
06 Sep 2024
The ContrastPool framework integrates domain-specific knowledge into Graph Neural Networks for classifying fMRI brain networks, achieving superior accuracy across three neurodegenerative diseases while providing interpretable disease-specific insights. It leverages a contrastive dual-attention mechanism and a contrast graph to address fMRI's low signal-to-noise ratio, node alignment, and limited data scale.

02 Aug 2025
 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of Oxford
University of Oxford Fudan University
Fudan University Shanghai Jiao Tong University
Shanghai Jiao Tong University the University of Tokyo
the University of Tokyo Tsinghua University
Tsinghua University City University of Hong KongThe University of Melbourne
City University of Hong KongThe University of Melbourne ByteDance
ByteDance RIKENGriffith University
RIKENGriffith University Nanyang Technological University
Nanyang Technological University University of Wisconsin-Madison
University of Wisconsin-Madison Purdue UniversityThe University of SydneyUniversity of Massachusetts Amherst
Purdue UniversityThe University of SydneyUniversity of Massachusetts Amherst Duke University
Duke University Virginia TechSingapore Management UniversitySea AI LabUniversity of Auckland
Virginia TechSingapore Management UniversitySea AI LabUniversity of Auckland HKUSTCISPA – Helmholtz Center for Information SecurityChinese University of Hong Kong, Shenzhen
HKUSTCISPA – Helmholtz Center for Information SecurityChinese University of Hong Kong, Shenzhen University of California, Santa Cruz
University of California, Santa CruzThis comprehensive survey systematically reviews current safety research across six major large AI model paradigms and autonomous agents, presenting a detailed taxonomy of 10 attack types and corresponding defense strategies. The review identifies a predominant focus on attack methodologies (60% of papers) over defenses and outlines key open challenges for advancing AI safety.

11 Jun 2024



Researchers from the National University of Singapore introduce Symbolic Chain-of-Thought (SymbCoT), an LLM-based framework that integrates symbolic expressions and logic rules directly into the reasoning process. This approach achieves state-of-the-art accuracy on logical reasoning datasets (e.g., 9.31% over CoT on GPT-4) and demonstrates 0% unfaithful reasoning by making LLMs perform intrinsic, verifiable symbolic deduction.

30 Sep 2025


This research introduces Multimodal Symbolic Logical Reasoning (MuSLR), a new task and benchmark, MuSLR-Bench, that requires vision-language models (VLMs) to perform formal logical deduction by integrating information from both visual and textual inputs. The proposed LogiCAM framework, developed by the National University of Singapore and collaborators, achieved a 14.13% average accuracy improvement on GPT-4.1, demonstrating enhanced capabilities in applying formal logic to complex multimodal scenarios.

30 Sep 2025
Transformers have achieved remarkable success across a wide range of applications, a feat often attributed to their scalability. Yet training them without skip (residual) connections remains notoriously difficult. While skips stabilize optimization, they also disrupt the hierarchical structure of representations, raising the long-standing question of whether transformers can be trained efficiently without them. In this work, we address this problem by analyzing the Jacobian of a skipless transformer block, showing why skips improve conditioning and revealing that their stabilization benefits can be recovered through a principled initialization strategy. Building on this insight, we introduce the first method that enables stable and efficient training of skipless transformers without altering the standard architecture. We validate our approach on Vision Transformers (ViTs) in both supervised and self-supervised settings, demonstrating that skipless ViTs trained with our initialization overcome the usual optimization barriers, learn richer hierarchical representations, and outperform strong baselines, that incorporate skip connections, on dense prediction benchmarks. These results show that skip connections are not a fundamental requirement for training ViTs and open new avenues for hierarchical representation learning in vision models.

13 Oct 2025

Researchers from Zhejiang University, Tencent Youtu Lab, Shanghai Jiao Tong University, University of Auckland, and National University of Singapore developed IVEBench, a benchmark suite designed to assess instruction-guided video editing (IVE) methods with a diverse dataset, extensive task coverage, and MLLM-integrated evaluation. The benchmark reveals current IVE models exhibit unsatisfactory per-frame quality, limited instruction adherence (scoring no more than 0.45), and significant scalability challenges for longer video sequences.

08 Oct 2024
Researchers from the University of Auckland and the Jožef Stefan Institute developed Counterfactual-CI, an end-to-end method that leverages Large Language Models to extract causal graphs and perform counterfactual causal inference directly from unstructured natural language. The work reveals that while LLMs excel at discovering causal relationships in text, their capacity for accurate counterfactual reasoning is limited by their ability to perform logical predictions on given causal inputs, even when the correct causal structure is provided.

19 Aug 2025

The emergence of large pre-trained networks has revolutionized the AI field, unlocking new possibilities and achieving unprecedented performance. However, these models inherit a fundamental limitation from traditional Machine Learning approaches: their strong dependence on the \textit{i.i.d.} assumption hinders their adaptability to dynamic learning scenarios. We believe the next breakthrough in AI lies in enabling efficient adaptation to evolving environments -- such as the real world -- where new data and tasks arrive sequentially. This challenge defines the field of Continual Learning (CL), a Machine Learning paradigm focused on developing lifelong learning neural models. One alternative to efficiently adapt these large-scale models is known Parameter-Efficient Fine-Tuning (PEFT). These methods tackle the issue of adapting the model to a particular data or scenario by performing small and efficient modifications, achieving similar performance to full fine-tuning. However, these techniques still lack the ability to adjust the model to multiple tasks continually, as they suffer from the issue of Catastrophic Forgetting. In this survey, we first provide an overview of CL algorithms and PEFT methods before reviewing the state-of-the-art on Parameter-Efficient Continual Fine-Tuning (PECFT). We examine various approaches, discuss evaluation metrics, and explore potential future research directions. Our goal is to highlight the synergy between CL and Parameter-Efficient Fine-Tuning, guide researchers in this field, and pave the way for novel future research directions.

30 Jul 2024
A survey from researchers across leading institutions in China, New Zealand, and Japan provides an integrated overview of cooperation within social dilemmas by examining multi-agent, human-agent, and AI-enhanced human-human interactions. The work synthesizes approaches for designing cooperative AI agents, analyzes the complexities of human-AI collaboration including human biases, and explores how AI can foster greater cooperation among humans.

04 Nov 2024
Researchers from Beijing Institute of Technology, University of Auckland, Hefei University of Technology, and Griffith University developed LLM-SmartAudit, a multi-agent LLM framework designed to improve smart contract vulnerability detection. The system achieved a 74% recall in broad analysis, detected 11 new vulnerabilities missed by prior audits, and offers a cost-effective solution at approximately 1 USD per contract.

27 Nov 2025



OralGPT-Omni is a dental-specialized multimodal large language model designed for comprehensive analysis across diverse dental imaging modalities and clinical tasks. It achieved an overall score of 51.84 on the new MMOral-Uni benchmark, significantly outperforming proprietary MLLMs and incorporating explainable reasoning to enhance diagnostic trustworthiness.

20 Dec 2024
This survey provides a systematic analysis of 287 papers from top FPGA conferences over six years, comprehensively mapping the research landscape for FPGA-based machine learning accelerators. The study identifies that 81% of efforts target ML inference, highlights the maturity and decline in new research for CNNs, and notes a rapid emergence of interest in Graph Neural Networks and Attention networks.
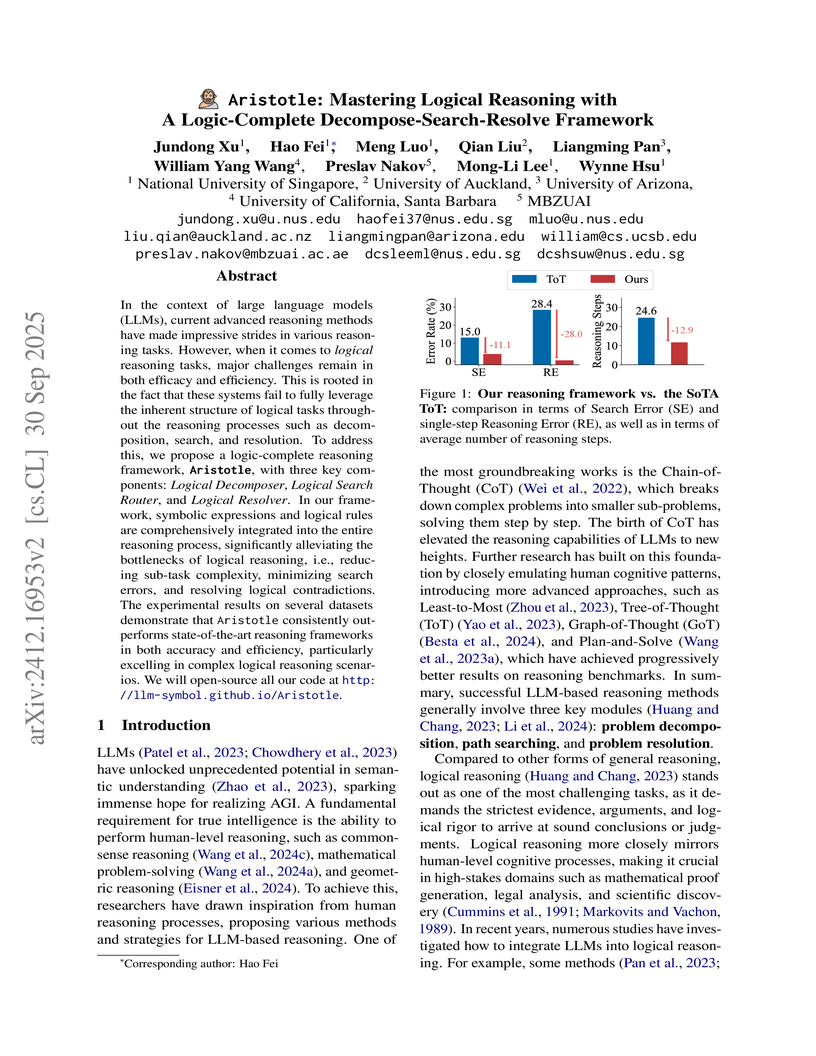
30 Sep 2025
In the context of large language models (LLMs), current advanced reasoning methods have made impressive strides in various reasoning tasks. However, when it comes to logical reasoning tasks, major challenges remain in both efficacy and efficiency. This is rooted in the fact that these systems fail to fully leverage the inherent structure of logical tasks throughout the reasoning processes such as decomposition, search, and resolution. To address this, we propose a logic-complete reasoning framework, Aristotle, with three key components: Logical Decomposer, Logical Search Router, and Logical Resolver. In our framework, symbolic expressions and logical rules are comprehensively integrated into the entire reasoning process, significantly alleviating the bottlenecks of logical reasoning, i.e., reducing sub-task complexity, minimizing search errors, and resolving logical contradictions. The experimental results on several datasets demonstrate that Aristotle consistently outperforms state-of-the-art reasoning frameworks in both accuracy and efficiency, particularly excelling in complex logical reasoning scenarios. We will open-source all our code at this https URL.

08 Aug 2025
Micro-expression recognition (MER) is a highly challenging task in affective computing. With the reduced-sized micro-expression (ME) input that contains key information based on key-frame indexes, key-frame-based methods have significantly improved the performance of MER. However, most of these methods focus on improving the performance with relatively accurate key-frame indexes, while ignoring the difficulty of obtaining accurate key-frame indexes and the objective existence of key-frame index errors, which impedes them from moving towards practical applications. In this paper, we propose CausalNet, a novel framework to achieve robust MER facing key-frame index errors while maintaining accurate recognition. To enhance robustness, CausalNet takes the representation of the entire ME sequence as the input. To address the information redundancy brought by the complete ME range input and maintain accurate recognition, first, the Causal Motion Position Learning Module (CMPLM) is proposed to help the model locate the muscle movement areas related to Action Units (AUs), thereby reducing the attention to other redundant areas. Second, the Causal Attention Block (CAB) is proposed to deeply learn the causal relationships between the muscle contraction and relaxation movements in MEs. Empirical experiments have demonstrated that on popular ME benchmarks, the CausalNet has achieved robust MER under different levels of key-frame index noise. Meanwhile, it has surpassed state-of-the-art (SOTA) methods on several standard MER benchmarks when using the provided annotated key-frames. Code is available at this https URL.

03 Sep 2025



The Nancy Grace Roman Space Telescope (Roman) will conduct a Galactic Exoplanet Survey (RGES) to discover bound and free-floating exoplanets using gravitational microlensing. Roman should be sensitive to lenses with mass down to ~ 0.02 , or roughly the mass of Ganymede. Thus the detection of moons with masses similar to the giant moons in our Solar System is possible with Roman. Measuring the demographics of exomoons will provide constraints on both moon and planet formation. We conduct simulations of Roman microlensing events to determine the effects of exomoons on microlensing light curves, and whether these effects are detectable with Roman. We focus on giant planets from 30 to 10 on orbits from 0.3 to 30 AU, and assume that each planet is orbited by a moon with moon-planet mass ratio from to and separations from 0.1 to 0.5 planet Hill radii. We find that Roman is sensitive to exomoons, although the number of expected detections is only of order one over the duration of the survey, unless exomoons are more common or massive than we assumed. We argue that changes in the survey strategy, in particular focusing on a few fields with higher cadence, may allow for the detection of more exomoons with Roman. Regardless, the ability to detect exomoons reinforces the need to develop robust methods for modeling triple lens microlensing events to fully utilize the capabilities of Roman.

23 Aug 2025
Every year, most educational institutions seek and receive an enormous volume of text feedback from students on courses, teaching, and overall experience. Yet, turning this raw feedback into useful insights is far from straightforward. It has been a long-standing challenge to adopt automatic opinion mining solutions for such education review text data due to the content complexity and low-granularity reporting requirements. Aspect-based Sentiment Analysis (ABSA) offers a promising solution with its rich, sub-sentence-level opinion mining capabilities. However, existing ABSA research and resources are very heavily focused on the commercial domain. In education, they are scarce and hard to develop due to limited public datasets and strict data protection. A high-quality, annotated dataset is urgently needed to advance research in this under-resourced area. In this work, we present EduRABSA (Education Review ABSA), the first public, annotated ABSA education review dataset that covers three review subject types (course, teaching staff, university) in the English language and all main ABSA tasks, including the under-explored implicit aspect and implicit opinion extraction. We also share ASQE-DPT (Data Processing Tool), an offline, lightweight, installation-free manual data annotation tool that generates labelled datasets for comprehensive ABSA tasks from a single-task annotation. Together, these resources contribute to the ABSA community and education domain by removing the dataset barrier, supporting research transparency and reproducibility, and enabling the creation and sharing of further resources. The dataset, annotation tool, and scripts and statistics for dataset processing and sampling are available at this https URL.

02 Jan 2024
Large Language Models have shown tremendous performance on a large variety of natural language processing tasks, ranging from text comprehension to common sense reasoning. However, the mechanisms responsible for this success remain opaque, and it is unclear whether LLMs can achieve human-like cognitive capabilities or whether these models are still fundamentally circumscribed. Abstract reasoning is a fundamental task for cognition, consisting of finding and applying a general pattern from few data. Evaluating deep neural architectures on this task could give insight into their potential limitations regarding reasoning and their broad generalisation abilities, yet this is currently an under-explored area. In this paper, we introduce a new benchmark for evaluating language models beyond memorization on abstract reasoning tasks. We perform extensive evaluations of state-of-the-art LLMs, showing that they currently achieve very limited performance in contrast with other natural language tasks, even when applying techniques that have been shown to improve performance on other NLP tasks. We argue that guiding LLM generation to follow causal paths could help improve the generalisation and reasoning abilities of LLMs.

21 Oct 2025
We study data-driven decision problems where historical observations are generated by a time-evolving distribution whose consecutive shifts are bounded in Wasserstein distance. We address this nonstationarity using a distributionally robust optimization model with an ambiguity set that is a Wasserstein ball centered at a weighted empirical distribution, thereby allowing for the time decay of past data in a way which accounts for the drift of the data-generating distribution. Our main technical contribution is a concentration inequality for weighted empirical distributions that explicitly captures both the effective sample size (i.e., the equivalent number of equally weighted observations) and the distributional drift. Using our concentration inequality, we select observation weights that optimally balance the effective sample size against the extent of drift. The family of optimal weightings reveals an interplay between the order of the Wasserstein ambiguity ball and the time-decay profile of the optimal weights. Classical weighting schemes, such as time windowing and exponential smoothing, emerge as special cases of our framework, for which we derive principled choices of the parameters. Numerical experiments demonstrate the effectiveness of the proposed approach.

25 Apr 2025
The proliferation of various data sources in urban and territorial
environments has significantly facilitated the development of geospatial
artificial intelligence (GeoAI) across a wide range of geospatial applications.
However, geospatial data, which is inherently linked to geospatial objects,
often exhibits data heterogeneity that necessitates specialized fusion and
representation strategies while simultaneously being inherently sparse in
labels for downstream tasks. Consequently, there is a growing demand for
techniques that can effectively leverage geospatial data without heavy reliance
on task-specific labels and model designs. This need aligns with the principles
of self-supervised learning (SSL), which has garnered increasing attention for
its ability to learn effective and generalizable representations directly from
data without extensive labeled supervision. This paper presents a comprehensive
and up-to-date survey of SSL techniques specifically applied to or developed
for geospatial objects in three primary vector geometric types: Point,
Polyline, and Polygon. We systematically categorize various SSL techniques into
predictive and contrastive methods, and analyze their adaptation to different
data types for representation learning across various downstream tasks.
Furthermore, we examine the emerging trends in SSL for geospatial objects,
particularly the gradual advancements towards geospatial foundation models.
Finally, we discuss key challenges in current research and outline promising
directions for future investigation. By offering a structured analysis of
existing studies, this paper aims to inspire continued progress in integrating
SSL with geospatial objects, and the development of geospatial foundation
models in a longer term.

14 Apr 2025
University of Illinois at Urbana-Champaign Texas A&M University
Texas A&M University McGill University
McGill University Arizona State University
Arizona State University University of MinnesotaUniversity of Wisconsin-Madison
University of MinnesotaUniversity of Wisconsin-Madison The Pennsylvania State UniversityOak Ridge National LaboratoryUniversity of AucklandUniversity of ViennaGeorge Mason UniversityUniversity of South CarolinaU.S. Geological Survey
The Pennsylvania State UniversityOak Ridge National LaboratoryUniversity of AucklandUniversity of ViennaGeorge Mason UniversityUniversity of South CarolinaU.S. Geological SurveyThis paper defines and proposes a comprehensive conceptual framework for "Autonomous GIS," an AI-powered next-generation system that leverages generative AI and Large Language Models to automate geospatial problem-solving. It outlines specific autonomous goals, functional components, levels of autonomy, and operational scales, while presenting proof-of-concept GIS agents that demonstrate automated data retrieval, spatial analysis, and cartographic design.
There are no more papers matching your filters at the moment.
