllable outputs without model fine-tuning by dividing the task into two stages: Coarse-to-Fine Planning, which handles perceptual structuring and semantic specification, and Structure-Aware Code Generation, enhanced by format-guided refinement. To support evaluation, we release Plot2XML, a benchmark of 247 real-world scientific diagrams with gold-standard XML annotations. Extensive experiments across eight MLLMs show that our approach yields high-fidelity, semantically aligned, and structurally valid reconstructions, with human evaluations confirming strong alignment in both accuracy and visual aesthetics, offering a scalable solution for converting static visuals into executable representations and advancing machine understanding of scientific graphics.

08 Jun 2023

The PIXIU framework offers an open-source solution for financial language modeling by releasing a financial instruction tuning dataset (FIT), a fine-tuned financial LLM (FinMA), and a comprehensive evaluation benchmark (FLARE). FinMA, built on LLaMA, generally outperforms other LLMs on financial NLP tasks but shows limitations in quantitative reasoning and financial prediction.

16 Jun 2024

As cities continue to burgeon, Urban Computing emerges as a pivotal
discipline for sustainable development by harnessing the power of cross-domain
data fusion from diverse sources (e.g., geographical, traffic, social media,
and environmental data) and modalities (e.g., spatio-temporal, visual, and
textual modalities). Recently, we are witnessing a rising trend that utilizes
various deep-learning methods to facilitate cross-domain data fusion in smart
cities. To this end, we propose the first survey that systematically reviews
the latest advancements in deep learning-based data fusion methods tailored for
urban computing. Specifically, we first delve into data perspective to
comprehend the role of each modality and data source. Secondly, we classify the
methodology into four primary categories: feature-based, alignment-based,
contrast-based, and generation-based fusion methods. Thirdly, we further
categorize multi-modal urban applications into seven types: urban planning,
transportation, economy, public safety, society, environment, and energy.
Compared with previous surveys, we focus more on the synergy of deep learning
methods with urban computing applications. Furthermore, we shed light on the
interplay between Large Language Models (LLMs) and urban computing, postulating
future research directions that could revolutionize the field. We firmly
believe that the taxonomy, progress, and prospects delineated in our survey
stand poised to significantly enrich the research community. The summary of the
comprehensive and up-to-date paper list can be found at
https://github.com/yoshall/Awesome-Multimodal-Urban-Computing.

10 Mar 2025



Researchers developed a method for controllable 3D outdoor scene generation using scene graphs as intuitive input. The approach leverages a multi-stage diffusion model conditioned by a novel sparse-to-dense architecture, achieving superior control over object quantities and road types (MAE 0.63, Jaccard Index 0.93) while maintaining high scene quality and diversity.

13 Oct 2025
3D Gaussian Splatting has recently emerged as an efficient solution for high-quality and real-time novel view synthesis. However, its capability for accurate surface reconstruction remains underexplored. Due to the discrete and unstructured nature of Gaussians, supervision based solely on image rendering loss often leads to inaccurate geometry and inconsistent multi-view alignment. In this work, we propose a novel method that enhances the geometric representation of 3D Gaussians through view alignment (VA). Specifically, we incorporate edge-aware image cues into the rendering loss to improve surface boundary delineation. To enforce geometric consistency across views, we introduce a visibility-aware photometric alignment loss that models occlusions and encourages accurate spatial relationships among Gaussians. To further mitigate ambiguities caused by lighting variations, we incorporate normal-based constraints to refine the spatial orientation of Gaussians and improve local surface estimation. Additionally, we leverage deep image feature embeddings to enforce cross-view consistency, enhancing the robustness of the learned geometry under varying viewpoints and illumination. Extensive experiments on standard benchmarks demonstrate that our method achieves state-of-the-art performance in both surface reconstruction and novel view synthesis. The source code is available at this https URL.

15 Oct 2025
 Arizona State UniversitySouthwest Jiaotong UniversityFriedrich-Alexander-Universit
is at the end of a word, it signifies the sound of the letter 'e' in 'get', or the 'ea' in 'bread'. The diacritic over 'a' is for the vowel 'a' in 'father', and '¨u' is the 'ue' in 'blue'. Thus, the full word 'Universit
is at the end of a word, it signifies the sound of the letter 'e' in 'get', or the 'ea' in 'bread'. The diacritic over 'a' is for the vowel 'a' in 'father', and '¨u' is the 'ue' in 'blue'. Thus, the full word 'Universit
Arizona State UniversitySouthwest Jiaotong UniversityFriedrich-Alexander-Universit
is at the end of a word, it signifies the sound of the letter 'e' in 'get', or the 'ea' in 'bread'. The diacritic over 'a' is for the vowel 'a' in 'father', and '¨u' is the 'ue' in 'blue'. Thus, the full word 'Universit
is at the end of a word, it signifies the sound of the letter 'e' in 'get', or the 'ea' in 'bread'. The diacritic over 'a' is for the vowel 'a' in 'father', and '¨u' is the 'ue' in 'blue'. Thus, the full word 'UniversitSELF-AUGMENTED VISUAL CONTRASTIVE DECODING (SAVCD) introduces a training-free strategy for Large Vision-Language Models to mitigate hallucinations by employing a query-dependent visual augmentation selection and an entropy-aware adaptive plausibility constraint. The method achieves average performance gains from 6.69% to 18.78% across multiple LVLMs and benchmarks by enhancing factual consistency and relevance.

03 Dec 2024
A comprehensive review by researchers from TikTok and several universities surveys the advancements and challenges of MultiModal Large Language Models (MM-LLMs) for understanding long videos. The work systematically traces model evolution, highlights the necessity for specialized architectural adaptations and training strategies, and quantitatively compares performance across various video benchmarks.

13 Aug 2025
Large Multimodal Models (LMMs) has demonstrated capabilities across various domains, but comprehensive benchmarks for agricultural remote sensing (RS) remain scarce. Existing benchmarks designed for agricultural RS scenarios exhibit notable limitations, primarily in terms of insufficient scene diversity in the dataset and oversimplified task design. To bridge this gap, we introduce AgroMind, a comprehensive agricultural remote sensing benchmark covering four task dimensions: spatial perception, object understanding, scene understanding, and scene reasoning, with a total of 13 task types, ranging from crop identification and health monitoring to environmental analysis. We curate a high-quality evaluation set by integrating eight public datasets and one private farmland plot dataset, containing 27,247 QA pairs and 19,615 images. The pipeline begins with multi-source data pre-processing, including collection, format standardization, and annotation refinement. We then generate a diverse set of agriculturally relevant questions through the systematic definition of tasks. Finally, we employ LMMs for inference, generating responses, and performing detailed examinations. We evaluated 20 open-source LMMs and 4 closed-source models on AgroMind. Experiments reveal significant performance gaps, particularly in spatial reasoning and fine-grained recognition, it is notable that human performance lags behind several leading LMMs. By establishing a standardized evaluation framework for agricultural RS, AgroMind reveals the limitations of LMMs in domain knowledge and highlights critical challenges for future work. Data and code can be accessed at this https URL.

09 Oct 2023

Researchers introduced LLM-Adapters, a comprehensive framework and empirical study of parameter-efficient fine-tuning methods for large language models. The work demonstrates that smaller LLMs, when fine-tuned with optimized adapter configurations and high-quality, in-domain data, can achieve performance comparable to or surpassing much larger models on specific downstream tasks like commonsense reasoning.

14 Mar 2025
Prompt tuning (PT) has long been recognized as an effective and efficient
paradigm for transferring large pre-trained vision-language models (VLMs) to
downstream tasks by learning a tiny set of context vectors. Nevertheless, in
this work, we reveal that freezing the parameters of VLMs during learning the
context vectors neither facilitates the transferability of pre-trained
knowledge nor improves the memory and time efficiency significantly. Upon
further investigation, we find that reducing both the length and width of the
feature-gradient propagation flows of the full fine-tuning (FT) baseline is key
to achieving effective and efficient knowledge transfer. Motivated by this, we
propose Skip Tuning, a novel paradigm for adapting VLMs to downstream tasks.
Unlike existing PT or adapter-based methods, Skip Tuning applies Layer-wise
Skipping (LSkip) and Class-wise Skipping (CSkip) upon the FT baseline without
introducing extra context vectors or adapter modules. Extensive experiments
across a wide spectrum of benchmarks demonstrate the superior effectiveness and
efficiency of our Skip Tuning over both PT and adapter-based methods. Code:
this https URL

18 Nov 2025


As Audio Large Language Models (ALLMs) emerge as powerful tools for speech processing, their safety implications demand urgent attention. While considerable research has explored textual and vision safety, audio's distinct characteristics present significant challenges. This paper first investigates: Is ALLM vulnerable to backdoor attacks exploiting acoustic triggers? In response to this issue, we introduce Hidden in the Noise (HIN), a novel backdoor attack framework designed to exploit subtle, audio-specific features. HIN applies acoustic modifications to raw audio waveforms, such as alterations to temporal dynamics and strategic injection of spectrally tailored noise. These changes introduce consistent patterns that an ALLM's acoustic feature encoder captures, embedding robust triggers within the audio stream. To evaluate ALLM robustness against audio-feature-based triggers, we develop the AudioSafe benchmark, assessing nine distinct risk types. Extensive experiments on AudioSafe and three established safety datasets reveal critical vulnerabilities in existing ALLMs: (I) audio features like environment noise and speech rate variations achieve over 90% average attack success rate. (II) ALLMs exhibit significant sensitivity differences across acoustic features, particularly showing minimal response to volume as a trigger, and (III) poisoned sample inclusion causes only marginal loss curve fluctuations, highlighting the attack's stealth.

23 Aug 2025

Large Language Models (LLMs) have shown promise for financial applications, yet their suitability for this high-stakes domain remains largely unproven due to inadequacies in existing benchmarks. Existing benchmarks solely rely on score-level evaluation, summarizing performance with a single score that obscures the nuanced understanding of what models truly know and their precise limitations. They also rely on datasets that cover only a narrow subset of financial concepts, while overlooking other essentials for real-world applications. To address these gaps, we introduce FinCDM, the first cognitive diagnosis evaluation framework tailored for financial LLMs, enabling the evaluation of LLMs at the knowledge-skill level, identifying what financial skills and knowledge they have or lack based on their response patterns across skill-tagged tasks, rather than a single aggregated number. We construct CPA-KQA, the first cognitively informed financial evaluation dataset derived from the Certified Public Accountant (CPA) examination, with comprehensive coverage of real-world accounting and financial skills. It is rigorously annotated by domain experts, who author, validate, and annotate questions with high inter-annotator agreement and fine-grained knowledge labels. Our extensive experiments on 30 proprietary, open-source, and domain-specific LLMs show that FinCDM reveals hidden knowledge gaps, identifies under-tested areas such as tax and regulatory reasoning overlooked by traditional benchmarks, and uncovers behavioral clusters among models. FinCDM introduces a new paradigm for financial LLM evaluation by enabling interpretable, skill-aware diagnosis that supports more trustworthy and targeted model development, and all datasets and evaluation scripts will be publicly released to support further research.
There are no more papers matching your filters at the moment.
