
12 Jun 2023
 ETH Zurich
ETH Zurich KAIST
KAIST University of WashingtonRensselaer Polytechnic Institute
University of WashingtonRensselaer Polytechnic Institute Google DeepMind
Google DeepMind University of Amsterdam
University of Amsterdam University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of CambridgeHeidelberg University
University of CambridgeHeidelberg University University of WaterlooFacebook
University of WaterlooFacebook Carnegie Mellon University
Carnegie Mellon University University of Southern California
University of Southern California Google
Google New York UniversityUniversity of Stuttgart
New York UniversityUniversity of Stuttgart UC Berkeley
UC Berkeley National University of Singapore
National University of Singapore University College London
University College London University of OxfordLMU Munich
University of OxfordLMU Munich Shanghai Jiao Tong University
Shanghai Jiao Tong University University of California, Irvine
University of California, Irvine Tsinghua University
Tsinghua University Stanford University
Stanford University University of Michigan
University of Michigan University of Copenhagen
University of Copenhagen The Chinese University of Hong KongUniversity of Melbourne
The Chinese University of Hong KongUniversity of Melbourne MetaUniversity of Edinburgh
MetaUniversity of Edinburgh OpenAI
OpenAI The University of Texas at Austin
The University of Texas at Austin Cornell University
Cornell University University of California, San DiegoYonsei University
University of California, San DiegoYonsei University McGill University
McGill University Boston UniversityUniversity of Bamberg
Boston UniversityUniversity of Bamberg Nanyang Technological University
Nanyang Technological University Microsoft
Microsoft KU Leuven
KU Leuven Columbia UniversityUC Santa Barbara
Columbia UniversityUC Santa Barbara Allen Institute for AIGerman Research Center for Artificial Intelligence (DFKI)
Allen Institute for AIGerman Research Center for Artificial Intelligence (DFKI) University of Pennsylvania
University of Pennsylvania Johns Hopkins University
Johns Hopkins University Arizona State University
Arizona State University University of Maryland
University of Maryland University of TokyoUniversity of North Carolina at Chapel HillHebrew University of JerusalemAmazonTilburg UniversityUniversity of Massachusetts AmherstUniversity of RochesterUniversity of Duisburg-EssenSapienza University of RomeUniversity of Sheffield
University of TokyoUniversity of North Carolina at Chapel HillHebrew University of JerusalemAmazonTilburg UniversityUniversity of Massachusetts AmherstUniversity of RochesterUniversity of Duisburg-EssenSapienza University of RomeUniversity of Sheffield Princeton University
Princeton University HKUSTUniversity of TübingenTU BerlinSaarland UniversityTechnical University of DarmstadtUniversity of HaifaUniversity of TrentoUniversity of MontrealBilkent UniversityUniversity of Cape TownBar Ilan UniversityIBMUniversity of Mannheim
HKUSTUniversity of TübingenTU BerlinSaarland UniversityTechnical University of DarmstadtUniversity of HaifaUniversity of TrentoUniversity of MontrealBilkent UniversityUniversity of Cape TownBar Ilan UniversityIBMUniversity of Mannheim ServiceNowPotsdam UniversityPolish-Japanese Academy of Information TechnologySalesforceASAPPAI21 LabsValencia Polytechnic UniversityUniversity of Trento, Italy
ServiceNowPotsdam UniversityPolish-Japanese Academy of Information TechnologySalesforceASAPPAI21 LabsValencia Polytechnic UniversityUniversity of Trento, Italy

A large-scale and diverse benchmark, BIG-bench, was introduced to rigorously evaluate the capabilities and limitations of large language models across 204 tasks. The evaluation revealed that even state-of-the-art models currently achieve aggregate scores below 20 (on a 0-100 normalized scale), indicating significantly lower performance compared to human experts.

07 Jul 2025
VLM2Vec-V2, developed by researchers from Salesforce Research and collaborating universities, introduces a unified multimodal embedding model capable of processing and aligning videos, images, and visual documents with text. The model achieves the highest overall score of 58.0 on the newly introduced MMEB-V2 benchmark, which expands evaluation to 78 tasks across these diverse visual modalities.

01 Sep 2025
Researchers introduce CVE-GENIE, an automated multi-agent framework leveraging Large Language Models (LLMs) to reproduce Common Vulnerabilities and Exposures (CVEs) and generate verifiable exploits. The framework successfully reproduced 428 out of 841 CVEs (51%) across diverse projects, languages, and vulnerability types, creating a substantial dataset for cybersecurity research.

20 Jun 2025


Researchers from UC Santa Cruz, Stanford, and UC Santa Barbara systematically investigate amplified visual hallucination in multimodal reasoning models, demonstrating that longer reasoning chains increase ungrounded content. They introduce RH-AUC and RH-Bench to quantify the trade-off between reasoning performance and perceptual fidelity across varying reasoning depths.

21 Nov 2025
This research introduces budget-aware strategies for tool-augmented large language model agents to improve efficiency and performance under resource constraints. The proposed methods, including a Budget Tracker and the BATS framework, enable agents to strategically utilize external tools and achieve higher accuracy with fewer resources compared to traditional approaches.

27 Apr 2025


Speculative Knowledge Distillation (SKD) introduces an interleaved sampling method for LLM compression, dynamically blending teacher-guided corrections with student-generated tokens. This approach consistently outperforms existing knowledge distillation techniques, achieving substantial gains across diverse tasks and data regimes while providing more stable training.

09 Oct 2024



This paper conducts a comprehensive survey of Role-Playing Language Agents (RPLAs) developed using Large Language Models, proposing a three-tiered taxonomy for personas, detailing their construction and evaluation methodologies, and identifying associated risks and market applications. It systematically organizes current research, providing a foundational understanding of the field's evolution and bridging theoretical insights with practical demands.

02 Aug 2024



A comprehensive survey systematically reviews and categorizes data selection methods for large language models, presenting a unified conceptual framework and taxonomy for understanding diverse approaches across various training stages. The work provides a structured overview of current practices, identifies challenges, and proposes future research directions, aiming to democratize knowledge in this critical area of LLM development.

08 Oct 2025
Various layer-skipping methods have been proposed to accelerate token generation in large language models (LLMs). However, limited attention has been paid to a fundamental question: How do computational demands vary across the generation of different tokens? In this work, we introduce FlexiDepth, a method that dynamically adjusts the number of Transformer layers used in text generation. By incorporating a plug-in router and adapter, FlexiDepth enables adaptive computation in LLMs without modifying their original parameters. Applied to Llama-3-8B, it skips 8 out of 32 layers while maintaining full benchmark performance. Our experiments reveal that computational demands in LLMs significantly vary based on token type. Specifically, generating repetitive tokens or fixed phrases requires fewer layers, whereas producing tokens involving computation or high uncertainty requires more layers. Despite the computational savings, FlexiDepth does not yet achieve wall-clock speedup due to varied skipping patterns and I/O overhead. To inspire future work and advance research on practical speedup, we open-sourced FlexiDepth and a dataset documenting its layer allocation patterns.

30 Aug 2025
Progent, developed by researchers including those from UC Berkeley, introduces a programmable privilege control framework for Large Language Model (LLM) agents, deterministically blocking malicious tool calls. The system achieves a 0% attack success rate across various benchmarks, including prompt injection and malicious tools, while preserving agent utility and incurring negligible runtime overhead.

02 Jul 2024

Researchers introduce VSP, a benchmark for evaluating Vision Language Models on visual spatial planning tasks. Experiments show that current state-of-the-art VLMs exhibit sub-optimal performance, with visual perception identified as a major bottleneck limiting their ability to comprehend spatial arrangements and devise multi-step action plans.

02 Apr 2025


Open-Qwen2VL presents a 2B-parameter multimodal LLM pre-trained using 220 A100-40G GPU hours, which outperforms Qwen2-VL-2B on several benchmarks. The project provides a fully open-source training pipeline, data filtering techniques, and pre-training data to promote reproducibility and accessibility.

13 Oct 2023
We study the problem of watermarking large language models (LLMs) generated
text -- one of the most promising approaches for addressing the safety
challenges of LLM usage. In this paper, we propose a rigorous theoretical
framework to quantify the effectiveness and robustness of LLM watermarks. We
propose a robust and high-quality watermark method, Unigram-Watermark, by
extending an existing approach with a simplified fixed grouping strategy. We
prove that our watermark method enjoys guaranteed generation quality,
correctness in watermark detection, and is robust against text editing and
paraphrasing. Experiments on three varying LLMs and two datasets verify that
our Unigram-Watermark achieves superior detection accuracy and comparable
generation quality in perplexity, thus promoting the responsible use of LLMs.
Code is available at https://github.com/XuandongZhao/Unigram-Watermark.

25 Aug 2025

TopoBench introduces an open-source, modular framework designed to standardize benchmarking for Topological Deep Learning (TDL) and accelerate research in the field. Empirical evaluations using the framework demonstrate that higher-order neural networks frequently outperform traditional Graph Neural Networks on tasks benefiting from complex multi-way interactions across diverse datasets.

27 Oct 2023



LeanDojo introduces an open-source toolkit, benchmark, and the ReProver, a retrieval-augmented language model, to advance automated theorem proving in Lean. ReProver achieved a 51.2% Pass@1 on the standard LeanDojo Benchmark and discovered 65 new formal proofs across MiniF2F and ProofNet, demonstrating improved generalization over non-retrieval methods and general-purpose LLMs.
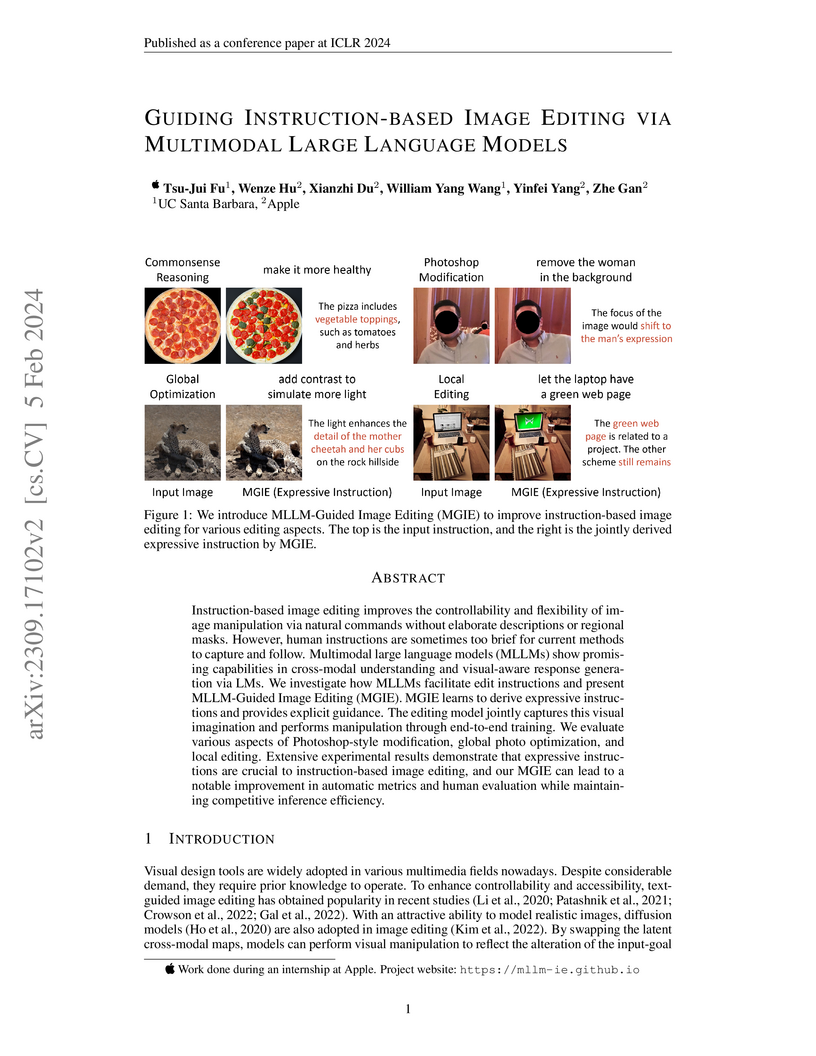
05 Feb 2024

MLLM-Guided Image Editing (MGIE) introduces a framework that uses a Multimodal Large Language Model to interpret ambiguous human instructions and generate explicit, visually-aware guidance for a diffusion model. This approach enables more accurate and versatile image editing across various tasks, outperforming existing instruction-based methods in both quantitative and human evaluations.

02 Apr 2025
Researchers from UCSB and MIT develop THINKPRUNE, a reinforcement learning framework that reduces the token length of large language models' chain-of-thought reasoning while maintaining performance, achieving a 65% reduction in generation length (from 10,355 to 3,574 tokens) on the DeepSeek-R1-Distill-Qwen-1.5B model through iterative length pruning and reward optimization.

15 Jun 2024

Researchers at Stanford University developed a statistical method, "distributional GPT quantification," to estimate the proportion of AI-modified content in large text corpora without classifying individual documents. Applying this method to peer reviews, they found that 7-17% of sentences in AI conference reviews were substantially AI-modified post-ChatGPT's release, a pattern not observed in Nature Portfolio journals.

10 Jun 2024
Researchers developed Input Clarification Ensembling (ICE), a framework that decomposes the total uncertainty of black-box Large Language Models into aleatoric (input ambiguity) and epistemic (model knowledge) components. This decomposition allows for identifying ambiguous inputs, significantly improving the recall of correct answers when users are prompted for clarification.

19 Mar 2022
Creating presentation materials requires complex multimodal reasoning skills to summarize key concepts and arrange them in a logical and visually pleasing manner. Can machines learn to emulate this laborious process? We present a novel task and approach for document-to-slide generation. Solving this involves document summarization, image and text retrieval, slide structure and layout prediction to arrange key elements in a form suitable for presentation. We propose a hierarchical sequence-to-sequence approach to tackle our task in an end-to-end manner. Our approach exploits the inherent structures within documents and slides and incorporates paraphrasing and layout prediction modules to generate slides. To help accelerate research in this domain, we release a dataset about 6K paired documents and slide decks used in our experiments. We show that our approach outperforms strong baselines and produces slides with rich content and aligned imagery.
There are no more papers matching your filters at the moment.
