25 Aug 2025


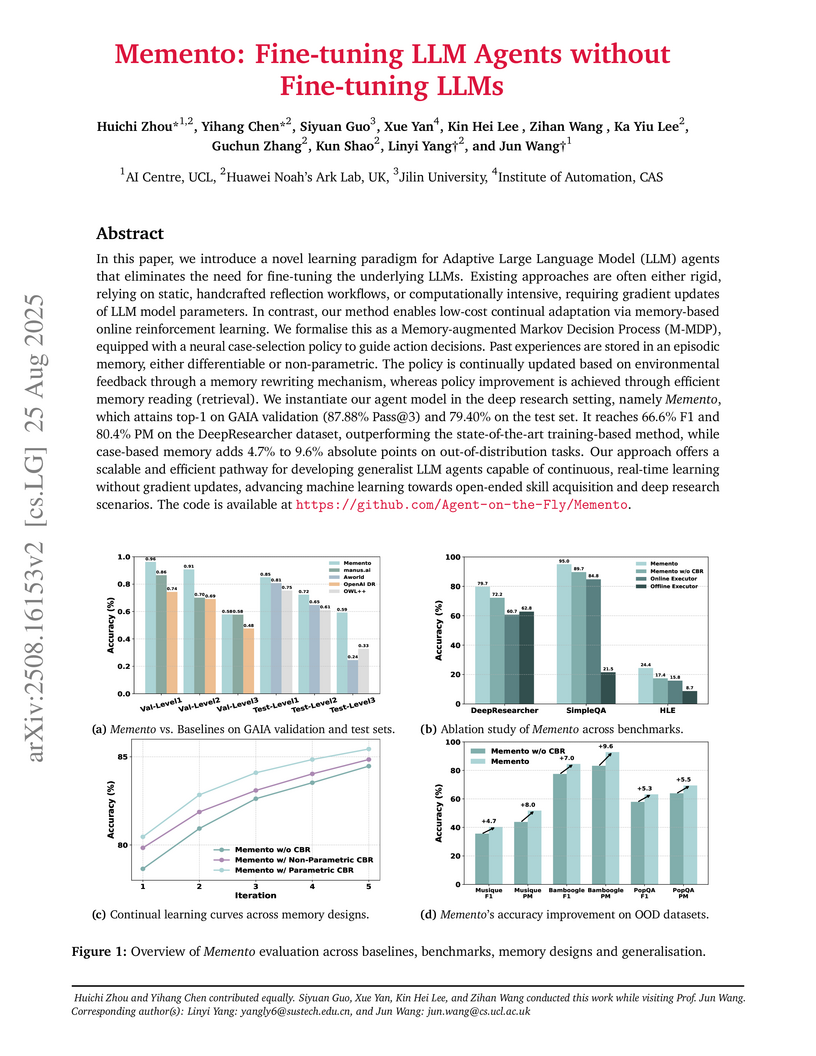
Researchers from UCL AI Centre and Huawei Noah’s Ark Lab developed Memento, a memory-based learning framework enabling LLM agents to continually adapt and improve without fine-tuning their underlying large language models. The framework achieved top performance on complex benchmarks, including 87.88% Pass@3 on GAIA and 95.0% accuracy on SimpleQA, demonstrating efficient, robust adaptation and generalization.

08 Dec 2025

Utilizing multi-band JWST observations, this research reveals that high-redshift submillimeter galaxies primarily form through secular evolution and internal processes rather than major mergers, uncovering a significant population of central stellar structures that do not conform to established local galaxy classifications.

16 Oct 2025
Researchers at the Chinese Academy of Sciences developed QDepth-VLA, a framework that enhances Vision-Language-Action (VLA) models with robust 3D geometric understanding through quantized depth prediction as auxiliary supervision. This approach improves performance on fine-grained robotic manipulation tasks, achieving up to 29.7% higher success rates on complex simulated tasks and 20.0% gains in real-world pick-and-place scenarios compared to existing baselines.

11 Jun 2024

Developed by Huawei Co., Ltd., CODER introduces a multi-agent framework guided by pre-defined task graphs to automate GitHub issue resolution. The system achieved a 28.33% resolved rate on SWE-bench lite, establishing a new state-of-the-art for the benchmark.

27 Dec 2024

Recent advances in speech spoofing necessitate stronger verification
mechanisms in neural speech codecs to ensure authenticity. Current methods
embed numerical watermarks before compression and extract them from
reconstructed speech for verification, but face limitations such as separate
training processes for the watermark and codec, and insufficient cross-modal
information integration, leading to reduced watermark imperceptibility,
extraction accuracy, and capacity. To address these issues, we propose WMCodec,
the first neural speech codec to jointly train compression-reconstruction and
watermark embedding-extraction in an end-to-end manner, optimizing both
imperceptibility and extractability of the watermark. Furthermore, We design an
iterative Attention Imprint Unit (AIU) for deeper feature integration of
watermark and speech, reducing the impact of quantization noise on the
watermark. Experimental results show WMCodec outperforms AudioSeal with Encodec
in most quality metrics for watermark imperceptibility and consistently exceeds
both AudioSeal with Encodec and reinforced TraceableSpeech in extraction
accuracy of watermark. At bandwidth of 6 kbps with a watermark capacity of 16
bps, WMCodec maintains over 99% extraction accuracy under common attacks,
demonstrating strong robustness.
24 May 2024
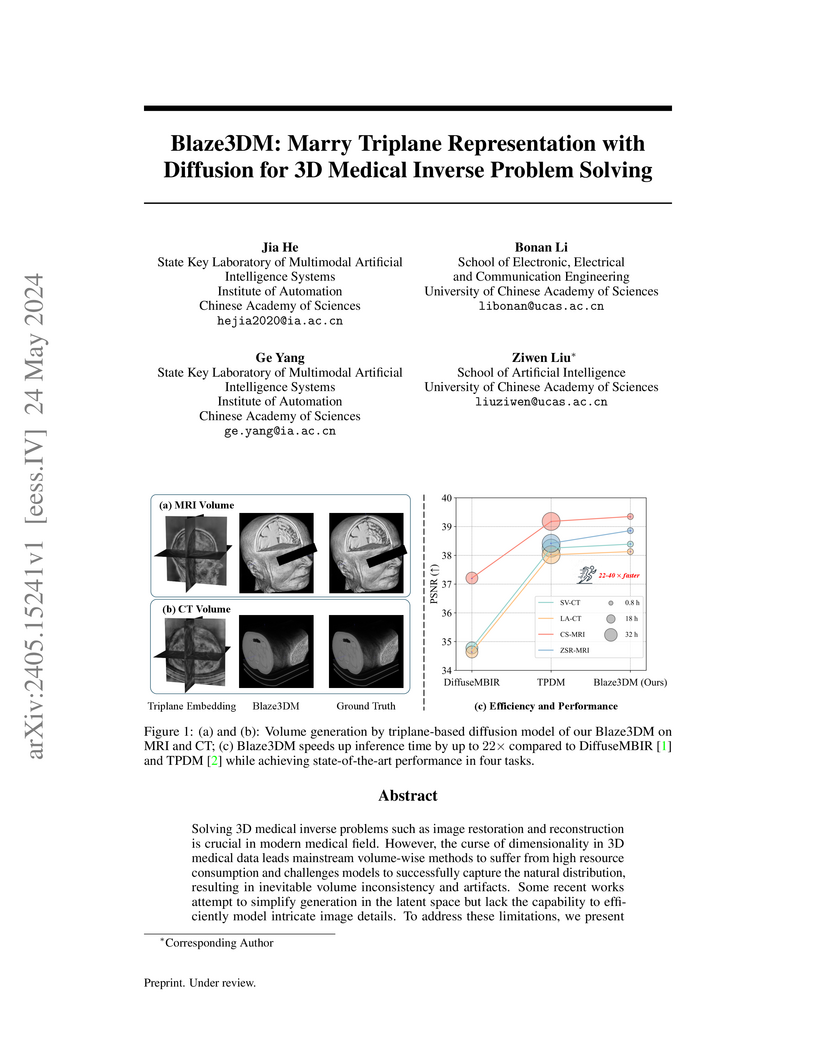
Solving 3D medical inverse problems such as image restoration and reconstruction is crucial in modern medical field. However, the curse of dimensionality in 3D medical data leads mainstream volume-wise methods to suffer from high resource consumption and challenges models to successfully capture the natural distribution, resulting in inevitable volume inconsistency and artifacts. Some recent works attempt to simplify generation in the latent space but lack the capability to efficiently model intricate image details. To address these limitations, we present Blaze3DM, a novel approach that enables fast and high-fidelity generation by integrating compact triplane neural field and powerful diffusion model. In technique, Blaze3DM begins by optimizing data-dependent triplane embeddings and a shared decoder simultaneously, reconstructing each triplane back to the corresponding 3D volume. To further enhance 3D consistency, we introduce a lightweight 3D aware module to model the correlation of three vertical planes. Then, diffusion model is trained on latent triplane embeddings and achieves both unconditional and conditional triplane generation, which is finally decoded to arbitrary size volume. Extensive experiments on zero-shot 3D medical inverse problem solving, including sparse-view CT, limited-angle CT, compressed-sensing MRI, and MRI isotropic super-resolution, demonstrate that Blaze3DM not only achieves state-of-the-art performance but also markedly improves computational efficiency over existing methods (22~40x faster than previous work).

01 Oct 2025


While Large Language Models (LLMs) have become the predominant paradigm for automated code generation, current single-model approaches fundamentally ignore the heterogeneous computational strengths that different models exhibit across programming languages, algorithmic domains, and development stages. This paper challenges the single-model convention by introducing a multi-stage, performance-guided orchestration framework that dynamically routes coding tasks to the most suitable LLMs within a structured generate-fix-refine workflow. Our approach is grounded in a comprehensive empirical study of 17 state-of-the-art LLMs across five programming languages (Python, Java, C++, Go, and Rust) using HumanEval-X benchmark. The study, which evaluates both functional correctness and runtime performance metrics (execution time, mean/max memory utilization, and CPU efficiency), reveals pronounced performance heterogeneity by language, development stage, and problem category. Guided by these empirical insights, we present PerfOrch, an LLM agent that orchestrates top-performing LLMs for each task context through stage-wise validation and rollback mechanisms. Without requiring model fine-tuning, PerfOrch achieves substantial improvements over strong single-model baselines: average correctness rates of 96.22% and 91.37% on HumanEval-X and EffiBench-X respectively, surpassing GPT-4o's 78.66% and 49.11%. Beyond correctness gains, the framework delivers consistent performance optimizations, improving execution time for 58.76% of problems with median speedups ranging from 17.67% to 27.66% across languages on two benchmarks. The framework's plug-and-play architecture ensures practical scalability, allowing new LLMs to be profiled and integrated seamlessly, thereby offering a paradigm for production-grade automated software engineering that adapts to the rapidly evolving generative AI landscape.

01 Apr 2025

Researchers developed LARF (Let AI Read First), an AI-powered system leveraging GPT-4 to annotate important information in texts with visual cues, improving reading performance and subjective experience for individuals with dyslexia, particularly those with more severe conditions. The system enhanced objective detail retrieval and comprehension while preserving original content.

25 Nov 2024
The Octree-Graph introduces a training-free system for open-vocabulary 3D scene understanding that combines efficient adaptive-octree spatial representation with a graph framework. The system achieves a +17.1% mIoU improvement on ScanNet for 3D semantic segmentation and reduces storage by two orders of magnitude compared to point clouds, enabling complex object retrieval and multi-resolution path planning.

22 Sep 2023


OneNet introduces an online ensembling framework to enhance time series forecasting models by addressing concept drift. It achieves a substantial reduction in online forecasting errors, reducing average cumulative Mean Squared Error by 53.1% and Mean Absolute Error by 34.5% compared to the previous state-of-the-art method, FSNet.

23 Dec 2024

Large Language Models (LLMs) have advanced rapidly in recent years, with their applications in software engineering expanding to more complex repository-level tasks. GitHub issue resolving is a key challenge among these tasks. While recent approaches have made progress on this task, they focus on textual data within issues, neglecting visual data. However, this visual data is crucial for resolving issues as it conveys additional knowledge that text alone cannot. We propose CodeV, the first approach to leveraging visual data to enhance the issue-resolving capabilities of LLMs. CodeV resolves each issue by following a two-phase process: data processing and patch generation. To evaluate CodeV, we construct a benchmark for visual issue resolving, namely Visual SWE-bench. Through extensive experiments, we demonstrate the effectiveness of CodeV, as well as provide valuable insights into leveraging visual data to resolve GitHub issues.

15 Oct 2025
Integrated photonic circuits are foundational for versatile applications, where high-performance traveling-wave optical resonators are critical. Conventional whispering-gallery mode microresonators (WGMRs) confine light in closed-loop waveguide paths, thus inevitably occupy large footprints. Here, we report an ultracompact high loaded Q silicon photonic WGMR in an open curved path instead. By leveraging spatial mode multiplexing, low-loss mode converter-based photonic routers enable reentrant photon recycling in a single non-closed waveguide. The fabricated device achieves a measured loaded Q-factor of 1.78*10^5 at 1554.3 nm with a 1.05 nm free spectral range in a ultracompact footprint of 0.00137 mm^2-6*smaller than standard WGMRs while delivering 100*higher Q-factor than photonic crystal counterparts. This work pioneers dense integration of high-performance WGMR arrays through open-path mode recirculation.

08 Sep 2025


ToxicSQL introduces a framework for investigating and exploiting SQL injection vulnerabilities in LLM-based Text-to-SQL models through backdoor attacks. The work demonstrates that these models can be trained with low poisoning rates to generate malicious, executable SQL queries while retaining normal performance on benign inputs, thereby exposing critical security flaws in database interaction systems.

27 Jul 2023

Huawei Cloud Co., Ltd. researchers developed PanGu-Coder2, a Code LLM fine-tuned with the RRTF framework, achieving 61.64% pass@1 on HumanEval and outperforming prior open-source models as well as several larger commercial models.

21 May 2025

This research develops a frequency domain analysis framework using the Z-transform to formally analyze momentum methods in deep learning optimization, interpreting them as time-variant filters for gradients. The framework reveals key distinctions between coupled and decoupled momentum formulations and guides the design of Frequency Stochastic Gradient Descent with Momentum (FSGDM), an optimizer that consistently achieves higher test accuracy and rewards across diverse tasks in image classification, natural language processing, and reinforcement learning.

10 Mar 2025
Magnetic resonance imaging (MRI) reconstruction is a fundamental task aimed
at recovering high-quality images from undersampled or low-quality MRI data.
This process enhances diagnostic accuracy and optimizes clinical applications.
In recent years, deep learning-based MRI reconstruction has made significant
progress. Advancements include single-modality feature extraction using
different network architectures, the integration of multimodal information, and
the adoption of unsupervised or semi-supervised learning strategies. However,
despite extensive research, MRI reconstruction remains a challenging problem
that has yet to be fully resolved. This survey provides a systematic review of
MRI reconstruction methods, covering key aspects such as data acquisition and
preprocessing, publicly available datasets, single and multi-modal
reconstruction models, training strategies, and evaluation metrics based on
image reconstruction and downstream tasks. Additionally, we analyze the major
challenges in this field and explore potential future directions.

14 Jun 2024

SliME introduces a framework for Large Multimodal Models to efficiently process high-resolution images by intelligently compressing local features and employing a novel alternating training scheme. This approach achieves state-of-the-art performance across 15 benchmarks, including mathematical and scientific reasoning, with significantly less training data than many competitors.

26 Aug 2024
This paper introduces SWE-BENCH-JAVA, a new benchmark designed to evaluate large language models on their ability to resolve real-world GitHub issues in Java repositories. The benchmark comprises 91 manually verified issue instances from popular Java projects, demonstrating that current LLMs achieve relatively low success rates on these complex tasks, with DeepSeek models generally outperforming others.

06 Aug 2025
With the rapid development of generative technologies, AI-Generated Images (AIGIs) have been widely applied in various aspects of daily life. However, due to the immaturity of the technology, the quality of the generated images varies, so it is important to develop quality assessment techniques for the generated images. Although some models have been proposed to assess the quality of generated images, they are inadequate when faced with the ever-increasing and diverse categories of generated images. Consequently, the development of more advanced and effective models for evaluating the quality of generated images is urgently needed. Recent research has explored the significant potential of the visual language model CLIP in image quality assessment, finding that it performs well in evaluating the quality of natural images. However, its application to generated images has not been thoroughly investigated. In this paper, we build on this idea and further explore the potential of CLIP in evaluating the quality of generated images. We design CLIP-AGIQA, a CLIP-based regression model for quality assessment of generated images, leveraging rich visual and textual knowledge encapsulated in CLIP. Particularly, we implement multi-category learnable prompts to fully utilize the textual knowledge in CLIP for quality assessment. Extensive experiments on several generated image quality assessment benchmarks, including AGIQA-3K and AIGCIQA2023, demonstrate that CLIP-AGIQA outperforms existing IQA models, achieving excellent results in evaluating the quality of generated images.

09 Dec 2024

Thanks to the powerful generative capacity of diffusion models, recent years have witnessed rapid progress in human motion generation. Existing diffusion-based methods employ disparate network architectures and training strategies. The effect of the design of each component is still unclear. In addition, the iterative denoising process consumes considerable computational overhead, which is prohibitive for real-time scenarios such as virtual characters and humanoid robots. For this reason, we first conduct a comprehensive investigation into network architectures, training strategies, and inference processs. Based on the profound analysis, we tailor each component for efficient high-quality human motion generation. Despite the promising performance, the tailored model still suffers from foot skating which is an ubiquitous issue in diffusion-based solutions. To eliminate footskate, we identify foot-ground contact and correct foot motions along the denoising process. By organically combining these well-designed components together, we present StableMoFusion, a robust and efficient framework for human motion generation. Extensive experimental results show that our StableMoFusion performs favorably against current state-of-the-art methods. Project page: this https URL
There are no more papers matching your filters at the moment.
