
25 May 2017
SRGAN, developed by researchers at Twitter, introduces a generative adversarial network architecture for single-image super-resolution that produces photo-realistic images with unprecedented perceptual quality at 4x upscaling factors. It achieves superior human-rated Mean Opinion Scores by optimizing a novel perceptual loss that combines VGG-feature-based content loss and an adversarial loss.

22 Sep 2021

We present Graph Neural Diffusion (GRAND) that approaches deep learning on graphs as a continuous diffusion process and treats Graph Neural Networks (GNNs) as discretisations of an underlying PDE. In our model, the layer structure and topology correspond to the discretisation choices of temporal and spatial operators. Our approach allows a principled development of a broad new class of GNNs that are able to address the common plights of graph learning models such as depth, oversmoothing, and bottlenecks. Key to the success of our models are stability with respect to perturbations in the data and this is addressed for both implicit and explicit discretisation schemes. We develop linear and nonlinear versions of GRAND, which achieve competitive results on many standard graph benchmarks.

24 Jun 2022


This paper introduces Graph-Coupled Oscillator Networks (GraphCON), a deep learning framework for graphs that models message passing as the dynamics of coupled oscillators, addressing the oversmoothing and gradient stability challenges in deep Graph Neural Networks. The framework provides theoretical proofs for mitigating both issues and demonstrates competitive to state-of-the-art performance across diverse graph learning tasks, significantly improving over baselines on heterophilic datasets and achieving 99.6% micro-F1 on PPI.

06 Sep 2023
Researchers at the University of Cambridge, in collaboration with Charm Therapeutics, Cash App, and the University of Oxford, demonstrate that simple graph convolutions can enhance high-frequency components and exhibit an asymptotic behavior called over-sharpening, challenging the long-held belief that Graph Neural Networks are inherently low-pass filters. They establish that GNNs can be viewed as gradient flows of a parametric energy functional, and that symmetric weight matrices combined with residual connections are crucial for enabling these high-frequency-dominant dynamics.

06 Oct 2022
People rely on news to know what is happening around the world and inform their daily lives. In today's world, when the proliferation of fake news is rampant, having a large-scale and high-quality source of authentic news articles with the published category information is valuable to learning authentic news' Natural Language syntax and semantics. As part of this work, we present a News Category Dataset that contains around 210k news headlines from the year 2012 to 2022 obtained from HuffPost, along with useful metadata to enable various NLP tasks. In this paper, we also produce some novel insights from the dataset and describe various existing and potential applications of our dataset.
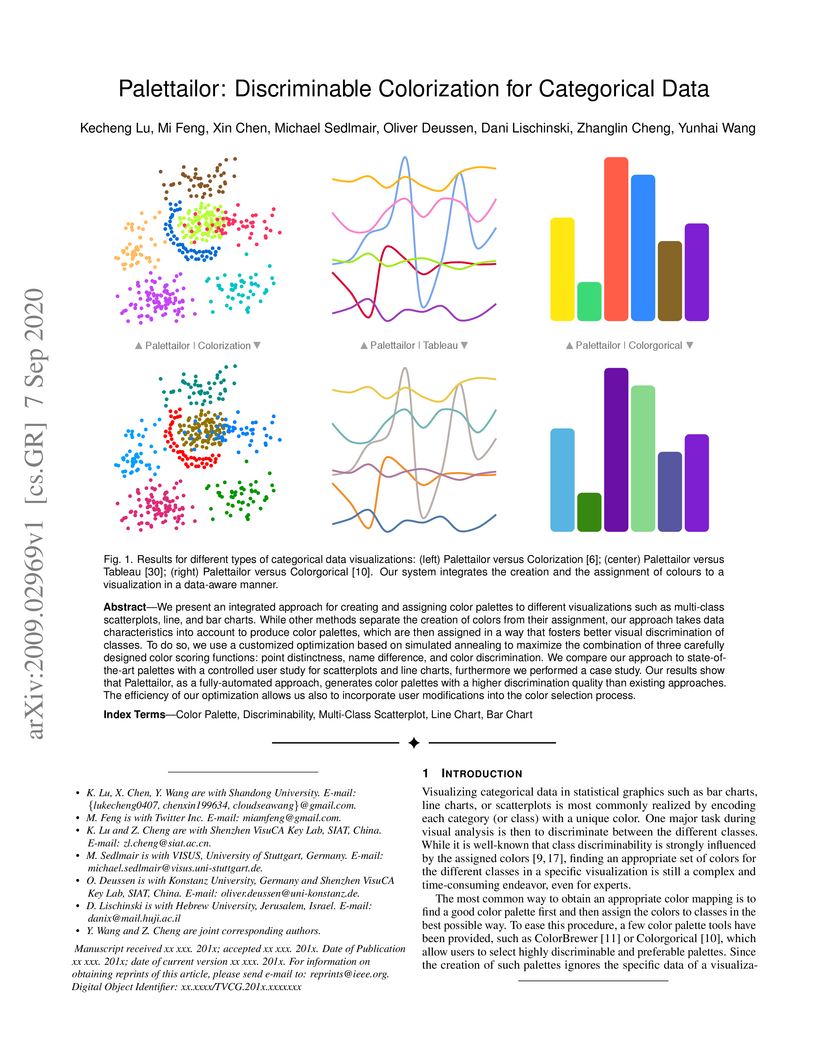
07 Sep 2020

We present an integrated approach for creating and assigning color palettes
to different visualizations such as multi-class scatterplots, line, and bar
charts. While other methods separate the creation of colors from their
assignment, our approach takes data characteristics into account to produce
color palettes, which are then assigned in a way that fosters better visual
discrimination of classes. To do so, we use a customized optimization based on
simulated annealing to maximize the combination of three carefully designed
color scoring functions: point distinctness, name difference, and color
discrimination. We compare our approach to state-ofthe-art palettes with a
controlled user study for scatterplots and line charts, furthermore we
performed a case study. Our results show that Palettailor, as a fully-automated
approach, generates color palettes with a higher discrimination quality than
existing approaches. The efficiency of our optimization allows us also to
incorporate user modifications into the color selection process.

14 Oct 2022
Named Entity Recognition and Disambiguation (NERD) systems are foundational for information retrieval, question answering, event detection, and other natural language processing (NLP) applications. We introduce TweetNERD, a dataset of 340K+ Tweets across 2010-2021, for benchmarking NERD systems on Tweets. This is the largest and most temporally diverse open sourced dataset benchmark for NERD on Tweets and can be used to facilitate research in this area. We describe evaluation setup with TweetNERD for three NERD tasks: Named Entity Recognition (NER), Entity Linking with True Spans (EL), and End to End Entity Linking (End2End); and provide performance of existing publicly available methods on specific TweetNERD splits. TweetNERD is available at: this https URL under Creative Commons Attribution 4.0 International (CC BY 4.0) license. Check out more details at this https URL.

25 Apr 2022

This paper presents "conditional delegation," a novel human-AI collaboration paradigm for content moderation, where humans specify conditions for AI autonomy. It demonstrates that this approach improves model precision on in-distribution data and enhances efficiency in rule creation, especially with AI explanations.

16 Jun 2022
With the evolution of cloud computing, there has been a rise of large
enterprises extending their infrastructure and workloads into the public cloud.
This paper proposes a full-fledged framework for a Belief-Desire-Intention
(BDI) multi-agent-based cloud marketplace system for cloud resources. Each
party in the cloud marketplace system supports a BDI agent for autonomous
decision making and negotiation to facilitate automated buying and selling of
resources. Additionally, multiple BDI agents from an enterprise competing for
the same cloud resource can consult with each other via Master Negotiation
Clearing House to minimize the overall cost function for the enterprise while
negotiating for a cloud resource. The cloud marketplace system is further
augmented with assignments of behavior norm and reputation index to the agents
to facilitate trust among them.

08 Feb 2015
We show a tight lower bound of on the number of
transmissions required to compute the parity of input bits with constant
error in a noisy communication network of randomly placed sensors, each
having one input bit and communicating with others using local transmissions
with power near the connectivity threshold. This result settles the lower bound
question left open by Ying, Srikant and Dullerud (WiOpt 06), who showed how the
sum of all the bits can be computed using transmissions.
The same lower bound has been shown to hold for a host of other functions
including majority by Dutta and Radhakrishnan (FOCS 2008).
Most works on lower bounds for communication networks considered mostly the
full broadcast model without using the fact that the communication in real
networks is local, determined by the power of the transmitters. In fact, in
full broadcast networks computing parity needs transmissions. To
obtain our lower bound we employ techniques developed by Goyal, Kindler and
Saks (FOCS 05), who showed lower bounds in the full broadcast model by reducing
the problem to a model of noisy decision trees. However, in order to capture
the limited range of transmissions in real sensor networks, we adapt their
definition of noisy decision trees and allow each node of the tree access to
only a limited part of the input. Our lower bound is obtained by exploiting
special properties of parity computations in such noisy decision trees.

20 Nov 2022
Presto is an open-source distributed SQL query engine for OLAP, aiming for "SQL on everything". Since open-sourced in 2013, Presto has been consistently gaining popularity in large-scale data analytics and attracting adoption from a wide range of enterprises. From the development and operation of Presto, we witnessed a significant amount of CPU consumption on parsing column-oriented data files in Presto worker nodes. This blocks some companies, including Meta, from increasing analytical data volumes.
In this paper, we present a metadata caching layer, built on top of the Alluxio SDK cache and incorporated in each Presto worker node, to cache the intermediate results in file parsing. The metadata cache provides two caching methods: caching the decompressed metadata bytes from raw data files and caching the deserialized metadata objects. Our evaluation of the TPC-DS benchmark on Presto demonstrates that when the cache is warm, the first method can reduce the query's CPU consumption by 10%-20%, whereas the second method can minimize the CPU usage by 20%-40%.

31 Aug 2010

In this paper, we analyze the efficiency of Monte Carlo methods for
incremental computation of PageRank, personalized PageRank, and similar random
walk based methods (with focus on SALSA), on large-scale dynamically evolving
social networks. We assume that the graph of friendships is stored in
distributed shared memory, as is the case for large social networks such as
Twitter.
For global PageRank, we assume that the social network has nodes, and
adversarially chosen edges arrive in a random order. We show that with a reset
probability of , the total work needed to maintain an accurate
estimate (using the Monte Carlo method) of the PageRank of every node at all
times is . This is significantly better than
all known bounds for incremental PageRank. For instance, if we naively
recompute the PageRanks as each edge arrives, the simple power iteration method
needs total time and the Monte Carlo
method needs total time; both are prohibitively expensive.
Furthermore, we also show that we can handle deletions equally efficiently.
We then study the computation of the top personalized PageRanks starting
from a seed node, assuming that personalized PageRanks follow a power-law with
exponent \alpha < 1. We show that if we store R>q\ln n random walks
starting from every node for large enough constant (using the approach
outlined for global PageRank), then the expected number of calls made to the
distributed social network database is .
We also present experimental results from the social networking site,
Twitter, verifying our assumptions and analyses. The overall result is that
this algorithm is fast enough for real-time queries over a dynamic social
network.

10 Apr 2017
Convolutional neural networks have enabled accurate image super-resolution in real-time. However, recent attempts to benefit from temporal correlations in video super-resolution have been limited to naive or inefficient architectures. In this paper, we introduce spatio-temporal sub-pixel convolution networks that effectively exploit temporal redundancies and improve reconstruction accuracy while maintaining real-time speed. Specifically, we discuss the use of early fusion, slow fusion and 3D convolutions for the joint processing of multiple consecutive video frames. We also propose a novel joint motion compensation and video super-resolution algorithm that is orders of magnitude more efficient than competing methods, relying on a fast multi-resolution spatial transformer module that is end-to-end trainable. These contributions provide both higher accuracy and temporally more consistent videos, which we confirm qualitatively and quantitatively. Relative to single-frame models, spatio-temporal networks can either reduce the computational cost by 30% whilst maintaining the same quality or provide a 0.2dB gain for a similar computational cost. Results on publicly available datasets demonstrate that the proposed algorithms surpass current state-of-the-art performance in both accuracy and efficiency.

03 Feb 2022

The harmful impacts of algorithmic decision systems have recently come into focus, with many examples of systems such as machine learning (ML) models amplifying existing societal biases. Most metrics attempting to quantify disparities resulting from ML algorithms focus on differences between groups, dividing users based on demographic identities and comparing model performance or overall outcomes between these groups. However, in industry settings, such information is often not available, and inferring these characteristics carries its own risks and biases. Moreover, typical metrics that focus on a single classifier's output ignore the complex network of systems that produce outcomes in real-world settings. In this paper, we evaluate a set of metrics originating from economics, distributional inequality metrics, and their ability to measure disparities in content exposure in a production recommendation system, the Twitter algorithmic timeline. We define desirable criteria for metrics to be used in an operational setting, specifically by ML practitioners. We characterize different types of engagement with content on Twitter using these metrics, and use these results to evaluate the metrics with respect to the desired criteria. We show that we can use these metrics to identify content suggestion algorithms that contribute more strongly to skewed outcomes between users. Overall, we conclude that these metrics can be useful tools for understanding disparate outcomes in online social networks.

28 Nov 2014

Low latency and high availability of an app or a web service are key, amongst other factors, to the overall user experience (which in turn directly impacts the bottomline). Exogenic and/or endogenic factors often give rise to breakouts in cloud data which makes maintaining high availability and delivering high performance very challenging.
Although there exists a large body of prior research in breakout detection, existing techniques are not suitable for detecting breakouts in cloud data owing to being not robust in the presence of anomalies.
To this end, we developed a novel statistical technique to automatically detect breakouts in cloud data. In particular, the technique employs Energy Statistics to detect breakouts in both application as well as system metrics. Further, the technique uses robust statistical metrics, viz., median, and estimates the statistical significance of a breakout through a permutation test.
To the best of our knowledge, this is the first work which addresses breakout detection in the presence of anomalies.
We demonstrate the efficacy of the proposed technique using production data and report Precision, Recall and F-measure measure. The proposed technique is 3.5 times faster than a state-of-the-art technique for breakout detection and is being currently used on a daily basis at Twitter.

24 Apr 2017
Performance and high availability have become increasingly important drivers,
amongst other drivers, for user retention in the context of web services such
as social networks, and web search. Exogenic and/or endogenic factors often
give rise to anomalies, making it very challenging to maintain high
availability, while also delivering high performance. Given that
service-oriented architectures (SOA) typically have a large number of services,
with each service having a large set of metrics, automatic detection of
anomalies is non-trivial.
Although there exists a large body of prior research in anomaly detection,
existing techniques are not applicable in the context of social network data,
owing to the inherent seasonal and trend components in the time series data.
To this end, we developed two novel statistical techniques for automatically
detecting anomalies in cloud infrastructure data. Specifically, the techniques
employ statistical learning to detect anomalies in both application, and system
metrics. Seasonal decomposition is employed to filter the trend and seasonal
components of the time series, followed by the use of robust statistical
metrics -- median and median absolute deviation (MAD) -- to accurately detect
anomalies, even in the presence of seasonal spikes.
We demonstrate the efficacy of the proposed techniques from three different
perspectives, viz., capacity planning, user behavior, and supervised learning.
In particular, we used production data for evaluation, and we report Precision,
Recall, and F-measure in each case.

08 Aug 2020
Named Entity Recognition (NER) is often the first step towards automated
Knowledge Base (KB) generation from raw text. In this work, we assess the bias
in various Named Entity Recognition (NER) systems for English across different
demographic groups with synthetically generated corpora. Our analysis reveals
that models perform better at identifying names from specific demographic
groups across two datasets. We also identify that debiased embeddings do not
help in resolving this issue. Finally, we observe that character-based
contextualized word representation models such as ELMo results in the least
bias across demographics. Our work can shed light on potential biases in
automated KB generation due to systematic exclusion of named entities belonging
to certain demographics.

18 Oct 2021
We propose a novel class of graph neural networks based on the discretised Beltrami flow, a non-Euclidean diffusion PDE. In our model, node features are supplemented with positional encodings derived from the graph topology and jointly evolved by the Beltrami flow, producing simultaneously continuous feature learning and topology evolution. The resulting model generalises many popular graph neural networks and achieves state-of-the-art results on several benchmarks.

01 Dec 2021
The proliferation of harmful and offensive content is a problem that many online platforms face today. One of the most common approaches for moderating offensive content online is via the identification and removal after it has been posted, increasingly assisted by machine learning algorithms. More recently, platforms have begun employing moderation approaches which seek to intervene prior to offensive content being posted. In this paper, we conduct an online randomized controlled experiment on Twitter to evaluate a new intervention that aims to encourage participants to reconsider their offensive content and, ultimately, seeks to reduce the amount of offensive content on the platform. The intervention prompts users who are about to post harmful content with an opportunity to pause and reconsider their Tweet. We find that users in our treatment prompted with this intervention posted 6% fewer offensive Tweets than non-prompted users in our control. This decrease in the creation of offensive content can be attributed not just to the deletion and revision of prompted Tweets -- we also observed a decrease in both the number of offensive Tweets that prompted users create in the future and the number of offensive replies to prompted Tweets. We conclude that interventions allowing users to reconsider their comments can be an effective mechanism for reducing offensive content online.

22 Mar 2022
Implementing big data storage at scale is a complex and arduous task that
requires an advanced infrastructure. With the rise of public cloud computing,
various big data management services can be readily leveraged. As a critical
part of Twitter's "Project Partly Cloudy", the cold storage data and analytics
systems are being moved to the public cloud. This paper showcases our approach
in designing a scalable big data storage and analytics management framework
using BigQuery in Google Cloud Platform while ensuring security, privacy, and
data protection. The paper also discusses the limitations on the public cloud
resources and how they can be effectively overcome when designing a big data
storage and analytics solution at scale. Although the paper discusses the
framework implementation in Google Cloud Platform, it can easily be applied to
all major cloud providers.
There are no more papers matching your filters at the moment.
